基于运动特征与序列袋的人体动作识别
2018-10-24冯小明冯乃光汪云云
冯小明,冯乃光,汪云云
(1.南京邮电大学 工程训练中心, 江苏 南京 210003;2.四川广播电视大学 工程技术学院, 四川 成都 610073)
0 引 言
对于复杂行为动作的识别具有一定的挑战性,主要是由于:①复杂动作由较多的子动作组成,具有短期和长期的因果关系,各序列因果关系会增加模型的复杂度,通常需要足够大的训练数据;②视角差异与动作类型等因素,动作的变化种类千姿百态[1-4]。
目前,人体动作识别成为当前的一个热点,取得了一定的成果。尹建芹等[5]设计了基于关键点序列的动作识别方案。基于身体关节点变化的节奏,将动作标签为上肢运动与躯体运动。为了获得关键点,通过C均值聚类提取上肢、中心关节点。并将关键点投射到对应的动作路线中,从而得到了初步分类运动的关键序列。为了精确识别,通过时序直方图对关键序列构建分类学习函数,将关键序列分类学习,完成动作识别。但其忽略了局部特征与运动的光流特征,对相似特征与复杂动作的识别效果不理想。刘长征等[6]设计了复杂背景下定位的动作识别方案。该方法对3D动作采样,完成对每个姿势定位从而实现动作识别。此算法能够较好地完成动作的识别,但在噪声场景下,随时间累积,显著降低了识别性能。Bohick等[7]设计了一种时间模板的动作识别方案,通过对视频序列中的临近帧图像执行差分运算,获得运动能量图MEI与运动历史图MHI,并通过MEI与MHI共同来描述动作。该方法在简单运动中获得了一定的识别效果,但在较复杂场景与摄像头移动中,动作轮廓很难有效提取,对于存在行为遮挡时,对动作识别的精确度大幅降低。
将视频分割成固定的时空网格是编码时间结构最流行的方法之一。这种方法通常与词袋表示相结合,可以自动学习视觉词汇和模型,而不需要对动作结构进行任何注释。然而,对视频划分为统一的单元不足以模拟复杂的动作。因此,本文提出了一种序列袋(BOS)模型,能够考虑复杂的行为有效的类内变化。为了构造BOS模型,首先将视频表示为原始动作序列。通过将视频转换成PA序列,BOS模型可以保持PA的时间顺序。然后,使用序列模式挖掘来自动学习动作结构。此时,将挖掘的序列模式称为序列集。本文的贡献主要有:①通过动作的序列集描述,BOS模型可以有效地表示了复杂动作的时序结构;②将视频描述为PA序列,可以使用SPM自动学习动作的时间结构,而不需要任何注释或行动结构的先验知识。
1 人体运动特征
