基于GPS的道路客运旅客在途位置辨识与到站时间精准预测技术
2018-10-19王静,解超
王 静 ,解 超
(1.中国民航信息集团有限公司,北京 101318;2.中国交通通信信息中心,北京 100011;3.中交信有限责任公司,北京 100007)
近年来,随着计算机、网络技术在公路、铁路、民航道路客运领域应用范围的逐渐扩展,对出行的精确规划已经成为常态。然而,相比在封闭体系中运行的火车、飞机,道路客运车辆与其他社会车辆共享行驶路径,其行驶时间受路况、事故、天气等因素影响较大,因此难以编制确定的车辆行程时间、里程表,导致乘客只知道上车的时间,却不知道什么时候到站,更不可能知道车辆现在行进到了哪里,是否晚点,还有多久才能抵达目的地。这严重影响了乘客们的出行体验,更为行程提前规划、接驳转乘与多种交通工具联程联运制造了障碍。可见,缺乏精准的车辆到站时间精准计算机制,已经成为了道路客运的最大痛点之一。相较之下,航空、铁路都有严格的行程-时刻表体系,除个别的延误情况外,基本做到了行程的可预期、可控制。航旅纵横等应用在航空领域的发轫,更为用户准确实时掌握交通工具精准动态提供了便捷的途径。
针对上述问题,作者利用全国营运车辆联网联控系统的长途班线客运车辆GPS监测数据,结合道路客运联网售票系统中的班次、票务数据,提出了一种计算长途班线客运车辆行程—时刻表的算法,实时获取长途班线客运车辆运行动态时刻表以及旅客实时位置信息,在此基础上,预测车辆到达特定车站时间、待行驶里程,服务于旅客的智慧出行和精准规划。如图1所示。
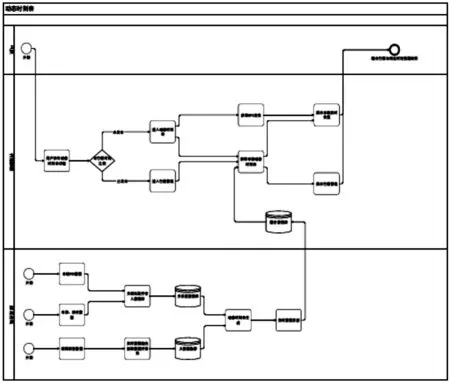
图1 基于GPS的道路客运旅客在途位置辨识与到站时间精准预测技术路线图
1 长途客车GPS数据预处理
从2008年起,交通运输部在班线客运、旅游包车和危险品运输车等重点营运车辆(即“两客一危”)车辆上安装基于北斗卫星导航系统的车载机,并通过无线数据网络将车辆的位置与行驶状况信息实时回传并记录。截至2017年底,在重点营运车辆上的设备安装率已达到100%,数据回传率在99%以上。
