基于大数据的驾驶风格识别算法研究
2018-10-29吴振昕何云廷于立娇付雷陈盼
吴振昕 何云廷 于立娇 付雷 陈盼
(中国第一汽车集团有限公司智能网联开发院,长春 130011)
主题词:驾驶风格识别 工况辨识 机器学习 决策融合
1 前言
车载电控系统数量日益增多且高度智能集成化,产生了大量数据,如何基于T-Box上传的数据开展挖掘分析,并通过挖掘数据价值创新业务引流衍生新的与车辆相关的业务,将是各大整车厂由生产车辆的传统业务向汽车生态圈拓展业务转型的重要途径。
驾驶风格识别是车联网领域的一项新兴技术,早期由于车辆数据量较小,其应用范围受限。随着车载T-Box的普及,车辆数据逐渐丰富化,驾驶风格识别应用广度和深度不断扩大。目前,驾驶风格识别研究方法大体分为3种:驾驶风格问卷调查、基于底盘数据和/或先进驾驶辅助系统(Advanced Driver Assisted System,ADAS)数据的统计分析、基于底盘数据和/或ADAS数据的机器学习分析[1-2]。由于驾驶员可能隐瞒自己某些偏向危险的驾驶行为及问卷题目设置困难等原因,驾驶风格调查问卷精度不高。基于底盘数据和/或ADAS数据的统计分析方法对与驾驶风格强相关的车辆状态参数进行统计分析得到驾驶风格识别结果,但面对海量数据时,统计分析方法的数据处理能力捉襟见肘。机器学习的优势是处理海量数据,随着车联网平台的广泛建立和T-Box数据上传频率的增大,车辆状态数据量呈指数级增长,基于底盘数据和/或ADAS数据的机器学习方法识别驾驶风格因精度高、机器学习技术成熟等原因具有广阔的研究与应用空间。
本文利用数据挖掘技术开展基于大数据的驾驶风格识别研究,建立了驾驶风格数据库,进行工况辨识,并提取工况特征建立驾驶风格识别模型,获得了驾驶员总体驾驶风格标签。驾驶风格识别结果可应用于ADAS开发及个性化定制、车辆能量控制、汽车电控系统控制参数调节、驾驶员能力提升及保险等后市场服务[3-5],为未来整车企业向服务生态提供商转型提供有力支撑。
2 驾驶风格数据库构建
为了训练并测试机器学习模型,本文将驾驶风格数据库分为固定工况试验数据和自然驾驶试验数据,分别将两种数据用于训练和测试机器学习模型,为驾驶风格识别建立可靠的数据库基础。固定工况的选择依据前期大量的调研与对标结果确定,包括换道、转弯、跟车等7种工况。
本文实车试验采用1辆试验样车和1辆环境车,在城市道路开展实车驾驶试验,提取各工况数据,构建驾驶风格数据库。
2.1 试验前期准备
2.1.1 车辆改装
基于信号需求对试验样车进行改装,在车辆正前方、正后方分别安装毫米波雷达,在车辆正前方安装前视图像单元。
试验设备采用多通道CANoe和Dewe43数据采集仪,其中CANoe主要采集试验车辆动力CAN信号、正前方雷达传感器信号、正后方雷达传感器信号及前视图像单元信号,Dewe43用于采集环境车辆的动力CAN数据。
2.1.2 驾驶员筛选及试验路线规划
资料显示,我国在册机动车驾驶员男女比例约为1.8∶1[2],本文筛选驾驶员时男女比例定为2∶1。为了避免参与试验的驾驶员驾驶风格偏向某一方面导致试验数据分布不均,在进行试验前通过《驾驶员驾驶风格调查问卷》进行初选,根据问卷得分在总体中的分布、性别、年龄和驾龄筛选参与试验的驾驶员。考虑样本分布的均衡合理,不仅要保证男女比例,而且须覆盖不同年龄分段(25~55岁)、不同的实际驾驶风格,本文从262名参与问卷调查的驾驶员中筛选出80名驾驶员参与实车试验。
试验路线如图1示,分为规定工况路线和自由驾驶路线。试验时,每位驾驶员需要提前熟悉车辆和试验路线,试验开始后,每位驾驶员分别在50 km/h和70 km/h两种常用车速下进行3次重复试验。
2.2 试验数据预处理
常见的数据预处理方法包括滤波、缺失值处理、异常值处理、归一化、重采样、单位转换等。车辆底盘CAN信号含有噪声,导致信号毛刺比较多。为了提高分析精度,根据各原始信号及其噪声的特点对其进行滤波处理。以纵向加速度信号为例,其含高频噪声成分较多,可采用低通滤波器,根据纵向加速度信号的频率属性设置滤波器通带截止频率为3 Hz,阻带截止频率为6 Hz。滤波后信号高频部分的幅值明显减小,低频部分幅值不变,符合纵向加速度信号的频率属性。