对于动作识别技术中,动作特征的提取与表示至关重要。在本文中,为了准确全面的表示动作特征,采用两个步骤来完成。首先,将一个视频表示为基础运动(PA)序列,形成了动作的特征序列。其次,将特征序列变换为PA索引序列。
1.1 特征序列
设训练视频集{(Vn,yn)|n=1,2,…,N},其中,Vn为一个视频,yn∈[1,2,…,C]为动作类别标签。提取改进的密集轨迹(improved dense trajectory,IDT),并将每个视频分成25个帧段,每个帧分别与前一段、下一段有五帧重叠。对每一帧段,分别计算每个轨迹的运动边界直返图(motion boundary histograms,MBH)、方向梯度直方图(HOG)、光流直方图(histograms of oriented optical flow,HOF)描述符并被编码为Fisher向量[8]。然后,视频Vn表示为特征序列Xn,定义如下
(1)
1.2 PA仿射传播
PA是短动作模式,设一个PA集表示为ι={pi|i=1,…,Np},Np为PA集的数量。第i个PA称为Pi,定义为
Pi={fi,Mi,τi}
(2)
式中:fi为第i个PA的特征;Mi为PA检测器;τi为检测阈值。
为了计算fi,首先对所有的训练特征序列{X1,…,XN}进行仿射传播,以获得具有代表性的帧段并聚类所有帧段的索引[9],仿射矩阵A表示为
(3)
然后,对每个簇i,训练一个PA探测器Mi。通过引入SVM与核函数定义式(3),则簇内的片段为正样本,其余为阴性样本。利用libsvm库学习PA探测器[10],对于每个PA探测器Mi,通过设置检测阈值τi来建立训练数据序列,从而避免了含噪声序列模式的被挖掘。
PA可以通过无监督进行学习,在训练阶段,PA信息是无需注释的。此外,具有相似部分的运动可以共享相同的PA(例如跳高和跳远的跑动部分)。
1.3 序列索引
设一个特征序列为Xn,PA集为ι,将Xn转换为PA索引序列表示为
(4)
1.4 序列集学习
一个序列集表示了一个动作的局部结构,定义为R={Rj|j=1,…,NR},通过SPM从索引的训练序列[I1,I2,…,IN]中挖掘出R,第j个序列Rj定义如下
Rj={cj,sj,xj,wj}
(5)

为计算sj,首先收集培训数据索引Gc={n|yn=c},c∈[1,2,…,C]为表示特定运动类别c的标签。然后使用PrefixSpan算法[11]从收集到的训练索引序列{IGc(1),…,IGc(Nc)}计算序列模式,Nc为被标记为动作类别c的视频数量。算法中唯一的参数是支持率阈值η,sj的支持率vj可表示如下
(6)
