不确定信息环境下多属性决策方法的研究进展
2018-10-10陈华友周礼刚刘金培陶志富
陈华友 ,周礼刚 ,刘金培 ,陶志富
(1.安徽大学 数学科学学院,安徽 合肥 230601;2.安徽大学 商学院,安徽 合肥 230601; 3.安徽大学 经济学院,安徽 合肥 230601)
针对社会、经济和工程系统中的一些实际问题,人们经常利用一些信息融合的方法把系统中的多源输入信息变成一个输出信息,再利用输出信息来进行适当的预测或决策分析.由于系统内部结构的复杂性和外部面临一个迅速变化的环境,传统的实数型信息很难刻画研究对象的基本特征,人们经常用区间数据、三角模糊信息、梯形模糊信息、直觉模糊信息和语言信息等多种不确定的信息形式来表征事物.因此不确定信息环境下的决策分析方法成为学术界研究的一个热点问题.
多准则决策(multi-criteria decision making,简称MCDM)依据决策方案个数是否有限可以划分为多属性决策(multi-attribute decision making,简称MADM)和多目标规划(multiple objective programming,简称MOP)两类.多属性决策问题是根据各方案的目标属性值,采用某种集成融合的方法,将若干个属性值转化为该方案的综合评价值,从而获得方案的排序结果,并给出最优方案.因此,本质上它是考虑具有多个属性的有限决策方案的排序问题,在投资、生产和服务等领域具有广阔的应用前景.论文对近年来发展起来的几种不确定信息及其信息集成的算子理论,不确定信息环境下多属性决策的赋权方法和决策技术,多种偏好关系一致性的概念、不一致性调整的算法、偏好关系的排序方法和共识性模型等问题进行了综述,并对未来的研究方向进行了总结和展望.
1 不确定环境下的信息融合理论
为了对不确定环境下的各种信息进行有效的融合,信息集成算子相关理论逐渐引起大家的关注[1].目前,提出新的集成算子并且讨论它们在各个领域的应用,已经成为国内外研究的热点[2-4].集成算子的研究起源于对算术平均、几何平均、调和平均等各类均值的探索,以及满足解决实际问题的需要.最初,人们对集成算子的研究主要考虑实际问题的需要,提出合适的集成算子来对实数值进行有效的融合.然而在实际中经常面临这样的困难,是由于人们对实际问题认识限制而造成的感知模糊性,且数据量过于庞大,变量之间关系错综复杂,具有很大的不确定性.在这种情况下,采用精确的实值就会造成信息丢失,或者偏离问题本身的实际.因此,人们经常用区间数据[5]、直觉模糊信息、语言信息等来表示这些不确定的因素.下面从实值信息融合出发,考虑到多种不确定信息形式,梳理在不确定信息环境下,集成算子理论在信息融合领域的发展现状.
1.1 实数信息集成理论
1988年,Yager[6]为了集成多个实数信息提出了有序加权平均(ordered weighted aggregation,简称OWA)算子的概念,该算子将第i个权重赋予第i大的变量.指出该算子介于“求极大”和“求极小”之间,具有单调性、幂等性、有界性和置换不变性等特点.
Fodor等[7]证明了任何的OWA算子都与Chquet积分是等价的,并在此基础上结合quasi算术平均定义了Quasi-OWA算子的概念.Torra[8]在OWA算子的基础上,提出了加权的OWA(weighted ordered weighting averaging , 简称 WOWA)算子的定义,指出WOWA算子结合了OWA算子和一般的加权平均的优点,并将WOWA算子推广到了语言变量的情况.Chiclana等[9]在OWA算子的基础上,结合几何平均算子的特点,定义了有序加权几何平均(ordered weighted geometric,简称OWG)算子.
