云环境下性能监测数据预处理方法研究
2018-10-26吕依蓉喻之斌张伟功
孙 斌,吕依蓉,王 晶,喻之斌,张伟功
1(首都师范大学 信息工程学院, 北京 100048)2(中科院深圳先进技术研究院 云计算中心, 深圳 518055)
1 引 言
随着云计算技术的发展,越来越多的应用服务运行在云平台上.因此,数据中心的规模和数量正以前所未有的速度增长.例如,仓库级计算机(Warehouse Scale Computer)越来越普遍.然而,大规模的云计算基础设施对运维造成了严峻挑战,需要新的监控与运维技术[1].当前数据中心所呈现出应用多样化和硬件平台异构[2]两个特点加大了性能监控和优化的难度,使得云环境下的性能监控变得尤为重要.和系统层的性能监控相比[3,4],如利用CPU利用率、内存利用率、以及磁盘利用率等,PMU(Performance Monitoring Unit)下硬件性能事件的计数结果能够更细粒度、更直接地反映机器的实际运行状况[2,5].
现代处理器中一般有2~8个性能计数器(寄存器),用来记录处理器在运行时发生的硬件事件,如内存访问次数、高速缓存的缺失次数等[6,7].为了节约芯片面积乃至成本,处理器中不能设计更多的性能计数器.为了深入理解程序的运行行为和优化性能,需要监测的事件数目却远远大于性能计数器的数目,而且仍在呈增长趋势[6,7].
由于数据中心中微量的性能提升都可以转化成巨大的成本节约,许多研究人员在研究如何利用PMU的监测结果来优化性能[2,5,8,9].从需要监测的性能事件到性能计数器之间的映射有两种方式:
1) 监测的性能事件数目小于或等于计数器个数;
2) 监测的性能事件数目多于计数器个数.
第一种方式可获得准确的监测结果[10],但受限于性能技术器的个数以及实际需求,需要进行多次重复实验才能得到所需全部事件的结果,因此,这种方式效率很低.此外,如图1所示,在云环境下同一程序多次运行的执行时间会有较大波动,得到不等长的时间序列结果,大大提高了后续分析难度.第二

图1 相同程序多次采集结果时间序列比较Fig.1 Compare the multi-result of sampling
种方式可以极大地提升监测效率,在一般需求下[2,5]可避免重复监测工作.然而,此方法会降低监测数据的测数据质量,如数据缺失,表现为未能有效监测到已发生事件而产生的零值,再如数据异常,表现为时序中存在突然数据增大的时刻,与同组中其他数据的偏差超过多倍标准差.而且监测事件数目越多数据质量越低[10,11-13].为了既能提高监测效率,又能提高监测数据的质量,对第二种方式中所存在的问题进行改进刻不容缓.考虑到服务器中处理器架构的不同,软件计算框架的差异以及应用本身的不同,本文提出基于知识库的数据预处理方法,来应对不同情况下的缺失值和异常值.
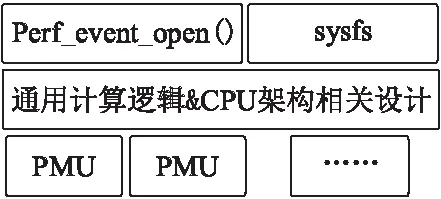
图2 Perf_events 子系统架构图Fig.2 Perf_events architecture
对于缺失值,根据知识库内相似监测任务下的数据,即对相同的运行环境,相同计算框架下应用的监测任务,监测事件可以不同但要包含缺失值所对应的事件,并结合当前监测数据中的未缺失项,构建回归模型,补全缺失数据.
对于异常值,根据知识库内的相似监测任务的监测数据,配置局部滤波器参数,使得滤波器可以自适应的检测不同事件结果中的异常值,并对其处理.
本文所提出的数据预处理方法,可以在提升2-5倍监测效率的同时极大地提升数据质量.
2 相关工作
2.1 性能计数器
现代处理器中一般都配有性能监测单元(PMU),它由两部分组成:硬件性能事件和性能计数器.性能计数器用来测量微体系结构中如程序执行所消耗的时钟周期数,指令数和高速缓存缺失数等硬件性能事件[6,7],其结果可直接反应程序执行过程中硬件的执行情况,从而可分析程序对硬件资源的使用情况.PMU的监测结果具有广泛的应用场景,如科学应用程序的性能建模[14,15]、生产环境中程序行为的异常检测以及诊断[9,16,17]、安全漏洞监测、编译过程中的配置优化、以及功耗优化模型.此外,它对未来的硬件设计工作也有极大的帮助,比如在监测Google数据中心应用过程中发现指令地址转换检测缓冲缺失(iTLB MISS)比较大[2],则未来可以考虑为云环境下的硬件设计增加iTLB的大小.
2.1.1 PMU的硬件结构
现代处理器中一般有2~8个性能计数器(寄存器).如Intel Xeon E5 v3系列处理器是基于Haswell-E的微体系结构生产的,它配备2个专用的性能计数器和4个通用的性能计数器,可监测事件超过200个[6].其中专用的性能计数器只能分别监测未被停顿的时钟周期数(Unhalted Cycles)和成功被执行的指令数(Instruction Retired)这两个事件,通用计数器可配置监测其余所有事件.性能计 数器本质上是一个特殊寄存器(MSR),用来记录某事件的发生次数.不同系列的处理器所拥有的性能计数器个数是不同的,而且所能支持监测的硬件事件种类也不尽相同,但共同点在于所有的处理器结构中性能计数器个数要远小于可监测的事件数.

