基于神经网络的微博情绪识别与诱因抽取联合模型
2018-10-16姬东鸿
张 晨,钱 涛,姬东鸿
(1.武汉大学 国家网络安全学院,武汉 430072; 2.湖北科技学院 计算机学院,湖北 咸宁 437100)
0 引言
情绪分析[1-2]是自然语言处理领域特别是社交媒体领域非常重要的研究内容之一,主要研究文本所蕴含的情绪及与情绪相关的深层信息。目前文本的情绪分析主要集中在情绪识别任务上,如文本的情绪极性分析,Li等[3]对文本的正负面情感程度进行了研究;或判断文本的情绪是高兴、喜欢、讨厌等,黄磊等[4]就对微博文本的情绪分类进行了探索。
为了实现深层次的文本情绪理解,情绪诱因抽取[5]已成为情绪分析中新的热点问题,所谓情绪诱因抽取就是针对文本中出现的被描述者的情绪,抽取出被描述者情绪产生的原因信息。当前对情绪诱因的抽取主要分为两类方法:一类是基于规则的方法[6],主要是通过语法规则构造情绪诱因与情绪之间的模板进行情绪诱因的抽取;还有一类是基于统计的方法[7],主要通过条件随机场(Conditional Random Field, CRF)和支持向量机(Support Vector Machine, SVM)分类器等方法进行情绪诱因的抽取。
这些诱因抽取方法假设情绪已经被识别出来,即把情绪识别和诱因抽取看作是两个独立的任务,容易引发错误在任务间传播的问题。情绪识别及诱因抽取是相互关联的:一方面,情绪识别依赖于诱因;另一方面,诱因抽取要求知道情绪类别。因此联合诱因抽取和情绪识别是自然的,能有效缓解串行模型所导致的错误传播问题。
微博目前已成为使用最广泛的社交媒体之一,其已成为情绪分析的主要对象之一[8]。微博不同于规范文本采用文本表达情绪,它通常采用表情符来表达情感或情绪。如下两则微博:

在这两则微博中,情绪通过表情符来表达。在微博①中表情符表达了作者“高兴”的心情,子句2为其诱因,在微博②中,表情符表达了作者“悲伤”的心情,子句1为其诱因,显然诱因与表情符的所表达的情绪有着直接关联。此外,已有研究[9]显示,表情符也存在歧义表达,如上面例子,同一表情符在不同诱因下表达不同的情绪,因此对表情符的情绪消歧或识别也是非常重要的。
基于微博文本的特点,本文提出情绪诱因抽取和表情符情绪识别的联合模型,该模型把情绪诱因抽取和表情符情绪识别形式化为一个统一的序列标注任务。模型采用双向长短期记忆(Bi-directional Long Short-Term Memory, Bi-LSTM)模型[10]与条件随机场(CRF)模型[11]联合进行训练,充分利用了远距离信息及全局特征,同时避免了复杂的特征工程。为了训练和评测模型,本文同时构建一个基于微博的情绪诱因语料库。
1 相关工作
