多信息融合技术在船舶柴油机故障诊断中的应用
2018-10-16尚前明王瑞涵唐新飞
尚前明, 王瑞涵, 陈 辉, 唐新飞
(武汉理工大学 能源与动力工程学院, 武汉 430063)
柴油机的性能直接影响着船舶航行的安全和效率。柴油机工作环境恶劣,故障发生率极高。并且,柴油机的构造复杂,出现故障时,维修难度较大,维修时间较长,一旦维修失误,将极有可能引发严重事故,造成海洋污染和货物的经济损失,甚至危及海员的生命。因此,对柴油机故障和潜在危险的预测至关重要[1]。但随着柴油机技术的不断发展,传统的故障诊断方法已无法满足现实需求。基于融合的综合诊断技术已经成为现代船舶故障诊断领域的一个新的研究方向,并随着现代信息技术的发展,船舶行业也有了足够的数据积累,对柴油机的故障实施智能诊断已具有可行性[2]。
目前国内外柴油机的智能诊断技术还不够成熟,大多数采用监督学习,即神经网络。文献[3]通过对故障实例和诊断经验的学习,实现对故障的识别。而神经网络的学习时间较长,在初始数据较复杂时,容易陷入局部极小值,影响诊断结果,这在工程实践中往往难以实现。还有一些文献采用无监督学习,即分类算法,将同一工况下的数据进行分类,如文献[4]和文献[5],但柴油机故障复杂多样,大多数分类方法仅局限于二分类,在样本数据量不平衡时,预测偏差较大。文献[6]采用多种技术融合的方法诊断柴油机故障,取得可喜的成绩。本文采用无监督学习和监督学习融合的方法进行柴油机故障诊断。利用k均值聚类分析(k-means)和BP神经网络对柴油机运行状态进行诊断,并在此基础上进行优化,利用主层次分析法(Principal Component Analysis,PCA)对数据进行特征值提取,对样本参数进行有效的降维,结合k-means聚类分析和BP神经网络来建立柴油机故障诊断模型,使得故障系统对获得的信息进行处理,实现柴油机故障的智能诊断。
1 基于数据挖掘技术的故障诊断
故障诊断领域的方法大致可划分为基于分析模型的方法,基于定性经验知识的方法和基于数据挖掘的方法等3类。
1) 基于分析模型的方法适用于信息充足且可以建模的系统,数学建模的建立必须了解整个过程的机理且建模必须精准。
2) 基于定性经验知识的方法适用于不能或不易建立机理模型、信息不充分的系统。基于分析模型的方法不可能获得复杂机理模型的每一个细节,而基于定性经验知识需要复杂高深的专业知识和长期积累的经验,这超出了普通工程师所掌握的范围,从而变得难以实现[7]。
3) 基于数据挖掘的方法是在以上两类方法基础之上的一种自动化诊断方法,汲取以上两类方法的经验和方法,设计出合理的诊断过程。
2 数据挖掘技术的故障诊断原理
采用数据挖掘技术对设备进行一系列的故障诊断,其原理就是根据设备传感器的记录数据,从这些数据信息中提取其中隐藏的有潜在价值的信息,找出其内在规律。对大量数据进行抽取和分析,最后进行模型化处理,预测其运行的趋势,并对其可能存在的运行状态分类。具体体现形式就是数据的分类,而数据挖掘分为监督学习和非监督学习两大类[8]。
本文基于数据挖掘的原理,提出一种基于无监督和监督学习的柴油机故障诊断方法,无监督学习采用k-means聚类分析,监督学习采用BP神经网络,并采用统计学原理对算法做进一步优化。对一组数据分别用这2种算法进行处理,分析试验结果,用统计学优化后的算法诊断准确度和效率更好。该算法的诊断过程见图1。
2.1 无监督学习
无监督学习是事先没有训练样本的,直接对数据进行建模分类。聚类算法就是一种典型的无监督学习[9]。
本文聚类算法选择简单高效的k-means算法。以往的算法像回归、朴素贝叶斯及SVM都必须有具体的类别,而k-means算法是基于距离的聚类算法,关键在于找到类别,通过均值对数据点进行聚类,将同一类别的特征放在一起。预先设定每个类别的初始质心,对相似的数据点进行划分,最终通过划分后的均值迭代获得最优的聚类结果。 其算法步骤为
1) 随机选取n个聚类点,为k1,k2,…,kn∈Rn。
2) 重复下面的过程直到收敛。
对于每一个样例i,计算其应该属于的类:
(1)
式(1)中:ci为i样例与n个类中距离最近的那个类,其值是1到n个类中的一个。
对于每一个类j,重新计算该类的质心为
(2)
3) 定义一个畸变函数,来描述计算的收敛性为
(3)
J函数表示每个样本点到其质心的距离平方和,由于J函数是一个非凸函数,有可能会陷入局部优化,不能保证取得的最小值就是全局最小值。为解决该问题,本文采用EM思想。EM思想是E步来确定隐含类别变量c,M步更新参数k使得J函数最小化。通过开始指定一个ci,为使得J函数最小,不断调整kj的值,使J减少,此时发现若有更好的ci(使得质心与样例xi距离最小的类别)指定给xi,ci可得到重新调整,上述过程重复,直到没有更好的ci指定。
2.2 监督学习
监督学习是通过训练样本构建数学模型,对未知数据进行分类。BP神经网络便是一种典型的监督学习[10],并广泛应用于信息处理中。
BP神经网络的训练算法是反向传播算法,即将均方误差(MSE)作为全部权值和全部偏置值的函数。全部输出向量和目标输出向量之间的距离(差的模)越小,均方误差越小。均方误差的值越小,则神经网络的行为与想要的行为越接近[11]。
2.3 算法优化
在对柴油机进行故障诊断时,经常会有多个故障征兆表示一个故障的情况。征兆变量数目较多会明显增加分析问题的复杂性。因为有些信息是多余的,所以可采用主层次分析法。主层次分析法是一种统计方法,是多元统计学中一种常用的降维方法[12]。主层次分析法采取的是一种数学降维的方法,将原来众多具有一定相关性的征兆变量,经过数学方法重新组合为一组新的相互无关的综合变量来代替原来变量,将多个变量综合为少数几个代表性的变量,使这些变量既能代表原始变量的绝大多数信息,又不互相相关,减少数据量,从而减少工作量。主层次分析法的步骤为
1) 对原始数据进行标准化处理。
(4)
2) 计算相关系数矩阵。
(5)
3) 求出相关矩阵的特征值(λ1,λ2,…,λp)和特征向量。
ai=(ai1,ai2,…,aip),i=1,2,…,p
(6)
4) 根据相关矩阵的特征值,根据式(7)选择重要的主成分(特征值越大的主成分所占的贡献率越大)。

