一种节点高稳定状态的应用层组播方案
2018-10-26崔建群常亚楠吴黎兵
崔建群 ,马 媛, 常亚楠, 吴黎兵
1(华中师范大学 计算机学院, 武汉 430079 )2(武汉大学 计算机学院, 武汉 430072)
1 引 言
近年来,由于IPTV直播,视频点播等应用的需求,使得多媒体传输的组播技术研究日益发展.组播(Multicast)是满足一点对多点通信需求的一种全新高效的技术,将源节点数据流的副本以多路复用的方式通过网络发送到一组接受者[1],而源节点只需产生并发送一份数据流,经过组播树中路由器的复制与转发,将数据流传送到一组目的节点.
IP组播是网络层组播[2],在通讯时保证在网络链路中只存在一份数据报文,因此可大量节省服务器成本与网络带宽,通过路由器来进行组播数据的复制和转发,减轻了服务器的负担和视频传输时延等问题.但是IP组播仍然存在较多并未解决的缺陷.例如组成员管理,组播拥塞控制以及难以部署等问题,图1(a)是IP组播.取而代之的是逐渐兴起的应用层组播(application layer multicast,ALM)[3,4],应用层组播将组播功能由网络层转移到终端,由终端主机进行数据分发,而节点
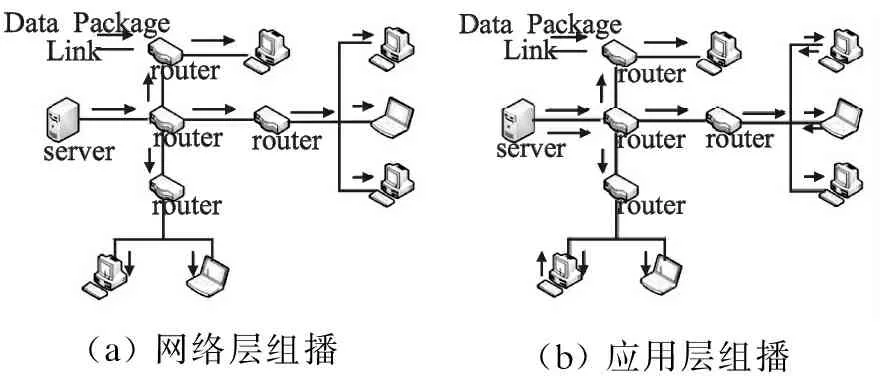
DataPackageLinkrouterserverrouterrouterrouter(a) 网络层组播DataPackageLinkserverrouterrouterrouterrouter(b) 应用层组播
图1 组播类型
Fig.1 Multicast classification
间的数据传输则通过传统的单播技术来实现,如此便解决了IP组播部署困难的问题,实现了组播的灵活性与扩展性,图1(b)是应用层组播.
对于应用层组播,端系统的稳定性与性能不如路由器,这就造成了应用层组播在稳定性与效率上不如网络层组播.由于组播树的性能会影响转发数据的效率,所以端节点的稳定状态与其在组播树中的位置直接关系到组播树的整体表现,本文针对以上问题设计了一种基于节点稳定状态的应用层组播方案.
2 相关工作
在已有的组播树构造算法中,组播协议分为集中式算法与分布式算法,分布式算法又分为网优先算法、树优先算法与隐含式算法.
集中式算法由集中控制点RP(Rendezvous Point)负责收集成员节点的网络信息,并周期性计算应用层组播树.RP负责数据分发,易于维持组播树的一致性,但容易单节点负载过重并且扩展性差,适用于小规模、多数据源情况,典型协议有ALMI[5]与HBM[6].
