基于改进YOLO算法的全景多目标实时检测
2018-10-24蔡成涛吴科君刘秋飞程海涛
蔡成涛,吴科君+,刘秋飞,程海涛,马 强
(1.哈尔滨工程大学 自动化学院,黑龙江 哈尔滨 150001;2.哈尔滨建成集团有限公司,黑龙江 哈尔滨150001)
0 引 言
常规视觉系统由于视场角固定,且不具有旋转不变性,不适于旋转全视场的监控。折反射全景视觉系统,能获取水平方向360°、垂直方向240°范围内场景的高清晰图像[1],且结构简单、成本低廉、反射面易于设计和加工,应用广泛[2]。然而由于全景图像成像变形的特点,待检目标的快速准确检测一直是困扰其发展的难题,目前常用的全景目标检测方法多为基于目标运动检测方法,文献[3-6]提出了背景差分法、帧间差分法、光流法等,然而只能对运动目标进行检测,对静止目标或缓慢移动目标无法有效检测,更无法对目标进行精确分类。得益于深度学习,主要是卷积神经网络(convolution neural network)和候选区域(region proposal)算法[7],目标检测取得了巨大的突破,文献[8-10]定义了RCNN、Fast-RCNN、Faster-RCNN及YOLO检测器。其中YOLO(you only look once)为一种全新的目标检测方法,把目标判定和目标识别合二为一,真正的端到端(end to end)的检测,实现快速检测的同时还达到较高的准确率[10]。
为了达到对全景目标的实时精确检测的目的,本文提出一种E-D-YOLO(expand density YOLO)全景多目标实时检测方法。通过不同环境下的对比实验,表明了该方法具有优秀快速性、良好的准确性和鲁棒性。适用于对速度和准确度同时有要求的场景,如关键敏感地带的实时监控,以及复杂作战环境下装甲车,结合全景视觉快速发现周围可疑目标,并做出相应回应以排除危险。
1 全景图像解算
双曲面全景系统及全景图像如图1所示,由于折反射全景视觉成像原理会使全景目标成像比发生变化如图1(b)所示,不便于我们直接在全景图像中提取特征进而进行多目标检测,可以考虑将全景图按照其成像模型变换为柱面展开图,然后对其展开图进行多目标检测。

图1 双曲面全景系统及全景图像
1.1 折反射全景模型
根据折反射式全景系统反射面曲面类型,对系统成像原理进行模型分析,得到反射面的三维成像方程如式(1)所示
(1)
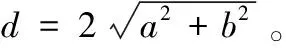
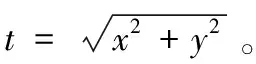
(2)
使用球坐标系表示

(3)
其中,θ为入射光线与T轴的夹角,R为球面的半径,可表示为
(4)
1.2 柱面展开
全景柱面展开图像是将环形全景图像投影到一个距反射镜指定半径的圆柱面上所获得的图像。将圆柱面沿径向切开平铺,得到一个二维矩形的柱面全景图[11],如图3所示,仍然取全景系统有效视点为反射镜坐标系OmXmYmZm的原点,虚拟成像面为一个与全景视觉系统共轴的圆柱面,半径为f,假设柱面展开图像分辨率为W×H,其上下边缘的俯仰角度分别为α1、α2,则柱面图像的高为H=ftanα1+ftanα2。记为柱面展开图像上一点m′=[i,j]T,则点m′在反射镜坐标系下的三维坐标x可表示为
x=[fcosθ,fsinθ,ftanα1-j]T
(5)
其中,θ=2π/L。

