数据采集在大数据中的应用
2018-10-20刘阳
刘阳

摘要: 当今世界已经进入了一个信息化时代,大数据在很多行业中都扮演着十分重要的角色,影响着人们的生产生活方式。本文围绕数据采集在大数据中的应用展开研究,重点分析了大数据的概念、数据采集的方式方法与如何用Python来进行数据采集。
关键词: 大数据;互联网;信息;数据采集
中图分类号: TP212.9;TN929.5 文献标识码: A 文章编号: 1672-9129(2018)09-0006-01
Abstract: the world has entered an information age. Big data plays a very important role in many industries, influencing people's production and lifestyle. This paper conducts research on the application of data collection in big data, and mainly analyzes the concept of big data, methods and methods of data collection and how to use Python to conduct data collection.
Key words: big data;Internet;Information;The data collection
1 大数据概述
大数据的含义是不能够在一定的时间范围里面使用常规软件工具来进行捕捉、管理与处理的数据集合,是需要使用新的处理模式才能够具有更加强烈的决策能力、洞察能力以及流程优化能力的海量、增长率较高、内容多样化的信息资产[1]。大数据技术的推广和使用,最为重要的意义不在于掌握和管理庞大的数据库,而是对这些含有一定意义的数据作出更加专业化、科学性的处理和利用。换句话来说,如果把大数据看成是一种产业的话,那么这一产业能够取得经济利益的关键之处,就在于提高对数据的“加工能力”,通过对數据进行加工来做到对数据价值的提升。适用于大数据的技术,包括数据采集、大规模并行处理(MPP)数据库、数据挖掘、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统。下面我们就大数据采集方式方法做简单介绍。
2 数据采集的方式方法
2.1系统日志采集方法。绝大部分的互联网企业都拥有自己专属的海量数据采集工具,一般是用于对系统日志进行采集,例如Hadoop的Chukwa、Fecebook专用的Scribe以及Cloudera的Flume等等,这些工具都是采取分布式类型的架构,可以满足很大的使用需求,绝大多数都可以满足每秒时间内数百MB的日志数据采集以及传输需求。
2.2网络数据采集方法。网络数据采集方法的意思是说通过利用网络爬虫或者是网站公开API等各种方式从网站上面得到相关的数据信息。使用这种方法能够非常简单地将一些非结构化的数据从网页之中抽取出来,并且将这些数据信息统一地存储在本地的数据文件之中,并且能够以结构化的形式进行存储。这种数据采集方法能够采集图片数据信息、音频数据信息以及视频数据信息,而且也能够采集附件,附件能够和正文之间自动地关联在一起。除了互联网中包含的一些信息内容之外,对于那些网络流量进行采集的时候一般会选择使用DPI或者是DFI等一些宽带管理技术来进行处理。
2.3其他数据采集方法。对于那些对企业生产经营数据或者是有关学科的研究数据等保密程度要求比较高的数据信息来说,可以采用与企业或者是科学研究机构进行合作的方式,通过使用特定系统接口等一些有关的方式来对数据进行收集。
2.4大数据采集平台。Apache Flume。Flume是Apache旗下开发出来的一款具有多重优势的数据采集系统,其具有的优势主要有可靠度高、扩展性强、管理简便易行、支持客户扩展等等。Flume是通过Jruby来进行构建的,因此其运行环境依靠Java来实现。
Splunk Forwarder。Splunk属于一个分布式类型的机器数据平台,主要扮演着三个重要的角色:Search Head承担的主要任务是对数据进行搜索和处理,同时需要提供搜索过程中的信息抽取情况;Indexer主要负责对相关数据进行存储和索引;Forwarder主要负责对数据进行收集、清洗和变形处理,并且发送给Indexer.