Yager等[10]根据OWA算子的性质对其进行了相应的拓展,定义了诱导有序加权平均(induced ordered weighted averaging, 简称IOWA)算子.该算子根据诱导变量的大小对被集成信息进行排序,然后进行加权集成.陈华友等[11]在调和平均和OWA算子的基础上,进一步提出了有序加权调和平均(ordered weighted harmonic averaging , 简称OWHA)算子的概念.文献[12]在OWA算子的基础上结合广义平均的概念,提出了一类广义的OWA(generalized ordered weighted aggregation, 简称GOWA)算子[13].该算子在OWA算子的基础上增加了一个幂控制参数,并指出取最大算子、取最小算子、OWA、OWG和OWH(ordered weighted harmonic)等都是GOWA算子当参数取不同值的时候的特例.文献[14]在OWG算子的基础上提出了诱导有序加权几何平均(induced ordered weighted geometric averaging, 简称IOWGA)算子,并构建了基于IOWGA算子的组合预测新方法,指出该方法比传统的单项预测具有更高的有效性和预测精度.
Merigó等[15]在GOWA算子和IOWA算子的基础上,提出了诱导广义的有序加权平均算子.该算子包含了所有的IOWA算子、GOWA算子、IOWG算子和IOWQA(induced ordered weighted quadratic averaging)算子.Yager[16]提出了一种新的幂平均(power averaging, 简称PA)算子,该算子允许输入变量之间相互支撑.Yager[17]则考虑到被集成信息之间的交互影响,介绍了Bonferroni平均算子的相关工作.文献[18]提出了广义power集成算子,并探讨其在多属性决策中的应用.
进一步,为了对模块化信息进行集成,文献[19]提出了有序模块化平均(ordered modular averaging,简称OMA)算子的概念.Liu等[20]则将其进行拓展,提出了广义有序模块化平均(generalized ordered modular averaging,简称GOMA)算子的定义.GOMA算子由于控制参数的加入具有更好的适用性.
另外,基于不同的罚函数准则,文献[21]提出了广义有序加权对数集成算子的定义,文献[22]提出了广义有序加权比例平均算子,文献[23]提出了广义有序加权指数比例平均算子,文献[24]构建了广义有序加权对数比例平均算子的概念,文献[25]提出了广义有序加权多重平均算子的定义.此类基于不同罚函数的信息集成算子具有更清晰的集成目标和作用机理,兼具更好的灵活度,便于在模式识别、多属性决策等领域进行广泛的应用.
1.2 区间数据信息集成理论
对于区间信息的集成,徐泽水[26]将OWA算子推广到决策信息为区间数的不确定环境中,提出了不确定有序加权平均(uncertain ordered weighted averaging,简称 UOWA)算子的概念,并给出了相应的集结群决策信息方法.许叶军等[27]基于区间数两两比较的可能度公式,提出了不确定有序加权几何平均(ordered weighted geometric averaging, 简称OWGA)算子的概念,并提出了基于该算子的多属性决策方法.刘金培等[28]进一步在OWH算子的基础上,提出了不确定组合加权调和平均算子的概念.该算子适合对于成本型的指标进行集成,在此基础上论文给出该算子在属性权重未知,且属性值为区间数的多属性决策中的应用.
周礼刚等[29]将OWGA算子推广到了区间环境下,并且基于区间数两两比较的可能度,提出一种组合不确定型OWGA算子,并给出了一种基于组合不确定型OWGA 算子的不确定群决策方法.汪新凡等[30]针对多属性群决策中,属性值为正态分布随机变量,且数据信息来源为不同时期的情况,给出了正态分布数的运算法则,并且定义了正态分布数加权算术平均算子及其动态的情形.Merigó等[31]提出了不确定诱导quasi有序加权平均算子,该算子不仅适用于不确定区间数的环境,而且保持了UOWA算子、IOWA算子和quasi-OWA算子的主要特点.Zhou等[32]定义了不确定广义集成算子,探讨了算子的性质和多种不同表达形式.
为了对于连续区间中所有数据信息进行集成,Yager[33]对连续区间进行无限分割,然后利用OWA算子对其进行集成,得到了连续的OWA(continuous ordered weighted averaging,简称C-OWA)算子.为了集成两个或两个以上的连续区间数,文献[34]进一步将C-OWA算子进行改进,提出了加权的C-OWA算子、有序加权的C-OWA算子以及组合的C-OWA算子.Yager等[35]提出了连续的有序加权几何(continuous ordered weighted geometric averaging,简称C-OWG)算子.Wu等[36]在IOWA算子和C-OWG算子的基础上,提出了诱导连续有序加权集成算子.陈华友等[37]为了集成成本型的连续区间数据,在OWH的基础上,提出连续区间数有序加权调和平均(continuous ordered weighted harmonic averaging,简称C-OWH)算子,证明了算子的单调性和有界性等特点,且集成多个区间变量,将其推广到加权调和、有序加权以及组合的C-OWH算子,探讨了这些算子在不确定多属性群决策中的应用.