1.1 重点营运车辆联网联控系统GPS数据格式
重点营运车辆联网联控系统GPS数据格式分为历史数据和实时数据两种。
图2 重点营运车辆轨迹数据示例
1.1.1 历史数据
文件格式:重点营运车辆联网联控系统GPS历史数据格式如图3所示:
(1)联网联控系统车辆历史数据文件统一采用文本文件格式($accesscode.data)。
(2)联网联控系统车辆历史数据每天每小时保存为一个文件夹,以当天日期YYYYMMDD_txt 格式命名为根目录,如2014年4月6日,保存数据的文件夹名为20140406_txt。根目录下每小时数据保存为一个文件夹,格式为data_HH,如上午十时数据保存的文件夹名为data_10。
(3)文本文件中各字段之间使用符号(,)进行分割,每条记录以回车符表示结束。
(4)每行数据中各字段的排列顺序按照下一节中每种数据的序号排列。
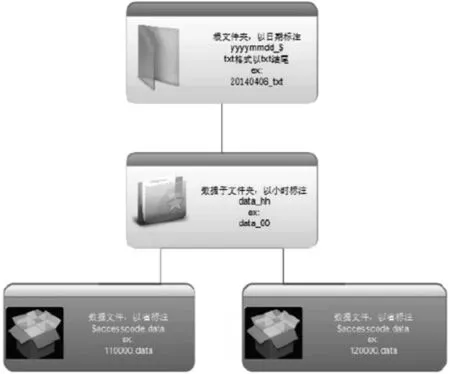
图3 重点营运车辆联网联控系统GPS历史数据格式
1.1.2 实时数据
重点营运车辆联网联控系统GPS实时数据格式如表1所示:
1.2 GPS数据预处理
长途客车GPS数据通过车载GPS终端在一定间隔内实时采集,数据主要包括线路编号、车辆编号、回传时间、GPS坐标(经纬度)、定位状态等。
长途客车在行驶过程中,由于隧道、立交桥等影响,易发生数据丢失、位置漂移等问题,因此,需要对长途客车GPS数据进行预处理,清洗掉漂移或异常的数据。
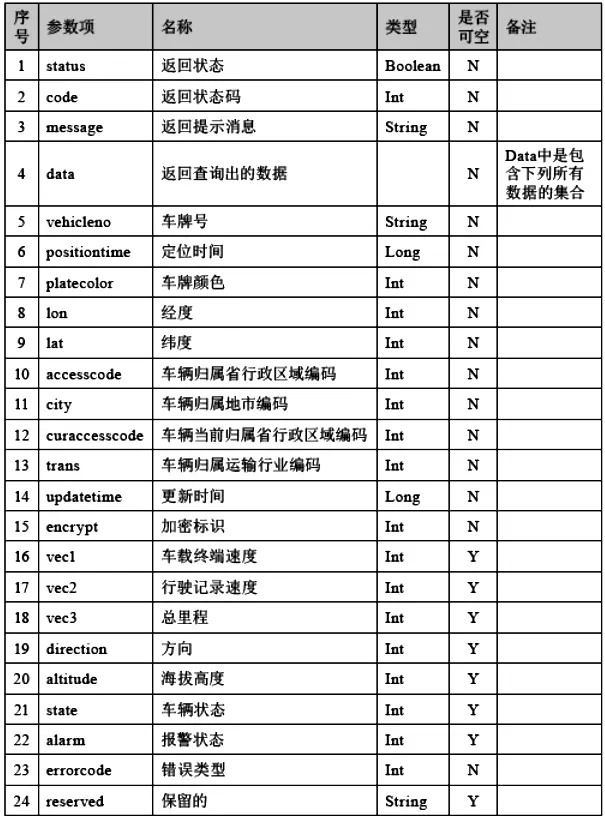
表1 重点营运车辆联网联控系统GPS实时数据格式表
为提高处理效率,基于GPS的道路客运旅客在途位置辨识与到站时间精准预测技术使用缓冲区方法对GPS漂移或异常数据进行过滤。过滤远离道路的数据最有效的方法是在道路中线的基础上构建缓冲区,然后删除在缓冲区以外的数据。
1.2.1 两级缓冲区法
