车载信息融合下的混合驾驶工况识别
2018-10-22刘海江章晓栋
刘海江,章晓栋
(同济大学 机械与能源工程学院,上海 201804)
整车驾驶性是评价汽车纵向动力学性能最重要的属性之一,反映了驾驶员在汽车纵向行驶过程中人车交互作用下的感觉[1]。其体现了汽车产品的市场定位与品牌基因,是影响消费者购买意愿,提升产品竞争力的关键。整车驾驶性具体表现为在车辆驾驶过程中出现的起步熄火、动力不足、加速响应缓慢等现象,这些现象均隐含在整车起步过程、加速过程、瞬时给油/断油过程等驾驶工况中,由实时采集得到的汽车性能参数数据形态进行反映。因此,从客观数据的角度出发,通过定义整车各驾驶工况的特征参数,从而实现工况的自动精确识别,是整个驾驶性评价过程中必不可少的工作,也是提高整车驾驶性开发效率的一大措施。
国外相关企业在针对整车驾驶性客观指标体系的构建及评价方法方面已展开了一定的研究。CHANG等[2]建立了驾驶人员自身的振动感觉与车辆主观评估之间的映射关系,使用神经网络法构建了一套能量函数及校准方法来客观地评估车辆驾驶性。HAYAT等[3]在研究各个子系统对于车辆驾驶性影响的基础上,采用动态建模、分析及仿真技术,分析了车辆在多种驾驶工况下的动态表现。但对于作为评价指标来源的驾驶工况片段数据的分类识别,还缺乏一定的研究。国内对于整车驾驶性客观评价的研究还处于起步阶段,而且当前根据车载数据进行的识别研究多集中于根据车载数据识别驾驶行为及状态的优劣上[4-6]。刘军等[7]根据从转角数据中提取的角度标准差和静止百分比,建立了驾驶员疲劳状态判别模型。郭孜政等[8]采用单因子方差分析提取驾驶危险状态辨识主因子,基于贝叶斯判别构建了驾驶行为危险状态辨识模型。李振龙等[9]通过方差分析和均值分析选取方向盘转角作为识别特征,并分别采用KNN和SVM构建了醉酒驾驶状态识别模型。胡月等[10]提出了与纵向加速度、冲击度等相关的驾驶性客观评价指标,初步建立了瞬态工况的驾驶性客观评价方法。