Zhou等[38]为了进一步提高连续区间数据信息集成的适用性和可行性,给出了连续的广义有序加权平均算子的定义,说明了C-OWA算子、C-OWG算子和C-OWH算子都是连续的广义有序加权平均算子的特例.文献[39]构造了基于惩罚的连续区间信息集成算子,并探讨了算子的几类特殊情形.Liu等[40]进一步提出了连续Quasi-OWA算子的定义,并将其拓展到对多个连续区间数据进行集成.
1.3 直觉模糊信息集成理论
Xu[41]在直觉模糊环境下,提出了直觉模糊加权几何平均算子、直觉模糊有序加权几何平均算子和直觉模糊混合几何平均算子,并给出了一种模糊环境下基于直觉模糊混合几何平均算子的多属性决策方法.文献 [42]的研究具有系统性:较系统地研究了直觉模糊信息的集成方式,定义了直觉模糊数的概念;基于得分函数和精确函数,给出了直觉模糊数的比较和排序方法;提出直觉模糊平均算子、直觉模糊加权平均算子、直觉模糊有序加权平均算子等一系列集成算子,详细研究了他们的优良性质,并说明了他们在多属性决策中的应用.为了集成区间直觉模糊数,文献 [43-44]定义了区间直觉模糊数的一些运算法则,并基于这些运算法则,给出区间直觉模糊数的加权算术和加权几何集成算子.
考虑到直觉模糊信息之间的交互影响,Xu[45]提出了直觉模糊Power集成算子.进而,Zhang[46]给出广义直觉模糊Power有序加权几何平均集成算子的定义,并证明该算子关于控制参数是严格单调的.Xia等[47]在Bonferroni平均算子的基础上,介绍了广义直觉模糊Bonferroni平均算子,证明该算子具有单调性、置换不变性和幂等性.Yu[48]受Heronian平均的启发,提出直觉模糊几何加权Heronian平均算子.考虑到被集成变量具有不同的优先级,Yu等[49]定义了基于优先度的直觉模糊集成算子.为了克服传统实值直觉模糊集成算子运算规则的缺陷,He等[50]考虑到直觉模糊数中隶属度和非隶属度的交叉影响,定义了直觉模糊几何交叉影响算子,并验证了该算子在多属性决策中的有效性.He等[51]提出了一种中性的直觉模糊信息集成的方法,并将其应用于多属性群决策.Zhou等[52]提出了连续区间值直觉模糊有序加权平均算子,来对区间直觉模糊信息集成集成,并探讨了算子的相关性质.Tao等[53]在Archimedean-Copula等的基础上,构造了多种直觉模糊Copula集成算子.该类算子具有较好的代数性质.
此外,文献[54]结合GOWA算子和余弦相似测度,提出了直觉模糊有序加权余弦相似测度,并探讨了该测度在直觉模糊信息融合过程中的优良性质.文献[55]进一步针对多属性群决策中的多种直觉模糊信息的集成问题进行了讨论,取得了良好的效果.
1.4 语言信息融合理论
目前对语言变量进行融合主要有以下几种方式.
一种是将语言变量进行转换,比较常见的是将语言标度转化为与之相对应的三角模糊数,根据模糊扩展原理进行模糊数的分析与运算[56].然而,此种方法在进行模糊数运算时,往往进一步增加了模糊性.
二是将语言变量直接进行运算,如文献[57]定义了语言加权析取算子、语言加权合取算子以及语言加权平均算子.在此基础上,文献 [58]提出语言OWA算子和语言加权OWA算子.另外,文献 [59]提出了语言加权几何平均算子、语言有序加权几何平均算子和语言混合几何平均算子等不确定语言有序加权平均算子.