情绪诱因任务由Lee等[12]在2010年首次提出,他们使用的方法是基于规则模板的方法,对于数据集出现的情绪诱因的语法结构进行规则集的构造,从而进行诱因的提取。Chen等[13]和Russo等[14]开始在基于规则模板的基础上又加上了情绪诱因与情感表达之间的位置关系。然而,规则很难覆盖所有的语言现象,而且规则之间很容易出现难以发现的矛盾,最重要的是规则往往针对于某个特定领域的文本而难以适用于其他领域的文本。随着统计学的方法在自然语言处理领域任务表现越来越好,袁丽[15]通过对语言学线索词、句子距离、候选词词法等特征构建特征向量,应用支持向量机分类器和条件随机场对文本的情感原因进行了判别。Ghazi等[16]在2015年使用了条件随机场来进行情绪诱因的抽取,但是局限于必须含有情感表达的描述且描述内容与情绪诱因在同一个子句当中。最近,基于神经网络的方法被应用在该任务,Gui等[17]将情绪诱因任务看作一个问答系统(Question-Answer, Q-A)的问题,采用了深度卷积神经网络的模型来进行训练,得到了不错的结果。慕永利等[18]则采用了集成的卷积神经网络的模型将情感诱因看作子句级别上的分类问题进行训练与测试,在自己的标注的数据集上得到了超过普通方法的结果。
诱因抽取通常可看作是一个序列标注任务,当前对序列标注采用的方法通常是隐马尔可夫模型(Hidden Markov Model, HMM)[19]、CRF等,特别是CRF充分利用上下文信息及全局优化达到了较好性能,但CRF模型通常采用人工设计的特征,可能导致复杂的特征工程,并且不能充分利用远距离信息。当前循环神经网络(Recurrent Neural Network, RNN)模型由于减缓了复杂的特征工程及充分利用上下文信息已广泛应用于序列标注问题。特别它的变种Bi-LSTM与CRF结合所结合成的双向长短期记忆条件随机场(Bi-LSTM CRF, Bi-LSTM-CRF)模型[20]结合了二者的优点,在序列标注问题如命名实体识别、词性标注、句法解析等取得了最好效果。
当前,研究人员已建设了一些情绪诱因语料[21],但它们都是针对规范文本,而对社会媒体如微博等缺少相关诱因标注语料。本文针对微博文本情绪表达的特点,构建一个较大模型的标注语料,并采用机器学习进行诱因及情绪联合分析。
2 微博情绪语料的构建
由于缺少公开基于中文微博的关于情感诱因抽取的数据集,因此本文将通过人工标注方式建立了一个情绪诱因及表情符情感的微博数据集。本章将首先介绍标注方案,然后给出标注语料的统计信息。
2.1 标注方案
慕永利等[18]在对规范文本标注时把诱因抽取看作是子句的识别,即把含有诱因表达所在的子句整体标注为诱因,本文也采用此标注方案。此外由于微博通常用表情符来表达情绪,对微博的情绪识别可看作是对表情符的情绪识别,因此把情绪标注在表情符上。情绪标签采用常用的情绪分类法,分为7类,包括:高兴(happiness)、悲伤(sadness)、惊讶(surprise)、害怕(fear)、厌恶(disgust)、愤怒(anger)和无情感(none)。
例子①、②的标注格式分别如下:
