改进超分辨率卷积神经网络和字典学习的图像超分辨率重构算法
2018-10-26张海涛
张海涛,赵 燚
(辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105)
1 引 言
图像超分辨率(Super-Resolution,SR)重构的目标是根据输入的一幅或者多幅低分辨率(Low-Resolution,LR)图像来估计高分辨率(High-Resolution,HR)图像.从本质上说,由于在图像降质过程中的信息丢失,这些降质过程基本上都是不可逆的,因此图像超分辨率重构是一个不适定问题.
目前,单帧图像超分辨率重构(Single Image Super-Resolution,SISR)可分为三大类:基于插值的方法[1-4]、基于重构的方法[5-8]和基于学习的方法[9-16].在早期研究中最常使用图像插值法,根据低分辨率图像的局部统计信息和空间关系来估计高分辨率图像.典型的图像插值方法包括二次线性插值法(Bilinear)、二次立方插值法(Bicubic)和边缘定向插值法(Edge Directed).但是,基于插值的图像超分辨率算法更倾向于将图片处理得平滑.基于重构的方法是利用信号处理技术来求解成像系统的逆过程,进而得到高分辨率图像,但是其运算较为复杂.基于学习的图像超分辨率重构算法由于具有较好的超分辨率重构质量成为近几年的研究热点,其主要思想是通过一个包含高、低分辨率图像的外部数据集学习得到先验知识,这种先验知识通常是低分辨率图像与其对应的高分辨率图像之间的映射关系,从而在给定低分辨率图像的情况下,通过优化方法获得相应的高分辨率图像.Chang等人提出基于局部线性嵌入的邻域嵌入方法[9](Neighbor Embedding with Locally Linear Embedding,NE+LLE),该方法假设低分辨图像块与高分辨图像块组成的两个流形空间具有相似的局部几何结构,根据这种假设,将低分辨输入图像块与训练集中的K近邻之间的重构关系,映射到对应的高分辨图像块上,合成需要的高分辨图像.Yang等人提出基于稀疏表示的图像超分辨率重构算法[10](Image super-resolution via sparse representation,ScSR),该方法假设高、低分辨率图像信号之间的线性关系可以通过低维投影精确表示出来,根据这个假设,先通过训练集学习到高、低分辨率之间的先验知识,称为字典,对于输入的低分辨率图像根据低分辨率图像字典求取其稀疏性系数矩阵,再通过稀疏性系数矩阵和高分辨率图像字典重构高分辨率图像.Timofte等人基于NE+LLE和ScSR提出了锚定邻域回归[11](Anchored Neighborhood Regression,ANR),改善了算法时间效率的问题.首先,使用与字典原子的相关性而不是欧式距离来计算最近的邻域;第二,使用全局协同编码能带来可观的计算提速,将超分辨率映射简化到预计算的投影矩阵;第三,提出了锚定邻域回归,将低分辨率图像块的邻域嵌入到字典中最近的原子,并预先计算相应的嵌入矩阵.
近年来,深度学习在图像处理以及计算机视觉领域中异常火热,出现大量基于深度学习图像超额分辨率算法.其中Gao等人提出了基于深度受限玻尔兹曼机[12](Restricted Boltzmann machine,RBM)的图像超分辨率重构算法,使用深度受限玻尔兹曼机学习高、低分辨率图像之间共享的稀疏表示系数.Cui等人提出深度网络级联[13](Deep Network Cascade,DNC)的思想,DNC是级联的多个协同局部自编码器,在级联的每个层中,首先进行非局部自相似搜索,以增强输入图像块的高频纹理细节,然后将增强的图像块输入到协同局部自编码器中,生成高分辨率图像块.Dong等人提出了基于卷积神经网络的图像超分辨率重构算法[14](Super-Resolution Convolutional Neural Network,SRCNN),首先利用3层卷积神经网络学习得到有效的高、低分辨率图像块之非线性映射关系,然后根据这种映射关系将输入的低分辨率重构为高分辨率图像.Ledig等人提出基于对抗生成网络的图像超分辨率重构算法[15](Super-Resolution Using a Generative Adversarial Network,SRGAN),该算法取得了较好的视觉效果,但是客观评价指标却低于其他算法,其细节部分虽然在视觉上更清晰,但是与原始高分辨率图像有较大差距.
