基于语言模型的缺失数据追踪方法与应用分析
2018-10-23陈鲁雁王嘉梅袁长森
林 睿 陈鲁雁 王嘉梅 范 菁 袁长森
(1.云南民族大学云南省高校少数民族语言文字信息化处理工程研究中心 昆明 650500)(2.云南民族大学电气信息工程学院 昆明 650500)
1 引言
在“语音识别”时,机器通过一定的算法将语音转换为文字,显然这个过程是极其容易出错的。我们无法得到正确的识别,而且计算机也不懂语法,通过建立一个简单易行的模型(马尔可夫链)从概率上来判断各个识别的正确可能性。语言模型中的信息含量大,数据内涵多,并且被调查语言的潜在不定因素十分影响结果。追踪方法作为探讨大数据环境下,数据的缺失数据处理方法建立在特定的缺失机制上。例如被试语言的忽略、同音词语字母的错误辨识,被试者语言作答过程的忽略、回避等导致某次收集中研究变量数据不完整,或追踪过程中被试没有时间或不愿意参加等均是随机因素导致,数据比例缺失过大就会导致样本不具有代表性和估计偏差。通常认为,缺失率为5%~10%为可接受的,不超过三分之一为最合适[1];缺失率为60%以上的数据完全失去价值[2]。因此,随机缺失数据对于数据整理十分重要,采取特定的方法进行处理。
缺失数据处理方法的选择影响处理的精确性和研究结果的有效性。追踪随机缺失数据的方法主要有Deletion和singleimputation,两种方法简单易行,但会造成参数估计的偏差和统计功能的损失[3~4]。其中对于随机缺失的数据maximum likelihood esti⁃mation和multiple imputation使用最为合适。
本文着重介绍了在确定了语言模型以及收集了语言数据后,确定缺失机制,数据处理方法以及与常用方法的比较,对比几种方法对于语言模型的实现效果以及Matlab的仿真对比。同时将Matlab数据仿真软件同其他数据仿真软件结果优缺点对比。最后,针对语言模型的随机缺失数据追踪方法国内外研究对比提出一定的建议。
2 缺失数据简介
在对缺失数据进行处理前,了解数据缺失的机制和形式是十分必要的。将数据集中不含缺失值的变量(属性)称为完全变量,数据集中含有缺失值的变量称为不完全变量。缺失数据处理方法建立在特定的缺失机制基础上,缺失机制描述的是数据缺失概率与研究变量之间的关系[5]。Rubin[6]将随机机制分为三类:1)missing completely at random,MCAR;2)missing at random,MAR;3)missing not at random,MNAR。
假设被试个数为N,测试时间点个数为T,对这T个点进行样本追踪,研究的追踪变量为X=(x1,…,xm),观测的数据部分为 Xobs,数据遗失部分为Xmis,整体样本为 Xcom=xijt,i=1,2,…,N,j=1,2,…,M ,t=1,2,…,T。设定一个指示变量矩阵R=rijt。
MAR情况:若 xijt只与 Xobs有关,与 Xmis无关,见式(1):
(θ,ξ分别表示X,R分别表示函数参数)
MCAR情况:若 xijt与 Xobs,Xmis无关,见式(2)

MNAR情况:数据的测试结果依赖于未观测到的数据,不完全变量中数据的缺失依赖于不完全变量本身,这种缺失是不可忽略的。
3 语言模型简介
在“语音识别”这样的场景下,机器通过一定的算法将语音转换为文字,显然这个过程是极其容易出错的。例如,用户发音“Recognize Speech”,机器可能会正确地识别文字为“Recognize speech”,但是也可以不小心错误地识别为“Wrench a nice beach”。简单地从词法上进行分析,我们无法得到正确的识别,一个简单易行的方法就是用统计学方法(马尔可夫链)。
首先,我们定义一个有限的字典(字符串)V。V={the,a,man,telescope…},通过字典间有限或者无限次笛卡儿积[7],我们可以得到一个无限的字符串组合S,S可能包含:the,a,the man,the man walks;其次,假设我们有一个训练数据集,数据集中包含了许多文章。通过统计数据集中出现的句子、其出现次数c(x)以及数据集句子总数N,我们可以计算出每个句子的出现频率。令x∈S,p(x)=表示x的出现频率,显然∑p(x)=1。综上所述,我们可以发现几个问题:
1)上述的语言模型是理论上的,当训练数据集无限大的时候,数据集中的频率可以无限接近语法中实际的概率;
2)对于S中的大部分句子,p(x)应当等于0,因此S是一个非常稀疏的数据集,很难存储。
既然上面这个简单的语言模型不太完美,我们寻找其他的方法来获得语言模型,其中一个比较著名的算法就是马尔可夫链。假如考虑一个长度为n的句子可以利用一串随机变量来表示,即x1,x2,…,xn,其中xk∈V。那么,我们的目标是求p(X1=x1,X2=x2,…,Xn=xn)。
显然,