本研究通过多传感器信息融合,对比了整车在不同驾驶工况下的数据表现,结合汽车试验理论与专家知识,定义并提取了与工况识别分类相关联的特征参数。在此基础上,采用C4.5决策树及朴素贝叶斯法进行混合驾驶工况分类模型的搭建,并通过测试验证,对比评价了所建立的分类识别模型的效果。
1 特征定义与提取
1.1 试验设计
研究过程中,首先采用驾驶性道路试验,而非模拟仿真的方式,由驾驶员在规范的跑道内执行各工况下的驾驶动作。与此同时,采用集成了多传感器(如从IMU获取纵向加速度信号,从OBD接口获取CAN总线数据)的数据采集设备对多源车载信号进行同步采集,并通过数据清洗,提取与整车驾驶性紧密相关的6类信号的数据,包括加速踏板开度、纵向加速度、车速、发动机转速、挡位及制动信号。
1.2 车载多传感器数据融合
由于对驾驶工况的识别及分类无法通过单一数据源的分析实现,所以采用信息融合技术,通过多传感器数据的组合,从不同维度进行综合分析。信息融合按数据抽象的不同层次,可分为像素(数据)层、特征层及决策层的融合[11-12]。为保留结果的精确性,本研究采用数据层目标特性融合的方式,针对驾驶工况自动识别的目标,对经预处理的原始数据进行特征提取与特征集构建。
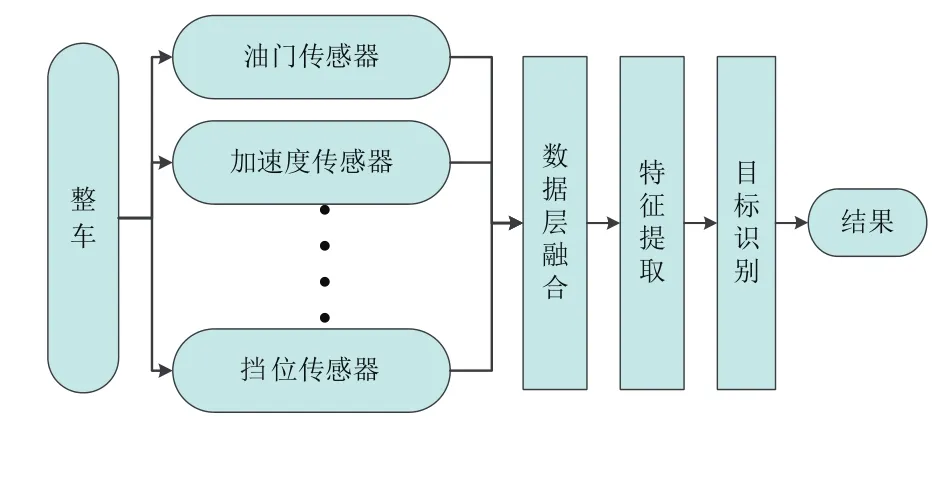
图1 车载多传感器数据层融合
1.3 工况定义与特征描述
特征提取的首要工作,是对整车驾驶性开发与试验过程中所出现的各驾驶工况从数据表现层面进行清晰的定义。通过研究整车起步过程、加速过程、瞬时给油过程的操作规范,结合对经预处理后传感器数据的分析,完成各工况下相关特征参数的提取。具体如下:
(1)整车驾驶性试验中,起步过程操作定义为:松开制动踏板后2 s内,在蠕行或车速为0的状态下在1 s内踩下加速踏板至某一目标油门开度。
如图2所示,基于专家知识对该过程的数据形态进行分析,得到起步过程的数据特征:①存在加速踏板开度变化率较高的触发点,在1 s内触发上升至大于20%。②无换挡事件发生。③加速踏板触发前2 s内存在制动信号。④加速踏板触发前车速为0或处于蠕行车速。由此提炼,得到特征参数为:加速踏板变化率;油门触发前车速;挡位变化;制动信号。
(2)整车驾驶性试验中,加速过程操作定义为:固定挡位下,缓慢地(5~7 s)将油门开度从0均匀踩到目标值后结束,并且整车初始状态为蠕行状态。
如图3所示,同理,得到稳车速瞬间给油过程的数据特征:①在>2 s内加速踏板均匀上升至一目标值(>30%)。②无挡位变化。③加速踏板触发前车速处于蠕行车速。由此提取特征参数为:加速踏板变化率;油门触发前车速;挡位信号。
(3)稳车速瞬间给油过程操作:将车速稳定至目标车速(±1 km/h)3 s后,执行瞬间的(<0.2 s)目标油门开度输入。
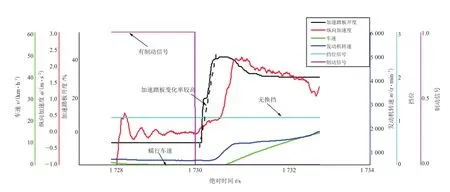
图2 整车起步工况预处理后数据
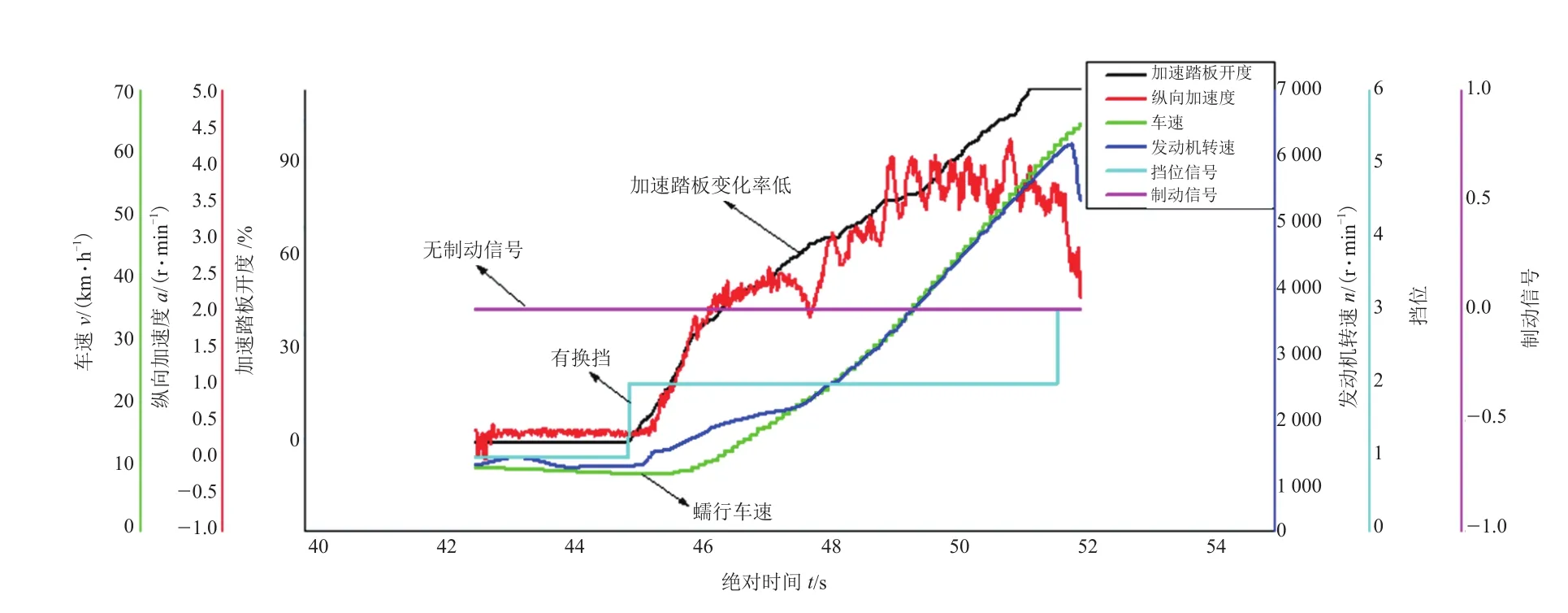
图3 加速工况预处理后数据
如图4所示,稳车速瞬间给油过程的数据特征为:①存在加速踏板开度变化率极高的触发点,在0.2 s内触发上升至大于30%。②数据窗内无制动信号。③加速踏板触发前3 s内车速处于稳定的目标值。由此得到特征参数为:加速踏板变化率;油门触发前车速;制动信号。

图4 稳车速瞬间给油工况预处理后数据
1.4 特征提取与特征集构建