虽然基于学习的图像超分辨率重构算法可以利用学习到的高、低分辨率图像之间的先验知识将低分辨率图像重构为高分辨率图像,但这种方法在图像细节的恢复上还有待加强.本文在SRCNN的基础上在网络层数、卷积核大小、卷积核数量以及激活函数的选取上进行改进并结合传统学习方法中的字典学习方法对原始高分辨率图像与改进SRCNN网络重构图像之间的残差进行学习,并对SRCNN重构图像中缺少的残差部分的高频信息进行补偿,以取得更好的图像超分辨率重构效果.
2 基于超分辨率卷积神经网络的图像超分辨率重构
2.1 卷积神经网络简介
卷积神经网络(Convolutional Neural Network,CNN)是最近几年发展起来并受到高度重视的一种前馈神经网络.CNN的二维拓扑结构专门针对具有类似网络结构的数据设计的,例如时间序列数据或者图像数据等.因此,多维图像可以直接作为网络的输入,避免传统算法中对图像复杂的预处理、特征提取等过程.CNN的非全连接、权值共享和局部感受野的特性在图像处理方面有其独特的优越性,减少了网络训练所需的参数,降低了网络复杂性,并且这种特性对于位移、比例缩放和旋转等形式的变形具有高度不变性.所以CNN在图像处理中得到广泛应用.
CNN是一个多层神经网络,其每层都由一组二维平面构成,且每个平面包含多个独立神经元.CNN的层级结构一般包含卷积层、激励层、池化层和全连接层.卷积层的作用是对输入数据进行特征提取.激励层通过激励函数添加非线性因素,将线性映射转化成非线性映射,因为通常每个卷积层后都连接激励层,所以常把连接的卷积层和激励层视为一层卷积层对待.池化层对卷积层得到特征进行降采样提取局部敏感特征,一方面将特征压缩降低网络计算复杂性,另一方面进行特征压缩提取主要特征.全连接层将前面获取到的局部特征汇总为全局特征,并且最后的全连接层作为输出层执行分类或回归等任务.CNN通常在一个或几个卷积层后会连接一个池化层,进而级联成深度神经网络,最后由全连接层输出.经典的卷积神经网络LeNet-5结构如图1所示.
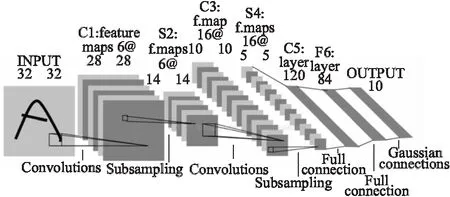
图1 LeNet-5 网络结构Fig.1 LeNet-5 network structure
2.2 基于超分辨率卷积神经网络的图像超分辨率重构模型
作为一种基于学习的单帧图像超分辨率算法,超分辨卷积神经网络(Super-Resolution Convolutional Neural Network,SRCNN)旨在学习一个以低分辨率图像为输入,高分辨率图像为输出的端到端的非线性映射.这里将原始高分辨率图像设为X,将X降采样后用Bicubic插值恢复到与X相同大小的低分辨图像设为Y,通过SRCNN学习到的非线性映射关系设为F,使得F(X)与原始超分辨率图像X尽可能相似.SRCNN网络结构包含3个卷积层,相当于一个全卷积神经网络.由于超分辨率重构需要更好的保存图像特征信息并且其输出也是不需要降维的完整图像,因此不需要池化层和全连接层.前两层使用激励函数为ReLu(Rectified Linear Unit),最后一层不使用激励函数.ReLu函数公式如下:
y=max (0,x)
(1)
SRCNN这3个卷积层,每个层负责特定的任务,分别于传统的SISR算法中三个过程相对应:
图像块提取和表示:该操作从低分辨率图像Y中提取多个特征块,并将每个特征块表示为高维度向量,这些向量构成第一层的特征图.
非线性映射:这个操作是非线性地将来自第一层的每个高维向量映射到另一个高维向量上.每个映射向量都是一个高分辨率图像块的表示.这些映射向量构成了第二层的特征图.
重构:这个操作集合了上一层的高分辨率图像块,来生成最终的高分辨率图像.这幅图像与原始高分辨率图像X近似.