图1 试验路线
3 工况辨识
根据车辆动力学原理进行工况辨识,从驾驶风格数据库中提取出7种固定工况,即转弯工况、变道工况、超车工况、掉头工况、跟车工况、起动工况和停止工况,然后利用工况辨识结果识别驾驶员风格。
本文以转弯工况为例说明工况辨识逻辑,其他工况辨识原理与转弯工况相同,只是提取的特征不同。
3.1 转弯工况辨识逻辑
根据车辆动力学原理,与直线行驶相比,转弯时车辆航向角、横摆角速度和侧向加速度会发生明显变化[6],根据实车试验转弯工况的统计分析结果确定转弯工况辨识逻辑的各项判定阈值,转弯工况辨识逻辑如图2示。

图2 转弯工况辨识逻辑
3.2 转弯工况辨识逻辑验证
为了验证转弯工况辨识逻辑的准确性,利用车辆GPS信号绘制车辆运动轨迹,标出已辨识出的转弯工况,辨识效果如图3示。

图3 转弯工况辨识逻辑验证
由图3可知,该逻辑可以较准确地辨识出转弯工况。在较低车速下,不同驾驶员间的操纵差异较小,故本文研究中、高车速下的驾驶风格识别。结果显示,该辨识逻辑可以用于驾驶风格识别中的转弯工况辨识。
4 建立驾驶风格识别模型
基于第3节工况辨识结果,利用无监督机器学习方法——K均值法对每种工况下的数据进行聚类分析,得到每种工况下驾驶风格识别结果;然后利用决策融合方法将每种工况下的风格识别结果进行决策融合,得到驾驶员的总体驾驶风格标签。
4.1 机器学习
机器学习是一门研究如何通过计算的手段、利用经验改善系统自身性能的学科[7],其研究的主要内容是在计算机上利用数据产生“模型”的方法,即“学习算法”。随着数据量不断积累,传统的数据分析方法不能有效处理大量数据,机器学习算法很好地解决了这一问题,广泛应用于计算机科学的众多分支领域以及交叉学科。
大数据的其特点是容量大、速度快、模态多、难辨识、价值大、密度低[8-9]。机器学习能够很好地应对大数据分析的困难和挑战,成为分析大数据的主流技术。按照机器学习过程中使用的样本是否存在标签,可将其分为监督学习和非监督学习[10]。监督学习是指训练的数据样本带有标签,在训练过程中利用标签评价模型的训练结果、调试模型参数、改进模型精度,根据标签从训练样本中学习对象的划分规则[11]。非监督学习适用于样本标签难以获得的情况,通过学习数据间内在模式和规律获得样本的特征[12]。非监督学习的典型算法有自动编码器、受限玻尔兹曼机、深度置信网络等,主要应用于聚类、异常检测等。
本文的研究目的是驾驶员驾驶风格识别,在实际应用场景中驾驶员风格标签未知,所以本文选择无监督机器学习方法对驾驶风格进行聚类。常用的聚类方法有划分聚类、层次聚类、密度聚类,其中划分聚类常见的方法有K均值法、CLARANS算法等,层次聚类典型的算法包括BIRICH、CURE等,密度聚类典型算法有具有噪声的基于密度的聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)方法、通过点排序识别聚类结构(Ordering Points To Identify the Clustering Structure,OPTICS)算法等[13]。
以上各种聚类方法中,K均值法是最经典、应用最广泛的算法之一,该方法用质心定义原型,其质心是一组点的均值,常用于n维连续空间中的对象[14]。综合考虑各种聚类方法的优缺点及使用场合,选择K均值法对驾驶风格进行聚类。
K均值法采用贪心策略,通过迭代优化来近似求解最小化平方误差,对于给定的样本集D={x1,x2,…,xm},K均值针对聚类所得簇划分C={C1,C2,…,Ck}最小化平方误差:
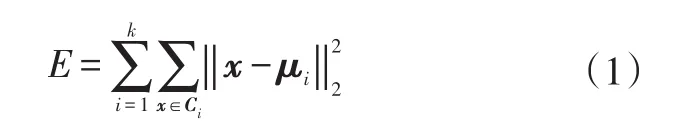
式(1)刻画了簇内样本围绕簇均值向量的紧密程度,E越小,则簇内样本相似度越高。K均值算法流程如图4示。

