LBlock轻量级密码算法的唯密文故障分析
2018-10-15吴益鑫谷大武廖林峰刘志强
李 玮 吴益鑫 谷大武 曹 珊 廖林峰 孙 莉 刘 亚 刘志强
1(东华大学计算机科学与技术学院 上海 201620)2(上海交通大学计算机科学与工程系 上海 200240)3(上海市可扩展计算与系统重点实验室(上海交通大学) 上海 200240)4(上海市信息安全综合管理技术研究重点实验室(上海交通大学) 上海 200240)5(上海理工大学计算机科学与工程系 上海 200093)
随着信息技术与计算机技术的不断发展,物联网正在逐渐深入到人们各个领域中.物联网将所有物品通过射频识别和红外感应器等信息传感设备与互联网连接起来,将人、数据与实体相联系,实现了人与物、物与物之间的信息交换与通信,以实现遍及智慧城市、智能家居、环境保护、智能交通和个人健康的智能化识别与管理[1-3].如图1所示.轻量级分组密码作为实现消息保密、数据完整性保护和实体认证的核心体制,其设计、分析与实现方法一直是密码学研究的主流,在物联网的安全领域发挥着重要的应用[4].

Fig. 1 The IoT scenario图1 物联网概况图
LBlock算法是一种Feistel结构的轻量级分组密码算法,具有优良的软硬件实现效率,以及在处理器应用上具有良好的实现性能[5-6],因而可应用于RFID标签和其他低资源设备以保护物联网的安全.前人针对LBlock算法的安全性分析主要致力于传统密码分析,包括不可能差分分析、相关密钥不可能差分分析、截断差分分析、零相关线性分析、积分分析、Biclique分析和侧信道立方分析等多种密码分析方法[7-9].然而,在物联网环境中,单纯从LBlock算法的算法结构研究安全性已经远远不够,攻击者不仅可以进行传统密码分析,而且可以通过电路剖析和软件逆向分析等方式获取密码算法的硬件结构和内部编码方法,借助异常时钟、异常电流、微波辐射、激光照射、涡流磁场等方式干预密码变换的正常过程使其出错,并有可能实现比传统密码分析更有效地破译,从而实现密码算法内数据的复制、篡改或伪造.人们通常把这种攻击称为“故障分析”[10-19].由于其成功的攻击效果和潜在的发展前景,已经引起了国内外从事密码学和微电子领域的研究学者的极大关注,并成为密码工程和密码分析领域发展最为迅速的方向之一.
故障分析在其自身的发展中,逐步衍生出多种攻击方法.1997年,由Biham和Shamir提出的差分故障分析是目前分析范围最广、威胁最大且发展最迅速的一种攻击技术,被广泛应用于密码算法的安全性分析中[20].后来,无效故障分析、碰撞故障分析、不可能故障分析、代数故障分析、中间相遇故障分析、线性故障分析以及唯密文故障攻击等应运而生.它们充分结合了传统密码分析技术以及软硬件实现,具备独特的分析优势,不仅扩大了攻击面,而且提升了威胁性,在面向现实的运行环境下具有更加灵活的应用前景.
在故障分析中,唯密文故障攻击是目前唯一只需要知道错误密文就能进行攻击的技术,在唯密文攻击(ciphertext-only attack, COA)假设下,攻击者通过导入故障得到错误密文,解密密文之后得到中间状态,分析得到的中间状态的特性,就能以低的时间复杂度和数据复杂度推导出正确的密钥.目前,国内外的主要研究是基于代换置换网络(substitution permutation network, SPN)结构的唯密文故障分析方法.那么,具有Feistel结构的典型密码算法是否能够抵抗唯密文故障分析,已引起国内外研究学者的广泛关注.由此,本文提出了一种针对LBlock算法的新型唯密文故障分析方法,在较短时间内以较少故障就能够恢复主密钥,为物联网的安全提供了保障.