其中cause标签内文本表示诱因,其中emoji属性表示它所属于哪个emoji的诱因,emoji标签表示表情符,其包含两个属性:id及情绪label。
2.2 语料构建
首先在新浪微博上随机爬取了2017年7月至2017年10月期间的微博文本共27 000篇,将文本长度小于5个字(英文以单词计数不包括标点符号)的文本、不包含表情符的文本、广告性质的文本和重复的文本剔除后获得了5 771篇待标注的微博文本。对筛选后的6 771篇微博文本进行人工标注,每一处表情符的分类由两名标注者进行标注,不统一的再由第三名标注者进行判定,然后由决定了表情符分类的标注者标注该表情符对应的情感诱因,情感诱因以子句为单位进行标注。最后得到一个语料数据集。该数据集包含9 386个表情符,29 061个子句,其中诱因子句数为10 465。表1显示了不同情绪类别下的表情符个数与诱因。
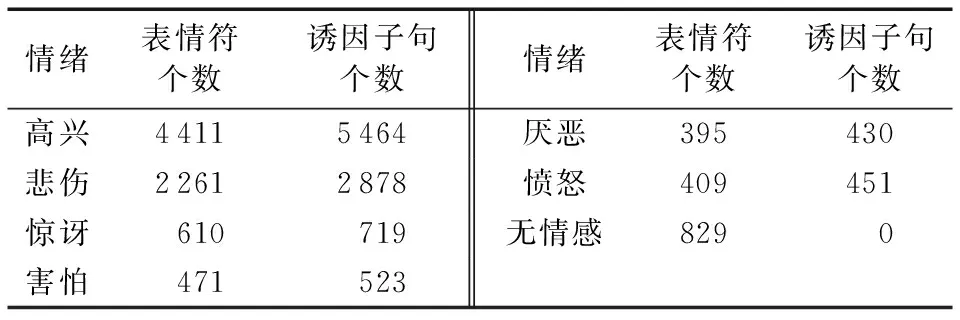
表1 不同情绪类别下的表情符个数与诱因统计
由于表情符存在歧义表达,即使同一种表情符在不同的语境中很有可能表达出不同的情绪,因此本文对数据集中出现次数最多的10个表情符的情绪类别进行了统计,结果如表2所示,从表中可以看出表情符往往包含超过一种情绪,这说明表情符表达出的情感除了自身的意义外很大程度上受上下文中的情绪影响,从一定程度上能够反映出上下文的情绪,而上下文的情绪与情绪诱因之间是相互关联的。
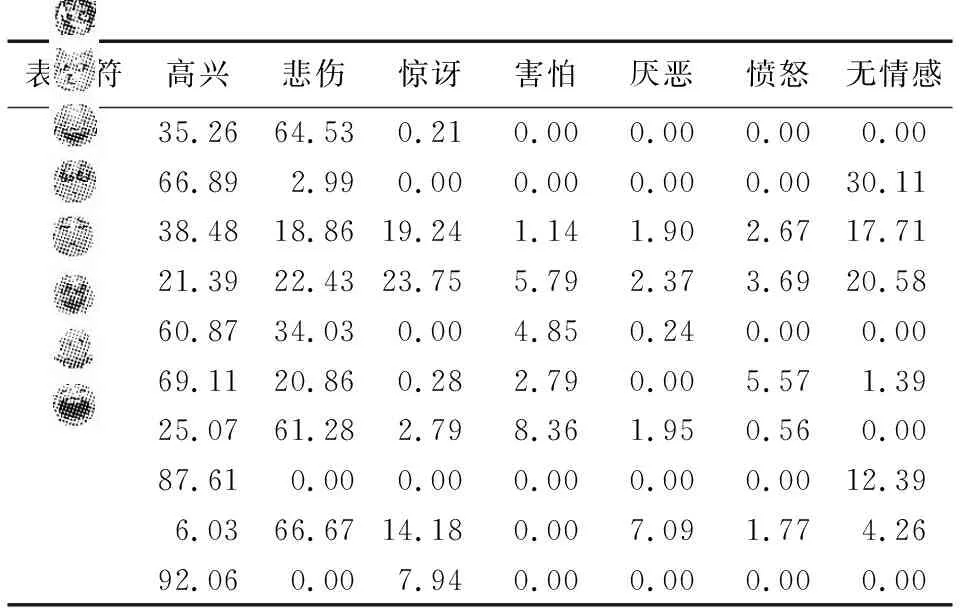
表2 表情符情绪类别分布 %
3 基于Bi-LSTM-CRF的联合模型
3.1 CRF模型
已有研究大多将情感诱因抽取看作一个子句层级上的分类问题[16],但分类问题会割裂子句与子句之间的全局关联。本文提出把诱因抽取看作是一个标注问题,从词级别可设置为三个标签B-Cause、I-Cause、O,其中B-Cause、I-Cause联合来标注诱因子句,B-Cause表示诱因子句的第一个词,I-Cause表示诱因子句的其他部分,O表示非诱因子句。对表情符的情感识别也可看标注问题,其标签即是情绪类别,可分别表示为:Happiness、Sadness、Fear、Anger、Surprise、Disgust、None。综合两类标注问题,可自然将其统一为一个标注问题,其标签即为两类标注问题的标签集合。对例②其标注结果见图1。
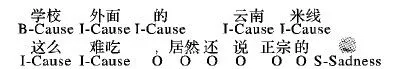
图1 微博例②的标注结果
因此可将诱因抽取与情绪识别形式化为联合的条件随机场(CRF)模型[18],CRF模型更多关注的是一个序列的整体性,它通过考察序列的联合概率来进行判别,因此能够有效地考虑到上下文的标签信息和全局信息。对于例②,图2给出基于CRF的网络结构图。
3.2 Bi-LSTM-CRF模型