当n过大的时候,条件概率的复杂度会大大地增加,我们找到一个近似的方法方便求出这些条件概率,假设每个单词这个随机变量只与前k个随机变量相关。
由一阶马尔可夫链:

二阶马尔可夫链:

可得计算二阶马尔可夫的语言模型

4 语言模型缺失数据的追踪方法
对于某个对象的属性值未知的情况,我们称它在该属性的取值为空值(null value)。空值的来源有许多种,因此现实中的空值语义也比较复杂。总的来说,可以把空值分成以下三类:1)不存在型空值,即无法填入的值,或称对象在该属性上无法取值,如一个完全不知的语言词汇。2)存在型空值。即对象在该属性上取值是存在的,但暂时无法知道。例如知道语言词汇的部分或者属性范围内。3)占位型空值。即无法确定是不存在型空值还是存在型空值,这要随着时间的推移才能够清楚,是最不确定的一类。这种空值除填充空位外,并不代表任何其他信息。
4.1 随机缺失数据的传统处理方法
传统数据多基于MACR,例如删除元组,也就是将存在遗漏信息属性值的对象(元组,记录)删除,从而得到一个完备的信息表。这种方法简单易行,却有很大的局限性。它是以减少历史数据来换取信息的完备,会造成资源的大量浪费,丢弃了大量隐藏在这些对象中的信息。
数据补齐方法,这类方法是用一定的值去填充空值,从而使信息表完备化。通常基于统计学原理,根据决策表中其余对象取值的分布情况来对一个空值进行填充,譬如用其余属性的平均值来进行补充等。数据挖掘中常用的有以下几种补齐方法:
1)人工填写(Filling Manually)
由于最了解数据的还是用户自己,因此这个方法产生数据偏离最小,可能是填充效果最好的一种。然而一般来说,该方法很费时,当数据规模很大、空值很多的时候,该方法是不可行的。
2)特殊值填充(Treating Missing Attribute val⁃ues as Special values)
将空值作为一种特殊的属性值来处理,它不同于其他的任何属性值。如所有的空值都用“un⁃known”填充。这样将形成另一个有趣的概念,可能导致严重的数据偏离,一般不推荐使用。
3)平均值填充(Mean/Mode Completer)
将信息表中的属性分为数值属性和非数值属性来分别进行处理。如果空值是数值型的,就根据该属性在其他所有对象的取值的平均值来填充该缺失的属性值;如果空值是非数值型的,就根据统计学中的众数原理,用该属性在其他所有对象的取值次数最多的值(即出现频率最高的值)来补齐该缺失的属性值。另外有一种与其相似的方法叫条件平均值填充法(Conditional Mean Completer)。在该方法中,缺失属性值的补齐同样是靠该属性在其他对象中的取值求平均得到,但不同的是用于求平均的值并不是从信息表所有对象中取,而是从与该对象具有相同决策属性值的对象中取得。这两种数据的补齐方法,其基本的出发点都是一样的,以最大概率可能的取值来补充缺失的属性值,只是在具体方法上有一点不同。与其他方法相比,它是用现存数据的多数信息来推测缺失值。
4)使用所有可能的值填充(Assigning All Pos⁃sible values of the Attribute)
这种方法是用空缺属性值的所有可能的属性取值来填充,能够得到较好的补齐效果。但是,当数据量很大或者遗漏的属性值较多时,其计算的代价很大,可能的测试方案很具有缺失数据样本最近的K个样本,将这K个值加权平均来估计该样本的缺失数据。另有一种方法,填补遗漏属性值的原则是一样的,不同的只是从决策相同的对象中尝试所有属性值的可能情况,而不是根据信息表中所有对象进行尝试,这样能够在一定程度上减小原方法的代价。
4.2 基于随机缺失的方法
4.2.1 K-means clustering
先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均来估计该样本的缺失数据。这种方法要根据参照原始数据来估计相应的缺失数据,然后利用合并数据寻找K个相邻的值,从而得到唯一的解。对于空间相应的应用函数,欧式距离最为合适,合并函数是K个相邻值的简单平均,有时也使用加权平均,我们假设K=1,距离为欧式距离。见式(3):

