基于双向长短时记忆联结时序分类和加权有限状态转换器的端到端中文语音识别系统
2018-10-16RYADChellali
姚 煜,RYAD Chellali
(南京工业大学 电气工程与控制科学学院,南京 211816)
0 引言
在过去三十年,自动语音识别系统被各大高校和研究机构广泛地研究,在性能上基本满足了日常使用的要求。在此期间,基于混合高斯模型/隐马尔可夫模型(Gaussian Mixture Model/Hidden Markov Model, GMM/HMM)的声学模型范式一度成为自动语音识别的主流框架。其中,HMM用来处理语音信号在时序上的变化性,GMM用来完成声学输入到隐马尔可夫状态之间的映射[1]。然后多层感知器被用来替代GMM完成HMM发射概率的计算,在一定程度上优化了这套识别框架[2]。随后,Geoffrey Hinton领导的深度学习开始兴起,使得深度神经网络(Deep Neural Network, DNN)被引入到自动语音识别的声学模型建模当中[1,3-5]。依靠DNN深度抽象和强大表示学习的能力,语音识别系统的识别准确性又一次获得了大幅提升。
然而在混合DNN/HMM系统的训练过程中,依然需要利用GMM来对训练数据进行强制对齐,以获得语音帧层面的标注信息进一步训练DNN。这样显然不利于针对整句发音进行全局优化,同时也相应地增加了识别系统的复杂度,提高了搭建门槛。另外由于HMM属于生成模型,其中存在与实际发音不符的条件独立性假设[6],导致了这套基于HMM的识别框架在理论上就存在重大缺陷,并不十分完美;同时在DNN发展基础上,循环神经网络(Recurrent Neural Network, RNN)和长短时记忆(Long Short-Term Memory, LSTM)神经网络依靠强大的序列输入建模能力进一步提高了语音识别准确度[7];并且近几年,有相关研究尝试在语音识别中应用卷积神经网络(Convolutional Neural Network, CNN),利用其卷积不变性来克服语言信号本身的多样性来进行语音识别,并获得不错的性能表现[8]。不过这些语音识别系统中仍然保留着HMM结构。这也就意味着在序列标记任务中,依然需要忍受不合理的HMM假设。
对于序列标记任务,Graves等[9]提出了在循环神经网络训练中引入了联结时序分类(Connectionist Temporal Classification, CTC)目标函数,使得RNN可以自动地完成序列输入自动对齐任务。本文在Graves工作的基础上,进一步深入研究了深度循环神经网络(Deep RNN),并针对汉语发音特性,提出了以声韵母为建模单元的基于双向长短时记忆(Bidirectional Long Short-Term Memory, BLSTM)神经网络的声学模型,并成功地将CTC函数应用于该声学模型的训练中。另外结合中文语言学知识,创新运用了基于加权有限状态转换器(Weighted Finite-State Transducer, WFST)的中文解码方法[10],解决了发音词典和语言模型等语言学知识无法顺利融入语音解码过程中的难点问题。该解码方法将CTC标签、发音词典和语言模型编码进单独的WFST网络中,组成一个完整的搜索图。根据CTC网络的输出,利用束搜索技术在搜索图中解码获得最终整体得分最高的识别文字串。实验结果表明了本文设计的基于BLSTM-CTC的端到端语音识别系统,在识别性能上不仅大幅超越了传统的GMM/HMM系统,而且与同样建模单元的混合DNN/HMM系统相比,音素错误率和单词错误率分别降低了4.7%和4.43%,同时在语音识别速度上提高了一倍多。
1 基于双向长短时记忆网络的声学模型
相较于前馈神经网络(Feedforward Neural Network, FNN),RNN是一种允许隐层神经元存在自反馈通路的神经网络类型。循环链接使得循环神经网络的隐层单元具备了记忆上一层刺激的能力,最终随时序作用于网络输出层。这一特性也使得循环神经网络特别适用于处理序列形式的输入数据[11]。而对于一些序列标记任务,如:手写识别、语音识别,不但需要过去时刻的上下文信息,同样也希望获得未来时刻的上下文信息,来进一步预测当前时刻的状态。双向循环神经网络(Bidirectional Recurrent Neural Network, BRNN)就提供了一种优雅的解决方案[12]。它通过在RNN基础上增加一套完全独立的后向传播隐层,让前向隐层和后向隐层共同作用于输出层,这样更加准确地预测当前输出状态。图1为RNN和BRNN在时间维度上展开的网络结构对比。