1 相关工作
Boneh等学者于1997年利用随机故障成功破译RSA算法,此后故障分析在评测密码体制安全性的方法中占据了重要的位置[21].国内外研究学者自2012年起针对LBlock算法相继提出了故障分析方法.2012年,Zhao等学者首次使用差分故障攻击(differential fault analysis, DFA)对LBlock算法进行攻击,在随机单比特故障模型下,通过在加密算法第25~31轮导入7次故障,成功恢复倒数3轮的子密钥,进而恢复了主密钥[22].2013年,Jeong等学者对无线传感网络环境下的LBlock算法提出了改进的差分故障攻击方法,在随机半字节故障模型下,通过在算法的第30轮导入7次故障成功恢复了主密钥,同时在算法的第29轮导入5次故障也成功恢复主密钥,进一步减少了导入故障数[23].2018年,Wei等学者对LBlock算法提出了改进的差分故障攻击方法,在随机半字节故障模型下,通过在算法的第27~29轮导入13.3次故障,成功恢复主密钥,扩展了该方法的攻击轮数[24].2013年,Chen等学者针对LBlock算法提出了积分故障分析(integral fault attack, IFA),在随机半字节故障模型下,通过在算法的第24轮结束时导入120次故障成功恢复了主密钥,同时也提出了在半随机的半字节故障模型下,通过在加密的第23轮结束时在算法的右分支导入32次故障成功恢复了主密钥.该方法成功实现了对算法更深轮数进行攻击,且能够确定故障导入的具体位置[25].上述方法均属于选择明文攻击(chosen-plaintext attack, CPA),而本文针对LBlock提出的唯密文故障攻击(Ciphertext-only Fault Analysis,CFA)是唯一一种在只知道错误密文的情况下就能对算法进行攻击的方法.表1列出了现有的针对LBlock算法的故障分析方法的对比.
2013年,Fuhr等学者基于全零字节模型、半字节模型和随机字节模型,针对AES算法首次提出了唯密文故障攻击方法[26].该方法在算法运行时导入随机故障,使算法执行某些错误的操作,并产生错误的密文,解密密文得到中间状态,利用统计学的知识统计中间状态的分布律,从而恢复最后一轮子密钥.重复上述过程,即可恢复更多的子密钥,直至破译原始密钥.针对AES算法,在随机字节故障模型下,将故障导入在倒数第2轮的指定位置并用平方欧式距离SEI和极大似然估计MLE作为区分器,分别以320个故障和224个故障且99%的成功概率恢复出了AES算法的主密钥.2017年,Li等学者针对LED算法提出了新型的唯密文故障分析,除了Fuhr等人提出的SEI区分器之外,还提出了拟合优度检验GF作为新型区分器,又构建了GF-SEI双重区分器,以更少的故障数成功求得了LED的密钥,提高了故障攻击的效率[27].目前发表的唯密文故障分析都是针对SPN结构的加密算法.因而,Feistel结构密码算法的安全性是目前唯密文故障分析研究的热点.
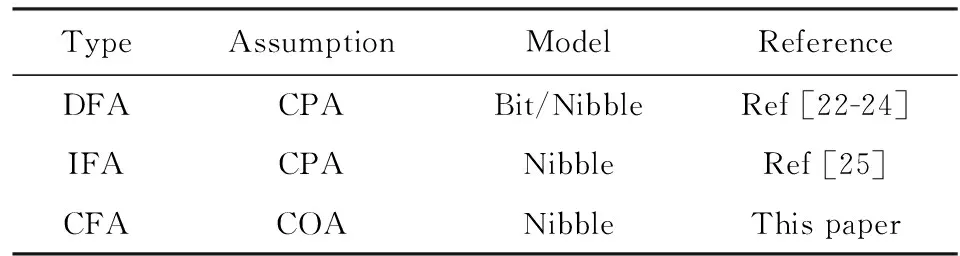
Table 1 Comparison of Fault Analysis on LBlock表1 针对LBlock算法的故障分析对比
本文首次提出了针对Feistel结构的LBlock算法的新型唯密文故障分析,并且以更深轮数对算法进行攻击,实现了故障导入在倒数第4轮,在原有SEI区分器、GF区分器、MLE区分器和GF-SEI双重区分器的基础上,提出了GF-MLE双重区分器和MLE-SEI双重区分器统计分析中间状态的分布律,以更少的故障数且99%的成功率恢复了LBlock算法80比特的密钥,提高了故障攻击的效率并减少了故障攻击数.表2为统计故障分析AES算法、LED算法和LBlock算法的唯密文攻击结果对比.其中,Byte和Nibble分别表示字节和半字节故障模型,r表示算法的总轮数.攻击结果总结如下:

Table 2 Comparison of Ciphertext-Only Fault Attacks on a Subkey of AES,LED and LBlock表2 LBlock,LED和AES算法唯密文故障分析部分子密钥结果对比
1) 唯密文攻击不仅适用于SPN结构的密码算法,对于Feistel结构的密码算法同样可以进行攻击.