图3 结果中缺失值(a)和异常值(b)的示意图
Fig.3 Pattern of missing values(a) and outliers (b)
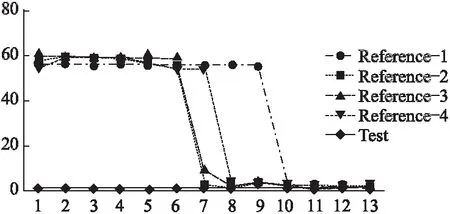
图4 监测ICACHE.MISSES缺失部分与参考值的比较
Fig.4 Compare the missing part and reference data of the sampling data of the ICACHE.MISSES
2.1.2 应用PMU
在Linux操作系统中,Perf_events1内核接口作为一个通用、高层级的接口来驱使性能计数器完成监测任务,而且在Linux 2.6.31之后便被添加到了官方的内核之中.监测系统架构如图2所示,Perf_event_open( )是一个系统调用,sysfs是一个文件系统,用来简化事件命名以及工具配置,中间层则包括通用的核心计算逻辑设计以及应对不同处理器架构的通用接口层设计.
目前,Perf1和Oprofile2是较为流行的性能监测工具,都调用了Perf_events (接口).在应用中只需提前传递待测事件即可.事件的调度贯穿整个监测过程,包括绑定计数器和通过触发机制输出记录结果,当待测事件数量多于实际计数器数量时,内核通过时分复用计数器来保证每一个待测事件都有机会被监测到.在复用过程中会采取轮询的方式并假设事件的发生速率是相同的.事件结果的计算方式如公式(1),按照事件被分配到的比例以及计数值推测整个时间段内的计数结果.

(1)
事件调度能保证最大限度地利用计数器,尽量减少复用带来的开销,但不能保证监测结果的准确性.而且部分事件有特定的计数器限制,容易造成事件调度过程中的事件冲突[6],加剧了监测结果种的不准确性.