图1 标准和双向RNN对比

(1)

(2)
在每个t时刻,计算当前循环隐层的状态,并把[hf,hb]作为下一层隐层的输入。这样不断迭代,直到计算出输出层的最终状态。
本文采用时序反向传播(Back-Propagation Through Time, BPTT)算法来学习循环神经网络中各层间的连接权值。在实际应用中,因为各层梯度会随反向传播不断减小而出现梯度消失现象,这样很难让RNN充分学习到上下文的长时依赖[13]。针对此种情况,Sainath等[14]引入 LSTM模块作为构建RNN隐层的单元。一个LSTM记忆模块主要包含:一个记忆单元,用来存储网络时序状态;和3个控制门,分别为:输入门、输出门和遗忘门,用来控制信息流。具体网络结构如图2所示。其中虚线箭头是将记忆单元和各个控制门联系到一起进行精确定时输出的窥视孔连接,实心黑体圆表示乘法单元。在t时刻,LSTM的输出计算如下:
it=σ(Wixxt+Wihht-1+Wicct-1+bj)
(3)
ft=σ(Wfxxt+Wfhht-1+Wfcct-1+bf)
(4)
ct=ft⊙ct-1+it⊙φ(Wcxxt+Wchht-1+bc)
(5)
ot=σ(Woxxt+Wohht-1+Wocct+bo)
(6)
ht=ot⊙φ(ct)
(7)
其中:i,o,f,c分别代表输入门、输出门、遗忘门和记忆单元;W·x为与输入层连接的权值矩阵,W·h为与上一层隐层连接的权值矩阵,W·c为与记忆单元连接的权值矩阵;σ(·)为sigmoid激活函数,φ(·)为tanh激活函数。以同样的方式,可以计算得到后向隐层的LSTM的输出。

图2 一个LSTM记忆块
2 端到端系统的训练及解码
2.1 基于联结时序分类目标函数的端到端训练
在大词汇量连续语音识别中,声学模型训练通常采用嵌入式训练方式,即利用HMM让模型自动对齐语音分割与音素标记,进而来训练声学特征映射模型,如:GMM、DNN。这样无疑增加了混合DNN-HMM系统的复杂度,而且HMM的局限性也不利于语音识别技术的进一步发展。本文应用CTC技术对基于BLSTM的声学模型进行端到端的训练,彻底解决对于隐马尔可夫模型的依赖问题。
CTC训练是在RNN输出层应用CTC目标函数,自动完成输入序列与输出标签之间的对齐。对于序列标记任务,假设存在一个大小为K的标签元素表L(如:音素集或字符集)。假设给定输入序列X=(x1,x2,…,xT),和对应输出标签序列z=(z1,z2,…,zU),CTC训练的目标就是在给定输入序列下,通过调整RNN内部参数最大化输出标签序列的对数概率,即max(lnP(z|X))。其中输出标签zu∈L∪{

(8)
通过定义映射Φ:L≤T|→L′T,再将标签序列z映射到CTC路径p上。这是个1到n的映射,也就是一个输出标签可以对应于多个CTC路径,例如:“AA- -BC-”与“-AAB-CC”都可以被映射到标签序列“ABC”。因此可以用所有CTC路径的概率来表示输出标签z的概率:

(9)