式中:fj为在{IGc(1),…,IGc(Nc)}中出现sj的数量。当vj≥η时,PrefixSpan算法的输出是一个序列模式sj的集合。由于通过PrefixSpan算法所采集的子序列之间存在着相同的模式。因此需要对其进行后处理,将这些模式合并。除去其长度超过3的过度拟合模式。所以,序列集xj的特征可定义如下
(7)
式中:xj为在sj中对应索引的PA特征的序列。由于相同的序列模式可以从两个动作类中挖掘得到,所以设定一个权重wj
(8)
对于模式sj,wj表示sj的相对支持率。如果同样的模式发生在两个以上的动作类型,那么两序列集权重减少。反之,如果一个模式值出现在一个类型中,权重将达到最大值1。
每个序列集表示一个特定的动作类型,其包含了中层时间结构,对特定的动作类型具有重要作用。然而,相对于语法模型,序列集通过自动学习,无任何注释或先验知识的动作结构。图1为序列集学习显示。图1中数字为每个图像代表的PA索引,括号中的值表示每个序列集的权重。

图1 序列集学习
2 本文复杂动作识别算法设计
为了构造一个BOS模型,将视频表示为一个基本动作(PA)序列,形成一个序列集,从而保持其时间顺序。一个序列集是一个内容丰富的子序列,描述了动作的局部结构并保留了PA的时间关系。因此,BOS模型既有内容也有时序属性,对于类别多样性与视角变化,其可有效地模拟复杂的行动。设测试视频VT,序列集R,一个动作c的评分函数可表示为
(9)
式中:αj,c,βj,c,γj,c为在动作类别c中第j个序列集的参数。IT为序列索引,XT为VT的特征序列,φa(IT,sj)、φf(XT,xj)、φr(wj)分别为序列比对特征、表观匹配特征、序列集特征。详细介绍如下所述。
2.1 序列比对特征
φa(IT,sj)的作用是测量测试视频和序列集之间的结构相似性,设初始值F(n,0)=0,n∈[0,L];F(0,m)=-m,m∈[0,mj],L为在IT中帧段的数量。因此,联配分数矩阵F定义如下
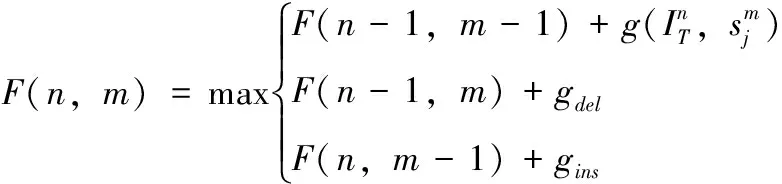
(10)
(11)
对于IT与sj的序列对比特征,当sj与测试序列相匹配时,φa(IT,sj)具有最大比对得分
(12)
2.2 表观匹配特征
φf(XT,xj)的目的是衡量测试视频与序列集间的视觉相似度,其表示如下
(13)
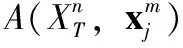
2.3 序列集特征
φr(wj)表示在特定动作类序列集的重要性,其定义为
(14)
当测试视频与序列集之间的结构相似性大于0时,选取其得到的值作为序列集的重要性。
2.4 BOS模型学习