Python属于一种开源语言,这种语言能够提供十分丰富的API和工具,能够通过使用C语言和C++等对这一模块进行编写和扩写,也能够通过第三方库来进行,具备非常高的灵活性和适应性,所以说越来越多的人开始选择通过使用Python来对互联网数据进行采集和整理。
3 如何用Python进行数据采集
Python数据采集之Scrapy框架,Scrapy是一个快速的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、舆情监测和自动化测试。
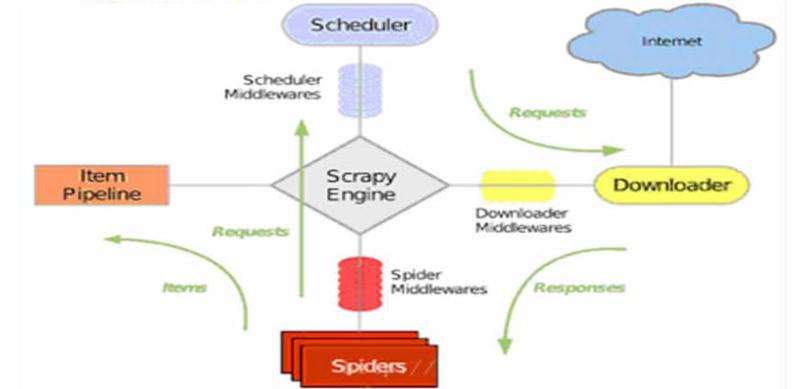
3.1 Scrapy整体框架。
Scrapy由引擎(Scrapy Engine)、调度器(Scheduler)、下载器(Downloader)、爬虫(Spiders)、项目管道(Item Pipeline)、下载器中间件(Downloader Middlewares)、爬虫中间件(Spider Middlewares)、调度中间件(Scheduler Middewares)等部件组成。
3.2 Scrapy运行流程。
(1)引擎打开域名,指定Spider来处理这个域名,获取第一个要爬取的URL;
(2)引擎从Spider中获取第要爬取的URL,并在调度器以Request请求调度;
(3)引擎向调度器请求下一个要爬取的URL;
(4)调度返回要爬取的URL给引擎,引擎通过下载中间件将URL发送到下载器;
(5)下载器生成一个该网页Response响应,将其通过下载中间件发送给引擎;
(6)引擎从下载器接收Response响应,并通过Spider中间发送给Spider;
(7)Spider处理Response响应,并返回爬取到Item和新的Request请求;
(8)引擎将爬取到的Item给Item Pipeline,将Request请求发给调度器;
(9)重复(2)操作,度器中没有新Request请求,引擎断开与该域名的链接。
3.3 采集实例。获取某电影网站的排名数据采用Python实现方式如下:
import requests
import re
Url = 'http://dianying.2345.com/top/meiguo.html'
response = requests.get(Url)
html = response.text
#print(html)
#
pattern = re.compile(r'TOP(.*?).*?.*?
主演:.*?.*?
(.*?)
.*?re_result = re.findall(pattern,html)
list = re_result
i =list[:]
for i in list:
print (i)
#print(re_result)'''
pattern = re.compile(r'TOP(.*?)')
re_result = re.findall(pattern,html)
print(re_result)'''
程序運行结果如下:
4 结论
当前,社会已经进入了一个信息化时代,掌握了丰富多彩的信息,也就等于掌握了制胜的关键。市场竞争越来越激烈,科学技术的运用能够为企业的发展增添动力。通过本文的研究也能够看出,大数据的使用能够为企业运营和决策带来诸多的便利。从长远来看,大数据必然将迎来一个又一个发展高峰,也将为社会的发展带来更多的机遇和挑战。
参考文献:
[1]顾军林.大数据在农业无人机上的应用研究[J].农机化研究,2018(04):213-217.
[2]黄金国,刘涛,周先春,严锡君.基于可变粒度机会调度的网络大数据知识扩充算法[J/OL].计算机应用研究,2019(03):1-3
[3]王承军. 高并发大数据在线学习系统中的关键技术研究[D].中国地质大学,2015.
