基于分类规则的大学生体质测试数据挖掘的应用研究
——以西安石油大学三年级学生为例
2018-10-15李寿邦
李寿邦
(西安石油大学 体育系,陕西 西安 710065)
引 言
当代大学生的体质健康水平不仅关系个人健康成长和幸福生活,而且关系整个民族的健康素质,关系我国人才培养的质量。随着我国青少年体质调研结果的出台,持续下降的体质水平令人触目惊心,已经引起了国家多部委和各高等院校的高度重视。胡精超和王莉[1]对河南理工大学学生体质测试原始数据进行数据处理后,应用关联规则对其进行数据挖掘,以体质测试单项指标作为输入、体质总评成绩为输出,发现:对大学女生体质影响较大的指标是速度、柔韧性和肺活量;对大学男生体质水平影响较大的是速度,身体形态的偏胖或超重不是影响其体质的重要因素。从而得出体质促进可以从柔韧性、速度和耐力等指标入手的结论。张崇林等[2]采用关联规则数据挖掘法,对上海市某高校教职工体质测试数据进行相关分析,建立体质总评与各单项指标关联规则数据挖掘模型,发现:对青年教职工体质影响较大的单项指标为最大摄氧量、舒张压、左手握力、仰卧起坐、体脂率等;对中年教职工影响较大的指标为最大摄氧量、上肢力量、躯干力量等。并依此结论建议,为促进高校教职工的体质健康,应优先考虑发展其心肺机能,改善上肢和躯干力量[2]。刘辛和杨素锦[3]采用一种基于数组的Apriori算法,对高校学生体质测试项目进行挖掘分析,找出了各测试项的关联关系并对各测试项目设置的合理性进行了判断。赵常红和王琳等[4]对西北民族大学男生和女生体质测试数据进行了对比研究,运用关联规则的Apriori算法并设置支持度、置信度与提升度的阈值,分别筛选出男生和女生数据的强关联规则,得出符合“总分成绩=及格”的测试指标。并建议学生体质测试中应加强女生立定跳远和男生引体向上的训练,这对提高民族院校学生身体机能的综合素质具有重要的参考价值。
目前高等院校已经积累了海量的大学生体质测试数据,相关研究已卓有成效。但是,这些研究成果大多停留在单项测试数据的浅层统计和分析上,或者只是对部分项目数据的关联分析,并不能揭示所有测试项目的内在联系,更没有指出各个测试项目的分类规则,所以不能针对大学生的实际体质状况,就所有测试项目提出全面科学的锻炼和训练建议。
本文采用ID3算法分析并提取了隐藏于“跑动石大”体质测试手机APP平台数据库的大三学生体质测试数据中所有测试项的分类规则,分析并从这些数据中挖掘出当代大学生身体素质同类体质特征型的共同性质以及不同体质个体之间差异的特征型知识,对于不同学生就个体差异采取针对性的锻炼和训练措施,提高个体的身体素质具有直接的指导作用。另外,对于专家学者关于体育课程价值取向、课程体系构建、课程评价等方面的调查和研究,对于“课内外一体化”体育教学模式的构建、针对各体育选项“一体化”教学的实现、“一体化”网络资源的开发等都具有较高的探索和研究价值。
1 分类分析