CRF模型利用远距离和全局特征优化,在序列标注问题中得到广泛应用,但需要复杂的特征工程。LSTM避免了复杂的特征工程。当前Bi-LSTM-CRF结合了Bi-LSTM模型与CRF模型的优点,在序列标注问题如命名实体识别、词性标注、句法解析等取得了较好效果。本文将采用Bi-LSTM-CRF作联合诱因抽取与情绪识别。图3给出该模型对于微博例②的框架。

图2 微博例②的CRF网络结构
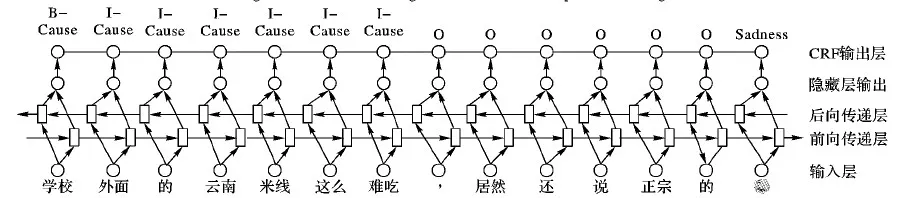
图3 微博例②Bi-LSTM-CRF模型结构
在联合诱因识别与情绪分类任务中,其输入微博由单词和表情符序列组成,记作X=(x1,x2,…,xn);输出为Y=(y1,y2,…,yn),即输入单词和表情符所对应的标签。
基于Bi-LSTM-CRF的联合模型分为三层,分别为输入层、Bi-LSTM层、CRF层。
输入层 输入层之前会将微博通过Word2Vec预先训练好的词向量集合进行转换,将每个词语和表情符变成一个低维的空间向量xt,它们的集合即模型的输入X=(x1,x2,…,xn);
Bi-LSTM层 为双向长短时记忆模型。这是一种特殊循环神经网络(RNN)模型,主要目的用来处理序列数据,其在自然语言处理中取得了广泛应用。LSTM能够提升神经网络接受输入信息及训练数据的记忆机制,让输出结果得到大幅度的提升。对于短文本中的第t个单词wt,首先将wt映射到一个词向量xt∈Rd,一个LSTM单元的输入为:单词xt,上一输出隐状态ht-1,上一内存状态ct-1,输出为ht、ct。具体公式如下:
it=σ(Wixt+Uiht-1+bi)
ft=σ(Wfxt+Ufht-1+bf)
ct=ft⊙ct-1+it⊙ct
ot=σ(Woxt+Uoht-1+bo)
ht=ot⊙tanh(ct)
对于普通的LSTM,其存在一个缺点,即只能正向读取文本,因此本文使用能够双向读取文本的Bi-LSTM模型。Bi-LSTM包含一个正向的LSTMforward,由x1读取到xT,以及一个反向的LSTMbackward,由xT读取到x1:
xt=Wewt;t∈[1,T]

CRF层 该层将上一层得到的输出H作为输入,得到观测序列X和与其标注序列T的预测输出。假设CRF层的状态转移矩阵为A,其中Ai, j表示从第i个状态转移到第j个状态的概率,Bi-LSTM神经网络的输出为H,其中Hi, j表示观测序列中的第i个词标记为第j个标签的概率。因此对于观测序列X=(x1,x2,…,xn)和对应的标注序列Y=(y1,y2,…,yn)的预测输出为:
3.3 训练过程
模型训练采用最大条件似然估计,对于输入x预测其标签y的概率表示为:
给定一个训练集{xi,yi},其优化目标就是最大化其对数似然估计函数:
模型使用随机梯度下降方法来进行前向传播和后向传播的训练过程,具体算法如下:
输入:数据集{xi,yi},单词向量集V,参数θ, 迭代次数k;
输出:参数θ。
1)
for 1 tok
2)
for每一个训练微博子集