为提高数据预处理过程的计算效率,引入了利用大小两级缓冲区进行车辆位点过滤的方法,即先通过大缓冲区高速粗筛,剔除远离目标道路的车辆数据,再通过小缓冲区细筛,剔除与道路距离较近,但不在道路上的车辆数据。
经分析,大约80%以上的车辆定位点都远离道路300m以上,为了提高效率,过滤远离道路点采用多(两)级缓冲区技术,先利用大尺度上的缓冲区对绝大多数远离道路500m以上的点进行过滤,然后利用小尺度上的缓冲区对距离道路500m以内的数据点进行过滤,提取出在道路上行驶的定位点。大小尺度上的缓冲区分别见图4和图5。
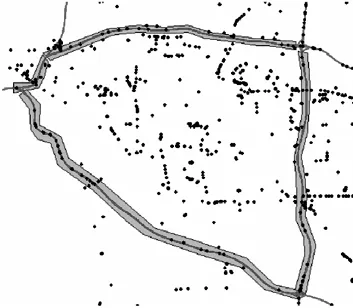
图4 大尺度缓冲区
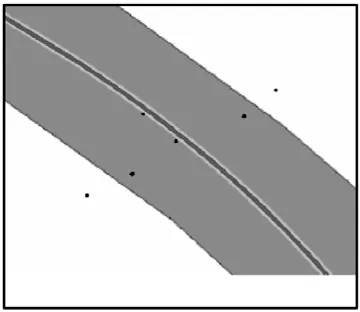
图5 小尺度缓冲区
在这个过程中,最关键是确定小尺度缓冲区的范围,从而最大程度地让存在误差的定位数据被包含在这个缓冲区中。根据误差理论,设道路网的定位误差为α,车辆定位误差最大为β,高速公路单向路宽为w,由图6可知,车辆GPS定位点离道路网的距离最大为,因此将缓冲区的半径设为ρ。
一般认为道路网的精度α=5m,车辆定位误差β=5m,从现有高速公路状况来看,大部分单向路宽为10~16m,大型车辆车宽为2.5m,则ρ取值为13~16m。由于在不同地区,道路宽度标准与车辆GPS型号的差异可能导致定位精度和缓冲区大小有所差别,因此可以考虑分区域确定缓冲区半径的具体值。这样,可以使所设缓冲区既能较快地区分车辆所属道路,又能最大程度包含行驶在道路上的车辆的定位数据。
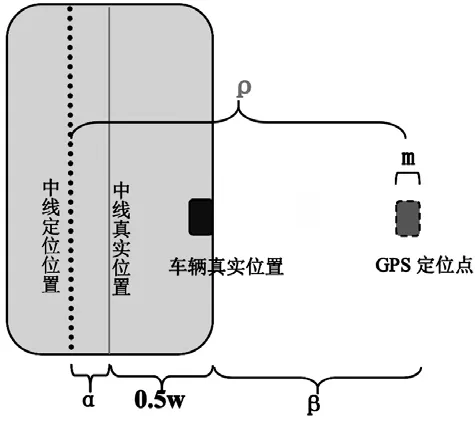
图6 道路、车辆的定位示意图
注:按照《GB-1589-2004道路车辆外廓尺寸、轴荷及质量限值》的规定,车辆高度限值为4m,宽度限值为2.5m,故取2.5m为车辆宽度。
由于缓冲区在每次计算路况时都会使用且范围相同,因此可以事先计算全国道路网的两级缓冲区数据,保存为独立图层,在浮动车数据预处理操作时直接调用。同时,缓冲区还可以消除车辆进入服务区或收费站后的定位数据,排除这些情况的对路况计算的干扰。