(7)
5) 按照式(8)计算求出主成分,依据主成分得分的数据,进一步对问题进行后续的分析和建模。
Fij=aj1xi1+…+ajpxip(i=1,…,n;j=1,…,k)
(8)
式(8)中:aj1,aj2,…,ajp为式(6)中的特征向量,xi1,xi2,…,xip为式(4)中标准化处理后的数据。
先将同一征兆下的数据进行聚类处理,简化参数,并呈现一定的规律性。
1) 第1种算法是将聚类处理后的数据作为神经网络的输入量,进行柴油机工况的识别,对试验进行分析。
2) 第2种算法是在聚类之前,先将数据通过PCA法对数据降维,使得原数据的多个征兆极大简化。
将经过PCA处理后的数据进行聚类处理,2种算法处理后的数据最终作为神经网络的输入,对柴油机工况进行识别。最后比较2种方法的准确度和效率。
3 故障诊断实例
本文以MAN B&W 10L90MC型船用柴油机为研究对象。柴油机在90%负荷下,在5种常见工况(正常、喷油器喷嘴结碳、排气阀漏气、高压油泵磨损及活塞环损坏)下所测得的数据,每种工况共6组数据。其中{S1,S2,S3,S4,S5,S6,S7,S8}为征兆,分别为平均有效压力、排气总管温度、排气压力、扫气压力、压缩压力、最大爆发压力、转速及耗油率。
3.1 数据预处理
样本数据的预处理采用k-means算法来实施聚类,其中k值的选择,根据J函数的计算来选择。聚类方法能使得原始样本数据简化,且呈现一定的规律性。分类结果及中心见表1。

表1 分类结果及中心
限于篇幅,仅列出每种工况经过k-means算法聚类后的两个样本数据见表2。表2中:Ⅰ为正常工况;Ⅱ为喷油器喷嘴结碳;Ⅲ为排气阀漏气;Ⅳ为高压油泵磨损;Ⅴ为活塞环损坏。
3.2 神经网络诊断故障
选取经k-means处理后的样本数据,采用MATLAB软件使用神经网络,以8种聚类分析后的征兆作为输入量,工况模式输出矩阵作为目标向量,经过不断测试,网络层数及结构最终确定为8-9-5。
输出分别为矩阵:[1,0,0,0,0]表示正常工况;

