城市轨道交通线网能耗大数据平台设计
2018-10-22王志心李佑文褚红健颜儒彬
王志心,李佑文,褚红健,颜儒彬
(南京国电南自轨道交通工程有限公司,江苏南京 210032)
0 引言
城市轨道交通是一种快捷高效、安全舒适的城市公共客运交通方式,其在解决城市交通拥挤和促进城市社会、经济发展等方面具有极其重要的作用。同时,城市轨道交通也是耗能大户,仅电费一项就占运营直接成本的 20% 左右。为了掌握用电情况,运营单位通常建设线路能源管理系统用于对全线用电参数进行采集、监控和存储[1-2]。但随着城市轨道交通网络化运营的发展,目前的能源管理系统存在重复建设、相对封闭(只能实现单线路的采集和监测)、数据格式不一、统计分析方法较少等缺陷。
本文根据城市轨道交通能耗特点,构建了基于Hadoop的线网能耗大数据管理平台。线网能耗平台可以实现对线网所有线路用电参数以及能耗分析相关数据的采集、监测和存储,有利于实现对线网能耗的管理、评估以及线路之间能耗的对比、考核和管理。同时可以节约建设成本,避免线路能源管理系统的重复建设。
1 平台架构设计
线网能耗大数据平台基于 Hadoop 技术实现,平台架构如图 1 所示。整个平台由数据源、数据采集、数据处理、数据存储、数据发布以及系统管理几部分组成。下文中将对其中主要部分进行详细描述。
1.1 数据接入
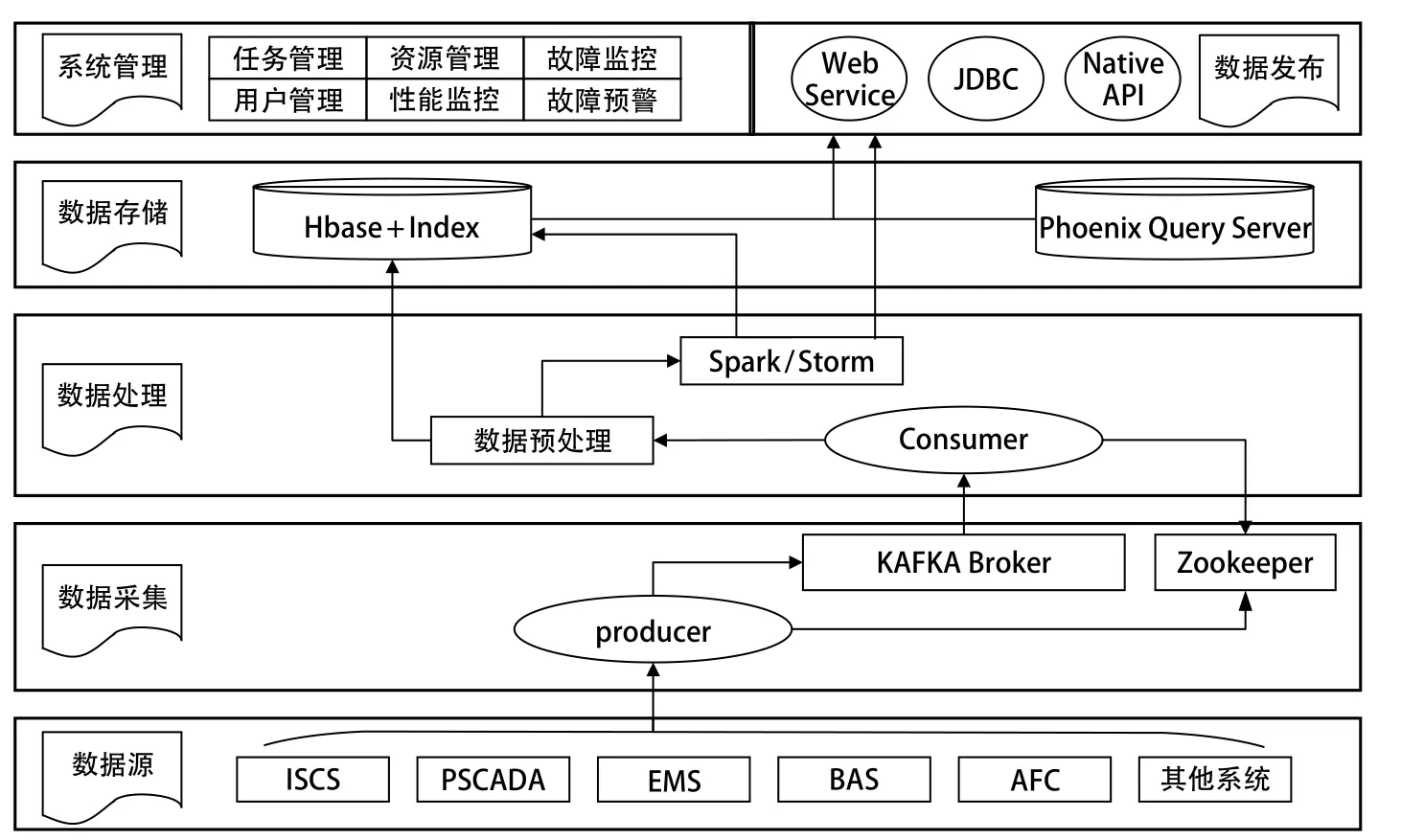
图1 大数据平台架构
线网能耗大数据平台通过通信网络连接各线路专业系统,实现对能耗及能耗分析相关的实时及历史数据的采集。采集数据主要包括以下几类:①线路 100 kV、35 kV、1 500 V、0.4 kV 等高低压柜的电能数据;②线路各车站 BAS 系统环境参数;③车站通风空调系统中各类设备运营模式及运行参数;④线路各站客流数据;⑤其他数据。
为了缓解后台服务器端的数据处理压力,整个架构引入数据接入队列系统来缓冲客户端发送过来的消息,以供后续程序处理,并提供消息的实时处理和持久化保存。