在过滤过程中,需要判断每一个动态数据点是否在缓冲区内,这时记录下在缓冲区内的数据点被包含于哪个道路的缓冲区内,此信息将用于地图匹配过程。在道路交叉点区域,还需要根据道路方向判断。
1.2.2 方程式缓冲区法
为了进一步提高浮动车数据筛选过程的效率,在两步缓冲区基础上,又引入了一种适合于浮动车数据的高效缓冲区分析方法。
考虑到目前缓冲区表达方式的特点,若使用栅格法表达,虽然缓冲区分析简单但占用存储空间大;若使用矢量法表达,虽然存储效率高但缓冲区分析涉及的几何计算复杂。两种表达方法都存在缺点,因此我们希望寻找第三种缓冲区表达方法,既存储效率高又应用简单。缓冲区分析主要是以距离为依据,因此方程式缓冲区需要与距离有关系,并且具有连续封闭的特点,当然最重要的特点是能用一个数学公式描述。而万有引力的等值线恰好能满足这些要求,为此我们借助万有引力等值线公式的形式构造方程式缓冲区,用地理要素的一条引力等值线拟合与之最接近的缓冲区边界,使缓冲区分析从一个包含复杂几何运算的过程转变成包含简单代数运算的过程,从而提高计算效率。
下面分别给出了点和线段的缓冲区方程,具体推导过程不在本文中阐述。
(1)点(x0,y0)的缓冲区为

式中,r是缓冲区半径。
(2)线段((x1,y1),(x2,y2))的缓冲区为
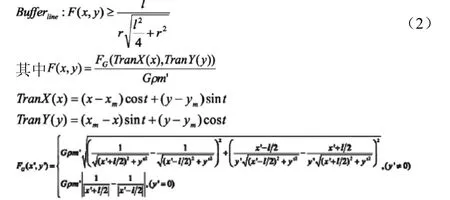
式中,r是缓冲区半径;为线段的长度;t为向量((x1,y1),(x2,y2))与X轴的夹角;(xm,ym)为线段的中点是线段的线密度。
图7中,左列为常规缓冲区,右列为方程式缓冲区,(a)、(b)为点的缓冲区,从里到外缓冲区半径分别为20、40、60、80,(c)、(d)为线段的缓冲区,线段长400,从里到外缓冲区半径分别为40、80、120、160。

图7 常规缓冲区与方程式缓冲区的对比
下面以地理信息检索为例,介绍方程式缓冲区的应用方法,即查询在缓冲区内的地理要素。