分类是对一组具有共同属性的数据(一组训练样本数据)按照其属性的取值进行分类的分析过程(通过数据挖掘分类算法进行学习),并通过分析的结果寻找每一类的规律,即分类规则或分类模型。以此分类规则为未来数据分类的依据,并依照对未来数据分类的结果作出预测[5]。分类分析是一项非常重要的数据挖掘类型,它反映了同类事物共同性质的特征型知识和不同事物之间差异的特征型知识。分类主要用于预测,其目的是找出一组能够描述数据集合典型特征的模型或函数,以便能够识别未知数据的归属或类别[6]。
1.1 决策树
决策树(Decision Tree)是分类模型的重要构造方法之一,它是基于机器学习的一种有向、无环图(Directed、Acyclic Graphics,DAG),由根节点、内部节点和叶子节点构成。决策树学习是从一组无次序、无规则的实例中推理并构造决策树表示形成的分类规则,采用自顶向下的递归方式,在决策树的内部节点进行属性值的比较并根据不同的属性值判断从该节点向下的分枝,在决策树的叶节点处得到结论。对于原始的训练元组数据集来说,属性选择度量是构造决策树最关键的问题,即依次采用哪些属性作为分类的标准,最终产生的决策树对于分类规则的产生最有利[7-9]。
设R是原始类标记的训练集,称之为原始的数据划分。假定某个类标号属性A具有m个不同的取值,即:A={a1,a2,…,am},则按照属性A可将数据划分R划分为m个不同的类,即:C={C1,C2,…,Cm},记Ci,R是R中第Ci类元组的集合,|Ci,R|和|R|分别是Ci,R和R中元组的个数。可得如下定义[8]:
(1)将R中的元组进行分类所需的期望信息(即R的熵(Entropy))定义为
(1)
其中pi=|Ci,R|/|R|,是R中任一元组属于Ci类的概率。
(2)按照属性A对R中的元组进行分类所需的期望信息定义为
(2)
(3)属性A对R的信息增益定义为
GainA(R)=Info(R)-InfoA(R) 。
(3)
(4)按照属性A对R中的元组进行分类的分类信息定义为
(4)
其信息增益率定义为
(5)
属性选择度量是一种选择分类的准则,决策树构造过程中的每一次分类采用哪个属性进行,其目的和判断的标准是将给定的训练元组数据集划分为“最好”(最纯)的子类,理想情况下,落在给定划分的所有元组都属于相同的类。但事实上这是不可能的,只能选择一种相对较纯的属性选择度量。对于以上2个指标,应该选择具有最高信息增益和最大信息增益率的属性作为当前分类的属性选择[6]。
1.2 ID3算法
由Quinlan于1986年提出并经过多次改版的ID3算法是决策树学习的典型算法之一,它以信息熵的下降速度作为选取测试属性的标准。ID3算法的决策树以自顶向下递归的分治方式构造,从训练元组集和它们相关联的类标号开始分类,随着树的构建,训练集递归地划分为较小的子集。算法用最高信息增益和最大信息增益率作为决策树中各级节点上属性选择的标准,在每一非叶节点上进行测试时,都能获得被测试例子最大的类别信息,使用该属性将例子集分成子集后,系统的熵值最小[10]。
ID3算法的完整描述[11]:
Input:原始类标记的训练集R;候选属性列表集attr_list;分类准则attr_sele_method
Output:决策树Decision_tree
