ID3 算法改进及其在信息管理中的应用缩减
2018-10-19张凌菁西南大学
张凌菁 西南大学
引言:在信息化时代,数据资源量呈现一种指数爆炸的状态,对数据资源进行挖掘,可帮助人们从数据库中提取感兴趣的信息、规律从而有效地利用数据信息。分类算法数据挖掘中最常用的一种数据计算方法就是决策树算法,是依据现有的数据资源,而建立的一种预测模型。ID3算法是根据决策树的反馈对信息进行分类的算法,该算法根据增益的信息,运用从上而下的策略建立决策树。这种信息增益可以度量出某个属性对样本集合分类的好坏。因为算法采用了信息增益,所以它建立的决策树规模比较小,便于查询。
1.算法基本原理
ID3算法主要依赖于决策树的建立,由J.Ross.Quinlan在1986年创建。ID3是根据信息的增益效果,采用自上而下的贪心策略对决策树进行组建,它的增益决策属性分类判别能力根据信息增益来度量,从而选择决策结点属性,并将建树的方法应用于一个迭代的模型中。ID3算法的核心就是分裂分裂之后信息增益最大的属性,期望的信息越小,信息的增益就会越大。
1.1 基本定义
ID3算法根据每个属性的分裂后的信息增益,如果信息增益高就是好属性,以信息增益最高的属性作为划分的标准,之后对这个过程重复运算,直到生成一个能完美分类训练样例的决策树之后结束运算。
设S代表s个数据样本的集合,有 m个不同的值类标号属性,定义m个不同的类Ci,其中i[1,m],设Si是类Ci中的样本个数。
设想A选测试属性,设 子集为 中属于Ci类别的样本个数。利用属性A对当前样本集合进行划分所需要的公式为:
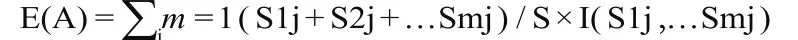
E(A) 如果计算结果越小,就代表其子集划分的效果越好。而对子集Sj来说,它的信息为:

或:
加入利用A样本集合划分当前节点分支之后获得的信息增益为:Gain(A) = I( S1 …. . Sm )-E(A)
根据属性A 的取值来对样本进行集合划分之后,得到的熵的减少量就是Gain(A)。Gain(A) 越大就说明了测试属性A对结果划分分类所需的信息量比较小。所以应该作为分类属性出现。
1.2 基本思想为
(1)决策树中每一个非叶结点对应着一个非类别属性,树枝代表这个属性的值。一个叶节点代表从树根到叶节点之间的路径对应记录所属的类别属性值。
(2)每个非叶结点都与具有最大信息量属性的非类别属性相关联。
(3)采用信息增益的方法选择样本分类属性。
度量某个属性对样本集合分类的好坏程度依赖于信息增益,采用了信息增益后的ID3算法建立的决策树规模比较小,所以查询速度比较快,在ID3决策树归纳方法之中通常采用信息增益的方法确定每个节点采用到合适属性,这样选择具有很高的信息增益效果,以此来作为当前节点的测试属性,这样对之后划分训练样本子集所需要的信息就比较小。或者说,用这种属性对当前节点所含的样本进行划分,所得到的样本中不同类别的混合程度是最低的,因此采用这样的信息论方法有效地减少了不同对象分类所需要的次数,这样得到的决策树也最为简单。