点缓冲区。判断某要素点 T(xt,yt)是否在点 A(x0,y0)半径为r的缓冲区内时,将要素坐标代入公式(1)中得到,若不等式成立,则要素点T在点A的缓冲区内;若不成立,则要素点T在点A的缓冲区外。缓冲区半径变化时只需要改变r的值重新计算即可。
线段缓冲区。判断某要素点T(xt,yt)是否在线段AB半径为r 的缓冲区内,A、B的坐标分别为(x1,y1),(x2,y2),将要素坐标代入公式(2)中得到,若不等式成立,则要素点T在线段AB的缓冲区内;若不成立,则要素点T在线段AB的缓冲区外。
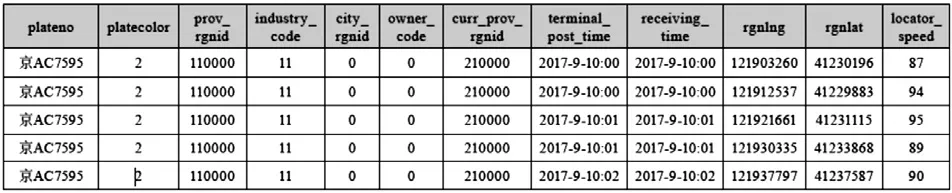
表2 联网联控数据样例表
曲线缓冲区。曲线Q(P1,P2,…Pn),判断某要素点T(xt,yt)是否在曲线半径为r的缓冲区内时,需要将要素坐标代入曲线所有子线段(Pt,Pt+1,t=1,2,…,n-1)的缓冲区不等式中进行判断,只要有一个不等式成立,则要素点T在曲线Q的缓冲区内,反之则不在曲线Q的缓冲区内。
2 道路客运线路经停点精准识别与动态时刻表生成技术
道路客运线路经停点精准识别与动态时刻表生成主要分为线路(班次)行驶轨迹精准识别、客运站精准位置提取和动态时刻表生成3个步骤,具体的技术路线图如图8所示:
2.1 行驶轨迹精准识别
(1)根据车辆班次表中的车牌号信息,从联网联控GPS数据中提取车辆轨迹数据(如表2)。
(2)通过识别和剔除时间紊乱点、异常定位点、临时停车点与长时停车点,生成精确轨迹路线图(见图8)。
2.2 客运站精准位置提取
(1)依据原始车辆轨迹数据识别出长时间停车数据,通过聚类算法汇总大量车辆数据提取共性停车位置,即客运站(停车点)位置。

图8 道路客运线路经停点精准识别与动态时刻表生成技术路线图
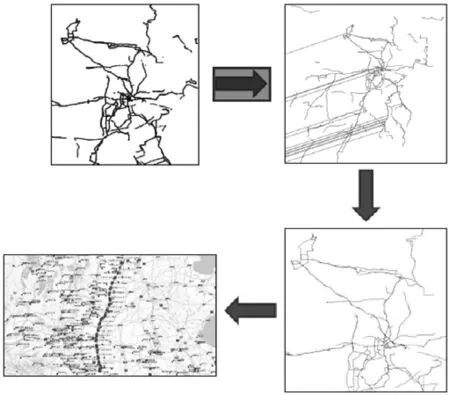
图9 线路行驶轨迹精准识别与提取
具体步骤如下:
A)坐标系转换:将GPS定位数据从地理坐标系转换到投影坐标系,便于后面步骤中的距离计算。
B)停车定位点筛选:从原始数据中筛选出速度零值点,为了剔除一些偶发因素(定位设备误差、临时停车)导致的速度零值点,添加距离、方向指标作为筛选条件。