数据源确定后,计算相应的统计量,利用已有的特征值公式进行K-means方法计算。
4.2.2 极大似然估计
MLE通过构造似然函数并求函数最值来获得参数的估计。当Ymis存在时,难以求解似然函数的最值,目前通过特殊方法如期望值最大算法(EI)和全息极大似然估计算法(FIML)算法解决问题。对于语言模型中的缺失数据两种方法非常适用。
1)语言模型EI算法
EM算法[8]的基本思想是 Xmis含有与参数θ有关的信息,而参数θ反过来有助于寻找最有可能的Xmis值。基于 Xmis与参数θ的依赖性,EM算法以设定参数的初始值θ(0)为起点进行迭代运算:依据计算出参数估计θ(k+1)。每一步迭代由条件期望步(E步)和极大化步(M步)构成[9]。
条件期望步(E步):在θ(k)的基础上,计算似然函数对 Xmis的条件期望如式(4):

极大化步(M步):极大化 Q(θ|θ(k))求得估计值θ(k+1)即:

EM算法的每一次迭代使得似然函数值增加。如函数有界,序列将收敛到一个平稳值,一般情况下平均值为的极大似然估计值[10]。通过上面两部,EM算法将缺失的语言模型问题转化为重复解决完整语言模型数据的问题。
将追踪的语言模型转化为4×5四个高斯分布混合,五维样本的语言模型应用EM算法得到的Matlab仿真结果如表1,表2所示,可得EM算法对语言模型的缺失数据追踪的准确率可以达到92.73%。