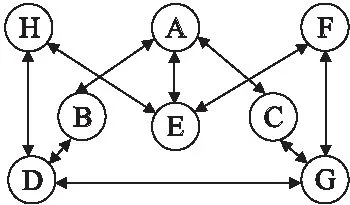
图2 基于网状的应用层组播树结构Fig.2 Data structure of mesh-basedoverlay multicast
分布式算法组播树构造与维护依赖于各个节点维护的局部信息,因此具有良好的扩展性.网优先算法将节点分布式自组织成Mesh,Mesh中各个节点都要维护全部或者部分成员状态信息,来迅速恢复网络分割,并运行组播路由协议.其优点是组成员管理、负载均衡与数据传输效率高,缺点是复杂度较高,维护代价比较大与有限的扩展性.典型协议有Narada[7]、PRO[8]和Prime[9]等.基于网状的应用层组播数据结构如图2所示,其中节点A是组播源节点.

图3 基于树状的应用层组播树结构Fig.3 Data structure of tree-based overlay multicast
树优先算法是成员节点直接在组内选择父节点构建组播树,与非邻居节点建立并维护控制链接,其优点是用户节点便于直接控制,缺点是进行单独的检测与回路避免处理.典型协议有TBCP[10]、Overcast[11]、PROMISE[12]等,基于树状的应用层组播数据结构如图3所示,其中节点A是组播源节点.隐含式算法在构造控制拓扑与数据拓扑方面没有先后次序之分,节点之间也没有其余交互信息,控制拓扑中隐含着数据拓扑.其优点是大幅度降低组播成员的处理开销,具有良好的扩展性.典型协议有NICE[13]、ZIGZAG[14]、Scribe[15]等.
文献[20]提出一种基于gossip的应用层组播方案,将数据分发过程分为上层分发以及底层簇内分发两个阶段.该方案具有较高的数据分发成功率,但增加了控制开销.已有的研究协议大多针对某一特定应用,在特定的前提下以生成最小延时组播树为目标,由于网络的易构性以及终端节点用户的不稳定性,必须综合考虑节点性能以及所在位置对组播树的影响.已有的研究协议大多针对某一特定应用,在特定的前提下以生成最小延时组播树为目标,由于网络的易构性以及终端节点用户的不稳定性,必须综合考虑节点性能以及所在位置对组播树的影响.
针对节点稳定状态与延时的问题,我们抽象出一种合理的问题模型-T-DTD (Spanning tree based on degree-constrained, max on-session time and depth bound for ALM) 模型.在应用层组播树生成过程中,该模型综合考虑了终端节点的转发能力与在线时长,以及节点所在组播树中位置这三个因素,构造高稳定性、低延时应用层组播树.
3 T-DTD模型及相应的概念
3.1 组播树稳定性
节点的稳定状态对组播树的稳定性有至关重要的作用.从节点的行为属性来看,在线时间越长的节点、位于组播树中越高层位置的节点,组播树越稳定;从节点度的角度看,组播树中间节点转发能力越强组播树越稳定.文献[16]用稳定度来衡量组播系统的稳定性,应用层组播稳定度定义为公式(1).
(1)
并由此推出公式(2).
(2)
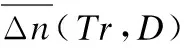
1)直接将带宽与节点已在线时间乘积值作为节点所在的位置,而没有考虑在实际问题中带宽与已在线时间对组播树稳定性影响权重比例问题;

图4 完全无向图Fig.4 Complete undirected graph
2)Tan默认高度低的组播树延迟小,但是对应用层组播树而言可能不正确.因此,要提高应用层组播树稳定性,既要综合考虑节点度与在线时间,还要考虑它们对组播树稳定性影响的权重问题.
3.2 组播路由问题描述
T-DTD问题模型:在组播路由问题中,通讯网络通常用完全无向图G(V,E)表示,如图4,其中V是待加入节点集合,E是路径集合,算法过程是由图G生成树T,将G中的节点及相关边加入到T中.
定义1.节点度是衡量一个节点转发能力的指标.B(vi)为节点vi的上行带宽,R为流媒体播放速度,节点在加入组播树时带有自己的出度,根据数据流的状态可以计算节点出度.节点vi的出度定义为节点上行带宽与流媒体传输速率的比值,可用公式(3)表示.