图3 柱面展开图
2 YOLO算法原理及改进
传统目标检测先提取特征,如LBP(local binary pattern)特征、HOG(histogram of oriented gradient)特征[12],然后采用SVM(surpport vector machine )训练得到物体的模型,再进行模型和目标匹配。YOLO使用了回归的思想,将目标区域预测和目标类别预测整合于单个神经网络模型中。该方法采用单个神经将候选框提取、特征提取、目标分类、目标定位统一起来,实现端到端的目标检测。
文献[10]给出了YOLO与其它物体检测方法如Fastest DPM、R-CNN、Fast R-CNN等,在检测速度和准确性方面的比较,通过比较可知YOLO在速度方面的优势明显。
2.1 YOLO检测过程
全景图像中可能包含多个目标或者多种类别的目标,故需对每个预测框的多种类别给出判断。具体检测过程为:
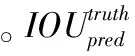
(6)
(2)CNN提取特征和预测,每个网格给出有物体存在时的C个分类的条件概率Pr(class|object),进而得到整幅网络中的各类别的概率,通过各检测框内某类别的概率与其对应的置信度相乘来得到该类别置信值,如式(7)所示
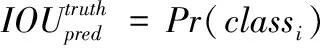
(7)
(3)通过非极大值抑制(non-maximum suppression)过滤边框,输出最终判断结果。
YOLO为了优化模型,设计上使用S*S*(B*5+C)维向量与图像真值的均方和误差,作为损失函数(loss function)的参数。然而由于很多网格内并无目标物体存在,所以在设计YOLO的损失函数时,分别给有目标与无目标存在的预测边框设置不同的比例因子进行平衡,此外还需差异化边界框的损失因子和类别判断的损失因子,如设定边界框的损失权重是类别判断损失因子的10倍,以上设计使得边界框有目标存在的损失因子处于较高权重。损失函数的形式如式(8)所示
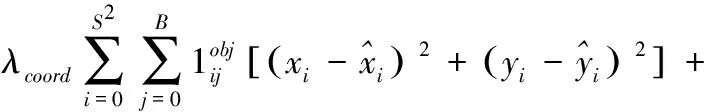
(8)
YOLO完整的检测过程如图4所示。
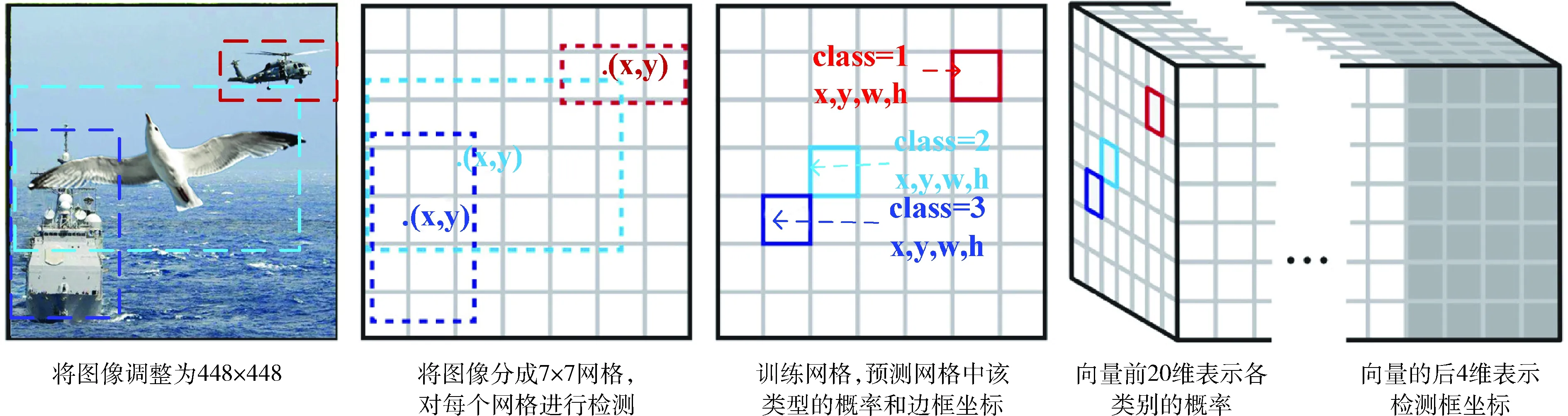
图4 YOLO模型检测原理
2.2 改进YOLO网络结构
文献[10]中指出YOLO检测网络包括24个级联的卷积层(convolution layer)和两个全连接层(fully connected layer),用来提取图像特征及预测图像位置和类别,能达到快速检测的目的,但其弊端也很明显,经全连接层处理后的预测边框,会丢失较多的空间信息,导致目标在虽能被检测到但其定位不准确。参考Faster R-CNN中的锚点(anchor)设计思路,去掉全连接层,直接在卷积层上进行滑窗操作。在网络结构的末端使用全局平均池化(global ave-rage pooling),把1*1的卷积核置于3*3的卷积核之间,对特征图(feature map)压缩,构成YOLOv2网络[13]。
YOLO检测方法中,图像被分成S×S的网格,即横向纵向检测权重相同,然而经全景解算后得到的展开图中待检目标的长宽比并不是其真实值的精确反映,而是呈现出矮粗的趋势,目标变形是非线性的,且同一方向上的变形密度不同,如图5中人和椅子,呈现出上下部分比例失调现象。