表1 语言模型中基密度高斯函数的权重

表2 模拟语言模型矩阵均值估计
2)语言模型FIML算法
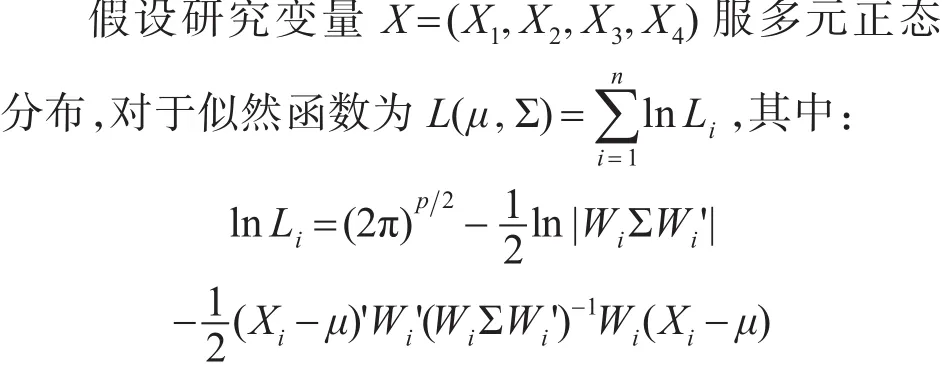
n为样本量,p为被试i有观测值的变量个数。对于 p=4的被试i,Wi为单位矩阵。若被试在第 j个单位矩阵。若被试在第 j个变量上有缺失,Wi则为单位矩阵去掉第 j行后形成的矩阵。
同EM算法的语言模型进行Matlab仿真和数据追踪对比如表3可得EM算法对语言模型的缺失数据追踪的准确率可以达到91.64%。
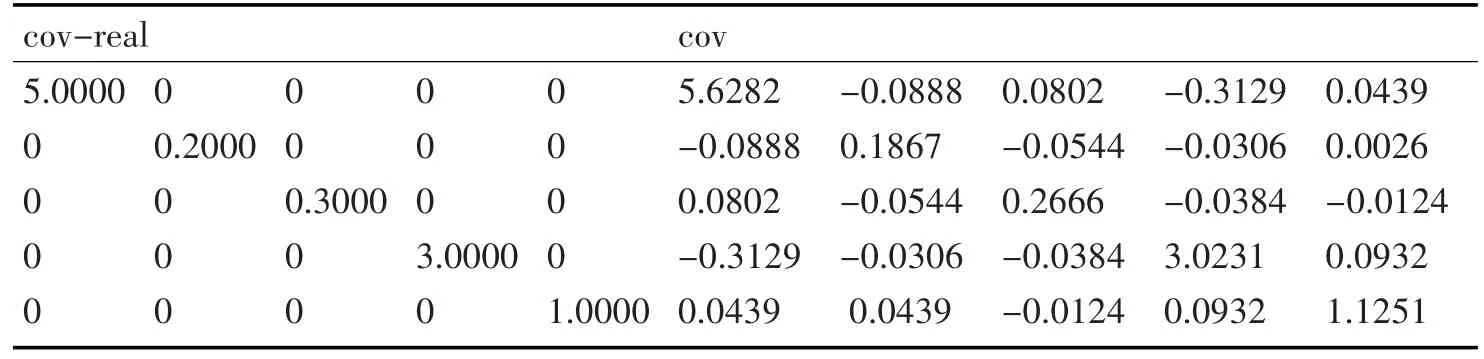
表3 FIML算法中语言模型模拟矩阵协方差估计对比
5 语言模型缺失数据处理方法选择以及软件实现
5.1 处理方法选择
一种优秀的处理方法应该具备以下三个标准:标准1,处理缺失数据过程可能考虑造成处理数据的原因,特别是辅助变量。标准2,采用与数据分析相同的模型处理缺失数据。标准3,可得到无偏估计和合理的标准率[11~12]。
结合语言模型的特殊性,我们引入缺失机制判断方法同传统的判断方法相结合:1)MCAR机制检验,若变量xi上有无缺失的两组数据样本的分布一致则为MCAR[13]。2)MAR机制检验,检验判断语言样本1中(未参与t+1,…,T时间点测试的样本)是否为语言样本2中(参与t时间点测试的样本)的随机样本,若是则为MAR。上述缺失处理方法在三个标准中的比较见表4。

表4 语言数据缺失处理方法的表现
语言学研究和追踪研究中处理不存在一种最佳方法,我们在考虑了语言相对属性和数据的缺失机制后,针对特殊情况进行数据处理,已达到数据的追踪处理最优化。1)简单的语言模型数据,可以使用传统方法进行分析,节省时间和精力。2)对于MCAR,如果缺失率小,达到10%以下且完整观测样本满足统计分析要求,传统方法是便捷有效的方法。若缺失率较大,则EM和FIML为有效的方法。3)EM算法较于其他的方法更容易引入辅助变量。
5.2 软件实现
目前的数据追踪软件比较多,心理学和统计学中的常用统计软件有:SPSS、SAS、R、MPLUS、HLM和LISREL等,Matlab实现语言模型的数据追踪更方便,详细比较见表5。

表5 缺失数据处理方法的软件实现
所以建议在处理语言模型缺失数据追踪时多使用Matlab,虽然Matlab的程序实现比较繁琐,但准确率较高。
6 结语
通过两种方法基本可以解决马尔科夫语言模型中的基本数据缺失问题,确定缺失数据类型,追踪缺失数据位置和所缺失的数据。使用方便快捷解决问题,但准确率有待提高,使得数据完整性更高。更要加强贝叶斯理论下的缺失数据讨论,进一步研究非随机缺失机制下的语言模型数据追踪和数据完善,从而为语言学研究进一步贡献方便的研究方法。