3)
①Bi-LSTM模型的前向传播:
4)
正向LSTM过程传播
5)
反向LSTM过程传播
6)
输出隐层变量H
7)
②CRF层将H作为输入进行前向传播和后向传播
8)
③Bi-LSTM模型的后向传播:
9)
正向LSTM过程传播
10)
反向LSTM过程传播
11)
④更新模型参数θ
4 实验与分析
4.1 数据参数设置
实验数据为本文前面所提人工标注数据集,共6 771个实例。实验评估方式以常用的序列标注评价指标准确率、召回率、F值作为评价标准。需要说明的是,本文假设情感诱因以子句为基础单位,所以在计算情感诱因的指标时,将模型计算得到的序列按子句进行拆分,覆盖超过2/3子句长度的部分会补全成整个子句,补全完成后再进行上述指标的计算。实验过程中,对数据集中的数据采用十折交叉检验的方法,求得各个指标的值。
模型的输入采用Word2Vec来表示文本的词向量,训练过程中采用反向传播方法进行参数调整,损失函数采用交叉熵损失函数。通过进行大量实验及参数调整后,获得的超参数设置如下:词向量维数d为200,隐藏层单元数hidden为300,学习率lr为0.01,dropout的百分比为50%,迭代次数为80。
4.2 实验结果
实验中采用以下模型与本文模型作比较:
1)串行Bi-LSTM-CRF模型。将情绪诱因抽取和表情情绪识别看作两个单独的序列标注问题,使用Bi-LSTM-CRF模型先进行表情符情绪识别,再作诱因抽取。
2)串行标注-分类模型。将情绪诱因抽取看作序列标注问题,表情情绪识别看作分类问题,先使用CNN分类模型进行表情符情绪识别,再使用Bi-LSTM-CRF模型进行诱因抽取。
3)联合CRF模型。将情绪诱因抽取和表情情绪识别看作统一的序列标注问题,使用CRF模型进行训练和标注。其特征包括上下文、词性、句法、语义、情感词等特征。
已有研究显示[22]Bi-LSTM-CRF模型在序列标注任务中达到了最好性能,因此本文未与其他如HMM、支持向量机(Support Vector Machine, SVM)等模型作比较。
表3给出了实验结果。从表中可以看出,本文所提联合Bi-LSTM-CRF模型达到了最好性能。比较串行Bi-LSTM-CRF模型,本文模型在情绪识别F值提升17.12个百分点,在诱因抽取F值提升5.82个百分点。情绪识别的F值提升明显,说明了情绪诱因对于表情符的情绪类别有着相当大的影响,同时诱因抽取F值的提升说明了表情符的情绪表达有助于情绪诱因的抽取,减缓了串行模型所导致的错误传播问题。比较联合CRF模型,情绪识别F值提升8.32个百分点,在诱因抽取F值提升11.82个百分点,主要是Bi-LSTM较有效利用远距离信息,同时也避免了复杂的特征工程。此外,对比两个串行模型,CNN模型相较于Bi-LSTM-CRF模型在情绪识别任务上F值高出了12.13个百分点,而随后的诱因抽取都使用的是Bi-LSTM-CRF模型,前者也比后者高出了2.89个百分点,说明了情绪表情符的情绪类别对诱因抽取有着一定的影响。