本文所述的架构方案中,采用 KAFKA 作为数据采集接入的消息队列系统。KAFKA 是一个分布式的消息发布订阅系统,具有高吞吐、内置分区、容错功能,所以特别适合大规模消息处理应用。KAFKA 逻辑结构如图 2 所示。
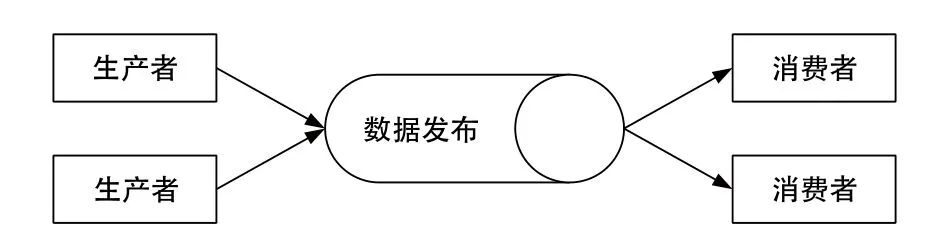
图2 KAFKA 逻辑结构
图2中,消息的生产者创建消息数据,消息的消费者消费消息数据。生产者使用 push 模式将消息发布到 Broker,消费者使用 pull 模式从 Broker 订阅并消费消息。数据按主题(Topic)进行划分,本方案中各线路上传数据按照线路、数据类型、实时或历史数据等创建不同的分区,如 ISCS_TOPIC、PSCADA_TOPIC、EMS_TOPIC 等等。
1.2 数据处理
架构方案中,数据处理分为数据预处理和实时计算处理 2 个部分。基于 Hadoop 生态圈 Spark/Storm 流式计算框架,通过其多线程处理和高效的并行化任务使得数据处理过程的效率得到显著提高。
消费者端从 KAFKA Broker 中 pull 数据后,首先通过数据的预处理环节对数据的完整性及合理性进行检验,并对异常数据进行修正,处理内容包括:①数据数量应等于预期记录的数据数量;②数据的时间顺序符合预期的开始、结束时间,并且中间应连续;③数据进行越限检验,删除越限数据,并以前一时刻数据代替;④所有经过修正的数据应以特殊标示记录。
经过预处理环节的数据通过接口保存至 HBase 中,作为其底层基础数据。同时一部分与实时业务相关的数据,发送至实时计算处理环节。实时计算处理部分的内容可根据能耗平台的实时业务需要进行定制,一般包括实时能耗统计、实时总功率计算、能耗异常报警等等,实时计算的结果直接提供给业务系统使用。
1.3 数据存储
1.3.1 HBase+Phoenix 架构设计
HBase[3]是以 HDFS 为底层存储的分布式的列存储数据库,在非结构化、大数据存储、分析方面具有很好的性能。但是 HBase 不支持 SQL 操作,只能利用其 API 进行操作,使用不便,使得应用业务通过性不好、开发成本较高。