根据上面的描述,式(9)可定义为
Sc(VT,ζ)=wc.ψ(VT,ζ)
(15)
式中:wc为αj,c、βj,c、γj,c的串联;ψ(VT,ζ)为φa、φf、φr的串联。对此,引入SVM对不平衡数据执行参数wc,c∈[1,…,C]测量,因此,优化问题变成
(16)
式中:C+、C-分别为正、负类别的正则化参数,学习之前,φa,φf为正则化为零均值和单位标准偏差。随着φa的变化,φf具有很大不同。通过对φf乘以常数λ来确保特征具有相似的范围。
2.5 分类学习
为了准确快速完成多动作的理解与识别,引入了一种有效的线性判别分析(LDA)[12]。LDA作为分类的思想是:希望获得的类间耦合度低,类内的耦合度高。意思就是要求类内散布矩阵Sw越低越佳;同时类间散布矩阵Sb越高越佳,这样才能达到最优的分类性能。对此,引入Fisher函数J
(17)
式中:φ为一个n维列向量。Fisher通过选取使J(φ)最大的φ为投影方向,投影后获得了最大Sb和最小Sw。根据Fisher的优化优计算,选择一组最佳判别矢量来建立投影矩阵W,表示为
(18)
在LDA学习中,利用PCA降维运算,消除冗余信息。
本文算法的过程如图2所示。将视频表示为多个PA序列,编码形成了PA的特征序列。然后通过仿射传播,将特征序列变换为PA索引序列。且将PA索引序列通过SPM形成不同的BOS,一个BOS描述了动作的局部结构并保留了PA的时间关系。在BOS模型中,一个动作可通过一个序列集来表示,无需对动作结构进行任何注释或先验知识,可以实现序列集自动学习。通过对BOS模型进行学习,计算其序列比对特征、外观匹配特征、序列集特征。最后,引入LDA学习,完成识别任务。

图2 本文算法框架
3 实验仿真与分析
3.1 实验准备与参数设置
为了评估算法的性能,选取2个常用数据集进行测验:MSR3D与UCF-Sport。测试环境为:Core I3,3.50 GHz CPU,4 GB运行RAM,Win7操作系统PC。开发工具:QT Creator+OpenCV。为了显示本文方案的优越性,通过将当前流行的动作识别方法进行对比,分别为:文献[5]算法、文献[6]算法和文献[7]算法,为便于书写,简写为A、B、C算法。为了获得最优的性能,通过多实验得到了参数值:σ=-1,Np=360,支持率阈值η=0.005,NR=1,λ=17.5,C+、C-分别为0.005、0.005/Nc,ρ=80。
3.2 数据集