图5 修改后的检测框
针对这一问题,改变预测边框在纵轴方向数量,本文是将纵向数量增加一倍,横向数量不变,即网格数量从S×S变化到S*2S,并在YOLO网络结构的末端增加一个特征层。网络结构包含20个卷积层、5个最大值池化层(maxpooling layers),从而生成YOLO网络的改进版E-D-YOLO网络,如图6所示,以满足全景展开而来的图像检测需求。
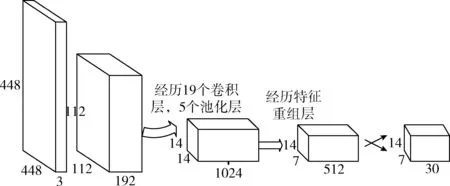
图6 E-D-YOLO网络结构
3 训练E-D-YOLO网络
使用python爬虫程序爬取图片作为训练素材,构建标准VOC数据集,在构建好的VOC数据集上完成100次循环(epoch)后得到预训练参数,每完成10次循环就随机改变网络的输入图像大小。
3.1 构建VOC数据集
按照VOC数据集的架构来构建自己的数据集,用OpenCV读取文件夹下的所有图像然后统一命名并改格式,备好数据后,需要按VOC数据集的结构放置图像文件,如图7所示。
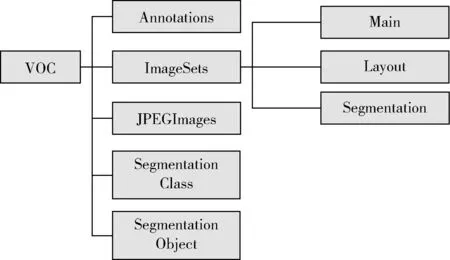
图7 构建VOC数据集
3.2 标记图像目标区域
使用labelImg软件标记原始图像中的目标区域以便训练使用。基本用法是框住目标区域然后双击类别,标记完整张图像后点击保存即可,类别选取常见的20类物体,如人、餐桌、椅子、箱子、自行车等。
3.3 训 练
计算机配置为:Windows 7系统,CPU为Intel Core i5-3470,GPU为NVIDIA GeForce GTX1080,内存32 G,安装有cuda8.0,python3.5并配置相应的库如tensorflow v1.1、numpy,、OpenCV 3和Cython扩展库。将折反射全景系统与搭载1394采集卡的计算机连接。设置YOLO参数,冲量常数(momentum)0.9,权值衰减系数(decay)为 0.0005,以防止过拟合现象,训练时参数选取见表1,参数设置完成后进行实验。

表1 关键参数选取
4 实验测试与结果分析
使用1000张图片进行测试,其中全景图100张,全景展开图800张,展开图中遮挡、无遮挡、光照正常与光照微弱4种环境各200张图片。设置对照实验,分别在YOLO、E-D-YOLO及主流检测方法Faster-RCNN下进行检测,其中YOLO和E-D-YOLO使用Darknet框架,Faster-RCNN使用Tensorflow框架实现。在实验环境下person(人)和chair(椅子)运动属性明显,可分别代表静止目标和运动目标参与检测,故选择其为统计对象,实验操作界面如图8所示。

图8 实验操作界面
对目标检测算法有3个要求,即快速性(rapidity)、准确性(accuracy)、鲁棒性(robustness)。对应分别取检测帧率(FPS)、准确率(accuracy rate)、平均重叠率(average overlap rate)为对比参数。
4.1 快速性
分别对YOLO 、E-D-YOLO及Faster R-CNN这3个检测器,在CPU和GPU下进行测试,并根据测试图片平均耗时计算出检测帧率,统计结果见表2。可知CPU下三者均无法满足实时性要求。GPU下使用YOLO或E-D-YOLO速度均超过30 FPS,远远满足实时性要求,而目前主流的检测方法Faster R-CNN检测速度不及每秒5帧。体现了YOLO及E-D-YOLO在实时检测方面优异的性能。
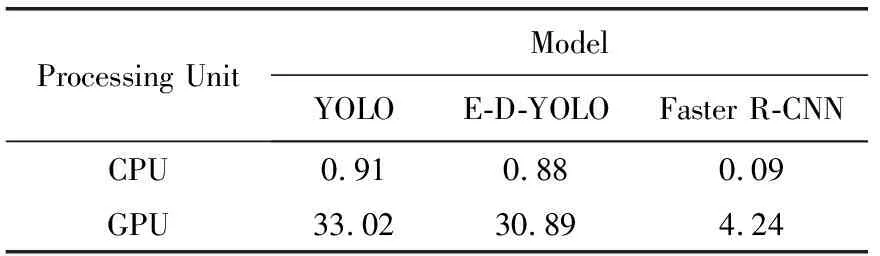
表2 检测速度对比
4.2 准确性
目标检测的准确性可由检测的错误率间接反映,错误率越低,对应模型检测的准确性越可靠。其中,False positive (错检)表示对目标分类错误,False negative (漏检)表示未能定位到目标,如图9所示。
使用YOLO检测器分别对全景展开图以及未经展开的全景图进行测试,E-D-YOLO及Faster R-CNN对全景展开图进行测试,统计各自错误率,见表3。可得出结论:
(1)对未经过预处理的全景图直接进行检测,即表中YOLO Panoramic一栏,其错误率均接近90%,检测效果非常不理想,失去实用价值。使用YOLO全景展开图进行检测,错误率40%左右,是因为待检目标处于“矮粗化”状态,常规检测器不能适应。使用E-D-YOLO检测器,通过增大纵向预测框数量,使其适应矮粗化目标,错误率控制在30%,性能远远优于YOLO检测器。