Phoenix[4]是在 HBase 上构建 JAVA 中间件。通过Phoenix 可以使得业务应用像使用 SQL 访问关系型数据库一样访问 HBase,从而降低业务开发成本。Phoenix引擎将 SQL 查询转换为 1 个或多个 HBase Scan,并编排执行以生成标准的 JDBC 结果集,规避了 Map-Reduce 框架的繁琐计算过程,减少了查询时间延迟,对 HBase 入侵性极小,也不影响 HBase 单独使用的其他操作。相对于Hive 和 Impala 而言,Phoenix 的性能很高,对于简单的低延迟查询,其性能量级为 ms,对于百万级别的行数来说,其性能量级为 s。
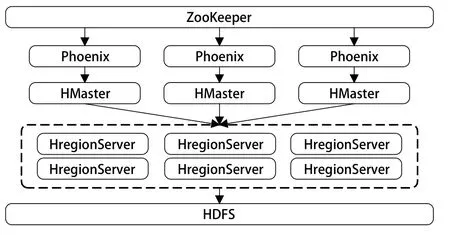
图3 HBase+Phoenix 架构
如图 3 所示,集群任务由 ZooKeeper 分布式应用程序协调服务统一调度,ZooKeeper 通过 2181 端口将任务传给分布在 HBase 上层的 Phoenix,Phoenix 解析并执行任务内容,然后使用 JDBC 连接将处理好的任务通过 HMaster 传给 HBase,最终任务数据通过 HBase 持久化存入 HDFS 中。
1.3.2 数据分层存储
线网能耗大数据平台需要存储全线 3~5 年的历史能耗数据,用于支撑数据查询和统计分析功能。大量的数据简单保存在历史数据库中,必然造成查询搜索缓慢,且不利于数据库的维护管理。本方案根据数据仓库的分层管理思想,将数据分为基础数据层、汇总数据层和专用数据层 3 层结构,并针对每一数据分层分别在HBase 中创建对应的命令空间。
基础数据层保存经过预处理的基本能源数据,不同线路、专业的数据保存在不同的数据表中,表 1 为线路基础能耗数据表。

表1 基础能耗数据表(basic:line1_p)