为了避免在语言变量转换和计算过程中造成的信息丢失.Herrera 等[60]提出了将一般的语言变量转化为二元语义量化算子的方法,然后对二元语义量化算子进行计算分析,这样就可以有效地避免信息的损失.巩在武等[61]利用三角模糊数与二元语义之前的转化方法,研究了基于二元语义的语言判断矩阵与三角模糊互补判断矩阵之间的内在联系,同时给出了一种决策信息同时有语言判断矩阵、三角模糊互补判断矩阵形式的集结方法.Wei[62]在不确定语言加权几何平均算子和不确定语言有序加权几何平均算子的基础上,提出了不确定语言混合几何平均(uncertain linguistic hybrid geometric mean ,简称ULHGM)算子的概念,研究了ULHGM的相关性质.指出ULHGM算子不仅反映区间语言变量本身的重要性程度,而且可以反映区间语言变量所在位置的重要性.给出一种不确定语言环境下的多属性群决策方法.刘兮等[63]针对具有语言评价信息的多属性决策问题,提出了二元语义广义有序加权平均算子和二元语义诱导广义有序加权平均算子.刘金培等[64]考虑到语言变量间的交互影响,提出了二元语义Bonferroni平均算子等定义,进一步实现了语言变量的有效融合.
文献[65]定义了广义语言有序加权混合对数平均算子.文献[66-67]基于Archimedeant-norm和s-norm,分别定义了新的二元语义运算法则和区间语言信息的运算法则,可以克服原有语言运算不满足封闭性的缺点.文献[68]提出了区间二元语义Bonferroni平均算子的定义.文献[69]进一步对语言信息的熵测度进行了定义,并讨论了相关的优良性质.文献[70]则针对不平衡语言信息,提出了广义依赖型不平衡语言有序加权平均算子,该算子可以对不平衡语言信息进行有效的融合.
对不确定环境下信息集成算子理论的发展趋势分析可以看出,集成算子经历了一个由确定性到不确定性的发展过程,且集成算子的形式越来越灵活,随着一些控制参数和转换函数的加入,集成算子变得更具适用性、灵活性和包容性.如GOWA算子就是在OWA算子的基础上增加了一个幂控制参数,这样GOWA算子为人们提供了一类广义的集成算子,经典的OWA算子、OWG算子和OWH都变成它的一个特例,随着控制参数的变化,GOWA算子就变得更具灵活性.
当然,实际问题的需要是集成算子发展的主要推动力量.正是因为人们在科学研究和实践中遇到很多问题,需要对各种确定的、模糊的或者语言的变量进行集成,才促使集成算子理论得到越来越多专家学者的关注,因而集成算子理论得到了迅速的发展.
2 不确定信息环境下多属性决策方法
目前,多属性决策的研究内容主要包括属性(和专家)权重的确定以及方案的综合排序两个方面.下面将从这两个方面展开讨论.
2.1 多属性赋权方法
权重在多属性决策问题中用于衡量属性(和专家)在决策过程中的重要性程度,属性(和专家)越重要,则赋予其越大的权重,反之则越小.目前依据权重的获取方式不同,可以将赋权方法划分为主观赋权方法、客观赋权方法和组合赋权方法3类.
2.1.1 主观赋权法
主观赋权法的发展历史较久,但主观随意性较大.其确定的过程依赖于决策者的主观判断,容易给决策者造成额外的负担,导致其在应用上具有一定的局限性.常见的主观赋权法包括语言量值方法[6]、德尔菲法[71]和层次分析法[72](analytic hierarchy process ,简称AHP法)等.其中,AHP方法由于融合了决策者的主观态度,同时又可以进行定量化的分析过程.
2.1.2 客观赋权法
针对主观赋权方法的不足,依据不同属性下各方案对应的属性值的差异,人们提出不同类型的客观赋权法.客观赋权方法相对于主观赋权法具有较强的数学理论依据,其计算过程相对复杂,但是由于其仅从数据出发,容易忽略实际决策中决策者对于属性重要性程度的感知.常用的客观赋权法包括熵权法[55,69]、离差最大化方法[65]、主成分分析法[73]、博弈方法[74]和多目标规划法[67,75]等.客观赋权法以实际数据为基础,可以结合测度论、统计学、运筹学等基本理论构建基于一定赋权准则的数学模型,通过模型的求解来获得相应权重的结果.例如:熵权法和离差最大化原理的赋权准则均是从属性下的决策信息差异越小越不利于做出决策的角度进行考虑的;而多目标规划法也是依据某种偏差准则进行提前设定的.
