基于关键词与本体混合搜索的实现
2018-10-31浩庆波
徐 岩, 浩庆波, 高 慧
(曲阜师范大学 网络信息中心, 山东 济宁 273100)
1 扩散激活理论
在认知科学领域, 通常使用语义Web来长期记忆存储知识的表示。在语义Web中, 概念被表示为节点, 通过关系进行链接。语义网络中的信息处理通常遵从扩散激活理论(Spreading activation theory)[1], 在这个理论中每一个节点通过某一计算值传播到其相邻节点,为网络的特定节点提供了一组初始输入。在传播激活过程中, 网络中的每个概念都将根据其关系而激活特定的值到相邻节点。由于本体和语义Web结构很相似并且由于扩散激活理论已被证明在语义网络中是有效的推理工具, 因此本文选择该理论作为本体推荐的理论基础[2]。
下面举例说明扩散激活理论在本体中的应用。如图1所示,概念节点"Team"初始时用值1.0来激活,这个节点激活后,在整个语义网络中传播激活。当网络稳定时, 所有的节点都将被激活,如图2所示。每个节点的激活值不完全依赖于其与初始节点距离。例如: " Serie A " 的概念比 " Inter Milan " 的激活价值更高,这意味着在本体中 " Serie A" 认为与 "Team" 更相关。
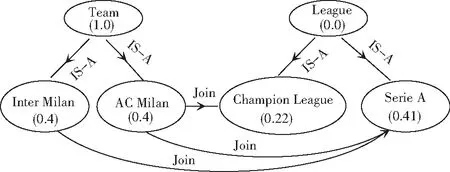
图2 扩散激活的结束状态
在传播激活扩散理论中,给定源结点x和目标结点y,激活过程可以用公式(1)来表示:
Iy(ti+1)=Ox(ti)×mxy×(1-α),α∈[0,1]
(1)
上式中的Iy(ti+1)是结点y在ti+1时刻传播扩散中的输入值,Ox(ti)是结点x在时刻ti的输出。mxy是结点x和y之间的权重,α是衰减因子,用来表示在传播扩散过程中的能力损失。
对于完整的激活扩散理论可以用上式来表示,然而在工程实现中为了减少计算量,通常认为结点y在时刻ti的输出就是该结点的输入,如公式(2):
oy(ti)=Iy(ti)
(2)
因此,在本体中的扩散激活过程可以用公式(3)来表示:
o=[ε-(1-α)MT]-1I
(3)
上式中I=[I1,I2,I3,...,In]T是整个网络的输入;矩阵M代表整个本体,对于矩阵M中的任意一个元素mxy代表概念cx和cy之间的关系;α是衰减因子;ε是n阶单位矩阵;O=[O1,O2,O3,...,On]T是整个激活扩散过程的输出结果,对于向量O中的任意一个元素Ox,则代表cx在整个激活扩散过程中获得的值。
2 基于关键词搜索与基于本体搜索的融合
利用上节的传播激活扩散理论,可以将基于关键词搜索与基于本体搜索两种方法相融合,最终达到较好的搜索效果[3]。搜索过程的流程如图3所示。
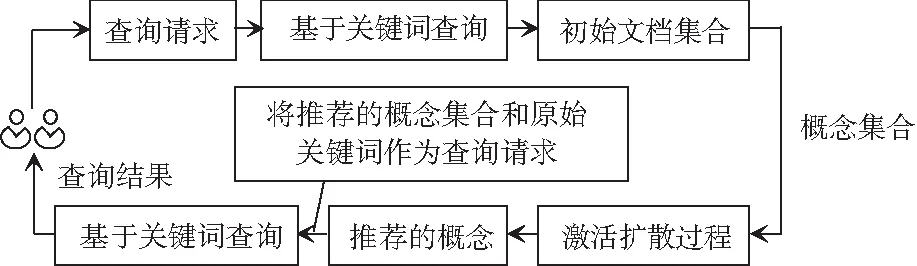
图3 2种搜索方法融合示意图
当用户输入关键词搜索时,首先利用基于关键词的搜索方法得到原始的搜索结果,因为系统中的文档都是预先标注好的,同时也获取了搜索结果隶属于概念的概念列表[4]。对这些概念列表进行分析,可以得到向量Iq,如公式(4)所示:
Iq=[I1, q,I2, q, ...,In, q]T
(4)
向量Iq作为整个传播激活扩散过程的输入,对于向量Iq中的任一元素Ii,q,代表概念ci在查询q结果中出现的频率,Ii,q可以使用公式(5)来计算:
(5)
其中,freq(ci)代表概念ci在查询q结果中出现的频率。
计算出向量Iq后,继续求解公式(3)中的变量,对于矩阵W中每一个元素Wi, j,代表搜索结果中概念集合中关系ri, j出现的权重。
根据公式(3)可以计算出扩散激活过程的输出O,向量O中任一元素Oi, q,代表概念ci和查询q之间的相关性。最后对向量O归一化,对向量的每一个元素按照实数大小倒序排序组成列表,就可以得到搜索结果中出现的概念和查询q之间的相关性。
最后,取相关性最大的几个概念和原来的关键词一起使用,基于关键词的搜索可以得到较好的搜索结果[5-6]。
3 结束语
本文针对基于关键词的搜索方法和基于本体搜索方法存在的问题,分析两种方法目前存在的瑕疵,并尝试解决。本文首先根据《中图法》构建了适用于搜索引擎的本体库,在此基础上结合了两种搜索方法的优点,提高了搜索结果质量。两种方法融合的优点:
(1)考虑到了原始基于关键词搜索结果,出现的各个概念的权重是根据搜索结果出现的频率来设定的,这样不会偏离用户查询的本意。
(2)基于本体的搜索过程中,综合考虑固有本体概念之间的结构和本次搜索概念之间的权重关系,同时兼顾了用户的查询意图和固有本体概念之间的关系。