图4 K均值算法流程
4.2 决策融合算法
在一段行程中,可能包含多个工况及某一工况多次出现,例如转弯、跟车、变道等工况,驾驶风格识别需要将某一工况出现一次的识别结果与到目前为止已经存在的该工况多次出现的识别结果融合,然后再把不同工况的识别结果融合,得到一段行程驾驶风格识别的最终结果。因此,本文决策融合算法分为两个层级:同一工况级决策融合,不同工况级决策融合。
决策融合方法的选择取决于分类器输出的类型:如果分类器输出概率值或范围值,那么融合这两种类型输出的算法称为软决策融合算法;如果分类器输出的结果是类标签或类的集合,那么融合这两种类型输出的算法称为硬决策融合算法。常见的软决策融合算法包括乘积法、求和法、最大/最小值法、均值法等[15-16],常见的硬决策融合算法包括投票法、贝叶斯法、D-S证据理论、神经网络、粗糙集理论等[17-18]。
本文聚类输出的结果属于标签类,所以需要选择一种硬决策融合算法。同一工况下融合识别结果的特点是多条识别结果融合、新产生工况的识别结果与历史识别结果融合,由于驾驶风格受交通环境影响可能会发生变化,为了体现工况识别结果的变化,选择D-S证据理论作为融合方法,避免投票法和贝叶斯计算先验概率时湮没新进识别结果。D-S证据理论于1967年提出,它比传统的概率论能更好地的把握问题的未知性和不确定,从而在多传感器信息融合中得到了广泛的应用。
设m1和m2是两个相互独立的基本概率赋值,那么组合后的基本概率赋值为m=m1⊕m2,即对两个证据进行融合,D-S证据理论提供了一种计算两个证据融合后的基本概率的方法。
4.3 驾驶风格识别模型
4.3.1 特征提取与特征选择
提取表征驾驶风格的特征是建立机器学习模型的基础,并且选择特征的优劣很大程度决定了模型的准确度。
试验采集的车辆状态信号中,能反映驾驶员驾驶风格的信号主要包括车速、纵向加速度、油门踏板开度、侧向加速度、横摆角速度、航向角、转向盘转角及其角速度共8个通道信号,根据本文提出的工况辨识逻辑获得驾驶员驾驶工况数据后,需要提取可以表征驾驶风格的特征,用于建立和训练机器学习模型。对于每个通道信号利用统计学方法提取统计特征,例如转弯工况下,提取车速的均值、最大值、最小值、方差、标准差、协方差、均方根、四分位值等统计量。利用此法处理8个通道信号,共得到105个特征。
从原始数据提取的特征会包含离群样本点,这样的数据点会对特征处理过程中的归一化产生影响,所以需要剔除离群点,以还原特征数据正常分布,如图5、图6所示。
在不同工况下需对90个特征进行筛选以降低聚类模型的复杂度,提高其精度。首先根据特征方差大小进行特征筛选,得到35个方差较大的特征,然后利用车辆动力学先验知识和因子分析(Factor analysis)方法进一步筛选特征,最终得到3个关键特征,即转向盘角速度最大值、横摆角速度最大值、侧向加速度最大值,用于建立和训练聚类模型。
图5 特征中存在数值较大的离群点

图6 剔除离群点后数据特征分布
4.3.2 驾驶风格聚类模型
根据先验知识,一般将驾驶风格分为谨慎型、一般型、激进型,因此K均值方法中K=3。聚类完成后,根据特征的数值大小分布情况并结合车辆动力学原理,为聚类得到的3个簇分别打上标签。以80名驾驶员的6 700多个换道工况为例,利用K均值方法对换道数据进行聚类,结果如图7所示。