procedure:
createNas a node
if ∀r{r∈R,r∈C} then (若R中的所有元组都归于一个类C,即R=C)
returnN∈Cas a leaf node (将N作为叶子节点返回,标记为类C)
end if
ifattr_list=φthen
returnN∈Mostas a leaf node (将N作为叶子节点返回,标记为多数类Most)
end if
split_attribute←attr_sele_method(R,attr_list) (调用attr_sele_method找到当前最好的分类属性度量值)
N∈Csplit_attribute(将N标记为类Csplit_attribute)
for eachRj∈Rdo(Rj是R按照split_attribute进行划分的第j个输出)
ifRj=φthen
addNjtoN(为N加一个叶子节点Nj)
else
Nj=generate_decision_tree(Rj,attr_list) (递归调用)
addNjtoN(为N加一个子树节点Nj)
end if
end for
2 分类规则ID3算法在大学生体质测试数据挖掘中的应用
“跑动石大”体质测试手机APP平台应用3年来已经积累了大量的大学生体质测试原始数据,本文分别选择西安石油大学三年级的男女大学生的体质测试成绩作为统计数据集R1和R2(限于篇幅,此处只给出部分抽样数据),见表1和表2。
本文对大学生体质测试原始成绩统计数据集R1和R2进行整理和清洗,并按测试标准对所有测试项目的成绩进行指标转换,导出得到对应的男女大学生体质测试统计类标记数据训练集R'1和R'2,见表3和表4。
这里以体质量指数(Body-Mass)为类标号属性,各取抽样记录50条,即属性ID值有50个,体重指标属性Weight-Index值有4个(营养不良、正常体重、超重、肥胖)、肺活量属性FVC、体前屈属性Sit-Reach、立定跳远属性Stand-Leap、50 m跑属性50 m、 1 000 m跑属性1 000 m(男)、 800 m跑属性800 m(女)、引体向上属性Pull-up(男)、仰卧起坐属性Sit-up以及类标号属性Body-Mass值各有4个(不及格、及格、良好、优秀)。从ID3算法的描述中可以看出,其核心思想是属性的选择度量,笔者采用ID3算法构造了决策树,对男女大学生体质测试数据进行分类分析,最终得出男女大学生体质测试的其它各种属性对其体质量指数属性结果的影响。
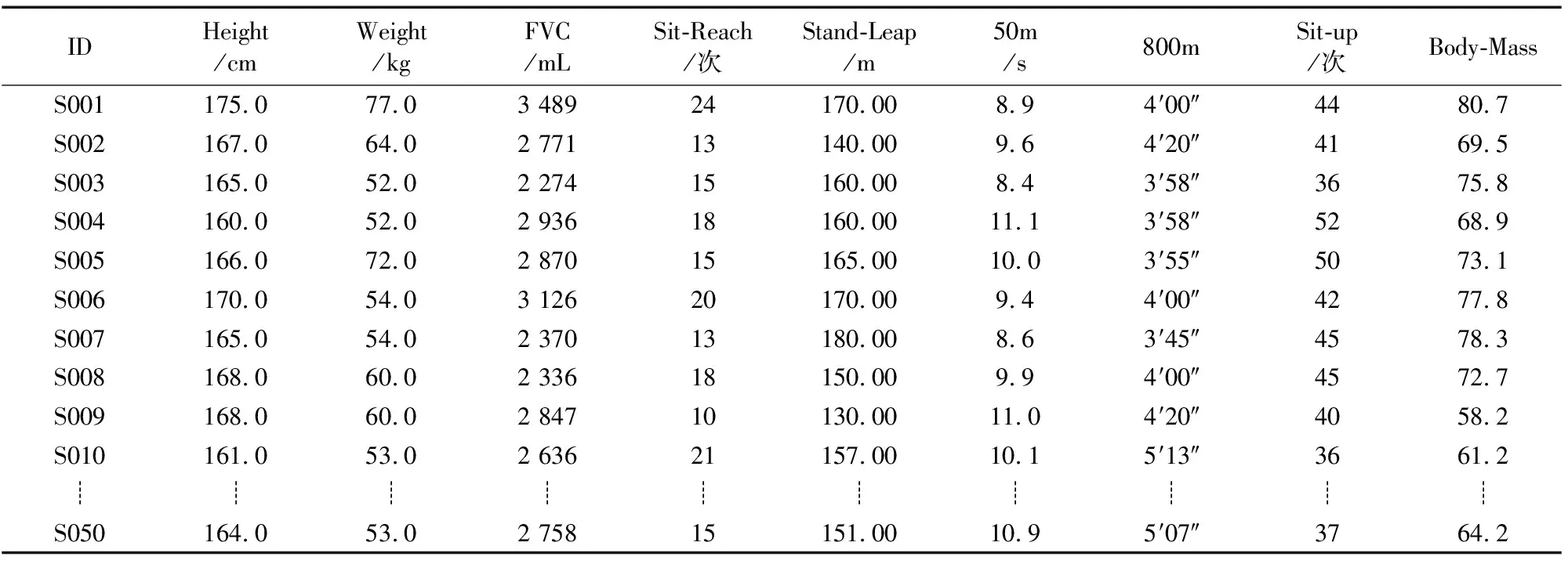
表1 大学生(女性)体质测试成绩统计数据集R1Tab.1 Statistical data set (R1) of university student (female) physical fitness test

表2 大学生(男性)体质测试成绩统计数据集R2Tab.2 Statistical data set (R2) of university student (male) physical fitness test