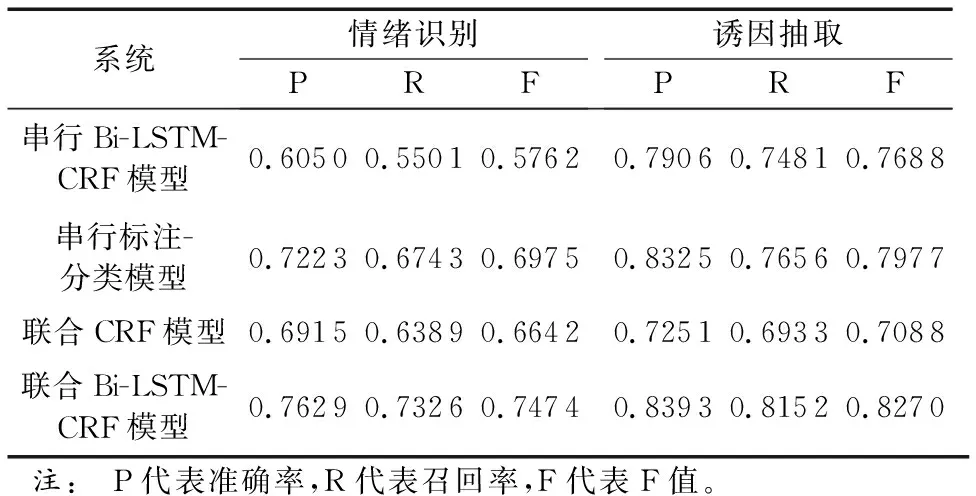
表3 不同方法的实验结果比较
为了进一步比较联合模型与串行联合的不同,在实验中分别给两种模型中不同情绪类别的F值。表4给出了实验结果。联合模型比串行模型性能更好。特别是如高兴、悲伤的情绪识别与诱因抽取的F值明显高于串行模型。可能是高兴、悲伤的语料最多,使得模型训练效果更好。

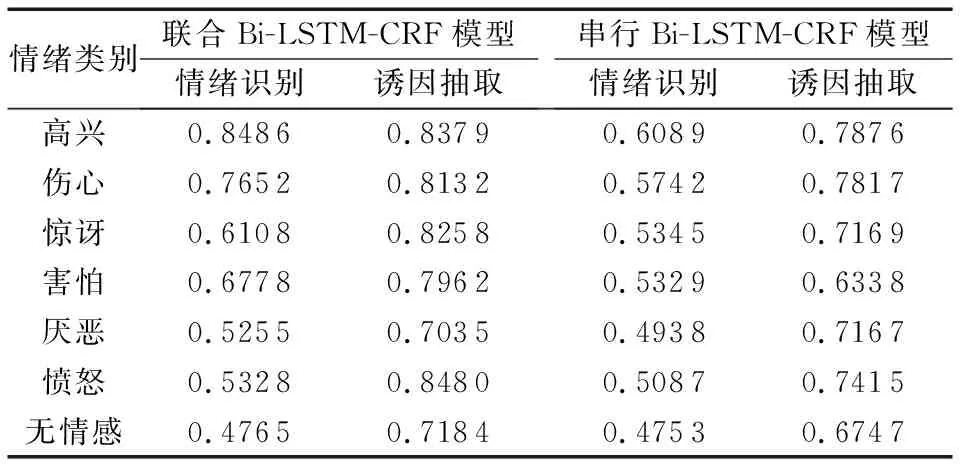
表4 在不同模型中各个情绪类别的F值比较
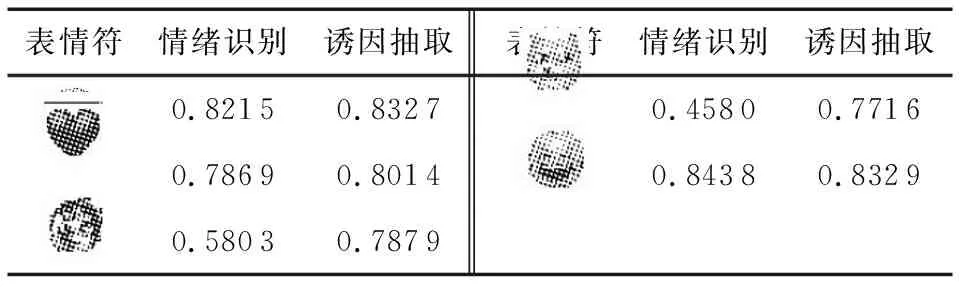
表5 不同表情符在联合模型中的F值对比
4.3 讨论分析
实验结果显示联合模型比串行模型性能有较大提升,主要是因为联合模型充分利用两者的信息,减缓了串行模型所产生的错误传播问题。图5给出联合Bi-LSTM-CRF模型与串行Bi-LSTM-CRF模型的识别结果,其中联合Bi-LSTM-CRF模型的识别结果为正确结果,而串行Bi-LSTM-CRF模型由于表情符错误识别为Sad,从而诱因抽取错误。这里可以看出,能否正确地识别出表情符的情绪类别对诱因抽取的结果有着相当大的影响。

图4 模型输出实例结果比较
5 结语
情绪诱因是情绪分析中相当重要的一项内容,能够进一步理解文本中的情绪特征,而微博文本中的表情符可以表达出这一部分文本的情绪。本文针对微博的文本特征,提出一个联合的情绪诱因和表情符情绪识别模型,该模型把情绪诱因和表情符情绪识别统一成一个序列标注任务,采用Bi-LSTM-CRF模型,不仅避免了复杂的特征工程,而且充分利用远距离信息和全局信息,与串行模型相比在诱因抽取任务上F值提高了5.82个百分点,在表情符情绪识别的任务上F值提高了17.12个百分点的性能。结果显示联合模型充分解决串行服务的错误传播问题,有效地提高了系统的性能,对下一步进行更深层的文本情绪分析提供了帮助。不过模型仍有不足,现在本文对于情绪诱因只能够进行粗粒度的抽取,下一步,将从语义事件的角度深度分析诱因的构成与情绪类别的关系。
[15] 袁丽.基于文本的情绪自动归因方法研究[D].哈尔滨:哈尔滨工业大学,2014:49-60.(YUAN L. The Study on Text-based Emotion Cause Detection[D]. Harbin: Harbin Institute of Technology, 2014: 49-60.)
[16] GHAZI D, INKPEN D, SZPAKOWICZ S. Detecting emotion stimuli in emotion-bearing sentences [C]// Proceedings of the 2015 International Conference on Intelligent Text Processing and Computational Linguistics, LNCS 9042. Berlin: Springer, 2015:152-165.