表1 参考记录和复用PMU时记录的数据比较Table 1 comparing reference data and the data sampling with multiplex PMU
2.2 云环境下应用PMU的效率和质量
如在2.1中所提到的,性能监测单元为程序特征描述所带来的作用无可替代.许多性能优化工作以此为根据,在云环境下的程序特征描述和性能优化工作中都取得了明显的效果[2,5,8,17].然而这些工作在应用基于PMU的监测工具时,受到性能计数器个数的限制,为保证监测结果的准确率都采用了相对保守的监测手段,即每一次监测事件时保证所监测的事件数不大于性能计数器个数.这种方式虽然能保证监测结果的准确性[10],但需要通过重复运行的方式来获得更多的监测结果,大大降低了监测效率.
硬件性能事件结果与性能之间的语义鸿沟一直是研究的难点,尤其要在繁多的事件中有针对地选择出一部分参与监测更是极具挑战[16],极端情况下需要所有事件的监测结果,这只能通过重复运行的方式遍历监测所有事件.如果实验环境中的处理器是上述的Intel Xeon E5 v3系列,需要以4个性能计数器、2个专用计数器来应对超过200个事件,则重复运行次数超过50次.而且在重复运行监测的结果中还会遇到相同程序不同次运行执行时间不等长的问题.例如,在云环境下同时分发多个任务,执行时间取决于最后一个执行完的任务.图1是对相同程序重复监测下多个不等长的时间序列的示意图,而且本文实验的基准测试程序HiBench[18]中的同一应用程序的执行时间表现出了3.3%-16.4%的波动.
一些学者的工作聚焦于提升复用性能计数器复用(multiplexing)情况下的监测准确率.比如通过量化错误来改进公式1,以获得较高的准确率[12].也有学者通过事件的变化率来改进公式1[13]以及通过改进调度方式来提高准确率[11]等.这些研究确实缓解了PMU在应用中的问题,然而在实际应用中仍有监测结果过调节(异常值)以及缺失监测结果的现象存在,图3(a)和图3(b)分别是时间序列中异常值和缺失值得示意图.实验结果表明,虽然异常值与缺失值的数量在全部数据中不超过1%,但它们对时间序列的特征描述造成了很大影响.例如,对时间序列正则化和方差计算带来巨大的偏差,而且由于硬件事件的计数结果一般没有严格的值域范围,难以界定缺失异常的阈值.通过反复监测Wordcount运行时ICACHE.MISSES事件的表现,在复用和不要复用硬件计数器的情况下,监测结果得出了不同的数据描述,如表1中Reference(1-4)是在不复用性能计数器时的数据描述,Test则是在复用性能计数器是而得到的数据描述,图4是对ICACHE.MISSES这个事件在复用性能计数器和不复用性能计数器下的时间序列(这里只比较了缺失部分的数据)比较.而且根据表1可知,借助参考记录可判别0值数据即为缺失记录.
3 基于知识库的数据预处理方法(KBDP)
为了提高PMU的监测效率,并保证监测数据的质量,提出一种基于知识库的预处理方法,如图5所示.每一次的监测结果都会结合历史监测数据来完成异常值和缺失值检测,并以他们为参考来替换异常值以及补充缺失值.这里所提到的历史监测数据主要指利用相同事件监测同一应用所产生的监测数据.对于异常值:本文设计了一个自适应的局部滤波器,自动判断异常值并对其进行处理.对于缺失值:将结合历史数据以及当前数据中未缺失部分构建回归模型,并利用该模型补充缺失值.

图5 预处理方法示意图Fig.5 Schematic of preprocessing method
如上文所述,由于硬件事件的监测结果一般没有确定的值域,使得对异常值和缺失值的判断极其困难.而且监测数据表明异常值和缺失的出现并没有确定的模式,相同事件在不同应用下的监测结果也有区别,这与程序表现密切相关.本文通过比较不等长序列间的相似性,计算经过动态时间归准(DTW)之后的曲线间的距离来判断事件监测结果的相似性.DTW是一种通过弯曲时间轴来更好地对时间序列形态进行匹配的相似性度量方法,被Bernd和Clliford用于度量时间序列的相似性[19].本文以历史数据的结果作为参考来判断异常和缺失现象.对比相同程序在不同输入数据下的监测结果,得到监测结果具有较高的相似性.
如图6所示,HiBench中的大数据应用程序在不同的输入数据集下,执行时间和平均水平相比有50%到350%的变化.然而在遍历所有服务器所支持的硬件事件之后,相同事件在不同输入数据集下,多次监测结果与参考结果之间的平均DTW距离不超过0.07,说明事件监测结果的趋势、幅度没有受输入数据集的变化而产生巨大变化,应用历史数据是可以信赖的.
下面分别介绍知识库的构建方法,局部滤波器设计以及回归模型的建立方法.
3.1 知识库的构建

