乌鲁木齐南山森林生物量和碳储量空间分布特征
2018-10-12常亚鹏许仲林
李 路,常亚鹏,许仲林
(1.新疆大学 资源与环境科学学院,乌鲁木齐 830046; 2.新疆大学 资源与环境科学学院绿洲生态教育部重点实验室,乌鲁木齐 830046)
近年来,作为主要的温室气体,大气CO2浓度的升高导致全球气候变化加快,进而引起陆地生态系统结构和功能发生改变,生态系统的可持续发展面临严峻挑战[1]。因此,如何采取有效措施减缓和适应急剧变暖的气候条件,成为各国科学家和决策者共同关注的焦点问题。就减缓气候变化的策略而言,森林生态系统也许能够发挥关键的作用,因为生态系统中森林植被的固碳量约占陆地植被总固碳量的82.5%[2]。因此,准确的估算森林生态系统的碳储量对于研究区域以及全球碳循环有重要的理论和实际意义[3-4]。
植被碳库是森林生态系统碳储量的重要组成部分[5]。植被碳库的碳储量可通过估算森林生物量来推算[6]。估算森林生物量的方法有生物量模型(包括相对生长关系法和生物量—蓄积量法)[7]、生物量估算参数法[8]、3S法[9]等。一些学者通过上述方法建立生物量模型估算了我国不同森林的生物量,但是目前对大区域尺度的研究较多[10],而对中等尺度定位研究相对较少,其相应的森林生物量和碳储量的获取方法也相对缺乏。
因此,本研究以乌鲁木齐南山雪岭云杉林为例,利用2015年野外实测样地的数据结合陆地卫星TM影像[11],采用逐步回归分析的方法构建最优云杉林生物量遥感估算模型,估算该区域雪岭云杉林的生物量,并探究雪岭云杉林碳储量的空间分布特征。
1 基础数据
1.1 研究区概况
本研究位于乌鲁木齐县南山,其经纬度范围为43°07′09″—43°27′42″N,87°04′30″—87°29′15″E,自南向北延伸60 km[12],总面积为120 km2,属于山区气候,年降水量的40%集中在6—8月份,平均降水量为456 mm。南山北坡是森林的主要分布区,其森林的分布范围是海拔1 500 m到2 800 m的中低山区,林区中生长的乔木树种有90%以上为雪岭云杉(Piceaschrenkiana)林。
1.2 数据采集与处理
采用样地数据为2015年4月至5月野外实测数据,共40个样地。野外采样工作中,选取海拔梯度连续的坡面,以50 m海拔高度为间隔,设置样地。每个样地选择一个中心,用激光测距仪测出半径8 m的样圆,用GPS定位每个样地中心点的海拔和经纬度,对样地的树木按顺序进行标记,统计株数,并记录树高和胸径。按照张绘芳等[13]构建的雪岭云杉器官生物量模型(表1)计算每株树木生物量,再按照样地面积求得样地总生物量。

表1 森林生物量模型[13]
2 遥感数据处理及地形与气候因子
2.1 遥感因子提取与处理
本研究采用的是NASA的Landsat TM数据,为保持影像信息和地面调查时间一致,本研究采用2015年4—5月的影像。野外样本采集区域覆盖2幅TM影像(行列号分别是142条带的30行和143条带的30行)。分别对两幅影像进行辐射定标和大气校正(FLAASH),将处理好的影像分别用乌鲁木齐县的矢量图进行裁剪并拼接。TM影像共分6个波段,投影方式为UTM/WGS84,空间分辨率为30 m。本研究中取其中的5个原始波段(TM2,TM3,TM4,TM5,TM7),在ArcGIS下提取波段值作为模型建立的输入变量。