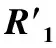
表3 大学生(女性)体质测试统计类标记数据训练集Tab.3 Statistical class tag data set (R'1) of university student (female) physical fitness test
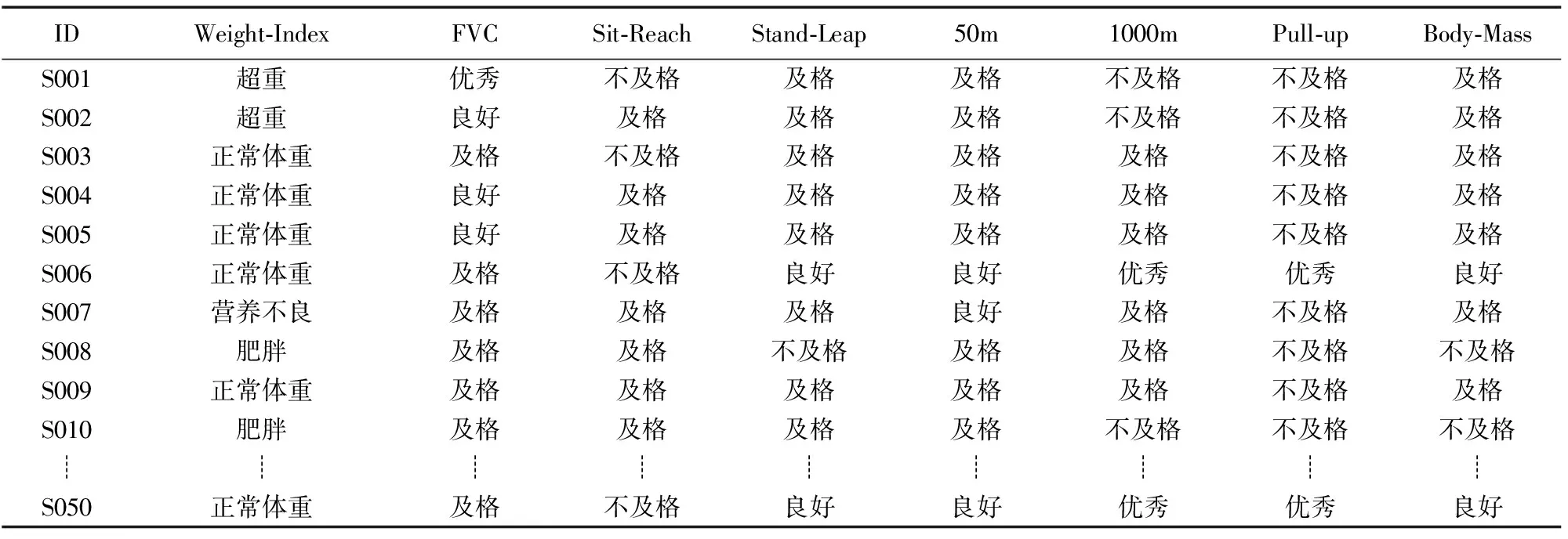
表4 大学生(男性)体质测试统计类标记数据训练集R'2Tab.4 Statistical class tag data set(R'2) of university student (male) physical fitness test
根据式(1)~式(5)对信息增益的定义,对于表3中的女大学生体质测试统计类标记数据训练集R'1,其计算过程和结果如下:


类似的,计算可得:


对比体重指标属性Weight-Index、肺活量属性FVC、体前屈属性Sit-Reach、立定跳远属性Stand-Leap、50 m跑属性50m、800 m跑属性800m、仰卧起坐属性Sit-up等7个属性的信息增益,选取具有最高信息增益的800 m跑属性800m作为决策树的根节点,利用同样的计算过程可以得到后续决策树结点,最终生成决策树,如图1。
对于图1的决策树,沿着根节点到每个叶节点的路径,分别提取分类规则如下:
Rule_1:IF 800m=不及格AND 50m =不及格AND Stand-Leap=不及格Then Body-Mass=不及格
……
Rule_m:IF 800m=及格AND 50m =不及格AND Stand-Leap=及格AND FVC=不及格AND Sit-up=良好AND Weight-Index=不及格Then Body-Mass=不及格
Rule_m+1:IF 800m=及格AND 50m =不及格AND Stand-Leap=及格AND FVC=不及格AND Sit-up=良好AND Weight-Index=及格AND Sit-Reach=不及格Then Body-Mass=不及格
Rule_m+2:IF 800m=及格AND 50m =不及格AND Stand-Leap=及格AND FVC=不及格AND Sit-up=良好AND Weight-Index=及格AND Sit-Reach=及格Then Body-Mass=不及格
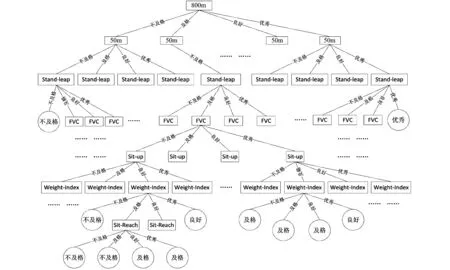
图1 大学生(女性)体质测试统计类标记数据决策树Fig.1 Statistical class tag decision tree of university student(female)physical fitness test
Rule_m+3:IF 800m=及格AND 50m =不及格AND Stand-Leap=及格AND FVC=不及格AND Sit-up=良好AND Weight-Index=及格AND Sit-Reach=良好Then Body-Mass=及格