C)停车定位点聚类:使用改进后的DB-SCAN 算法对步骤B)筛选出的停车定位点进行分类,将高密度的定位点集划分到同一类中,分类后得到若干个点簇,并剔除噪声点。
D)聚类中心计算:对任一个点簇Ci,提取簇心Pi(XPi,YPi),并通过车牌号字段统计点簇包含的车辆数VNi,得到簇心集合S。
E)客运站位置提取:将S中距离较近的簇心归并到同一类中,得到S的多个子集Sk,使Sk中任意两个簇心的距离不超过dc。合并Sk中的簇心,得到新的簇心(XSk,YSk),合并后剔除车辆数量小于Nmin或与道路中线距离小于dr的簇心,剩下的簇心即为客运站。
(2)根据车站位置与班次经停表数据库、第三方电子地图地名POI数据库进行比对(图10),确认各车站位置与班次经停表中车站名称的对应关系,如表3所示。
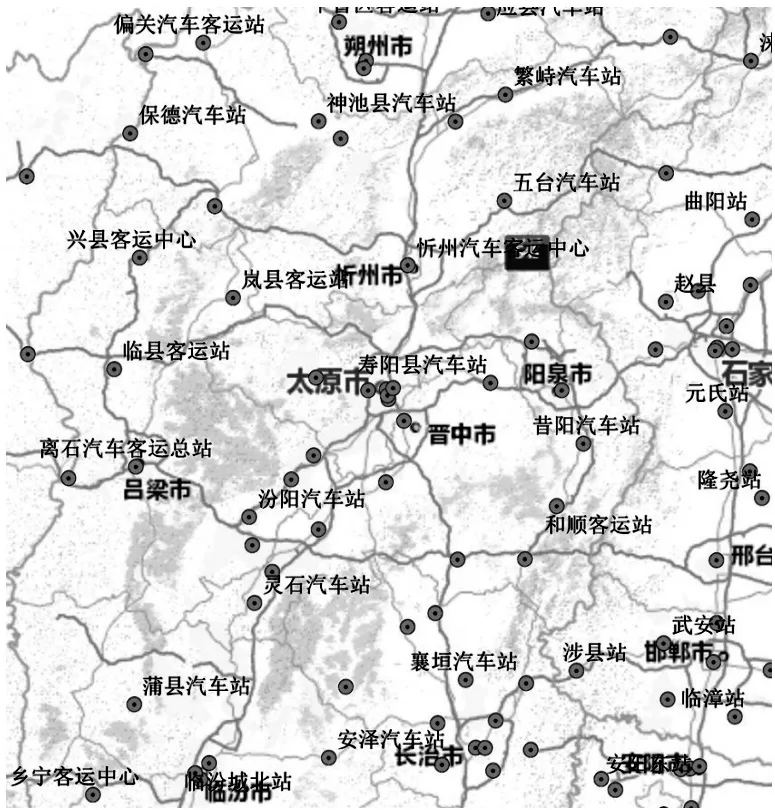
图10 电子地图POI库车站位置点
2.3 动态时刻表的生成
在确定班次各经停站的名称、位置的对应关系后,即可根据班次轨迹计算道路客运班次对应的里程-时刻表格,即:
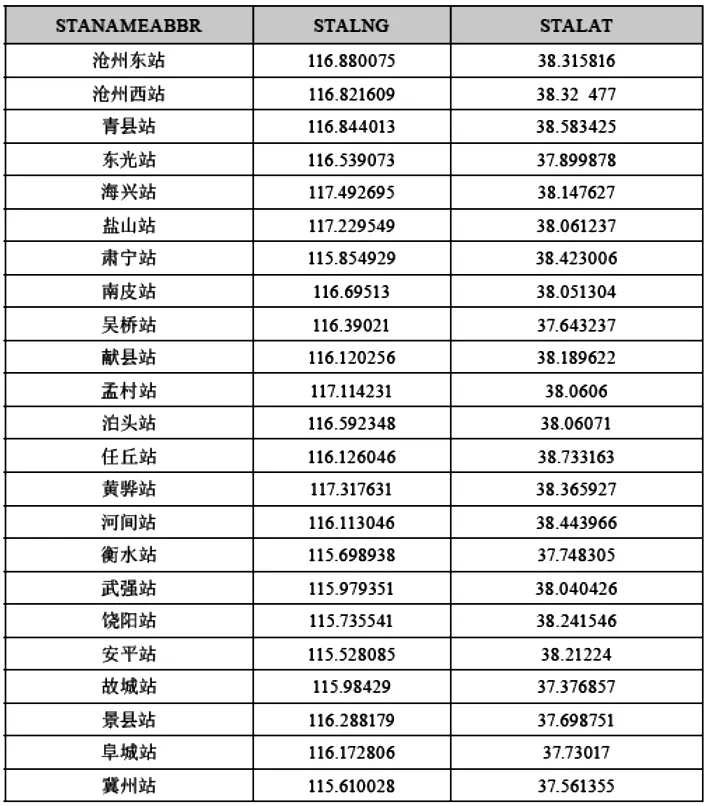
表3 车站名称与经纬度对应表
按照班次行驶路线,每1分钟记录一个采样点,记录经纬度、计划到达时刻、从起点出发的行驶时间、从起点出发行驶里程及该点对应的经停站在数据库中生成特定班次对应的里程-时刻表格(见表4)。
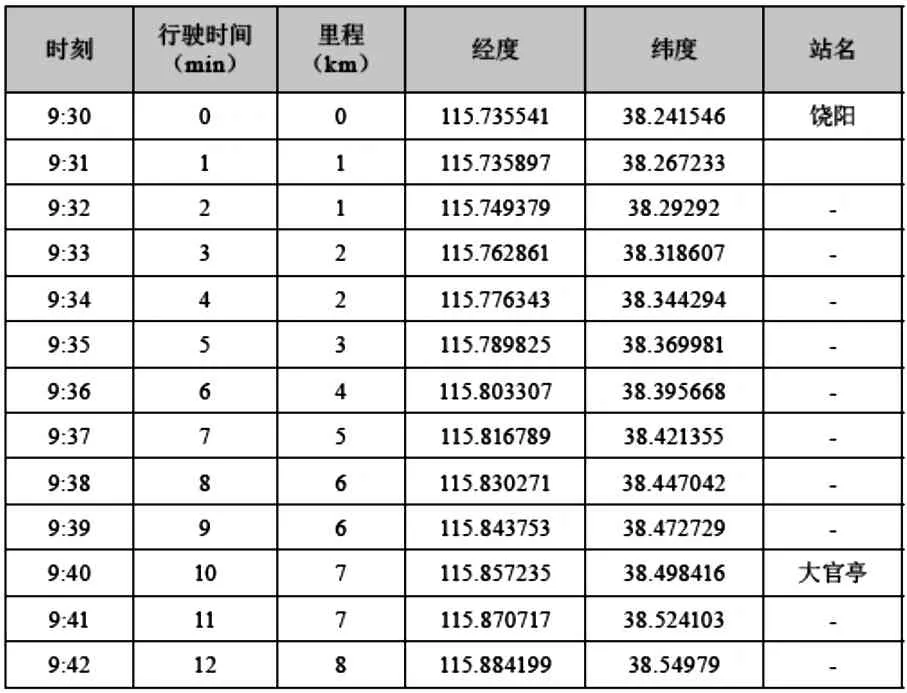
表4 班次里程—时刻表
该方法实现轨迹与车站位置点的匹配,使用准确的采样方法计算班次时刻-里程表,并可通过同一班次对应的多日车辆轨迹数据的整合减少不确定因素影响,提高班次时刻-里程表的精度。
3 道路客运旅客在途位置与到站时间精准预测技术
3.1 在途位置确定