上述操作在网络中的位置以及SRCNN整体网络结构如图2所示.接下来详细介绍每层的具体操作.
特征块提取和表示阶段:在传统算法中这一步骤通常使用PCA、DCT等操作来表示它们,这相当于通过一组卷积核对图像进行卷积,而这些卷积核是由人们设定好的模板.在SRCNN中将这些模板加入到网络优化中,由网络训练得到,设本层操作为F1:
F1(Y)=max (0,W1×Y+B1)
(2)
其中,W1表示大小为c×f1×f1×n1的卷积核,c表示输入的低分辨率图像的通道数,f1表示卷积核的尺寸,n1表示卷积核的个数.B1表示维度n1为偏置向量.

图2 SRCNN网络结构Fig.2 SRCNN network structure
非线性映射阶段:在上一层对每个图像块提取到一个n1维的特征图.在本层中将这n1维特征图非线性映射为n2维的特征图.设本层操作为F2:
F2(Y)=max (0,W2×F1(Y)+B2)
(3)
其中,W2表示大小为n1×1×1×n2的卷积核,n1表示第一层特征图维度,n2表示第二层特征图维度.B2表示维度n2为偏置向量.
重构:通过求取重叠图像块的平均值来生成最终的高分辨率图像.求取平均值也可视为使用卷积核对图像进行卷积.因此,设本层操作为F3:
F3(Y)=W3×F2(Y)+B3
(4)
其中,W3表示大小为n2×f3×f3×c的卷积核,n2表示第二层特征图维度,f3表示卷积核尺寸,c表示输出的高分辨率图像的通道数.B3表示维度c为偏置向量.由于求取平均值的操作是一种线性操作,因此本层并未使用激活函数增加其非线性因素.
2.3 对超分辨率卷积神经网络的改进
SRCNN网络的三层结构,第一层选择卷积核尺寸f1为9,卷积核个数n1为64;第二层选择卷积核尺寸为1,卷积核个数n2为32;第三层选择卷积核尺寸f3为5,卷积核个数等于输出图像通道数,即9-1-5的网络结构.这种网络结构在实际使用中,在网络训练阶段存在损失函数收敛速度差的情况.为使SRCNN网络达到更好的重构效果,本文从网络层数、卷积核尺寸与数量以及激活函数的选择上对网络进行改进,优化网络的超分辨率重构效果.
深度学习方法一般情况下优于传统机器学习方法,因为深度学习通常具有更深的网络层次结构,对于深度学习来说,这些更深网络层次结构可以提供更多可供训练学习的参数,因此得到的效果往往更好.对于CNN在SISR上的应用,三层卷积的神经网络也许不是最优方案.参考AlexNet[17]、VGGNet[18]和GoogleNet[19]等网络结构,它们层数已经达到十几层甚至几十层之多.因此,我们也可以通过增加CNN的层次来提高图像超分辨率重构效果.但通常上述网络针对的是分类任务,在网络中存在多个池化层,通过对特征压缩从而降低网络计算复杂度.对于SRCNN使用的全卷积神经网络,过高的层数意味着有更多参数需要训练学习,无疑增大了训练时间.通过实验,增加卷积层数到4层的网络模型是可行的,训练时间可以接受.如果继续增加层数,训练网络所花费的时间代价较高,因此,我们选择4层的卷积神经网络来进行图像超分辨率.
加深卷积神经网络的方法除了增加层数,也可以通过增加卷积层卷积核的个数、卷积核的尺寸等方法.由于CNN是深度学习领域中一个著名的“黑盒”模型,各参数均由网络训练迭代优化而来.因此,SRCNN的3层与传统SISR的3个步骤并非完全对应.由于,SRCNN的第一层和第二层都使用了激活函数增加非线性因素,非线性映射并不仅仅针对第二层,而是通过每层的激活函数逐步进行的,因此,SRCNN在第二层只使用较少参数的1×1卷积核仅仅是为了非线性映射而降低了对于特征进一步提取的能力.我们可以增大第二层的卷积核尺寸,在我们的4层卷积神经网络中,每层卷积核尺寸分别为9×9、7×7、7×7和5×5,即9-7-7-5的网络结构.在卷积核数量上,为了使提取到的特征逐步整合为高分辨率图像,参考SRCNN逐步递减的方式,每层卷积核数量分别为64、32、16和c,c表示输出高分辨率图像的通道数.