结合上述分析,将各工况下描述的特征参数进行提取与组合。通过定义统一的数据窗Ri=[油门触发3 s前时刻,油门触发5 s后时刻],可得组合后的特征属性集为:
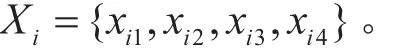
式中:xi1为加速踏板变化率;xi2为油门触发前车速;xi3为挡位变化;xi4为制动信号。其中,xi1和xi2为连续型特征参数,其它均为离散型特征参数。
将不同工况类别进行组合,得到输出集为:
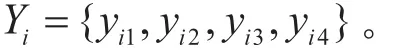
式中:yi1为起步;yi2为加速;yi3稳速瞬间给油;yi4为其它。
将特征参数集与输出集相结合,可得到样本集合:

为简化样本集的表示,将集合中所含的自然语言进行归一化处理:(1)“有”、“无”分别标记为“1”、“0”。(2)“起步”、“加速”、“稳速瞬间给油”、“其它”分别标记为“1”、“2”、“3”、“4”。
根据上述建立的规则,基于某自主品牌车型大量驾驶性试验数据建立样本库。从中提取部分样本数据,经归一化处理后见表1。
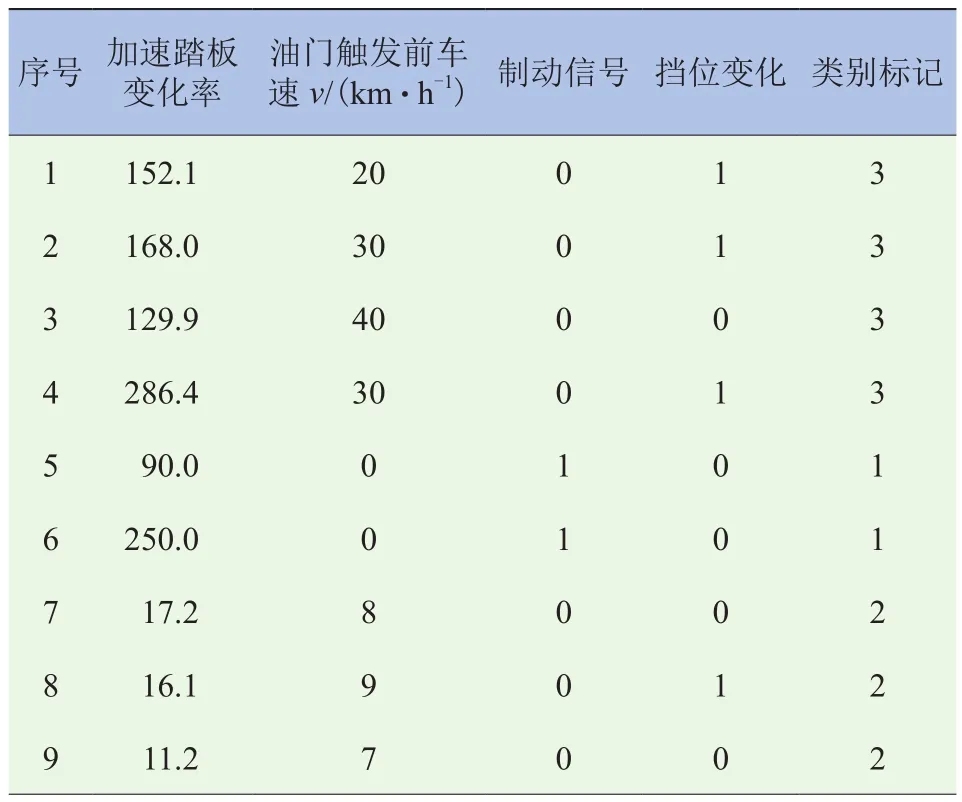
表1 样本集示例
2 模型构建与测试
由于当前已建立的样本数据库仍属于小规模数据集的范畴,为防止结果欠拟合,不采用神经网络等常用于解决大数据量问题的分类/预测模型,而基于概率统计学理论,分别选用决策树及贝叶斯法进行建模。
2.1 基于C4.5算法的混合工况识别分类
2.1.1 C4.5决策树分类方法
C4.5算法属于决策树学习算法的一种,表示对象属性和对象值之间的一种映射。其继承了ID3算法的优点,采用信息增益率来选择特征属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足,且对于连续型的特征属性,C4.5算法能够完成对连续属性的离散化处理。