2.算法的优缺点与改进
2.1 ID3算法存在的优点
(1)运算清晰简明,构造的决策树平均深度较小,直观、易于理解
(2)分类速度较快,适合处理大规模问题
(3)每次都使用了全体训练样本,能有效降低个别噪声数据的影响
(4)很好地处理离散型属性值
2.2 ID3算法存在的缺点
(1)ID3算法在对根节点和各内部节点中的分支属性进行选择时,采用的标准是信息的增益量。倾向于选择取值较多的属性是信息增益的一大缺点。
(2)ID3算法具有局限性,它只能对离散型属性的数据进行分析。
(3)在对决策树空间进行遍历的时候,ID3算法只会对单一的当前假设实现维护。它无法进一步对其训练样例进行增加,因此在每次增加实例的时候都要放弃前面的决策树
(4)算法在搜索的过程中是不能回溯的,无论是树的哪一层都要对属性进行选择和检测
2.3 ID3算法的改进
经过上述分析ID3算法的局限性可表示为:
①在整个环节当中存在着繁琐的对数运算,公式计算复杂度倍增,不仅影响ID3 算法执行的效率,还造成极大的时间开销。
②存在不合理的多值偏向缺陷。
由此,提出的改进方法是:对ID3算法公式进行改进,化简信息熵的运算过程,再通过对泰勒公式和麦克劳林公式的运用,消除log对数运算,只需要对函数进行有限次四则运算,同时根据粗糙集理论知识,将重要度、关联度的概念引入到算法中以调整系数,最后会根据一个综合评价指数来对属性进行选择,用来作为决策树生成的划分结点。具体方法为:
(1)针对ID3原始算法存在的问题,提出一种改进后的决策树算法。在新的算法中设定测试样本集为U,样本集包含的记录数为D,样本属性个数为M, 关联度为K,调整系数为5(0 < 51),样本子集分组数的最大度量为1,综合评价指数为NO,其中调整系数n,综合评价指数N=K+n(关联度不为0的时候使用),多次对多值取向问题进行精确改进,避免大数据掩盖小数据的情况发生,从而提高了算法的效率和精确度。改进后的算法执行步骤如下:先对要进行决策树生成的测试样本集进行确定选择,根据不同的属性对样本集中的记录数据进行分组,得到以编号为集合的分组记录
(2)计算按照属性进行分组后的各分组记录中的最大度值
(3)根据粗糙集论中关于对属性重要度知识的描述,计算样本集属性的关联度K值
(4)根据第2步得到的最大度量1值及本次分组样本集包含的记录数D,计算各属性对应的调整系数值
(5)计算各属性对应的综合评价指数NO
(6)由上一步得到的综合评价指数N来进行判断,究竟选择哪一个属性作为结点进行进一步的划分。