在激活函数的选择上,我们使用比ReLu更好的PReLu[20](Parametric Rectified Linear Unit)作为激活函数,PReLu即带参数的ReLu,函数公式如下:
y=max(0,x)-α×min(0,x)
(5)
其中,α参数可由网络训练获得.使用PReLu作为激活函数的优点是,仅仅增加了少量的参数,便可达到更好的效果,同时网络的计算复杂性和网络过拟合的危险性仅仅小幅度增加.
修改后的网络各层操作分别为F1、F2、F3和F4,其公式如下:
F1(Y)=max(0,W1×Y+B1)+α1×min (0,W1×Y+B1)
(6)
F2(Y)=max(0,W2×F1(Y)+B2)+α2×min(0,W2×F1(Y)+B2)
(7)
F3(Y)=max(0,W3×F2(Y)+B3)+α3×min(0,W3×F2(Y)+B3)
(8)
F4(Y)=W4×F3(Y)+B4
(9)
其中,W1、W2、W3和W4分别表示大小为c×f1×f1×n1、n1×f2×f2×n2、n2×f3×f3×n3和n3×f4×f4×c的卷积核,c表示输入的低分辨率图像的通道数,f1、f2、f3和f4表示各层卷积核的尺寸,n1、n2和n3表示各前三层卷积核的个数.B1、B2、B3和B4表示各层偏置向量,α1、α1和α3表示前三层中非线性映射参数.
根据上文网络结构,学习端到端的映射函数F所需要的网络参数为θ={W1,W2,W3,W4,B1,B2,B3,B4,α1,α2,α3},通过随机梯度下降法与反向传播法[21](Back-Propagation,BP)优化参数,使重构图像F(Y,θ)和其对应的原始高分辨率图像之间的损失函数达到最小值,此时的参数即为所需的参数.给定一组高分辨率图像集{Xi}和一组与之对应的降质后的低分辨率图像集{Yi},损失函数选择均方误差(MSE),其公如下:
(10)
其中,n为训练样本个数.
3 基于字典学习的残差补偿
3.1 字典学习
字典学习[22](Dictionary Learning)也可称为稀疏表示(Sparse Representation).在稀疏表示方面的成就表明,高维信号之间的线性关系可以从其低维度投影中准确地恢复.其基本原理为,自然图像可以视为稀疏信号,当用一组过完备字典线性表达出输入信号时,在满足一定稀疏度的情况下,展开系数可以获得对原始输入信号的良好近似.该方法在图像复原与超分辨重构以及图像降噪中取得良好表现.通过矩阵分解的角度看待字典学习的过程:给定样本数据集X={x1,x2,…,xn},字典学习的目标是把X矩阵分解为D、Z矩阵:
X≈D·Z
(11)
其中,D={d1,d2,…,dK}称之为字典,D的每一列dk称之为原子,同时D的每一个原子都是一个归一化向量.Z={z1,z2,…,zn}称对应稀疏表示的系数矩阵,同时X要求尽可能稀疏.字典学习优化问题的目标函数可以表示为:
(12)
其中,X表示训练数据集,D表示学习的字典,Z为所对应稀疏表示系数矩阵.但是由于这种表示中l0正则项难以求解,所以很多时候使用l1正则项近似替代.因为目标函数中存在两个未知变量D、Z,构造字典的算法通常分为稀疏表示和字典更新两个步步骤.
稀疏表示:首先设定一个初始化的字典,用该字典对给定数据进行稀疏表示,得到系数矩阵Z.di表示字典D的列向量,zi表示稀疏表示系数矩阵Z的行向量.即:
(13)
字典更新:初始字典通常不是最优的,满足稀疏性的系数矩阵表示的数据和原数据会有较大误差,我们需要在满足稀疏度的条件下逐行逐列对字典进行更新优化,减小整体误差,逼近可使用的字典.忽略字典中第k项dk的影响,计算当前稀疏表示误差矩阵:
(14)

(15)
3.2 基于字典学习对改进超分辨率卷积神经网络模型的残差补偿
在本文中,针对残差图像的字典学习优化模型如下:
(16)
由于该字典学习方法有益于高频信息的恢复,本文将卷积神经网络与字典学习相结合,应用于图像超分辨率重构中,本文方法总体框架如图3所示.