2.2 植被指数的计算和因子的提取
植物体中的色素、水分和结构有着特殊的光谱响应,因此可以利用植物多光谱遥感信息来获取植物的相关信息[14]。植被指数作为植被特有光谱特征,是将可见光和近红外波段进行组合形成的能反映绿色植被生长状况和分布的特征指数[15]。与单波段值估算生物量相比,利用植被指数监测生物量的准确性更高。本研究运用ENVI的波段运算功能计算常用的植被指数(表2),并将植被指数和原始波段进行线性或非线性变换得到新的参数[16],依此对植被的生物量作进一步的分析。

表2 植被指数模型[15]
其中:B3为红光波段;B4为近红外波段;B5为红外波段;A和B为经验系数;A=0.969 16;B=0.084 726(参考MSS和TM的取值)[22]。
利用90 m栅格分辨率的SRTM-DEM数据,对样地的坡度和坡向数据进行提取,并从Worldclim数据[17]中提取样地的年均温度和年降水量数据,作为参与建模的地学和气候因子变量。通过GIS技术获取部分地学和气候因子参与生物量估算,可提高生物量估算的精度。
将波段值、植被指数值、地学和气候因子以及波段和植被指数的变换值共19个因子作为参与建立估算模型的变量。
2.3 生物量估算模型及误差评估
在SPSS 22.0中,以上述参数作为初始自变量,对初始自变量进行多重相关性分析,并计算各初始自变量与生物量之间的相关性,提取与生物量显著相关的自变量,采用逐步回归法建立森林生物量非线性估算模型。
由于预测模型对样本数据的拟合程度有限,实测值与估算值之间存在偏差[18-19],因此需要通过计算预测误差来衡量估算模型的精度。在所有样地中,随机选取27个样地作为建模样本,剩余13个作为检验样本。模型检验过程中,本研究采用绝对误差(式1)和相对误差(式2)评估模型的精度估算:
Δ=|x估算-x实测|
(1)
(2)
式中:Δ是为绝对误差;σ为相对误差。
2.4 雪岭云杉碳储量的估测
按照植物干重有机物中碳所占的比重将植物生物量转化为碳储量,树木的种类、年龄和种群结构以及转化率之间存在差异,但差异不大,因此,其转化率一般在0.45~0.5变化[20]。由于各种植被类型转化率的获取难度较大,因此国际上以0.5作为常用转化率[21]。本文采用0.5的转化率计算碳储量。
3 结果与分析
3.1 相关性分析与生物量模型建立
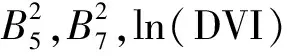
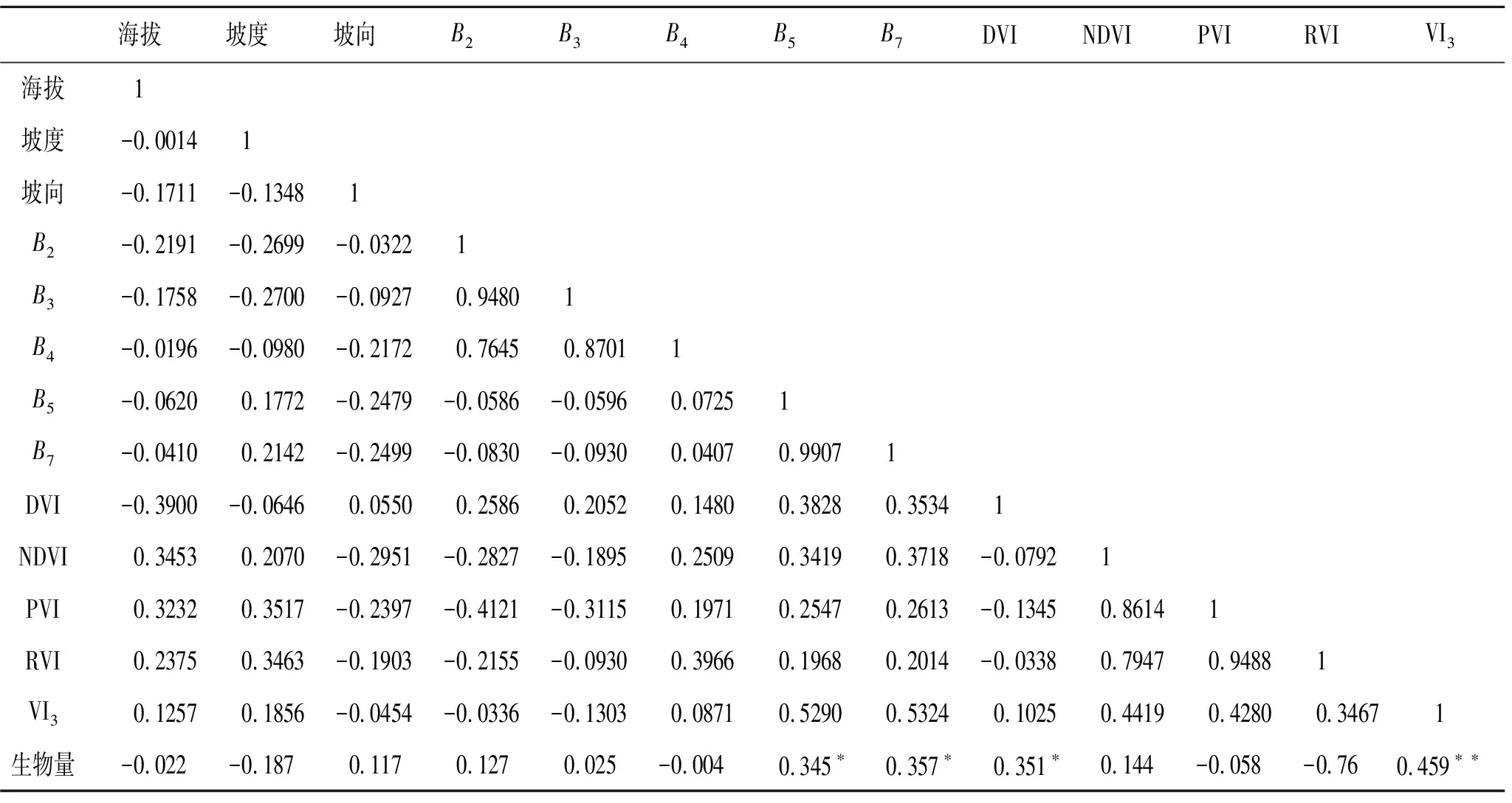
表3 自变量之间及与生物量的相关性
注:*,**分别表示0.05,0.01显著性水平。