Deg(vi)=B(vi)/R
(3)
定义2.节点深度表示节点所在组播树中的层次,根节点层次为1.若根节点不空时深度记为1;若根节点为空时则深度记为0,在此模型中都假设根节点不空.节点的深度可表示为公式(4).
(4)
定义3. 在应用层组播树中,所有节点组成集合V,V(T)={v1,v2,…,vn-1,vn},n为组播树中节点个数,则组播树T的平均深度按公式(5)所示.
(5)
定义4.节点在线时间表示从节点成功加入到组播树的时间到当前时刻的时间段,在线时间越长,表示节点继续停留平均时间也越大,节点退出概率越小.节点的在线时间可用公式(6)表示,其中Tjoin(vi)表示节点vi的请求加入时间,t表示当前时间.
Ton-session(vi)=t-Tjoin(vi)
(6)
定义5.节点稳定度因子(Nodedegreeofstability,NSD)是表示节点稳定状态的指标,NSD越大,表示节点越稳定,节点越稳定,组播树性能越好.节点vi(1≤i≤n)的出度Deg(vi),节点在线时间Ton-session(vi),则公式(7)可表示节点的稳定度因子.
(7)
其中∂为稳定度因子权重系数,根据不同的应用环境权重系数取不同的值.Bishop和Rao等人研究异构环境中组播树稳定性问题[19],实验结果显示,基于节点度的策略优势明显优胜于基于节点已在线时间的策略,基于节点在线时间的策略中,节点频繁的更改自己的位置,其优势不明显.因此在综合计算节点稳定度因子时,这里设置度所占权重∂为大于0.5小于等于1的实数.
4 基于节点稳定状态的组播方案
为了更好地对算法进行说明,本文将组播树中已有节点用三元组N(T,Deg,C)信息来表示,如图5所示.其中T表示节点在线时间,Deg表示节点的转发能力,C为候选父节点集合.实线部分表示已构建的组播树,虚线部分表示待加入节点有可能的位置.在构建组播树的过程中,节点候选位置集合为ST={E,F,G,H}.
4.1 组播树的建立
本文将解决T-DTD(Spanning tree based on degree-constrained, maxon-session time and depth bound for ALM)问题模型的算法定义为DTD-H(DTD-heuristic)算法.DTD-H基本数据结构与具体算法可以描述如下:
m为组播树中小于平均节点深度的节点数目.

图5 组播树
Fig.5 Multicast tree
临时集合(Templeset,TS):记录组播树中深度小于等于平均树深度并且具有度剩余的节点集合,TS={v1,v2,…,vm-1,vm}.
候选父节点优先级集合(priority set of candidate parents,CPPS):记录可以纳入新孩子节点的节点集合,并按照节点稳定度因子降序排序.
输入:G(V,E),图中每个节点带有出度Deg(Vi),深度Dep(Vi) ,以及节点在线时间.
输出:树T.
初始化待求树T=φ,将源节点s纳入到树T中.
1) 计算组播树平均深度Depavg(T),图5中Depavg(T)=(1+2+2+2+3)/5=2.
2) 取V′中深度不大于⎣Depavg(T)」 且有剩余出度的节点位置得到集合TS,如果所有候选位置深度都大于⎣Depavg(T)」,则取深度最小的候选位置得TS.
3) 计算TS中的候选父节点的节点稳定度因子NSD,并按照节点稳定度因子大小降序排序得CPPS.
4) 取CPPS中稳定度因子最大的节点作为待加入节点N的最佳候选父节点.每成功加入一个节点,候选父节点度减少1.
5) 实时更新修改集合TS、CPPS.
算法伪代码如下:
DTD-H Algorithm
Input:G(V,E),for anyv∈V
Output:T(V,E′)
Procedure:
1)T=φ;TS=φ.