图3 本文方法总体框架图Fig.3 Overall framework of proposed method

4 实验及分析
4.1 实验设置
本文的实验环境:CPU为Intel(R) Core(TM) i5-7500 CPU @ 3.40GHz;GPU为NVIDIA GeForce GTX 1060 6GB;内存为8GB;操作系统为Ubuntu 16.04 LTS.其中卷积神经网络的训练在深度学习框架Caffe上实现,其他部分均在Matlab 2017a平台上完成.
在数据集的选取上,训练集选择与SRCNN相同的Timofte数据集(包含91幅自然图像),测试集选择在图像超分辨率重构领域中常用的两个数据集Set5与Set14,分别包含5张图像与14张图像.在数据集处理上,本文使用与通常的SISR研究中相同的方法获取低分辨率图像,即对原始高分辨率图像进行降采样至其1/k之后,再使用Bicubic插值方法放大k倍,得到与原始高分辨率图像相同尺寸的低分辨率图像.在使用卷积神经网络和字典学习训练图像超分辨率重构模型时,输入数据为高、低分辨率图像块.在卷积神经网络中以步长为10像素的滑动窗口在图像上截取大小20×20像素的具有重叠区域的图像块.由于卷积神经网络中的卷积核大小影响,导致输出图像小于输入图像,因此要对低分辨率图像块进行填充,填充后大小为38×38像素.在字典学习中,直接将CNN重构图像与残差图像分解成9×9的图像块.
本文使用YCbCr颜色空间,由于大多数图像超分辨率算法都是对YCbCr颜色空间中的亮度分量(Y)敏感,通常是将图像转换到YCbCr颜色空间,对Y分量进行图像超分辨率重构后在与原Cb、Cr分量合并得到重构的高分辨率图像.因此,本文在实验过程中仅考虑Y分量的单通道,但本文也适用多通道.
考虑到单通道,本文卷积神经网络模型中各项参数为:c=1,n1=64,f1=9,n2=32,f2=7,n3=16,f3=7,f4=5,基础学习率为0.0001.在字典学习中,原子个数为500.
4.2 实验结果与分析
为验证本文算法效果,在对比实验中,选取如下算法作为对比算法:图像超分辨率重构中的经典算法以及多数图像超分辨重构算法的预处理算法Bicubic插值算法;基于稀疏表示的图像超分辨率重构算法中的经典算法ScSR[10];结合邻域嵌入与局部线性嵌入的基于外部样例学习的图像超分辨率重构算法NE+LLE[9];结合了稀疏表示与邻域嵌入的基于外部样例学习的图像超分辨率重构算法ANR[11];以及本文的第一阶段原型算法,使用深度学习模型中卷积神经网络的SRCNN[14].
客观评价效果:按照图像超分辨率重构领域中常用实验方法,将上述算法同本文算法分别在放大系数k为2、3、4倍进行对比,主要客观评价指标为峰值信噪比(Peak Signal to Noise Ratio,PSNR),次要客观评价指标为结构相似性(structural similarity,SSIM).由于篇幅所限,仅在Set5数据集上放大系数为3倍的图像超分辨率重构中将将每张图像的PSNR评价指标列出,其他不同倍数、不同评价指标的对比将按照数据集,以该数据集图像的平均值做对比.实验结果如表1、表2和表3所示.