如表 1 所示,HBase 通过行键(Row Key)、列簇 (Column Family)和列(Column)组成表结构。上表中根据HBase特性,将查询的关键信息(车站 ID、设备ID、采样时间、采样类型等)拼接作为 KEY 键值以实现记录的快速定位,满足应用层复杂查询。
汇总数据层将基础数据按照能耗分类/分项/分户(如线路、车站用电量,牵引、照明用电量等)以及不同时间粒度(小时、日、月、年用电量等)进行不同粒度的汇总统计,表 2 为线路分项用电统计表。

表2 线路分项用电统计表(mid:line_category_total)
专用数据层面向统计分析功能、能耗指标、报表等业务设计,通过定期对基础数据和汇总数据运算统计并存储,直接供各业务应用使用。
2 测试系统搭建
整个 Hadoop 生态圈由 4 台惠普 DL580 Gen8 服务器搭建,分别在各个服务器内部署了 Hadoop 生态圈内的组件。服务器配置如表 3 所示。在实际工程应用中,线网能耗大数据平台主要用于实现对线网各线路数据的实时采集以及对各类应用业务提供数据支撑。所以,本文模拟实际线网(16 条线路)能耗大数据平台的数据容量分别进行数据采集及数据查询两方面的测试。
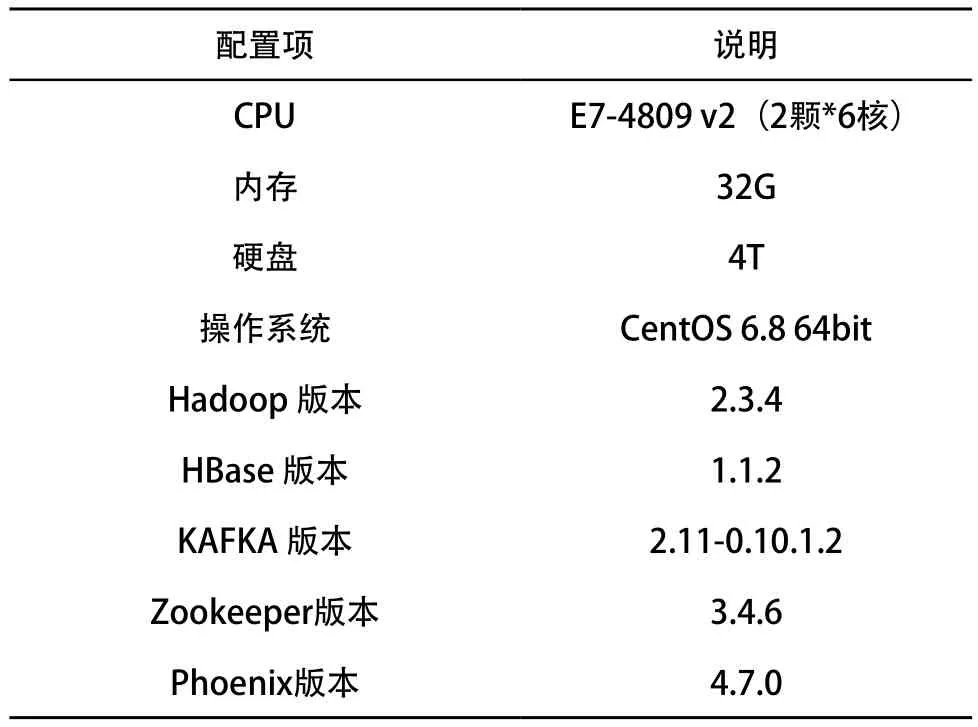
表3 服务器配置
2.1 数据采集测试
每台服务器运行 4 个生产者、4 个消费者线程。假设各线路能耗数据来源于单一的业务系统,在 KAFKA集群内针对各线路分别划分了主题,如 TOPIC_LIN1、TOPIC_LIN2 等,每个主题分为 3 个 Partition 分区,保留2 个副本进行存储。
一般情况下,地铁单线路中能耗数据点数(包括相电压、线电压、电流、功率、功率因素、电能等)在2 万~5 万点之间。本次测试按照不同的数据采集个数进行了多次模拟测试,多次测试平均值如表 4 所示。
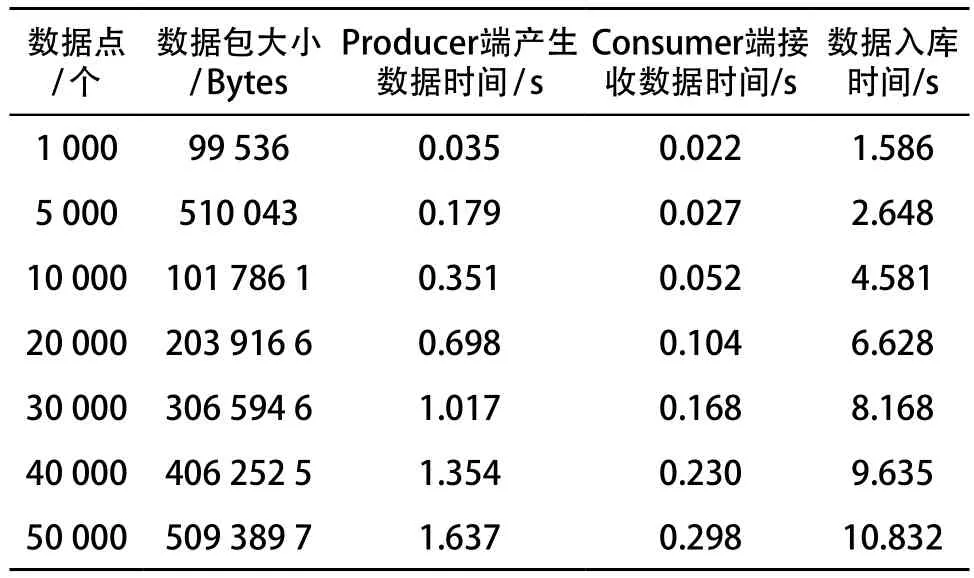
表4 KAFKA 测试结果