2)V(T)←s;
3)TS←{s};

5)FOR each node in V′
6)IF node′s out-degree is not full and node′s depth≤⎣Depavg(T)」
7)TS←v.
8) END IF
9) END FOR
10) FOR each node inTS
11) calculateNSDof each node and sort the nodes ofCPPS
12) father←select the first node ofCPPS
13) out-degree[father]= out-degree[father]-1.
14) updateTSandCPPS
15) END FOR
16) END WHILE
4.2 组播树的维护
4.2.1 组播树调整
在文献[17]中,对视频日志进行统计分析,验证了用户在线时间符合对数正态分布,并指出用户剩余在线时间随着用户在线时间增大而增大.本文对文献[17]中统计数据进行分析,将节点分为以下三类:当节点在线时间小于200秒时,有超过70%的节点会在连接后的200秒内选择退出,为保证组播树的稳定状态,应当使该节点远离根节点;在线时间在200秒到2000秒之间的节点,对降低节点的退出概率相比第一类节点已有较大提升;而在线时间超过2000秒的节点,其剩余在线时间在10的三次方数量级以上,节点已处于相对稳定的状态,所以为保证组播树的稳定状态,应当使该节点靠近根节点.
节点不仅要维护自己的信息,还要保存孩子节点的信息.当新节点加入组播树后,分别计算父节点与子节点的NSD值,当父节点的稳定度因子小于子节点的稳定度因子时,则将父节点与子节点进行交换.本文将节点交换的周期设置为200秒,即每隔200秒对组播树内的节点进行动态维护.
4.2.2 节点离开
节点离开组播树有两种方式:友好离开方式,将离开消息通知给父节点与子节点;意外离开方式,由于外在故障原因未能将离开消息告知父节点与子节点.
当节点离开时,非叶子节点的离开会导致其子孙节点离开组播树从而中断数据传输,最简单的一种解决方法是使中断连接的节点重新申请加入到组播树中,但是这样会花费较多时间,降低组播树的服务质量,因此针对以上两种节点离开方式,本文分别给出两种快速恢复组播树机制.设F(A)为A的父节点,C(A)为A的孩子节点集.
1)友好离开
当节点A离开时,告知父节点F(A)与子节点C(A)自己将要离开的消息,F(A)收到离开消息后将A的有关信息删除,C(A)收到A的离开消息后则将C(A)中节点按照NSD值排序.因为A节点的离开,F(A)一定有空余出度,然后将C(A)中排序后的节点依次作为F(A)的子节点.若C(A)中还存在子孙节点,则剩余节点以集合中NSD值最大的节点作为父节点加入组播树.
2)意外离开
这种情况下A离开时,并未告知父节点F(A)与子节点C(A).子节点在一段时间未收到A节点发送的数据,则向A节点发送心跳探测消息.若A节点回应则说明节点仍然在组播树上,无需进行任何操作;若A一段时间未回应则说明A节点已失效,C(A)将A失效已离开的消息告知F(A),后续操作和节点友好离开组播树的处理方式相同.
5 仿真实验
本文将通过仿真实验对比DTD-H算法与NICE算法和度优先算法以及随机算法在平均加入时延、最大加入时延和链路伸展度这三方面性能.NICE[13]协议是一种典型的分层分簇的应用层组播协议,它可以支持大量不同的数据转发树,有较强的可扩展性.度优先算法[19]是优先考虑有最大度的节点并且以最大度节点为父节点加入新节点的过程.随机算法是随机选择组播树中仍有剩余出度的节点将新节点加入组播树的过程.
5.1 仿真实验的环境
为了验证DTD-H算法的性能,本节对算法进行实验.这里使用OMNet++作为模拟环境,以OverSim[21]为基础进行代码编写和模拟实验.