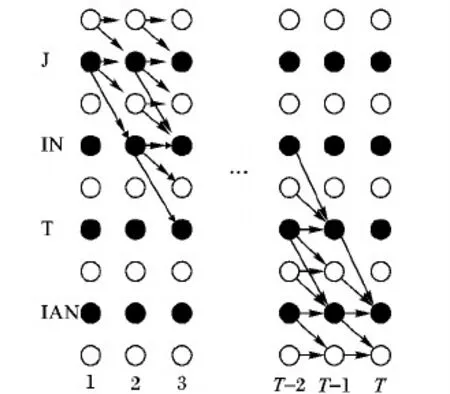
图3 中文“今天(J IN T IAN)”构成的篱笆图
然后计算标签序列z的似然度:
(10)
其中:t可以为1到T中的任意时刻。根据CTC目标函数lnP(z|X),对网络输出yt求微分,得:
(11)
其中:γ(l,k)={u|lu=k}表示返回在扩展标签序列l中标签为k的下标。由于目标函数可微,可通过BPTT训练算法进一步计算RNN内部权值的梯度。
2.2 基于加权有限状态转换器的中文解码
语音解码过程非常依赖于语言学知识,文献[15-16]都没能很好地融合语言文法规则。本文根据汉语的发音特点和语言学知识,将声学模型输出、发音词典和语言模型用WFST形式表示,构建一个基于WFST的综合搜索图来进行语音解码,有效地保证了语音语言学知识的完整性,同时大幅提高解码效率。
WFST解码网络由标记(Token)转换器、词典(Lexicon)和语法(Grammar)三部分构成,表示形式如图4所示。其中:
1)语法转换器G,主要编码了符合文法规则的单词序列,可以通过手工或数据学习的方式获得。图4(a)表示了由“今天好热”和“今天下雨”构成的语言模型,其中转换器输入、输出用“:”分隔,弧上权值对应语言模型概率。
2)词典转换器L,主要编码了发音词典构建单元与单词之间的映射关系,图4(b)为“好”字发音的WFST形式,其中标记
3)CTC标记转换器T,主要编码了语音帧级的CTC标签到词典单元的映射关系;图4(c)对应了发音单元“H”的CTC转换器,其中

图4 三种WFST网络示例
实际应用中,先分别生成各自层面的标记T网络、字典L网络和语法G网络,然后利用组合、最小化和确定化算法将它们组合在一起。首先,通过组合操作将词典网络L和语法网络G合并得到LG网络;其次对LG网络作确定化和最小化操作,进行权重推移以优化WFST网络;最后与CTC标签网络合并,生成一个完整搜索图S:
S=T∘min(det(L∘G))
(12)
其中∘、det和min分别表示组合,确定化和最小化操作[17-18]。搜索图S可以将本文声学模型输出的CTC标签映射为对应的文字序列,并且得到每种可能文字序列的概率,最终选择整体得分最高的文字序列作为识别结果。
基于BLSTM-CTC的端到端中文识别系统的具体识别流程如图5所示。图5的下半部分为双向长短时记忆神经网络的输入部分,是原始语音信号经过加窗分帧操作和特征提取后的声学参数序列;中间部分描述的是一个深度长短时记忆神经网络,分别由输入层、输出层和多个的循环隐层构成,能够根据上下文信息输出当前语音帧对应的CTC标签概率;上半部分描述了一个CTC篱笆网络,最终可以通过网络输出概率和完整的WFST转换器在CTC网络中搜索得到输入语音序列对应的字符串识别结果。