图6 不同应用在不同输入下监测事件结果的相似性变化Fig.6 Similarity of results in different input data size among different applications
据记录表的描述,包含事件名,应用名,记录时长,记录最大值,最小值以及平均值,同时记录其他事件以及记录所有二级数据记录表的名字.
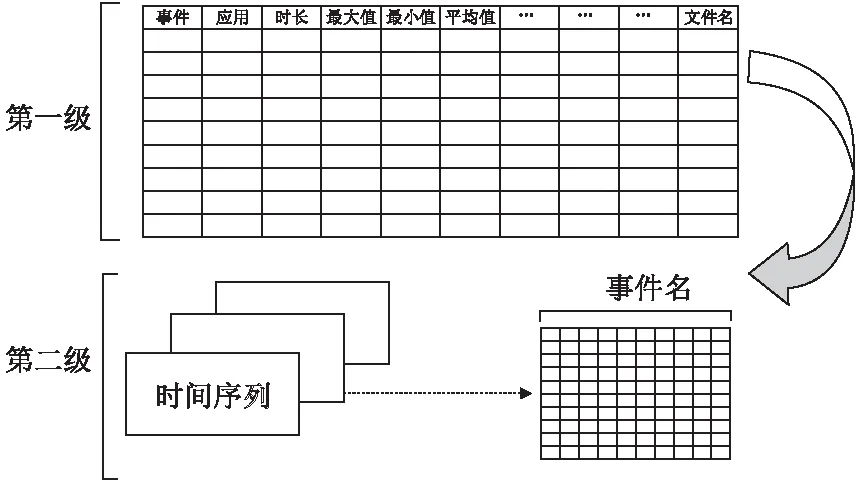
图7 两级表设计Fig.7 2 level sheet in the design of knowledge base
知识库将随着监测任务的进行不断更新,包括对有完全相同监测事件的监测结果进行替换,以及对新监测事件的监测结果进行添加.
对历史记录的查询,以被监测程序和问题事件为查询条件,返回具有相似监测任务的记录.从一级主表中查找事件的描述信息,再根据具体需要二次查找特定记录和当前记录中的历史数据,用于下一步的模型训练.
3.2 局部滤波器设计
局部滤波器设计包括针对两种情形的设计:
1) 历史记录事件:指相同监测应用下事件已被记录.此时利用一级主表中的数据描述信息,以其记录最大值的2倍,作为本地阈值作为判断异常值的依据,其数值源自于实验过程中的经验数值.
2) 初始记录事件:从观察监测数据的分布可知,数据分布曲线类似高斯分布,但不是严格的高斯分布.借用高 斯分布的特性,根据对数据的观察以公式2作为阈值的计算方法,
以均值和n倍标准差的和作为阈值.
List.threshold=List.mean+n*List.std
(2)
表2统计了n取不同值时的所有数据,n取5时可保证99%以上的数据都在阈值范围内.将检测到的异常值利用局部中位值替换的方式进行替换.
2.2 危险因素分析 单因素分析显示:3~6周岁幼儿近视与平均1天看电视时间有关联;远视与母亲视力、父亲视力、幼儿营养状况有关联;散光与父亲视力、幼儿营养状况有关联;多因素Logistic逐步回归分析:父亲视力是3~6周岁幼儿近视与散光的独立影响因素,是3~6周岁幼儿远视的危险因素。父亲视力异常则3~6周岁幼儿近视、散光的概率小。幼儿营养状态、母亲视力是3~6周岁幼儿远视的保护因素。3~6周岁幼儿营养状态越好则远视的概率越小,父亲远视、散光,增加3~6周岁幼儿远视的危险。见表2。
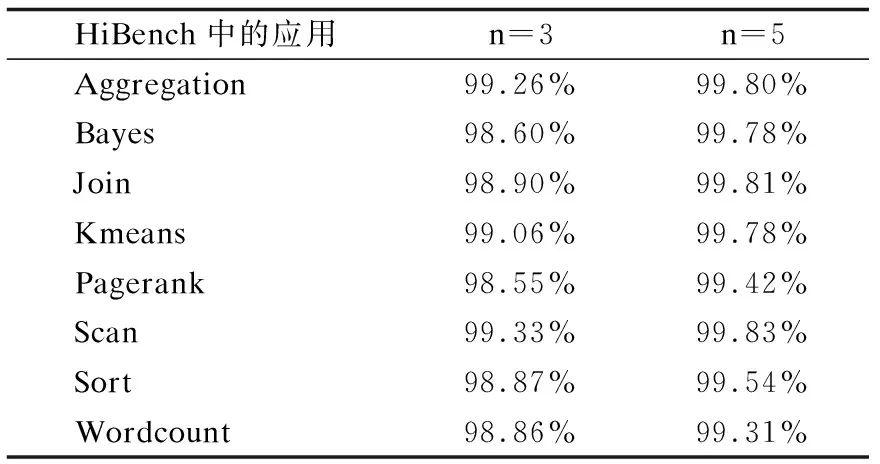
表2 n的不同取值所能涵盖的数据范围Table 2 Compare the scale of threshold with different n
3.3 回归模型的建立
对于缺失值的判断极具挑战,如图6所示,监测结果的差异度并没有随着输入数据集的变化而发生巨大变化,同时结合图4和表1的结果表明历史数据可作为缺失值补充的依据.然而历史记录中的序列长度与当前缺失项的记录时长未必相同,难以通过位置信息来补全缺失值,如图4中的参考数据所示.然而利用事件之间的关联可快速构造出回归模型,利用回归模型对数据进行补充则不存在错位的问题.本文利用知识库内相似监测事件的数据,即对相同的运行环境,相同计算框架下应用程序的监测任务,监测事件可以不完全相同,但必须包含缺失值的事件.以当前结果中的监测数据事件集的交集得出公共事件集作为训练数据,构建回归模型,回归模型采用KNN回归3的方式实现:
假设对含有缺失项的监测事件(a,b,c,d)的结果R1,只有事件a有缺失项 ,查找含有事件a,而且监测相同程序的记录结果R2.R2之中含有(a,b,c,e,f)的监测记录.
1.相同监测事件:
R1∩R2 = (a,b,c)
选取缺失项a为目标结果,b, c为特征事件.
2.整合数据:
结合R2之中事件a,b,c的监测结果和R1之中未缺失部分为模型训练集Ts1,缺失部分为Ls1.
3.应用KNN算法,以K个距离最相近数据的为一类,建立分类模型.
4.根据(b,c)预测a的从属分类,以类内所有a的平均值为缺失部分的最终预测值.
4 评 测
4.1 实验环境
实验集群由4台Dell服务器组成,其中一台作为主节点,其他三台作为计算子节点.每台服务器配备有16核Intel至强E5-2630 v3 @2.4GHz处理器,服务器内存大小为64GB,操作系统为Ubuntu 14.04.
集群管理系统为Mesos 1.0并应用Hadoop 2.7为计算框架,同时挑选了4类8个来自于Hibench中的典型云应用程序作为被监测程序,分别是:网络分析算法(Pagerank),分布式数据库应用(Aggregation,Scan),机器学习算法(Bayes,Kmeans)以及微基准程序(Sort,Wordcount).
4.2 数据质量评估方法
由实验观察可知,即使是在相同的系统环境中,反复监测同一程序只能得到具有极高相似度的实验结果,而不可能得到完全相同的实验结果,如表1之中Reference1到Refernce4的数据描述,以及图4之中对应的部分比较也可以证实这一点.所以本文对数据质量的评价是以数据结果与参考值的相似度作为数据清理效果的评价标准.并通过计算监测数据与参考值的DTW,评估结果的相似性,并以此比较数据清理前后的差异度Diff(%)来表现处理的效果,如公式(3).
Distancetest=DTW(datatest,dataref1)
Distanceref=DTW(dataref1,dataref2)