表1 Set5上PSNR对比结果(k=3)
Table 1 PSNR contrast results on Set5 (k=3)
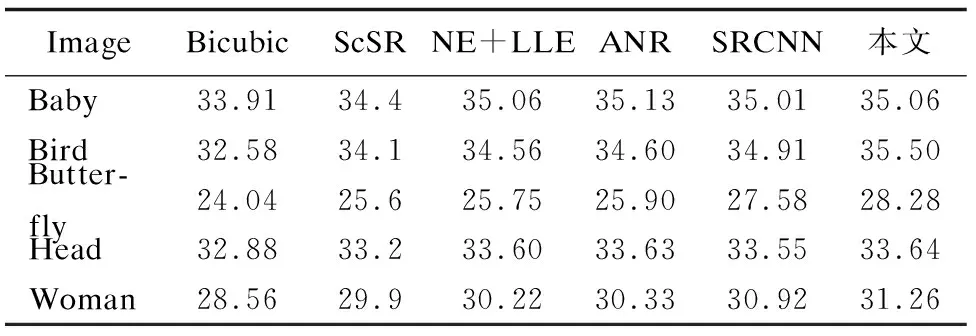
ImageBicubicScSRNE+LLEANRSRCNN本文Baby33.9134.435.0635.1335.0135.06Bird32.5834.134.5634.6034.9135.50Butter-fly24.0425.625.7525.9027.5828.28Head32.8833.233.6033.6333.5533.64Woman28.5629.930.2230.3330.9231.26
对比上述客观评价实验数据,本文算法取得了较高的PSNR与SSIM的平均值,
对比SRCNN大部分图像均有所提
表2 Set5上不同放大系数的PSNR与SSIM均值对比结果
Table 2 Comparison of PSNR and SSIM mean of different
amplification coefficients on Set5

kBicubicScSRNE+LLEANRSRCNN本文PSNR233.66-35.7735.8336.3436.53330.3931.4431.8431.9232.3932.75428.42-29.6129.6930.0830.36SSIM20.929-0.9490.9490.9520.95330.8680.8820.8950.8960.9000.90940.801-0.8400.8410.8520.860
升,但是在部分图像上提升并不明显,如Set5上的baby图像.这是因为一些图像纹理精细、细节微小,在降采样之后损失大量有效信息,以至于重构效果提升不明显,
下文主观对比
表3 Set14上不同放大系数的PSNR与SSIM均值对比结果
Table 3 Comparison of PSNR and SSIM mean of different
amplification coefficients on Set14
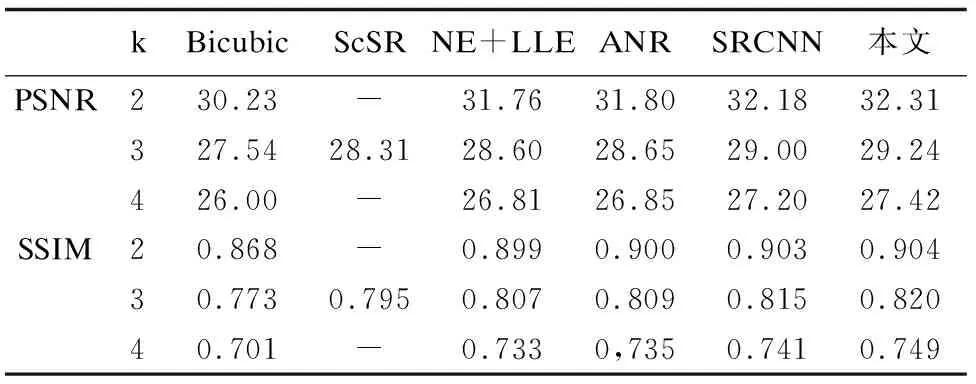
kBicubicScSRNE+LLEANRSRCNN本文PSNR230.23-31.7631.8032.1832.31327.5428.3128.6028.6529.0029.24426.00-26.8126.8527.2027.42SSIM20.868-0.8990.9000.9030.90430.7730.7950.8070.8090.8150.82040.701-0.7330,7350.7410.749
中bird图像,鸟眼内部瞳光的还原没有得到较好改进也是这个原因.而对比不同放大系数k的实验数据可以发现,在放大系数k为较大倍数(2、3)时,PSNR值和SSIM值提升比放大系数k为较小倍数时明显,这是因为将原始图像降采样到其1/2时,其图像信息保存相对较完整,大部分图像超分辨率算法均可以较好的对其进行重构,残差相对较小,而本文中的字典学习方法是针对残差图像进行学习的,在使用字典学习方法进一步对残差中的高频分量进行补偿时,可能会引入一些不必要的冗余信息,因此,限制了其分辨率重构效果.
主观评价效果:将本文算法得到的超分辨率重构图像同上述其他算法得到超分辨率重构图像进行对比,选取放大系数k=3上的三张图像进行主观对比,结果如图4、图5以及图6所示.