OMNet++是Objective Modular Network Testbed in C++的缩写,是一个免费且开源的网络环境模拟软件,其通过对基础底层网络事件的模拟可以精确的复现出近似实际网络的结果.而OverSim则是基于OMNet++实验环境的一套覆盖网络模拟框架,该框架包含了基本的组播覆盖网络实现算法,为实现自定义的各种覆盖网络算法提供了较为便利的开发环境.通过复用OverSim的部分代码,可以很容易的开发并设计出自己想要的覆盖网络模型.该仿真器可以运行于 Linux和Windows 等多个平台.图6是节点数目为150时,DTD-H算法的模拟仿真架构图.

图6 模拟仿真架构图Fig.6 Simulation framework diagram
5.2 实验参数设置
下列是对实验中相关参数的设置情况:
1)节点的出度代表着节点的转发能力,节点的最大出度表现为该节点能够容纳孩子节点的最大数目.根据文献[22,23]中采用的实验参数,本文在仿真实验中采用节点的最大出度degmax(vi)服从整数区间[2,6]之间的均匀分布;
2)在文献[17]中,对视频日志进行统计分析时,当节点在线时间小于200秒时,有超过70%的节点会在连接后的200秒内选择退出,为保证组播树的稳定状态,因此在实验中设置组播树更新调整维护周期为200s.
5.3 性能指标
平均加入时延:当新的节点要加入组播树中时,在组播树中找到最合适的父节点,并且向父节点发送加入请求,父节点发出回应后才能顺利加入.从开始找父节点到最后顺利加入到组播树中所花费的时间的平均值.加入时延越小,新节点就能越迅速加入到组播树中,也就能更快接收到数据.假设vi节点发送加入请求时刻为t0,父节点发送回应消息的时刻为t(vi),组播树中节点总数为n,则平均加入时延tave的计算如公式(8)所示.
(8)
最大加入时延:新节点在加入组播树的过程中,在组播树中找到最合适的父节点,向父节点发送加入请求后才能顺利加入.假设vi节点发送加入请求时刻为t1,父节点发送回应消息的时刻为tmax,则最大加入时延的计算如公式(9)所示.
tdelay=tmax-t1
(9)
平均链路伸展长度:对于组播树中的每个成员节点,数据从数据源经过其他节点转发到达该节点所走过的路径长度,是衡量组播数据路径质量的主要标准.设数据从数据源经过其他节点转发到节点vi所走过的路径长度为Leg,则平均链路伸展长度的计算公式如公式(10)所示.
(10)
5.4 仿真结果分析
将DTD-H算法与Nice算法、度优先算法、随机算法在平均加入时延、最大加入延时与平均链路伸展长度方面对比.
图7统计了当节点数目为10~150时,节点加入到组播树中所需要的平均时间,当节点数目为10的时候,度优先算法在比较少的节点里可以快速找到有最大度的父节点,度优先算法加入时延比DTD-H算法快0.02s,比NICE协议快0.05s,加入时延会优先于其余三个算法.但是在节点数目逐渐增多时,NICE算法在由上至下每次寻找最近的成员会需要较多时间,而随机算法在组播树中随机加入有剩余度的节点.当节点数目为100时,DTD-H算法的平均加入时延为0.15s,明显小于NICE协议的0.43s和随机算法的0.42s,因此DTD-H算法的平均加入时延会优于随机算法与NICE算法;度优先算法在所有节点中选出最大度的节点的过程,而DTD-H算法只在满足稳定状态的节点集合中选择父节点,DTD-H算法的平均加入时延小于度优先算法0.02s,随着节点个数越来越多,DTD-H算法在减少节点加入时延方面相对于度优先算法的优势也越来越大.