2.1.2 基于C4.5算法的模型构建与测试验证
(1)连续属性离散化。C4.5决策树算法采用二分法对连续属性进行离散化处理[13]。对于本研究中的样本数据集D,设连续属性P(加速踏板变化率)在样本集上出现的有序序列为{ p1, p2,..., pn},选择在pi与pi+1间取候选划分点ti = ( pi+ pi+1) /2( 1 < i< n −1),可将样本集划分为2个子集。此时,通过改进后的信息增益公式计算每一候选划分点:
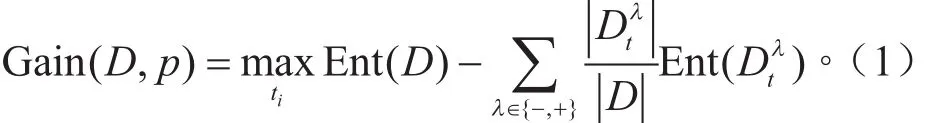
可得到使信息增益最大化的最终划分点(Ent(D)即为样本集D的信息熵)。
(2)分类模型训练与测试。将连续属性离散化后所取得的最大信息增益值与其它离散属性进行比较,选择信息增益值最大的属性作为C4.5决策树的根结点进行划分。依次类推,递归执行节点划分过程。
选取已有的84个训练样本及22个测试样本构成样本集,采用Python编写决策树学习算法对样本集进行训练与测试。训练所得的C4.5决策树模型如图5所示。
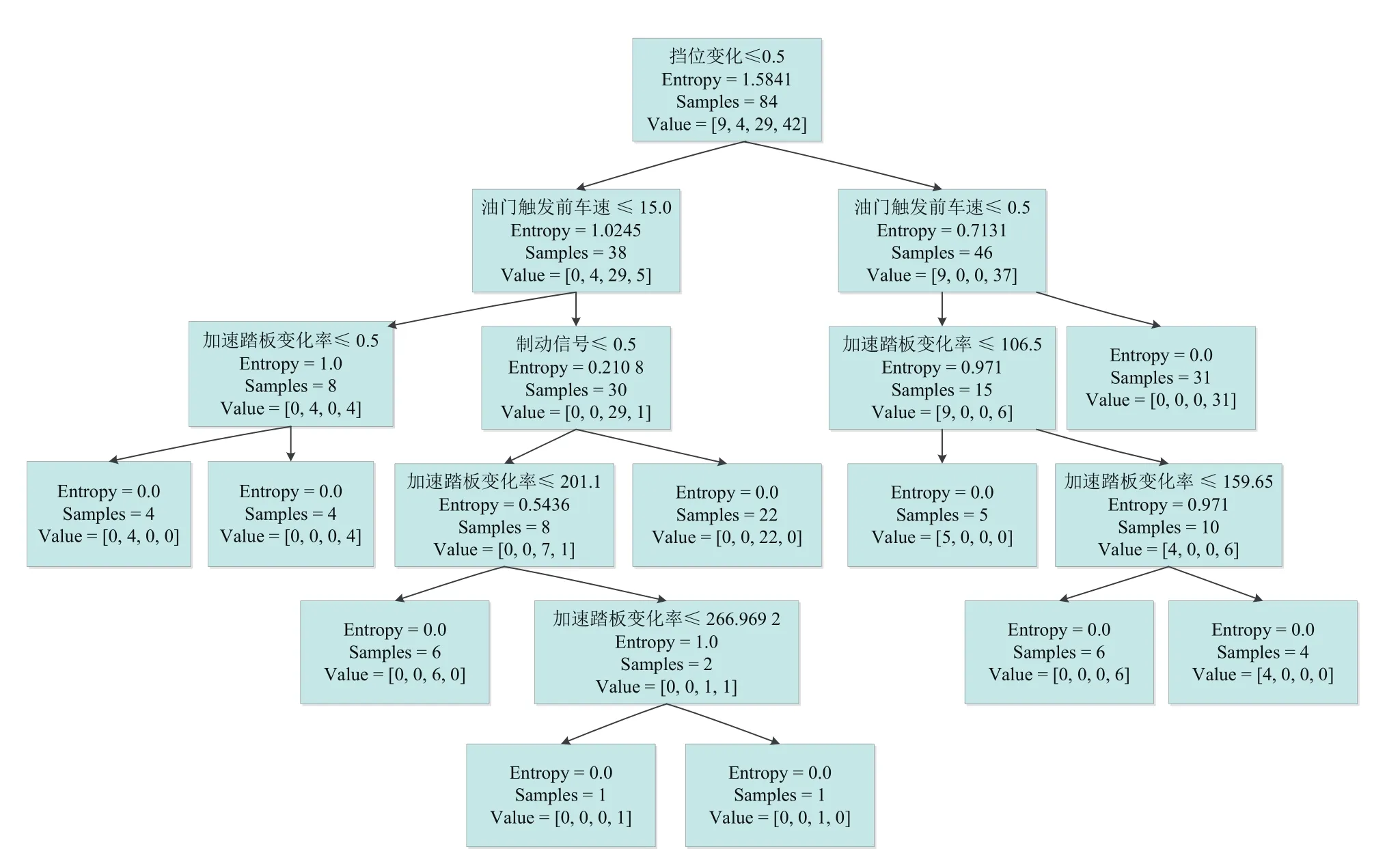
图5 混合驾驶工况C4.5决策树分类模型
由图5可知,决策树深度为6,且“挡位变化”属性的信息增益率最高。
对当前生成的决策树进行保存,并输入测试样本对其进行验证。采用混淆矩阵,对模型测试结果进行可视化,结果如图6所示。
混淆矩阵中,列代表对具体工况的预测结果,行则代表的是每一样本的真实类别。由图6可知,测试集中存在5个起步工况,6个加速工况,8个稳速瞬间给油工况及3个其它随机工况。预测结果显示,对于各工况的识别,分类准确率为(5+6+8+2)/(5+6+8+3)=95.5%,分类模型的准确率较高。只有一组真实类别为随机工况的样本被错误分类为起步工况。