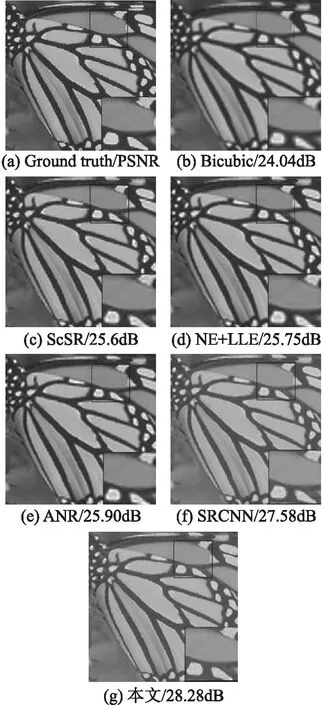
图4 butterfly图像主观对比结果Fig.4 Subjective contrast results of butterfly images
图4展现了不同算法在butterfly图像上的放大3倍的超分辨率重构与结果,从放大区域可以看出,本文算法对该图像超分辨率重构效果较好,在边缘等细节上的重构效果要好于其他算法,更加接近原始高分辨率图像,同时图像中黑色部分噪声较少,更为纯净.而传统算法的结果图中可以看出边缘较为模糊.
图5展现了不同算法在bird图像上放大3倍的超分辨率重构与结果,从放大区域可以看出,虽然本文算法的超分辨率重构效果及边缘上的表现都好于其他算法,如鸟嘴边缘的黑色羽毛处的重构,但是对比本文算法结果图与原始高分辨率图像,在鸟眼内部的细节还原上还欠佳,同其他算法一样鸟眼内部的瞳光并未得到还原.
图6展现了不同算法在lenna图像上放大3倍的超分辨率重构与结果,通过放大图像中的帽檐边缘可以看出,本文算法得到的结果图像边缘更加锐利,更接近原始高分辨率图像.

图5 bird图像主观对比结果Fig.5 Subjective contrast results of bird images
在时间效率方面,对比算法中只有SRCNN与本文算法是深度算法,与其他非深度算法对比训练时间效率意义不大,因为在使用训练好的模型时只需执行一次.深度算法需要花费大量时间训练,SRCNN与本文算法通常训练需要迭代100万次能得到理想结果.在输入图像块大小均为38×38,使用相同的GPU环境下训练,每进行100次迭代,SRCNN花费时间平均为1.8s,本文算法花费时间平均为3.2s,因此每次迭代相差0.014s,以迭代100万次为训练完成计算,本文算法在训练阶段比SRCNN需多花约4小时.在使用模型进行重建时,将本文算法与其他对比算法在Set5数据集上相同CPU环境下运行时间进行对比,如表4所示.本文算法要快于ScSR,略慢与SRCNN.其中Bicubic为其他算法基础操作且运行速度约为0.01s.
通过上文主观以及客观的评价效果,与传统算法相比本文算法效果提升明显,表明卷积神经网络可以学习到有效的高、低分辨率图像之间的映射关系.同时与SRCNN相比,本文也取得了效果上的提升,表明基于字典学习的残差补偿方法能补偿SRCNN中未能恢复的高频信息,但时间成本也会因此增加.本文所提出的基于改进SRCNN和字典学习的算法能恢复更为丰富的细节信息和分明的图像边缘,得到视觉效果更好的超分辨率重构图像.

图6 lenna图像主观对比结果Fig.6 Subjective contrast results of lenna images

ImageBicubicScSRNE+LLEANRSRCNN本文Baby0.0s24.6s7.4s1.0s13.6s15.7sBird0.0s7.3s2.4s0.3s3.3s4.1sButter-fly0.0s5.7s1.9s0.3s2.3s4.6sHead0.0s8.6s2.2s0.3s2.4s4.4sWoman0.0s7.8s2.1s0.3s2.4s4.2s
5 结束语
本文提出了一种基于改进SRCNN和字典学习的图像超分辨率重构算法,该算法在超分辨率卷积神经网络的基础上,对其网络结构进行改进,并针对原始高分辨率图像与SRCNN输出的重构图像的残差采用传统的字典学习方法进行学习,实现了高频信息补偿,具有较优的视觉效果及客观评价指标.在图像超分辨率的图像质量上,本文算法取得了一定研究成果,对比SRCNN在Set5和Set14测试集上平均PSNR分别提升了0.36dB和0.24dB,但在网络训练时会消费较多时间,因此本文下一步将在保证图像质量的前提下研究如何提升算法的时间效率.