图7 平均加入延时与节点数目的关系图Fig.7 Relation graph of average delay of the spanning tree and the number of nodes
图8统计了当节点数目为10~150时,节点加入到组播树中所需要的最大时延.当节点数目为10~20之间时,四种算法在最大加入时延方面均呈现递增趋势,随机算法与NICE协议的最大加入时延分别分布在0.32s到0.4s之间以及0.41s到0.8s之间,度优先算法在比较少的节点里可以快速找到有最大度的父节点,最大加入时延分布在0.16s到0.53s之间,而本文提出的DTD-H算法的最大加入时延分布在0.22s到0.40s之间,所以节点数目略小时,度优先算法最大时延会优先于其他三个算法.但节点数目逐渐增多时,NICE算法在由上至下每次寻找最近的成员时所需要的时间也越来越长,最大加入时延分布在0.8s到1.73s之间,所以NICE算法最大加入延时最大;随机算法在所有具有度剩余的节点中随机选出父节点,最大加入延时低于NICE算法,分布在0.45s到1.18s之间;度优先算法会在众多节点中选出最大度的节点,最大加入延时分布在0.53s到0.57s之间;DTD-H算法的最大加入时延分布在0.44s到0.52s之间.因此节点数目多于20个时,DTD-H算法的最大加入时延会略优于度优先算法,而明显优于NICE算法以及随机算法.
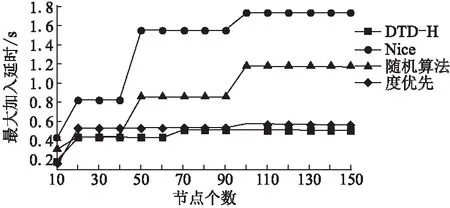
图8 最大加入延时与节点数目的关系图Fig.8 Relation graph of max delay of the spanning tree and the number of nodes
图9所示统计了100~1000个节点数目时,DTD-H算法与对比算法的平均链路伸展长度.随着节点数目逐渐增多时,四种算法的平均链路伸展度均呈现递增趋势.NICE协议采用的分层分簇结构,大部分节点位于分层结构的最底层,组播树中成员节点加入的过程由上至下寻找最近的节点,一旦某一层出现误差将会影响下层节点簇的选择,在实现数据转发的过程中路径长度越来越大;而度优先的算法不考虑其他因素,只选择最大度的节点加入;随机算法任意加入组播树中,将存在出度剩余的节点作为父节点;而本文的算法在考虑路径长度的前提下选择稳定度因子最大的节点作为父节点加入.仿真数据显示,DTD-H算法降低了平均链路伸展长度.

图9 平均链路伸展长度与节点数目的关系图Fig.9 Relation graph of average link stretch length and the number of nodes
6 结束语
针对应用层组播的终端节点随机任意退出的问题,本文主要研究了如何构造高稳定性的应用层组播树.本文的主要贡献为提出了一种合理的问题模型-T-DTD模型,在应用层组播树生成过程中,该模型综合考虑了终端节点的转发能力与在线时长,以及节点所在组播树中位置这三个因素,并且对主要影响因素进行比重控制构造高稳定性、低延时应用层组播树.最后通过仿真实验,对比了本文DTD-H算法与NICE协议和度优先算法以及随机算法在平均加入延时、最大加入延时以及平均链路伸展度这三个方面的性能,仿真结果表明本文提出的算法能够有效地降低组播树的时延以及链路伸展度.
本文对应用层组播的构建算法进行了研究,但还存在诸多不足和有待继续完善的地方,在未来的研究中,我们将继续深入研究T-DTD模型中调整组播树的算法,以更加精确有效的提高组播树服务质量.我们也将进一步探索求解T-DTD问题模型的算法,以获得更优的解法.另外,从分布式和组成员动态管理的方面对本文提出的算法进行改进,使之能适应成员节点规模较大的应用层组播场景,这也是我们下一步研究方向.同时,由于本文中对利用DTD-H算法构建的应用层组播树性能的验证,是通过OMNet++仿真实验实现的,还没有考虑到实际网络中的环境,所以下一步工作也会将本算法投入到实际应用中,以验证算法的优越性.