根据上述测试结果,KAFKA 性能已经非常优异,其性能也远远高于一般的 JMS 产品。 同时 HBase 写入性能很好、并行度高,在测试过程中,集群 CPU 资源使用率不超过 50%,磁盘繁忙程度大致在 70%~80%。测试结果表明,设计方案能够满足线网能耗数据平台的业务需要。
2.2 数据查询测试
本次查询性能测试采用能耗点数据查询作为测试用例。能耗点数据查询即根据指定的能耗数据点 ID 从数据库中查询一段时间内的历史能耗数据,通过记录数据检索所花费的时间评估数据查询性能。
在 HBase 中,基础能耗数据按照线路划分,以月份为单位进行存储,每条线路包含 5 000 电度量测点,采集周期 5 min,线路单月历史能耗数据记录为 5 000×288×30 = 4 320 万条。
查询测试语句:
SELECT TIMESTAMP,VALUE FROM WHERE DEVICEID=XXX AND TIMESTAMP>=XXX AND TIMESTAMP<=XXX
100 次查询测试结果如表 5 所示:
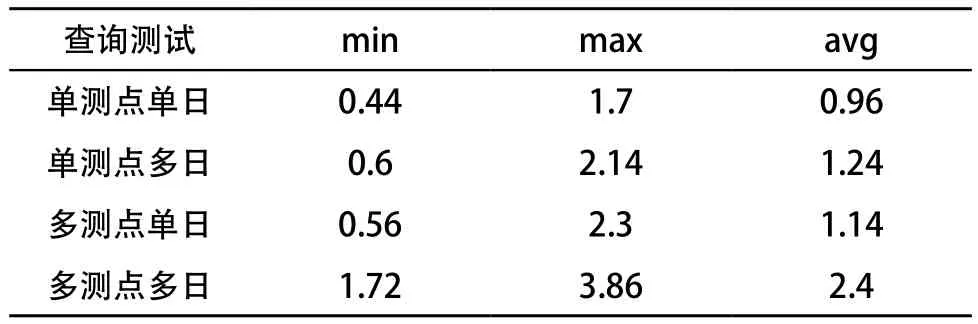
表5 数据查询测试结果 s
为更好地评估架构 HBase+Phoenix 的性能特点,本文采用上述基础能耗数据表进行了并发测试,测试过程中模拟 100 用户同时发起查询操作,测试结果如表 6 所示:
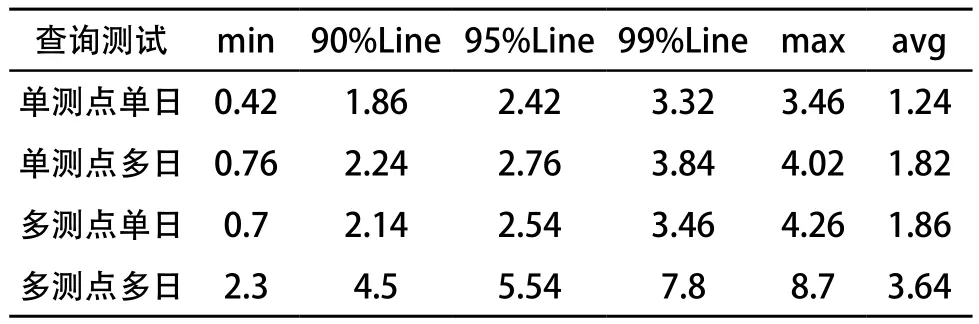
表6 多用户并发查询测试结果 s
以上测试结果表明, HBase 数据库具有构建大表的优势,并且使用 HBase+Phoenix 的组合架构能够满足业务对数据查询的需要。
3 结语
本文根据城市轨道交通能耗特点,构建基于 Hadoop的线网能耗大数据平台,实现对线网所有线路的用电参数以及能耗分析相关数据的采集、监测与存储。文章中针对大数据平台整理架构以及架构中数据接入、数据处理、数据存储几个部分进行了详细说明,并通过搭建测试平台对方案可行性进行了评估。测试结果表明,本方案能够满足对线网各线路数据的实时性要求以及对各类应用业务提供数据支撑。