2) GF-MLE双重区分器与MLE-SEI双重区分器减少了故障数,提高了攻击效率.
3) 使用这6种区分器进行攻击的轮数在倒数第4轮.
本文首先对唯密文故障攻击的研究现状进行了探讨,接着详细介绍了LBlock算法,然后给出了故障模型与假设,详述唯密文故障攻击过程,最后分析攻击的实验结果并对本文进行总结,附录给出了实验的全部数据.
2 LBlock算法
2.1 术语说明
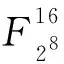
记F为轮算法,SL和DL分别表示S盒混淆层和P扩散层.SL-1和DL-1分别表示S盒混淆层的逆运算和P置换的逆运算.
2.2 LBlock密码算法
LBlock密码算法是一种具有Feistel结构的迭代型分组密码,分组长度为64 b,主密钥长度为80 b.迭代轮数为32轮.在加密算法中将消息明文分为32 b等长的左右2个分支.
该算法由3部分组成,分别为加密、解密和密钥编排方案.其中,解密过程是加密过程的逆.下面介绍算法的加密过程.算法结构如图2所示.

Fig. 2 The structure of LBlock图2 LBlock算法的结构
LBlock算法前31轮都是左右交换操作,最后一轮不包含左右分支交换操作,每一轮变换之后的状态表示为
Xi=F(Xi-1,eki-1)⊕(Xi-2<<<8),
其中,2≤i≤33.在F轮函数中,首先将左分支与轮密钥进行异或运算.其次将左分支的每半个字节经过8个S盒进行置换变成另外一个半字节.之后将经过S混淆层之后的状态按照特定的交换规则,变换到不同的位置.最后密文输出为C=X32‖X33.
2.3 密钥编排方案
密钥编排由3个步骤组成:
1) 选取80 b的主密钥K(ek79,ek78,…,ek0)的左侧32 b密钥(ek79ek78…ek47ek46)作为第1轮加密的轮密钥ek0.
2) 对80 b的主密钥进行循环左移29 b操作,将得到的80 b作为新的主密钥.
3) 部分密钥位更新,更新规则如下:
[ek79ek78ek77ek76]=s9[ek79ek78ek77ek76],
[ek75ek74ek73ek72]=s8[ek75ek74ek73ek72],
[ek50ek49ek48ek47ek46]=
[ek50ek49ek48ek47ek46]⊕[i]2,
其中,s8,s9均为4位S盒.
3 唯密文故障分析
3.1 故障模型和基本步骤
本文采用的唯密文故障分析的基本假设为:对随机明文采用同一个密钥进行加密,分析人员可以获得的是密码算法的任意错误密文.
LBlock算法中采用的S盒输入与输出均为4 b,因此本文采用随机半字节故障模型,诱发某一轮的存储单元发生4 b的随机错误.在本节中,导入故障轮数为倒数第4轮.
唯密文故障分析的基本步骤如下:
1) 选择随机明文并使用同一个密钥对其进行加密.当LBlock算法的加密过程运行到倒数第4轮时,导入随机故障,从而获得一组错误的密文.其中,故障导入既可以通过控制硬件实现中的异常时钟、异常电流、微波辐射、激光照射、涡流磁场等手段对真实的密码硬件实现来实现,也可以通过修改程序等软件模拟技术的方式来实现.
2) 解密错误密文得到中间状态.找到中间状态、子密钥和错误密文之间的关系,用关系式正确表达出来.
3) 利用构造的区分器统计中间状态值的分布律.从而恢复倒数3轮的子密钥中的部分位.因为在故障导入之后,加密过程中的某些中间状态值会呈现非均匀分布.
4) 重复上述过程,可以恢复倒数3轮的子密钥的全部位,最后结合密钥编排方案直至破译原始密钥.
3.2 具体过程
本文首次提出了用唯密文故障分析的方法对Feistel结构算法进行破译.针对LBlock算法,本文在前人提出的SEI区分器、MLE区分器、GF区分器和GF-SEI双重区分器的基础上又提出了2种新型区分器用于唯密文故障分析.具体过程如下:
1) 使用同一个密钥对随机明文进行加密,在运算过程中的某一轮中导入随机半字节故障,故障导入的位置在倒数第4轮的左分支上8个半字节中的任意半个字节,根据故障导入的位置不同,则扩散路径也各不同,从而根据不同的故障扩散路径求得子密钥的不同的比特值.如图3所示,故障可以导入在X29的任意半个字节,图中阴影表示受故障影响的半字节.图3表示故障导入在X29的第1个半字节后的故障扩散路径.