2.1.3 组合赋权法
为了克服主观赋权法和客观赋权法的不足,组合赋权法认为多属性决策中属性的权重应为兼顾决策者主观评价和客观决策信息的综合度量.徐泽水等[76]利用一类线性目标规划方法实现主观和客观两类权重的结合;陈华友[77]应用离差最大化原理给出一种组合赋权方法;李刚等[78]基于级差最大化方法计算出不同单项赋权结果的组合.
组合赋权法能够兼顾决策者对于属性的重要性感知以及决策数据蕴含的数值规律,因而能够在利用主观和客观赋权优点的同时,还能够克服各自的不足.与前述信息融合原理相类似,组合赋权法本质上是对由不同主观和客观赋权获得的多个单项权重进行融合.
2.2 多属性决策方法
多属性决策方法的核心在于如何利用获得的决策信息实现对决策方案的综合排序.目前,依据决策信息类型、决策信息的完整性和信息融合的方法等决策的不同环节,国内外学者进行了广泛和深入的研究,取得了大量的研究成果.
2.2.1 考虑决策信息差异的多属性决策研究
随着不确定信息表达方式研究的不断扩展和深入,依托不同类型不确定信息的多属性决策也得以获得了广泛的研究.自模糊决策[79]提出以后,不同类型的不确定多属性决策相继被提出,如直觉模糊多属性决策[50,52,54]、语言多属性决策[80-85]、犹豫信息和犹豫语言多属性决策[86-87]、中智集多属性决策[88]、区间值信息多属性决策[68, 83]、Pythagorean模糊多属性决策[89-90]等.随着信息表达形式的逐渐复杂化,其用于表现现实生活也更为贴切,相应地,对不同不确定环境下的多属性决策方法进行拓展和研究成为当前研究的领域之一.
信息的表达形式是决策信息环境的表征,与前面几个模块的研究相对应,不确定信息环境下的多属性决策需要对决策信息进行融合继而进行综合排序.相关研究内容归纳如下.
(1) 不确定信息融合理论在多属性决策中的应用
信息融合方法为方案在不同属性下的属性值综合以及进一步的比较分析提供了基本的工具.不确定多属性决策研究中信息融合原理和方法的应用最为直接,信息集成算子方法[50,52,65,75]是具有代表性的一类,其中信息的运算法则[66-67, 91]与集成算子的表现形式和功能是两个主要研究内容.除此之外,包括贝叶斯方法[92]和证据推理[93]等在内的随机类数据融合算法和模糊逻辑[94]等人工智能类数据融合算法在不确定多属性决策中均有广泛的应用.
(2) 不确定信息测度理论在多属性决策中的应用
如前面所述,多属性决策问题中决策信息常见测度包括信息熵测度[69](包括交叉熵)、距离测度[80, 87]和相似性测度[54, 87]等.这些信息测度不仅能够表征决策信息所蕴含的信息量的大小或者不同属性(决策者)下决策信息的差异性大小,还能进一步用于实现对方案的综合排序.例如:TOPSIS(technique for order preference by similarity to an ideal solution)法[95]通过衡量方案决策信息与正负理想点之间的距离大小综合成贴近度指标,进而通过比较贴近度大小实现方案排序;ELECTRE(ELimination Et Choix Traduisant la REalité)法[96]利用距离测度构造了一类多属性决策方法,信息熵或者交叉熵测度[69]通过衡量属性下决策信息的差异大小获取属性的权重;与距离测度相类似,相似性测度[87]也可以通过比较各方案的决策信息与正负理想点之间的相似性给出一类综合评价指标.由于3类测度之间在一定程度上可以相互转化,因而,它们在多属性决策过程中的应用也具有一定的共性.
(3) 不确定信息排序方法
相对于精确数而言,不确定信息的大小比较也是不确定多属性决策问题中的重要研究内容之一.比较可能度[97]是不确定信息比较的主要工具,之后不同类型的比较方法相继得以提出:文献[98]归纳了区间数排序的相关研究并提出了一类直觉模糊形式的区间数排序可能度;文献[99]和文献[100]分别给出一类比较犹豫模糊语言术语集和2型模糊集的比较可能度的概念,并将其应用到相应的多属性决策问题中.