图9 错检与误检表示
(2)对比E-D-YOLO和Faster R-CNN两个检测器,Faster R-CNN错误率低于30%,是准确度方面最优秀的检测器,E-D-YOLO检测器错误率较其稍高3%左右,但考虑到E-D-YOLO检测速度方面的巨大优势,使得其在全景检测方面更具有实用性。

表3 检测准确性对比
4.3 鲁棒性
选取人为目标对象,椅子、箱子、桌子等室内其它物体为干扰对象。统计检测结果中人的准确率(accuracy rate)、平均重叠率(average overlap rate)作为定量性统计指标。重叠率是指检测结果的区域和目标真实值的区域之间的重叠部分所占的比率,数值越大表示检测结果的区域越准确。使用E-D-YOLO在各种实验环境下检测,其中图10(a)、图10(c)为无遮挡组且光照正常组,图10(b)、图10(d)为遮挡组和弱光组,选取4张检测结果如图10所示,其中白色框为目标对象的检测框,其它框为干扰目标的检测框。准确率和平均重叠率的统计结果见表4,其中Normal表示正常组,Overlap表示遮挡重叠组,Weak light表示弱光组。
由检测结果可知,当目标被遮挡,E-D-YOLO会出现一定程度漏检,准确率比正常环境下低6个百分点,平均重叠率低7个百分点,但仍高于65%。当光照不足导致目标与背景有一定程度的融合,检测准确率下降5个百分点,平均重叠率降低3个百分点。可见在遮挡和光照不足环境下,基于E-D-YOLO方法的检测虽性能有所下降,仍保持了较高的准确率和平均重叠率,表现出较好的鲁棒性。
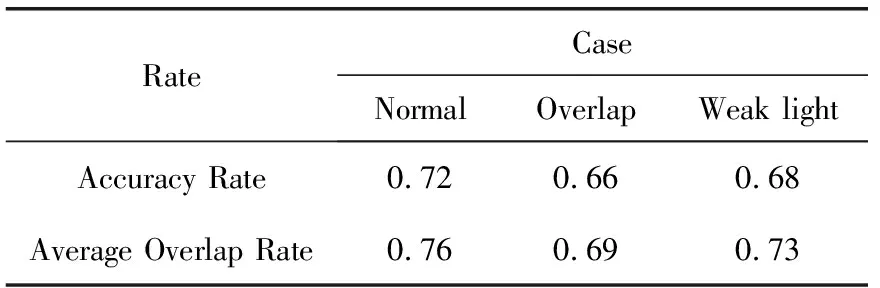
表4 鲁棒性定量检验

图10 4种情况下的检测结果注:(a)无遮挡 (b)遮挡 (c)光照正常 (d)光照不足
5 结束语
考虑到全景图像中的待检测目标长宽比和轮廓特征均发生显著变化,使用常规手段无法可靠检测,提出了基于改进YOLO算法的全景目标实时检测方法, 即E-D-YOLO方法。实验结果表明,GPU环境下E-D-YOLO方法对全景目标检测速率高达每秒31帧,远远满足实时性要求,且稳定保持70%以上目标识别正确率。在实验中还存在各类目标数量偏少的问题,下一步将大幅增加目标数量,如地铁站密集人群或车流量较大的交通枢纽路段,以验证E-D-YOLO方法在目标密集场景下检测的能力。