表4所列的回归模型中,单波段自变量(B5和B7)建立的估算模型(1~4)相关系数R较低(R<0.4)。模型5和模型6是以中红外植被指数(VI3)和差值植被指数(DVI)为自变量建立的模型,相关系数R分别为0.544,0.672,高于单波段自变量建立的模型。模型7是以中红外植被指数(VI3)、差值植被指数(DVI)、T和P为自变量建立的模型,相关系数为0.694。模型8是以中红外植被指数(VI3)和差值植被指数(DVI)经过非线性变换后共同建立的非线性方程,相关系数为0.711。模型10是中红外植被指数(VI3)和差值植被指数(DVI)经过非线性变换后结合T和P共同建立的非线性方程,其相关系数最高(R=0.726)。从各预测模型中可以看出,自变量与森林生物量之间并非简单的线性关系,相比于线性模型,非线性模型对研究区森林生物量的拟合效果更好。引入年均温度和年降水量参数提高了模型的精度,说明年均温度和年降水量对生物量有一定的影响。模型10的R2最高(R2=0.528),并且F=6.14>F0.01=4.24,因此B=-263.290+36.367×ln(DVI)+63.653×ln(VI3)+3.191×T+0.393×P为最优生物量估算模型。

表4 生物量估算模型
为检验估算模型的精度,利用未参与模型构建的13个样地实测生物量数据对模型进行估算精度检验。由表5知,模型10平均估算精度为87.28%,基本符合生物量的估算要求,反演得到的估算值与实测值的差值范围是0.18~8.21 t/hm2,估算值的平均值为31.85 t/hm2,实测值的平均值为31.51 t/hm2,绝对误差为0.13 t/hm2,平均相对误差为12.72%,说明模型的精度较好,可以用来估算乌鲁木齐南山的森林生物量。

表5 实测值与估算值的误差及估算精度
3.2 生物量估算及空间分布
运用逐步回归分析方法得到的模型10,结合ArcGIS 10.1软件监督分类划分的森林模块,进行乌鲁木齐南山森林生物量的反演。通过计算得出乌鲁木齐南山森林生物总量为8.2×106t,最大值为219.67 t/hm,平均森林生物量为91.21 t/hm。由图1A知,乌鲁木齐南山森林生物量密度分布不平衡,西南地区大于东北地区,少数分布在乡镇边缘。生物量随着纬度的增加而减少,这是因为随着纬度的增加,夏季的平均气温增加而年均降水量减少,影响了树木的生长;由于乌鲁木齐南山森林经度的跨度较小,所以生物量在经度上没有明显的变化趋势。总体来说,生物量密度的分布呈现西南高、东北低的趋势。
3.3 碳储量估算及空间分布
根据碳储量的转换系数(0.5)以及森林生物量密度的空间分布计算森林碳储量的空间分布(图1B)。乌鲁木齐南山森林碳储量为4.1×106t,平均碳密度为45.61 t/hm。若将碳储量密度划分为低,中,高3个等级,则统计结果表明,低密度等级的碳储量占总量的0.32%,中密度等级的碳储量占总量的57.14%,高密度等级的碳储量占总量的42.54%,因此,乌鲁木齐南山森林碳储量主要集中在中高密度等级。
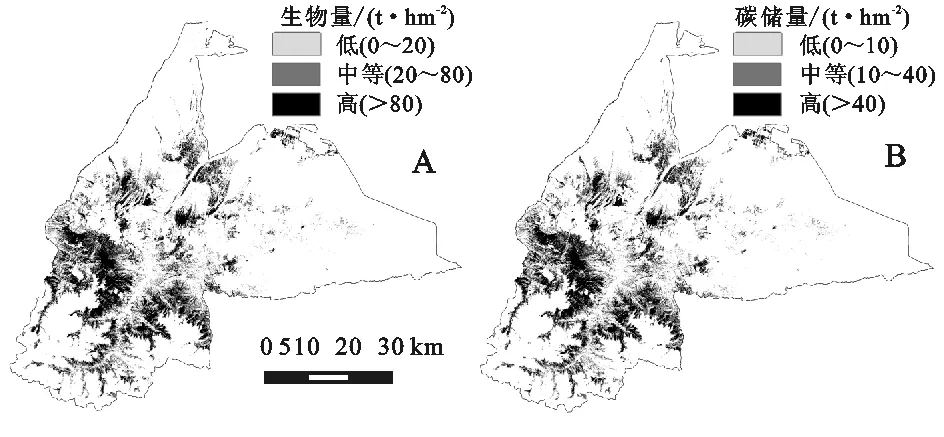
图1乌鲁木齐南山森林的空间分布
4 讨 论
4.1 森林遥感信息生物量估算模型