表2 部分样本数据聚类结果
[0,1,0,0,0]表示高压油泵磨损;[0,0,1,0,0]表示喷油器喷嘴结碳;[0,0,0,1,0]表示活塞环损坏;[0,0,0,0,1]表示排气阀漏气。 每种工况的5组数据采用“训练-测试”的方法进行多组试验。选取训练最好的网络,网络训练误差曲线见图2。
由图2可知,当计算达到第8步时,训练误差达到了目标误差的要求。将每工况最后的一组数据作为检验样本来检验训练好的网络,检验结果见表3。
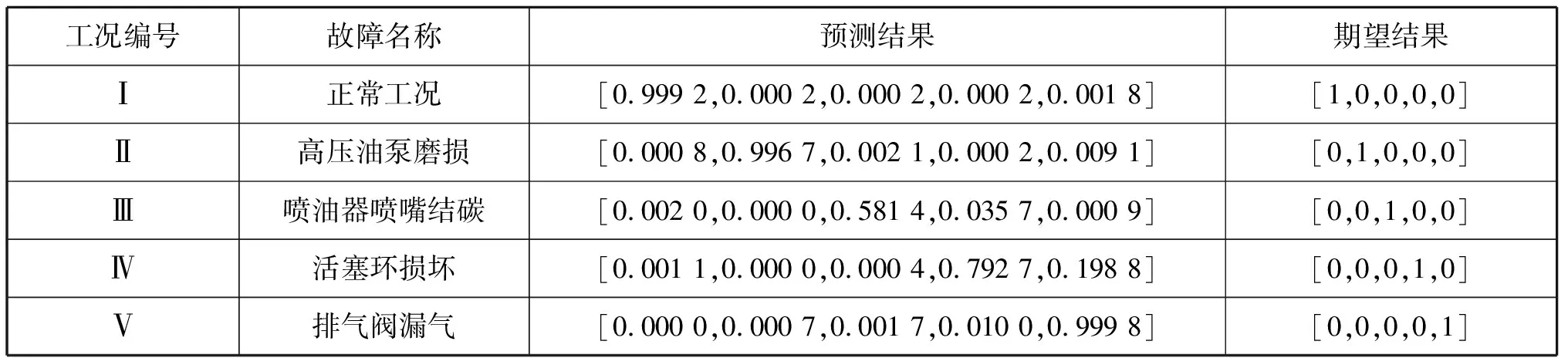
表3 柴油机故障预测结果
表3中在正常工况和高压油泵磨损排气阀漏气的3种工况,此神经网络诊断精度都很高。在喷油器喷嘴结碳和活塞环损坏的工况下,虽然隶属度分别为0.581 4和0.792 7明显大于其他故障类型的隶属度,但是隶属度相对较小,诊断精度需进一步提高。
3.3 算法优化处理
由多个征兆来表现一个工况,这大大的增加神经网络的训练时间,且显著增加分析问题的复杂性,所以在某些情况下会减弱神经网络的监测精度。
其实在多个征兆之间存在一定的相关性,所以可采用PCA方法,对原始数据进行降维,将具有一定相关性的原始征兆数据,重新组合为一组新的相互无关的综合变量。对数据进行PCA降维处理。虽然非线性相关的数据降维后会使原始数据的部分信息丢失,但由于柴油机各征兆之间存在一定的相关性,可计算各成分的贡献率,贡献率越大,包含原始数据的信息量就越多。通过累计贡献率的计算,选择较少维数的参数来表示原始数据大多数的信息,可降低学习算法的复杂性。
对数据进行标准化处理后,求数据的特征值和成分贡献率,得到的特征值从大到下排列见表4。

表4 主成分的贡献率及累计贡献率
主成分个数的选取根据主成分的累计贡献率来决定,贡献率根据特征值在所有特征值中的比重来决定,一般要求累计贡献率大于85%,能保证计算后的变量能包括原始变量的绝大多数信息。根据表4和累计贡献率,前4个特征值的贡献率便已超过85%,达到93%,即经计算得到的前4个综合变量就可包括原始数据8个变量中93%的信息量,然后计算出第1、第2、第3、第4的主成分值。
根据标准化的原始数据,按照各个样品,分别带入式(5),可得到前4个主成分下的各个样品的新数据,即为主成分得分见表5。
表5 主成分计算后的样本数据
对使用主成分分析法计算后的样本数据进行k-means分类,将复杂的数据换成简单的数字。根据数据不同的k值聚类分析进行具体的分类。采用EM思想,根据类之间有明显的区分和类别的数量越多的要求来确定k值。分类结果及中心见表6。

表6 主成分聚类结果
根据表6的聚类中心,将各个主成分的数值进行分类,得到各个主成分的分类结果见表7。

表7 主成分分类结果
经过PCA和k-means两种算法简化原始数据,将得到的新数据用神经网络采用相同的方法进行试验,网络结构为4-7-5。多次试验,选取训练最好的网络,网络训练误差曲线见图3。
由图3可知,当计算达到第7步时,训练误差达到了目标误差的要求。将每工况最后的一组数据作为检验样本来检验训练好的网络,检验结果见表8。
对表8的结果进行分析,得到经过PCA和k-means处理后的数据,神经网络诊断工况的精度都很高,且这种优化后的算法能很好也识别在喷油器喷嘴结碳和活塞环损坏的2种故障。

表8 柴油机故障预测结果
3.4 分析试验结果
2次的试验结果对比见表9。由表9可知,所用经PCA优化聚类分析的神经网络算法,不仅能保持较高的诊断率,同时也大大减少神经网络的输入节点数和隐含层数,简化了网络结构,且减少了平均误差平方和迭代数,提高诊断速度。

表9 两种诊断算法的试验结果对比
4 结束语
本文根据对数据挖掘的理解,提出一种基于无监督学习和监督学习相结合的柴油机故障诊断算法,并用统计方法对原始数据降维,进而对算法进行优化。试验分析证明,这种优化算法可靠并且有效,采用这种算法可大大提高柴油机故障诊断的效率,不仅可识别柴油机故障类型,且能较多在最大程度上简化监测数据,为诊断故障节约了较多的时间。