图5 BLSTM-CTC声学模型流程
3 实验与分析
3.1 实验数据
本文实验在THCHS-30中文数据集上进行。该数据集包含来自50人的35 h录音数据,采样频率为16 kHz,量化位数为16 b。其中25 h(10 000句)录音数据作为训练集,大约2 h(893句)作为开发集,剩下的大约6 h(2 495句)作为测试集,同时该数据集还包含一个基于单词的3-gram文法模型和一个基于音素的3-gram文法模型,及对应的词典和音素词典。由于汉语以音节为发声单元,包含23个声母和24个韵母,并且每个发音单元包含阴平、阳平、上声、去声和轻音5种声调,于是本文采用包含声调的共218个声韵母为基本建模单元,测试各个模型的性能。
3.2 声学模型对比
1)GMM-HMM。输入特征参数采用包含一阶、二阶差分共39维的梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient, MFCC),分别以单音子、三音子为建模单元进行实验,其中HMM状态经过基于决策树的状态聚类处理。单音子模型的状态数为656个,搜索图大小为718 MB;三音子模型的上下文相关状态数为1 658个,搜索图大小为747 MB。
2)DNN-HMM。特征参数为40维的梅尔标度滤波器组特征参数(Mel-scale Filter Bank, FBank),同样分别以单音子、三音子为建模单元。其中DNN模型包括4个隐层,每层1 024个神经元节点;输入层经拼帧操作后总共有440(40×11)个节点;在对单音子建模时,DNN输出层包含656个输出节点;对三音子建模时,DNN输出层包含1 658个输出节点。训练数据通过GMM-HMM系统进行强制对齐,以获得了语音帧级别的标注信息。另外,搜索图与上述GMM-HMM系统相同。
3)BLSTM-CTC。输入特征参数为包含一阶、二阶差分共120维梅尔标度滤波器组特征(Mel-scale Filter Bank, FBank),建模单元为单音节,其中BLSTM声学模型包括4个隐层,每层包含正向和后向传播两部分共640个LSTM单元;输入层包括120个输入节点;输出层包括220个输出节点。将CTC目标函数作为BLSTM网络的目标函数,和利用BPTT算法来训练循环神经网络。搜索图大小为439 MB。
3.3 结果对比
本文所有实验都是基于相同的训练集、开发集、测试集和语言模型,在GTX 1070显卡和i7 CPU构建的硬件计算平台上,利用Kaldi语音识别工具包完成了对以上各种声学模型的测试。图6展示了各系统性能对比结果,其中本文提出的BLSTM-CTC端到端系统获得了11.16%的音素错误率(Phoneme Error Rate, PER)和24.92%的单词错误率(Word Error Rate, WER)。与基于单音节和基于上下文相关状态的传统GMM-HMM识别系统相比,在PER上分别降低了21.04%和9.13%,在WER上分别降低了25.91%和11.02%。另外,与基于单音节的混合DNN-HMM系统相比,端到端系统在PER和WER上分别降低了4.7%和 4.43%;同时识别率上非常接近基于上下文相关状态的混合DNN-HMM识别系统的10.27%的PER和23.69%的WER。实验结果表明了基于BLSTM的声学模型在应用CTC训练准则后,充分挖掘循环神经网络对序列数据的建模能力,在模型表示能力上要明显优于GMM和DNN,同时也使得语音识别系统摆脱了不合理HMM条件假设。

图6 不同系统音素错误率(PER)、单词错误率(WER)和实时率(RTF)对比
另外,本文对语音识别系统的另一个重要性能指标——解码速度作了对比分析。由3.2节中给出的各模型搜索图和图6中实时率的对比,可以发现端到端系统在解码时间上相比GMM-HMM系统减少了66.7%,并且相比混合DNN-HMM系统减少了57.1%;同时搜索图(TLG)大小只有GMM-HMM系统的GMM-HMM和DNN-HMM系统的0.61倍。证实了端到端技术在有效降低识别错误率的同时优化了系统结构,并获得了巨大的存储空间和解码时间上的节省。
4 结语
本文深入研究深度循环神经网络,搭建了基于BLSTM-CTC的端到端中文语音识别系统。该端到端系统将CTC训练准则成功地应用在BLSTM声学模型训练中,摆脱了对HMM的依赖;结合汉语语言学知识,设计了基于WFST的解码方法,解决了声学模型、发音词典和语言模型难以融合的问题。在THCHS-30数据集上,实验表明该端到端技术不仅明显地降低了识别错误率,而且有效地简化系统复杂度,大幅提高了识别速度。当然语音识别是一个受外部环境和说话人因素影响非常大的多重识别过程,如何减少这些因素的影响,进一步提升模型的区分度和鲁棒性,将是下一阶段的研究工作重点。另外通过迁移学习,将端到端系统应用于不同领域或不同环境,也是接下来研究的方向。