(3)
4.3 实验结果分析
由第一章可知,采用复用时系统会通过时分复用PMU实现多个事件的同时监测.以监测HiBench中的WordCount程序为例, 观察同时监测事件数量变化时的精度变化,结果如图8所示.纵坐标为不同监测结果与参考数据的差异度,横坐标为同时监测的事件数目.比较相同事件在不同的PMU配置下处理前后监测数据与参考数据之件的差异度,在同时监测的事件数量增多时差异度逐渐增加.预处理之后差异度明显减少,预处理之后差异度不超过参考值的42%,较处理前最低都在50%以上的偏差来比较极大地提升了监测结果的质量,而且在同时监测的事件数量上少于24个时,DTW距离的差异度不超过20%,而这20%中还包括监测程序因频繁的调度事件对程序所产生的影响.可监测的事件数量最大可提升到方式一的5倍,监测效率最大可提升5倍,确保数据依旧可保持较高的质量.

图8 同时监测多个事件,数据质量比较Fig.8 Compare of data quality when sampling with more events

注:KBDP,基于知识库的数据与处理方法;GDP,对当前缺失异常情况采取以当前均值直接替换的方法.三条直线(从上到下)分别代表经过预处理之前,GDP处理之后,KBDP处理之后的平均情况.
图9 针对多种应用采取不同预处理方法比较.
Fig.9 Data quality promotion when it applied to different application
同时对Hibench之中的其他应用进行了验证,并与针对缺失值和异常值直接以当前均值替换的方法[20](在本文中把这种方法定义成一般性的预处理方法方法-General Data Preprocessing approach,GDP)进行了比较,如图9所示.在监测10个硬件事件时,基于数据库的预处理方法(KBDP)与GDP相比极大的提高了与参考结果的相似性,总体的平均差异度由处理前的52.7%减低到8.7%,也就意味着平均91.3%的相似度.
5 总 结
本文提出的基于知识库的预处理方法有效解决了在云环境下应用PMU时的问题,即通过配置的事件数少于性能计数器个数来完成数据收集的工作才能获得可靠数据的限制.通过对复用PMU后监测结果的预处理工作处理了异常值,补全了缺失值,提高数据质量,使得监测数据可直接应用到后续的分析工作中,大大提升了工作效率.