图7 换道工况聚类结果
评价聚类模型优劣通常有两种方法,一种是基于对象间距,另一种是基于人工主观标签结果。由于本文的目的是识别驾驶风格,除考虑聚类模型本身性能的优劣外,还要结合业务背景考虑风格聚类结果与实际情况是否相符,因此采用与人工主观标签结果对比来评价聚类模型的优劣。人工主观标签由具有丰富经验的、了解驾驶风格评价方法并全程参与试验的专家提供。
4.3.3 驾驶风格决策融合模型
以换道工况为例,利用D-S证据理论进行决策融合的过程为[19]:
a.设n为D-S证据理论进行决策融合的最小工况数,前n个换道工况识别出的3类风格频数分别为m0、m1、m2,当第(n+1)个换道工况出现时,第(n-1)、n、(n+1)个换道工况识别出的3类风格频数分别为p0、p1、p2;
b.计算前n个换道工况下3类风格出现的概率分别为r0=m0/(m0+m1+m2)、r1=m1/(m0+m1+m2)、r2=m2/(m0+m1+m2),得到概率矩阵R=(r0,r1,r2);
c. 计算第(n-1)、n、(n+1)个换道工况下3类风格出现的概率分别为s0=p0/(p0+p1+p2)、s1=p1/(p0+p1+p2)、s2=p2/(p0+p1+p2),得到概率矩阵S=(s0,s1,s2);
d. 计算矩阵R与ST之积,得到混合矩阵N=R⊗ST=
e. 计算不确定系数K1=s0r1+s0r2+s1r0+s1r2+s2r0+s2r1;
f. 计算D-S证据理论概率融合矩阵M=(M1,M2,M3),其中M1=s0r0/(1-K1),M2=s1r1/(1-K1),M3=s2r2/(1-K1),当K1=1时表示相互融合的事件相互独立,无法进行融合;
g.应用D-S证据理论融合判据确定融合后的类,预先设定门限值e1,令L1=maxMi,L2=maxMi,(Mi≠L1),如果L1-L2>e1,则L1对应的类为融合后的类。
驾驶风格决策融合模型首先采用D-S证据理论对同一工况的多个识别结果进行融合,然后进行不同工况识别结果融合。以换道工况为例,80名驾驶员换道工况的D-S证据理论融合结果与人工标签对比结果如表1示。
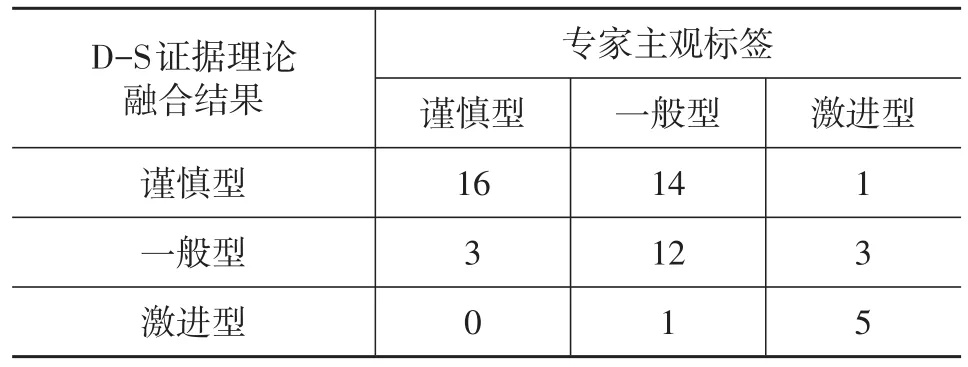
表1 换道工况D-S证据理论融合结果与专家主观标签对比 名
由表1可知,一般型与谨慎型和激进型均有交叉,谨慎型与激进型基本无交叉,主要原因有:驾驶员的驾驶风格受交通环境、道路条件等环境因素影响会发生迁移;有些驾驶员在不同工况下体现出的风格不同,导致某一工况的风格识别结果与总体风格标签即专家主观标签不一致。总体看,K均值法用于换道工况驾驶风格识别的精度在可接受范围内。
完成同一工况不同识别结果的融合后,得到该工况下驾驶员驾驶风格识别结果。同理,利用D-S证据理论对其他新进工况的识别结果与历史识别结果融合,更新每个工况的风格识别结果。
由于工况数量有限且每个工况由一条识别结果代表,鉴于工况数据有限以及驾驶员风格在不同工况下具有一定倾向性的特点,选择投票法融合不同工况下的驾驶风格识别结果。投票法是最常见、最简单的决策融合算法,统计各个工况识别结果出现的频数,出现频数最多的识别结果即是此驾驶员对应的总体驾驶风格。
采用投票法将多种工况的风格识别结果进行融合,融合结果与人工标签对比结果如表2所示。

表2 不同工况投票法融合结果与专家主观标签对比 名
由表2可知,不同工况的融合结果与专家主观标签的对比结果较表1好,印证了前文驾驶员在不同工况下体现的风格存在差异,激进型驾驶员不是在所有工况下都激进驾驶的分析。驾驶风格识别关注识别结果的查准率,即正确地识别每一种类型,不关注误判率,谨慎型查准率为16/(16+4+0)=80%,一般型查准率为38/(38+6+4)=79.2%,激进型查准率为10/(10+2)=83.3%。
由此可见,本文建立的由聚类模型和决策融合模型组成的风格识别模型查准率较高,能够满足驾驶风格识别研究的需求。
5 结束语
基于驾驶风格数据库,首先利用工况辨识逻辑提取特征数据段,然后利用统计学方法、特征选择和提取方法提取特征,最后用K均值方法聚类,并对聚类结果进行D-S证据理论融合,得到单一工况的风格识别结果。按照此思路,得到其他工况的风格识别结果,最终利用投票法得到最终的风格识别结果,经过验证,本文开发的驾驶风格识别模型查准率达到80%。
后续研究将利用本文建立的驾驶风格识别模型分析160位用户体验数据的驾驶风格,进一步改进识别模型,并利用该模型处理用户通过T-Box上传至云平台的数据,分析其驾驶风格,为驾驶员驾驶行为、驾驶行为保险(Usage Based Insurance,UBI)等研究提供依据。