获取旅客在途位置可通过两种途径:一是根据用户前端(手机等)GPS定位数据获取用户实时空间位置(经纬度信息)。二是根据用户购票订单信息建立用户与特定车次的关系,再通过班次信息获取运营车辆的车牌号码(图11),之后通过前文所述的重点营运车辆联网联控系统GPS实时数据数据接口获取对应车牌车辆的实时位置,从而获取旅客实时位置。
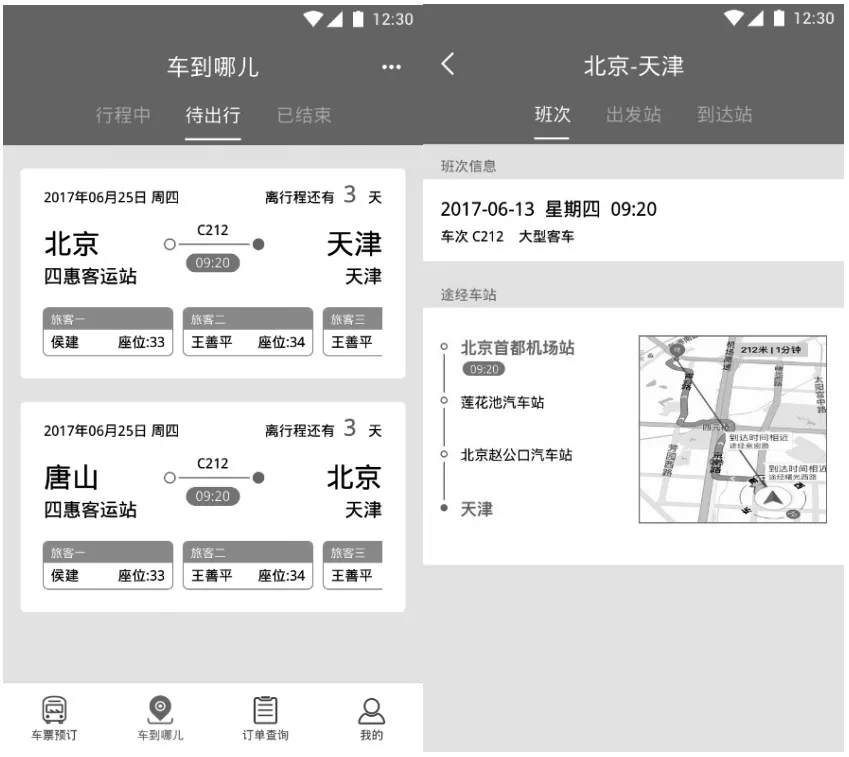
图11 用户订票信息与班次时刻表信息与轨迹关联
3.2 车辆到达时间及行程预测
(1)获取旅客在途位置后,根据依照票务信息关联到的班次数据,查询对应班次的动态里程-时刻表(见表2,图11)。
(2)利用勾股法计算动态里程-时刻表中与当前位置最接近的记录,设当前点位置(Xc,Yc),即在动态里程-时刻表中查找点(Xi,Yi),使 ΔDc-i=[(Xc-Xi)2+(Yc-Yi)2]1/2为最小,即可确定车辆当前在班次轨迹上的位置。
(3)之后根据点(Xi,Yi)对应的时刻和车辆行驶里程数据,与动态里程-时刻表中计划到达站的时刻和车辆行驶里程数据比较,即可计算得到车辆到达特定目的地站点的时间。同时,还可以根据乘客需要,在车辆到达目的地站点前的一定时间(或里程),向旅客发送提醒信息(图12)。

图12 车辆到达时间计算及旅客到站提醒
4 结束语
通过以上方法,在GPS车载机采集的数据可以覆盖车辆运营轨迹的情况下,即可精确获取车辆的动态里程-时刻表,并根据该表格计算旅客的精确在途位置并预测其到达时间。同时,系统可通过同一班次对应的多日车辆轨迹数据的整合减少不确定因素及轨迹数据缺失的影响,提高班次时刻-里程表的精度与可信度。
在此基础上,作者将建立获取无车牌信息的班次时刻-里程表的机制:根据经停站位置,对无车牌信息的班次数据进行分析,根据轨迹数据推算出其对应的车牌号,绘制无车牌信息班次的线路轨迹、无位置数据经停站位置及时刻-里程表。从而进一步通过已获得的经停站位置数据,对全部班线客运车辆数据进行筛选,获得轨迹与已知班次经停站位置相匹配的车辆车牌号,即确定无车牌信息的班次对应运营车辆的车牌号信息,实现全部班次时刻-里程表的计算与输出。■