Rule_m+4:IF 800m=及格AND 50m =不及格AND Stand-Leap=及格AND FVC=不及格AND Sit-up=良好AND Weight-Index=及格AND Sit-Reach=优秀Then Body-Mass=及格
……
Rule_s:IF 800m=及格AND 50m =不及格AND Stand-Leap=及格AND FVC=不及格AND Sit-up=良好AND Weight-Index=优秀 Then Body-Mass=良好
……
Rule_t:IF 800m=及格AND 50m =不及格AND Stand-Leap=及格AND FVC=优秀 AND Sit-up=及格AND Weight-Index=不及格 Then Body-Mass=及格
Rule_t+1:IF 800m=及格AND 50m =不及格AND Stand-Leap=及格AND FVC=优秀 AND Sit-up=及格AND Weight-Index=及格 Then Body-Mass=及格
Rule_t+2:IF 800m=及格AND 50m =不及格AND Stand-Leap=及格AND FVC=优秀 AND Sit-up=及格AND Weight-Index=良好 Then Body-Mass=及格
Rule_t+3:IF 800m=及格AND 50m =不及格AND Stand-Leap=及格AND FVC=优秀 AND Sit-up=及格AND Weight-Index=优秀 Then Body-Mass=良好
……
Rule_w:IF 800m=优秀 AND 50m =优秀 AND Stand-Leap=优秀 Then Body-Mass=优秀
对于表4中的男大学生体质测试统计类标记数据训练集R'2,依据同样的原理和算法计算可得体重指标属性Weight-Index、肺活量属性FVC、体前屈属性Sit-Reach、立定跳远属性Stand-Leap、50 m跑属性50m、1 000 m跑属性1 000m、引体向上属性Pull-up等7个属性的信息增益,并选取具有最高信息增益的引体向上属性Pull-up作为决策树的根节点,最终生成决策树。限于篇幅,在此不再赘述。
3 结 论
本文针对当代大学生体质健康水平持续下降的现状,结合高校体育“课内外一体化”教学模式改革对大学生体质测试模式和评价机制的具体要求,采用分类分析的典型算法——ID3算法,对“跑动石大”体质测试手机APP平台运行3年来积累的大量大学生体质测试原始数据进行分类分析,对于男女生各自生成决策树,并分别提取了分类规则。经过对比发现,这些分类规则和数据库中的实际数据高度一致,在学生个体调研中发现高度吻合。因此,利用这些分类规则的预测结论,能够快速科学地判定每个学生的个体体质,从而对不同体质的学生进行分类,有针对性地提出合理的运动训练建议,对学生的体质锻炼和学校的体育教学改革有参考价值和促进作用。