Fig. 3 Fault diffusion path in the fifth countdown round图3 故障导入在倒数第4轮后的扩散路径
2) 在运算过程中,中间状态X29的每个半字节都能用子密钥ek31的2个半字节、ek30的1个半字节、ek29的1个半字节和错误密文的4个半字节来表示:
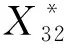
3) 通过区分器对中间状态进行分析,计算出ek29的1个半字节、ek30的1个半字节、ek31的2个半字节.对于每一个子密钥的候选值,根据导入的故障数都能求出一组中间状态值.选择一个区分器,以这组数据为样本,计算出每个密钥候选值所对应的区分器的值,经过比较,区分器值最大或最小所对应的候选值,即为正确子密钥.
4) 将上述过程重复4次,即可恢复出子密钥ek31的8个半字节、ek30的4个半字节、ek29的4个半字节.上述过程重复8次,即可恢复出子密钥ek29、ek30和ek31的全部位,之后可通过密钥编排方案求出主密钥.
3.3 区分器介绍
在3.2节的步骤3中所使用的区分器一共有6种,前4种是以前学者所提出的,后2种是本文所提出的新型区分器.
1) 平方欧氏距离(square euclidean imbalance, SEI)区分器
SEI区分器用于计算未知分布到均匀分布的距离,其中越不服从均匀分布的那一组样本值所对应的密钥候选值,即为所求的子密钥的部分位的解.表达式为
其中,M表示半个字节的所有可能值的个数,因此M=16.γ[m]表示实际得到的中间状态半字节值为m的样本个数;N为导入的故障数;每个密钥候选值都可以通过中间状态呈现的不同的分布律求出对应的SEI值.计算故障导入之后实际得到中间状态半字节值的分布与理论半字节值均匀分布的距离,即为当前样本的SEI值.当得到的SEI数值越大,表示这组样本越不服从均匀分布.因此,攻击者可以计算SEI的最大值来求出正确的候选值.
2) 拟合优度(goodness of fit, GF)区分器
GF区分器的使用条件为已知样本的分布律.攻击者通过比较得到的样本分布律是否满足所讨论模型下的理论分布律.若满足,则可求出子密钥的部分位.其中,4 b故障以按位与方式导入后,分布律如图4所示,并在GF区分器中使用该分布律.区分器表达式为
其中,M表示半个字节的所有可能值的个数;Om表示实际得到的值为m的样本个数;Hm表示在样本总数相同的情况下,值为m中的理论个数.通过区分器表达式可求出样本分布律是否满足理论分布律.其中,M=16,GF所求出的值越小越满足分布,即正确候选值.
3) GF-SEI双重区分器
GF-SEI双重区分器结合了GF区分器与SEI区分器的优点,先用拟合优度检验筛选出满足分布的样本.再用SEI区分器从中寻找最优样本,从而恢复一定的密钥比特.该方法进一步减少了故障数,提高了故障攻击的效率.
4) 极大似然估计(maximum likelihood estimate, MLE)区分器
MLE区分器作为唯密文故障分析的区分器之一适用于已知样本满足某种概率分布的情况下,攻击者计算得到样本出现的概率,当概率最大时,即为所求的子密钥:
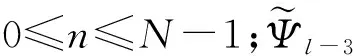
5) GF-MLE区分器
为了减少故障,本文将GF区分器与MLE区分器相结合,构建了一个GF-MLE双重区分器,先用拟合优度检验筛选出符合中间状态值分布的所有样本组.再用MLE区分器从中选出更优样本,即为正确子密钥:
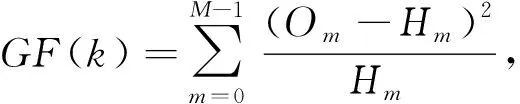


其中,k′表示GF区分器筛选之后的候选值,MLE(k′)表示每组样本对应的MLE值;RK表示正确的候选值.从中选取MLE区分器最大的值,就是正确的子密钥.