图6 分类混淆矩阵
2.2 基于Naive Bayes的混合工况识别分类
2.2.1 朴素贝叶斯分类方法
贝叶斯概率及贝叶斯准则提供了一种利用已知值来估计未知概率的有效方法。其中,朴素贝叶斯方法基于对特征属性独立性的要求,在样本数据较少的情况下仍然有效,且可以处理多类别问题。
2.2.2 模型构建与测试验证
假设所提取的特征属性集中各特征均相互独立,则基于朴素贝叶斯方法,针对每个样本 ,需要寻找使后验概率P( yi|xi)最大的类别yi,即:
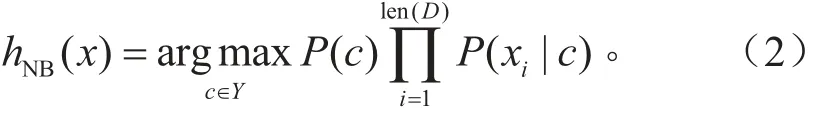
对于离散属性,即“制动信号”、“挡位变化”,条件概率P( xi|c )计算式为:

式中:Dyi为样本集中类别为yi的样本集;Dyi,xi为在Dyi中属性取值为xi的样本集。
而对于连续属性,即“油门变化率”,“油门触发前车速”,采用概率密度函数对条件概率计算式进行变形:
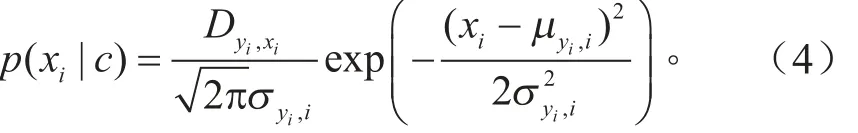
式中:µyi,i,πσyi,i分别为输出类别yi的样本在特征参数xi上取值的均值与方差。
(2)分类模型训练与测试。采用Python机器学习库Scikit-learn辅助构建贝叶斯分类器,采用上一节中决策树分类所使用的样本集对贝叶斯分类器进行训练。对于已构建完成的分类器,对22个测试样本进行识别与分类,得到识别准确率情况见表2。

表2 朴素贝叶斯识别工况准确率
由表2可知,基于朴素贝叶斯构建的分类器在测试集上可达到19/22=86.4%的识别准确率,效果较好。
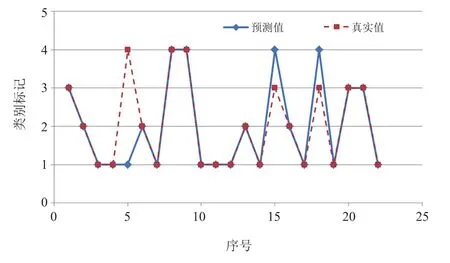
图7 朴素贝叶斯驾驶工况分类器测试效果
2.3 C4.5及Naive Bayes分类效果对比分析