MSR 3D是通过深度照相机获取的深度序列的动作样本[13]。MSR 3D通过10个演员表演20种不同动作。每种动作通过每个演员表演2到3次,共557幅序列组成。为便于测试,将20种动作分成3个子集,如表1所示。在每个子集中,50%数据用于训练,50%用于测试。

表1 MSR3D数据集分类
UCF Sport数据库主要从BBC/ESPN的收集的各种运动数据和YouTube中下载得到的数据组合[14]。UCF主要包含的动作类型有:basketball shooting、biking、diving、golf swinging、horse riding、soccer juggling、swinging、tennis swinging、trampoline jumping、volleyball spiking、walking with a dog。UCF含有的服饰、运动,相机移动、光照变化、背景等千奇百态,类似于现实生活。因此,对于动作识别具有一定的挑战性。UCF Sport数据集显示如图3所示。
表2为本文进行测试所用到的数据集与方法。表2中包含了每种数据种的动作类型,动作种类与样本大小,并且给出了其对应的实验方法。
3.3 实验结果
表3、表4与表5是在S1、S2和S3中通过提出的算法测量的混淆矩阵。从表中得出,绝大部分的动作类型能准确识别与理解,识别率高达95%以上。少部分动作识别率相对低一些,例如S1中的High arm wave易被误判断为Two hand wave、Forward kick。S2中的Golf swing易被误判断为Side kick。S3中的Tennis serve易被误判断为Golf swing。原因是这些动作轨迹相似较高,差异较小。
表6为在UCF Sport中利用本文算法获得的混淆矩阵。依据表6看出,本文算法在UCF Sport中具有优异的识别率。对biking、diving、horse riding、soccer juggling、swinging、trampoline jumping、walking with a dog“golf swinging的正确率高达95%以上。golf swinging、tennis swinging、volleyball spiking等的识别率相对较低。主要是这几种动作较复杂,变化速度快。

图3 UCF Sport数据集

表2 实验数据集与方法
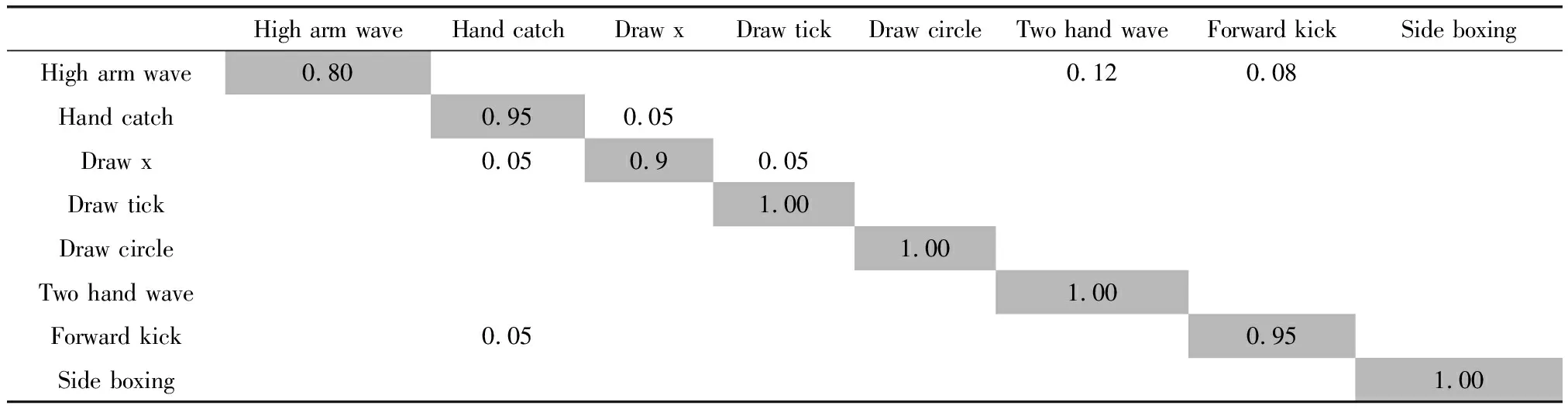
表3 S1子集的混淆矩阵
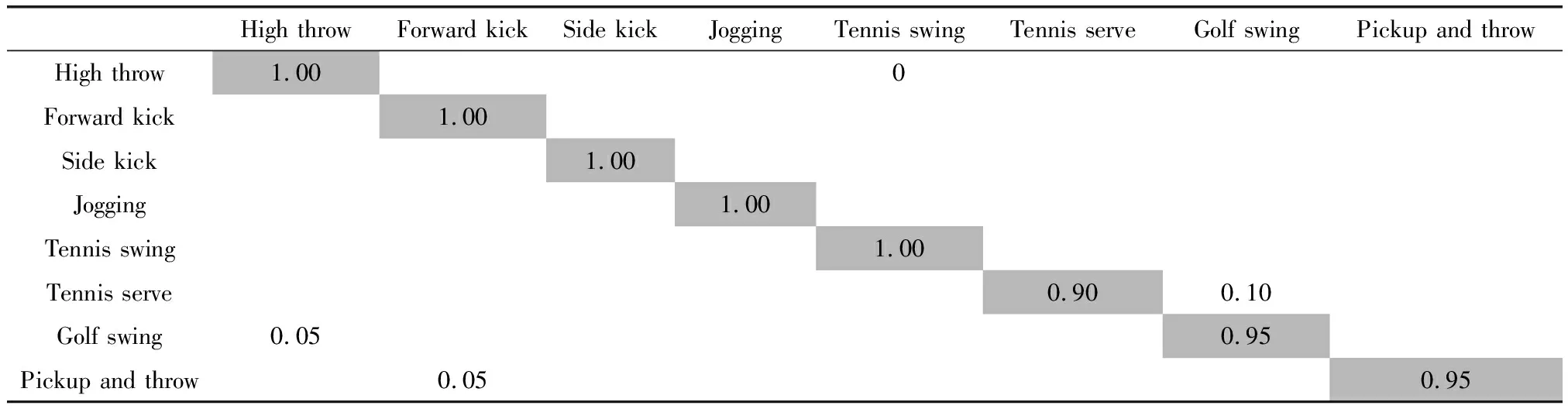
表4 S2子集的混淆矩阵