(7)重复上述步骤直到所有的叶子结点都归属同一个类别时,结束结点的划分工作,这样就得到了分类决策树,并提取分类规则。
3.算法的应用
为了进一步对ID3改进算法进行详细描述,下面以学生成绩表中的测试样本集来简单说明新算法的挖掘过程。

ID Name Class Math English LinearA History Policy Total 120305 BOB 3 89 94 91 86 86 446 120203 Chenli 2 99 92 86 89 92 458 120104 Dube 1 86 63 88 86 73 396 120301 Fuqi 3 98 71 59 95 58 381 120306 Jixiang 3 94 89 87 95 93 458 120206 Lgus 2 56 84 65 78 90 373 120204 Loids 2 92 96 95 91 92 466 120201 Atdlp 2 77 96 93 92 93 451 120103 Kare 1 85 99 92 92 48 416
过程如下:
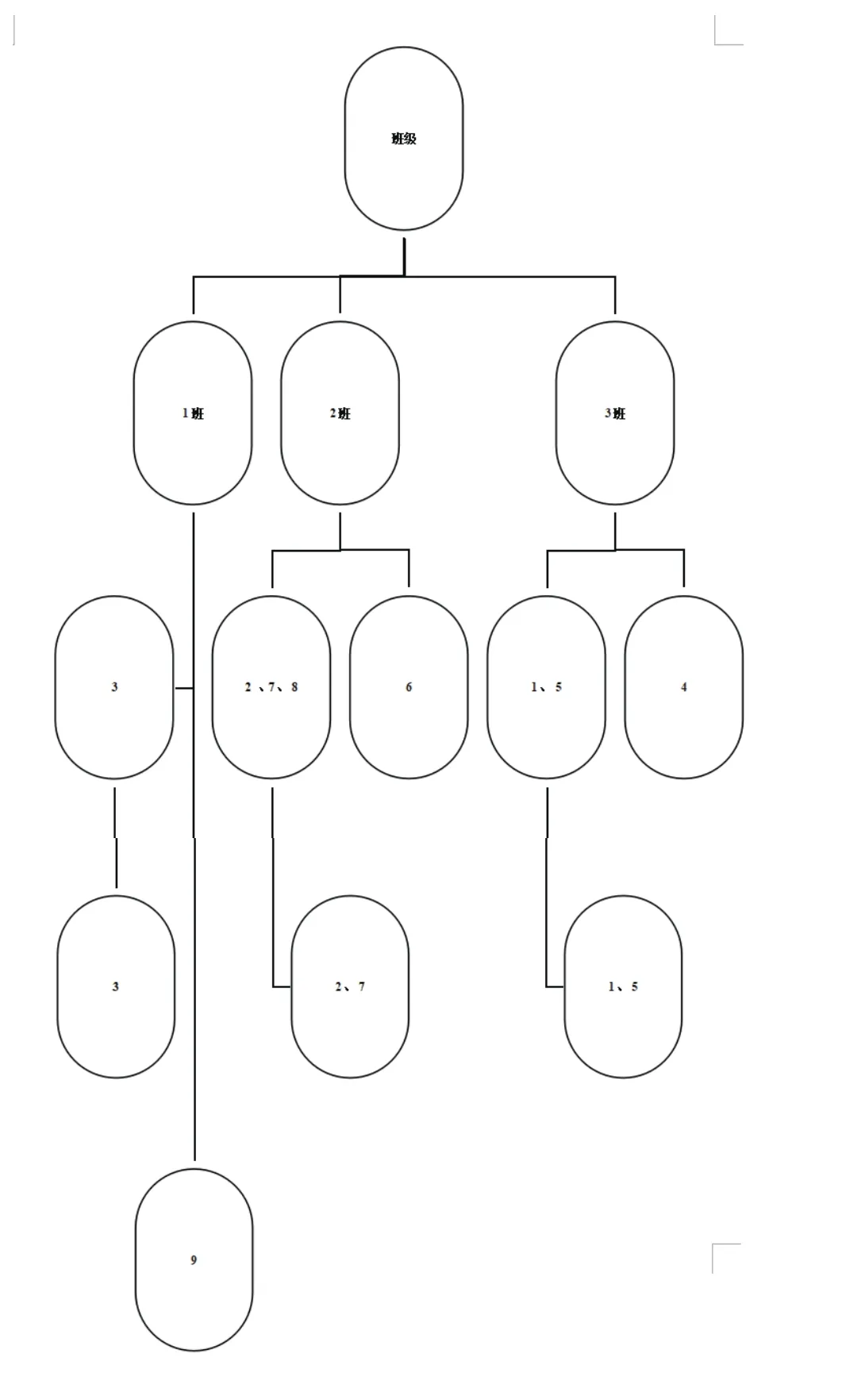
1.第一先利用属性对测试样本集中记录按班级进行统计分组,并计算出样本子集分组数最大度量1:
U /班级 = { 1、4、5 }、 { 2、6、7}、{3、9}
U / 是否及格 = {4、6、9 }、{ 1、2、3、5、7、8}
U / 单科第一 ={ 2、9、7、4、5、5、8 }、{ 1、3、6、9}
U / 总分 400 以上={1、2、5、7、8、9}、{3、4、6}
U / 检验标志= {1}{2}{3}{4}{5}{6}{7}{8}{9}
I/ 检验标志=1
3.计算各调整系数:
e/合格率=41/45=0.911
e/一班合格率=9/10=0.9
e/二班合格率=19/20=0.95
e/三班合格率=13/15=0.867
e/优秀率=34/45=0.756
e/一班优秀率=7/10=0.7
e/二班优秀率=16/20=0.8
e/三班优秀率=11/15=0.733
4.计算各属性对应的综合评价指数:根据公式N:K + n计算各位同学的综合评价指数。
如:Loids=5/5=1(优秀)
5.由上一步得到的综合评价指数N,以此为依据来对哪一个属性作为结点进行选择,并进一步的划分。
6.决策树为:
结论:本文研究了决策树分类算法ID3,并通过对该算法的描述、改进以及作用于高校学生成绩的特征数据等步骤深化。新的算法,提高了决策树的生成速度和精度。复杂查询已有的数据,进而提供更一层的数据分析功能,相信实践改进得到的结果将更有参考价值与应用价值。