2.2.2 考虑基于决策技术的多属性决策研究
事实上,决策方法无疑都是从不同的视角利用决策信息.因而,这里所谓的决策技术更多地侧重于多属性决策流程设计和不同学科与多属性决策的交叉研究等.
首先,Lahdelma等[101]通过引入权重空间的方法给出一类随机多准则可接受性分析方法,其后续与其他决策方法的结合也均得到了具有显著影响的结果[102].
其次,多维偏好分析的线性规划方法[103]通过决策者对方案的成对比较去估计权的值和理想解的位置,给出一类与TOPSIS相区别的另一类多属性决策方法,并且在不确定多属性决策中获得了推广[104].
再次,为了反映实际多属性决策过程中,不同决策者可能考虑的属性集的不同,如文献[55]给出一类广义的多属性群决策模型,以期能够从决策问题本身更贴近实际的决策过程.由此可以看出,上述成果均是在决策流程或结构上对不确定多属性决策给出的有益尝试.
3 不确定环境下偏好关系的理论研究
3.1 偏好关系一致性的概念研究
表1给出了不同偏好关系的一致性定义、测度和相应的文献来源.
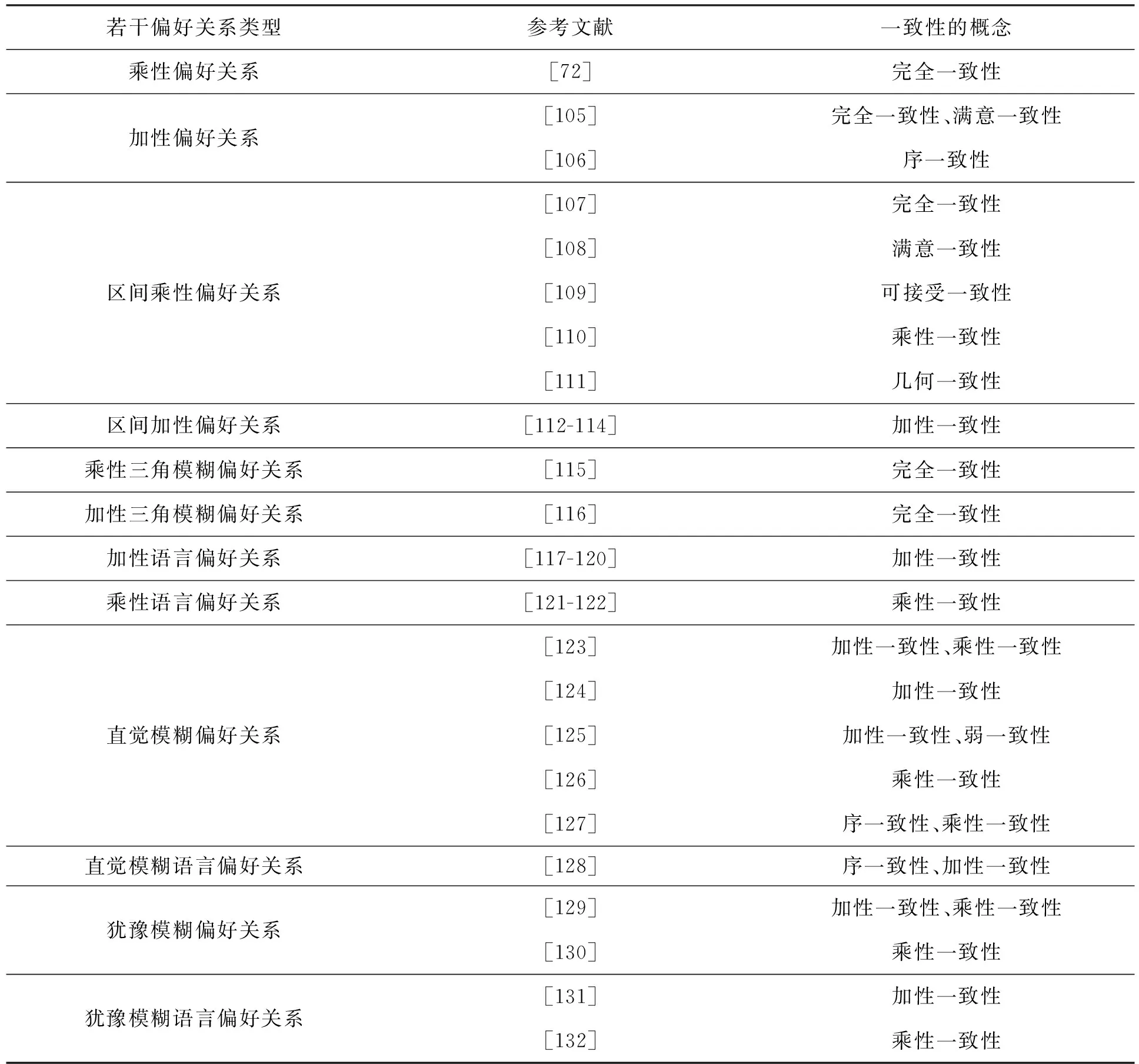
表1 不同偏好关系的一致性
一致性反映了决策者对准则或方案的判断结果是否具有序传递性,因此它是用来对方案进行排序的基本保证和前提条件.只有具有满意一致性或可接受一致性的偏好关系才可以用来对方案进行排序.目前关于偏好关系一致性方面的研究主要包括乘性一致性和加性一致性两种形式.而一致性的定义方法主要有两个角度:一个是从偏好关系的元素满足传递性关系式的角度出发来定义的,另一个是从偏好关系对应的排序权重的角度来定义的.
上述研究表明,一些复杂信息环境下的偏好关系一致性研究较少,包括区间直觉模糊偏好关系、区间犹豫模糊偏好关系、区间犹豫模糊语言偏好关系、二型模糊偏好关系、中智模糊偏好关系等偏好关系的一致性定义和测度.另外,对于常见偏好关系的残缺信息形式,其一致性测度研究也非常少.
3.2 偏好关系不一致性的调整算法研究