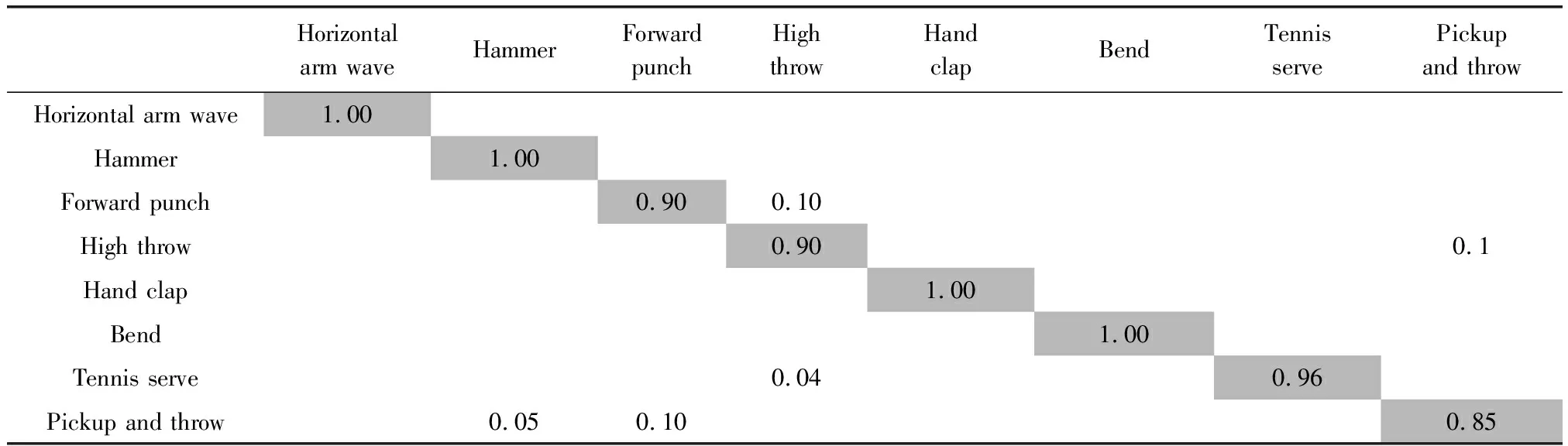
表5 S3子集的混淆矩阵
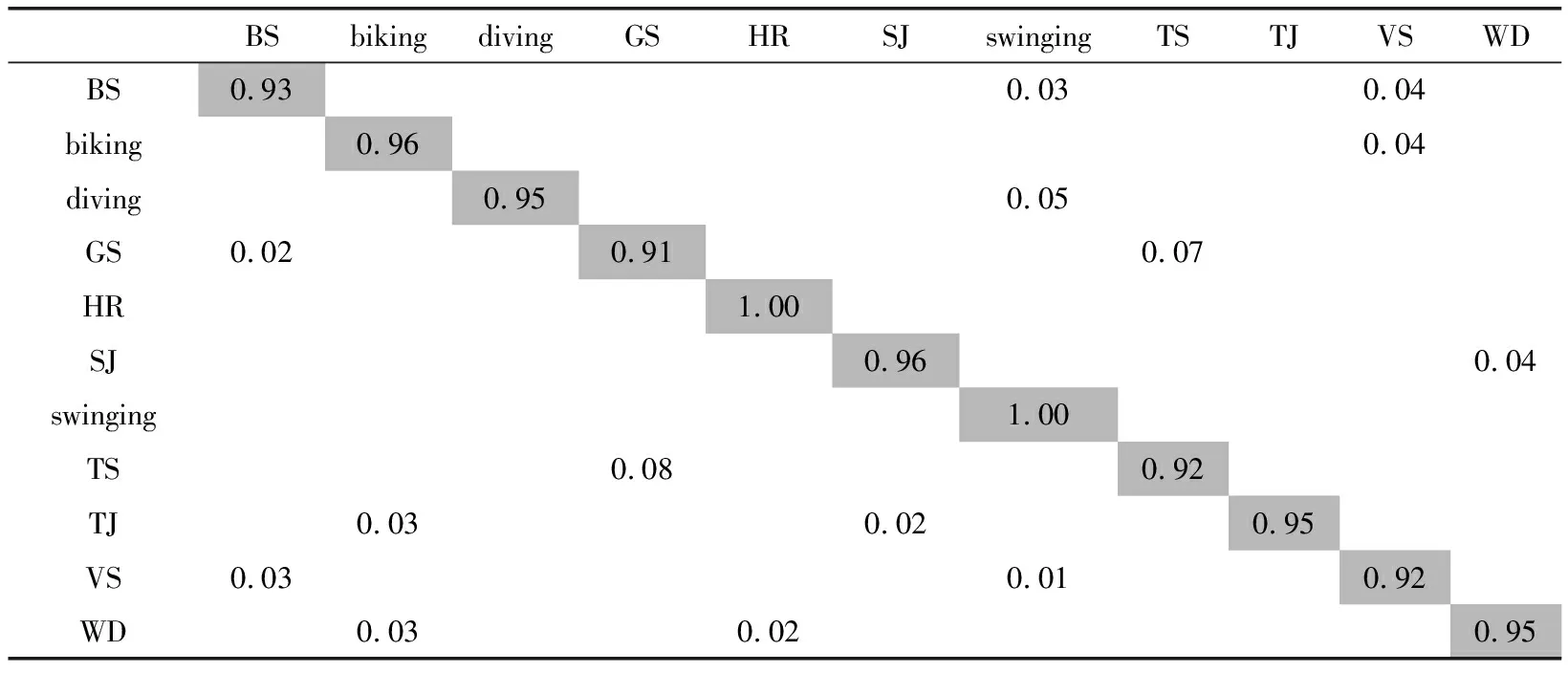
表6 UCF Sport数据集混淆矩阵
图4显示了在MSR 3D与UCF Sport数据集中,得到了A、B、C与本文算法分别动作的平均识别精度统计。根据图4中看出,在表2的数据集中,本文方法取得了优异的识别率,在MSR 3D与UCF Sport中分别达95.2%、94.5%,相对A、B、C方法取得了较好的表现。对于动作较简单的MSR 3D中,4种算法获得了一定的识别效果。但是在动作复杂的UCF Sport中,3种对照组算法明显处于劣势,而本文算法同样取得了优异的成绩,说明提出的算法对复杂动作识别同样有效。

图4 两个数据集中平均识别精度比较
图5显示了在MSR 3D与UCF Sport数据集中利用A、B、C与本文算法测量的Precision-Recall曲线[15]。从图5中看出,在4种算法中,本文方法法曲线表现最优,特别是对于复杂动作的UCF Sport中,本文方法的优势更明显,说明了本文算法性能相对对照组算法更优秀,能够较好适应复杂动作的识别。
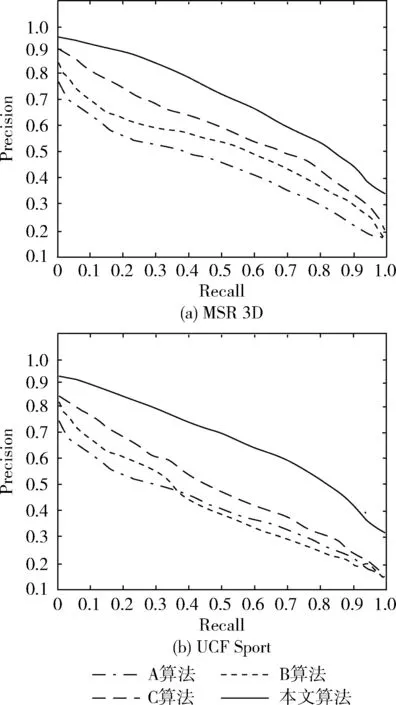
图5 不同算法的P-R曲线
本文算法在MSR 3D与UCF Sport取得了优良的效果,对复杂人体动作识别同样有效。主要是本文通过将视频转换为PA索引序列,通过SPM将得到的序列建立了BOS模型,利用构建的BOS模型能够有效描述动作的局部结构并保留了PA的时间关系。通过对BOS模型的学习,定义了动作的评分函数,从而无需对动作结构进行任何注释或先验知识,实现了序列集自动学习。有效地完成了对复杂动作的特征表示。最后引入LDA,根据动作的评分值进行分类学习,完成了动作的识别。而对照组A、B、C算法中在MSR 3D取得了较好的识别效果,但是对于复杂动作UCF Sport中识别效果不佳。
4 结束语
为了提高复杂动作识别的准确度,如体育赛事中的各种动作,本文设计了基于连续运动动作的复杂人体动作识别方案。利用PA索引序列对动作特征进行描述,并通过SPM构建了BOS模型。BOS有效描述动作的局部结构并保留了PA的时间关系,考虑了复杂动作的成分和时间特性,无需任何注释或行动结构的先验知识,从而使得BOS模型具有可扩展性。通过对BOS模型学习,建立了复杂动作的评分值,再根据LDA分类学习,实现对复杂动作的识别与理解。在MSR 3D与UCF Sport数据集测试表明了提出算法对复杂动作识别的有效性。