6) MLE-SEI区分器
为了更进一步减少故障数,本文构建了一个MLE-SEI双重区分器,将MLE区分器与SEI区分器结合,先用MLE区分器筛选出符合中间状态值分布的一部分样本,再用SEI区分器选出更优样本:
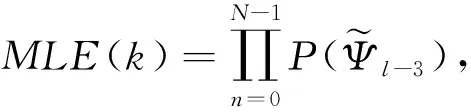
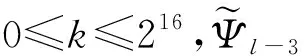
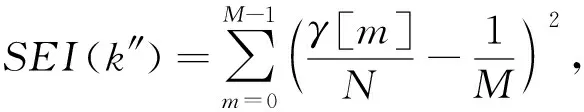
其中,m表示每个k″所对应的所有中间状态值,SEI(k″)表示部分样本分别对应的SEI值;从中选取SEI区分器最大的值,就是正确的子密钥.
4 实验分析
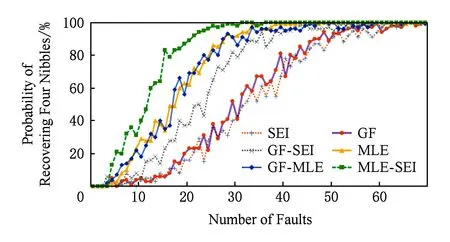
Fig. 5 The probability of recovering a partial subkey using different faults图5 不同故障数对应恢复出部分子密钥的概率
本实验在普通PC机器(CPU为Inter Core I7-7700K,4.2 GHz 内存16 GB)上使用Java语言编程进行算法的加解密实现和攻击操作,利用计算机软件来模拟故障的产生,从而得到错误密文,用编程实现从故障导入到唯密文攻击再到最后得到主密钥的全部过程.本文一共进行了1 000次实验,记录了恢复ek31,ek30和ek29部分比特的SEI区分器、GF区分器、MLE区分器、GF-SEI和GF-MLE双重区分器所需的故障数和耗费时间.图5表示不同区分器导入不同的故障数所恢复正确密钥部分位的成功概率.其中,横坐标轴表示导入的故障数,纵坐标轴表示恢复出正确子密钥的成功率.图5中有6种不同线段,分别表示使用SEI区分器、GF区分器、GF-SEI双重区分器、MLE区分器、GF-MLE双重区分器和MLE-SEI双重区分器进行唯密文攻击的结果.从实验结果可知,在半字节随机故障模型下,当以99%的概率恢复出过程3中的子密钥时,SEI区分器、GF区分器、GF-SEI双重区分器、MLE区分器、GF-MLE双重区分器和MLE-SEI双重区分器分别需要51,47,36,29,28和22个故障数.由此分析,本文所提出的2种新型区分器可以减少攻击时使用的故障数,并且使用MLE-SEI双重区分器时故障数减少明显.
图6表示分别使用SEI区分器、GF区分器、GF-SEI双重区分器、MLE区分器、GF-MLE双重区分器和MLE-SEI双重区分器破译密钥时间消耗图.其中纵坐标轴表示消耗时间,以秒为单位,横坐标表示导入故障数.从实验结果可知,在半字节的随机故障模型下,6个区分器以99%的成功率破译密钥所需时间分别为130.4 s,87.4 s,50.0 s,43.2 s,37.0 s和28.4 s.不同的区分器所需时间相差较大,其中消耗时间最多的GF区分器,消耗时间是MLE-SEI消耗时间的5倍多.从结果可知,本文中所提出的双重区分器并不会增加消耗的时间,反而减少了消耗时间.

Fig. 6 The time shown with stacked charts of using different faults图6 不同故障数对应消耗时间的堆积柱形图
由图5和图6可得,从各个区分器对算法的破译情况进一步分析,GF区分器的攻击效果比SEI区分器更佳,而GF-SEI双重区分器的攻击效果比GF和SEI区分器效果更佳,本文中所提出的2种新型区分器的攻击效果都比之前的4种区分器的攻击效果更佳.MLE-SEI双重区分器所需要的导入故障数和耗费的时间比前面5种区分器均明显减少.
5 结束语
本文提出并讨论了LBock密码算法抗唯密文故障攻击的安全性.研究结果表明:在面向半字节的故障模型中,与原有的4种区分器相比,本文所提出的2种新型区分器所需故障数更少,故障攻击效率更高;以LBlock为代表的Feistel结构的密码算法易受到统计故障分析的威胁,此方法有助于优化唯密文故障攻击方法的攻击性能,提高故障攻击的效率和实用性.在下一步工作中,我们将进一步深入分析双重区分器的效率以及注入故障的分布律.