利用遥感估算模型来估算森林生物量是目前的研究热点之一。牛志春等人研究表明,基于遥感信息的非线性回归模型要优于线性回归模型[22]。Fan等研究表明森林生物量与植被遥感参数之间存在非线性关系[23],因此可以选择非线性方法来建立森林生物量模型。Wu等人认为利用多个遥感数据的相关波段可以提高生物量的估算精度[24],彭守璋等在祁连山青海云杉林生物量的研究中引入降水和温度等气候要素提高模型精度[25],因此,本研究利用5个原始波段(TM2,TM3,TM4,TM5,TM7)、年均温度和年降水量参与非线性生物量估算模型的建立,提高了估算的精度(平均估算精度为87.28%)。此外,基于自学习过程的神经网络方法,也能够显著的提高估算生物量的精度。例如,袁野等利用改进型B-P神经网络模型,分别对西雪岭云杉林的幼龄林、中龄林、近熟林、成熟林和过熟林进行生物量估算,其估算精度为91.97%[26],这表明神经网络相比于多元回归模型能够更加真实的反映实际的情况。需要提及的是,由于遥感影像分辨率、遥感影像获取时间、建模因子的选择、样地的数量和选取等都可能影响生物量的估算,因此选取何种模型进行估算,需考虑上述多种数据的可获取性和适用性[27]。
本研究所采用的野外调查的数目较少,因此用于构建估算模型和验证模型的样本有限,且样地分布不均匀,因此对模型精度造成了一定的影响。此外,地形纹理特征、土壤信息等因子也会影响森林生物量的估算[28]。在未来的研究中需要增加野外调查样地数量,并且研究区内的样点要均匀分布,进一步优化建模因子,加入土壤、纹理等因子[29],建立精度更高、实用性更强的生物量估算模型。由于森林生物量是时刻变动的,为了能够更加精确的估算生物量密度的空间分布,可考虑建立具有物理机制和生理学意义的生物量模型进行估算[30]。
4.2 乌鲁木齐南山森林碳储量/碳密度的空间分布特征
地形对森林碳密度有一定的影响[31],徐少君等研究表明森林碳储量密度随海拔的增高呈现明显的增长趋势[32],李海涛等人研究表明乔木层碳密度随着海拔的升高而增加,且样地的总碳密度也随着海拔的上升而增加[33]。本研究表明,森林碳密度主要集中在中密度等级,但是在不同海拔梯度上没有明显的变化规律(图2),说明碳密度还与不同海拔梯度上的温度、降水和土壤等有关。刘倩楠等研究表明碳储量(碳密度)随坡度和坡向的分布特征明显[34]。徐新良等研究表明我国森林植被碳储量和碳密度空间差异显著[35],因此在进一步的研究中,应考虑引入坡度、坡向等因素来探究云杉林碳储量和碳密度的空间变化特征。
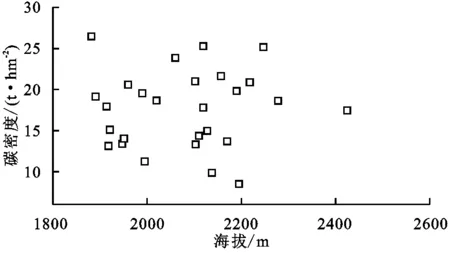
图2碳密度随海拔的变化关系
5 结 论
(1) 研究中选取与生物量相关性较高且关系显著的自变量,并结合年均温度和年降水量数据进行回归方程的拟合。得到的最优生物量估算模型为B=-263.290+36.367×ln(DVI)+63.653×ln(VI3)+3.191×T+0.393×P,相关系数为0.726。
(2) 本文建立的最优估算模型拟合效果较好,从模型的检验来看,估算精度为87.28%,具有较高的预估精度。适应于森林生物量的估算,能够较为真实的反映实际情况。
(3) 本研究表明,由于乌鲁木齐南山东北部区域人类活动较为频繁,因此,生物量密度的分布呈现西南高、东北低的趋势。将碳储量密度划分为低,中等,高3个等级,结果表明,乌鲁木齐南山森林碳储量主要集中在中高密度等级。