[17] GUI L, HU J, HE Y, et al. A question answering approach for emotion cause extraction [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: EMNLP, 2017: 1593-1602.
[18] 慕永利,李旸,王素格.基于E-CNN的情绪原因识别方法[J].中文信息学报,2018,32(2):120-128.(MU Y L, LI Y, WANG S G. Emotion cause detection based on ensemble convolution neural networks [J]. Journal of Chinese Information Processing, 2018, 32(2): 120-128.)
[19] RABINER L R. A tutorial on hidden Markov models and selected applications in speech recognition [J]. Readings in Speech Recognition, 1990, 77(2): 267-296.
[20] 张子睿,刘云清.基于BI-LSTM-CRF模型的中文分词法[J].长春理工大学学报(自然科学版),2017,40(4):87-92.(ZHANG Z R, LIU Y Q. Chinese word segmentation based on bi-directional LSTM-CRF model [J]. Journal of Changchun University of Science and Technology, 2017, 40(4): 87-92.)
[21] GUI L, WU D, XU R, et al. Event-driven emotion cause extraction with corpus construction [C]// Proceedings of the 2016 Conference on Empirical Methods on Natural Language Processing. Austin: EMNLP, 2016: 1639-1649.
[22] HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging [EB/OL].[2017- 12- 27]. https://arxiv.org/pdf/1508.01991.pdf.