为进一步对比两者的识别效果,采用评估分类模型时常用的查准率及查全率[14-15]两个指标进行分析,并最终计算模型的F1度量值[14-15]来进行综合评估。查全率、查准率及F1测试值的公式如下所示:

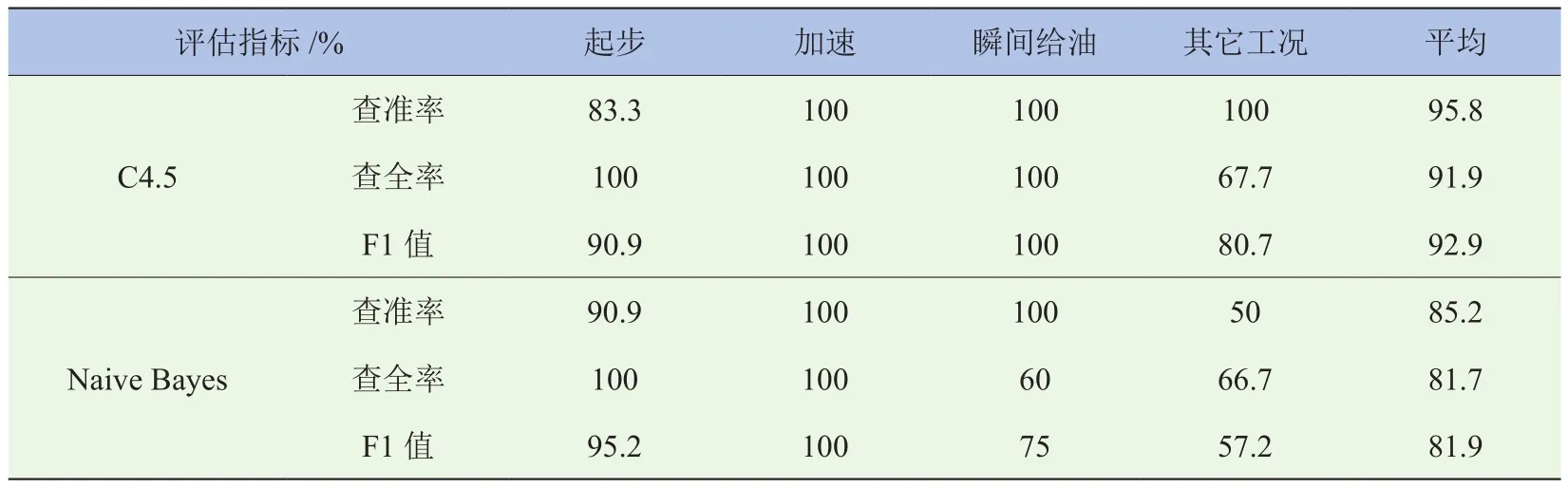
表3 分类模型效果比较
针对两模型在同一测试集上的分类效果,分别计算上述指标,结果见表3。
由表3可知,C4.5决策树的识别准确率、查全率及F1值相较于朴素贝叶斯方法分别高出10.6%、10.2%及10.0%。因此,在对混合驾驶工况的识别与分类中,C4.5模型的识别性能要高于Naive Bayes,究其原因,是由于决策树算法最适用于处理带分界点的、由大量分类数据和数值数据共同组成的数据集[14]。而本研究中所提取的特征参数集,均符合上述特点,所以识别准确率极高。而在使用朴素贝叶斯方法进行分类的过程中,虽然做了条件独立性假设,但由于各特征参数均为整车动力总成系统性能的反映,无法做到完全独立,所以将对分类模型的识别效果产生一定影响。
3 结论
在对不同汽车驾驶工况进行定义与描述的基础上,将在时间序列数据中进行混合工况识别的问题抽象为分类判别问题。通过特征定义、数据融合、特征提取及特征组合,构建了用于分类模型训练的样本集。基于某自主品牌车型实车试验样本数据,分别采用C4.5决策树算法及概率统计学中的朴素贝叶斯方法构建了混合驾驶工况分类模型,并通过回代,对模型的识别准确率进行了测试。结果表明,基于C4.5决策树及朴素贝叶斯构建的模型均可达到85%以上的识别准确率,且前者的识别准确率要优于后者。然而,贝叶斯分类器支持增量式训练,且接受大数据量训练时具有较高的速度。随着试验数据的不断获取,样本数量的不断增加,在今后的应用过程中需综合考虑。