对于不满足一致性的偏好关系,一般需要对其进行调整,将其调整为具有满意一致性或者可接受一致性.而对偏好关系进行一致性调整时,需要构建一个满足一致性的目标偏好关系,根据该目标偏好关系与被调整的偏好关系之间的偏差测度或者相关性测度大小对被调整偏好关系进行调整,因此目标偏好关系的构造成为偏好关系一致性调整的关键.目前关于目标偏好关系的构建方法主要有两类:一类是根据待调整的偏好关系自身特点利用其元素来构造一个一致性目标偏好关系;另一类是通过待调整偏好关系的排序权重来构造一个一致性目标偏好关系.
对于第一类方法,很多专家学者针对不同的偏好关系进行了大量研究:文献[133]通过构造加性偏好关系的邻接矩阵定义了目标偏好关系并给出了一致性调整算法;文献[134]通过定义偏好关系的Hadamard乘积提出了普通的乘性偏好关系的目标偏好关系给出了乘性偏好关系一致性改进算法;文献[135]基于优化模型求解一致性乘性偏好关系和加性偏好关系;文献[136]基于对数偏差距离提出了一种衡量区间乘性偏好的一致性测度并给出了一致性调整算法;文献[137]通过区间加性偏好关系本身研究了最优一致性矩阵和最差一致性矩阵,进而给出了一种一致性改进算法来调整区间加性偏好关系;文献[138]利用诱导连续区间有序加权平均算子提出了区间加性偏好关系的一致度概念,并用来衡量区间加性偏好关系的一致性;文献[139]通过乘性三角模糊偏好关系元素的3个参数定义了3个目标偏好关系,并给出了乘性三角模糊偏好关系一致性的调整算法;文献[140]基于梯形模糊偏好关系乘性一致性的概念构造了具有乘性一致性的梯形模糊偏好关系,并以该偏好关系为目标设计了乘性梯形模糊偏好关系一致性调整算法;文献[141]通过C-OWG平均算子,模糊集的截集和乘性一致性定义了乘性梯形模糊偏好关系的一致性,并给出了一致性改进算法;文献[142]基于梯形模糊偏好关系加性一致性的概念构造了具有加性一致性的梯形模糊偏好关系,并以该偏好关系为目标设计了加性梯形模糊偏好关系一致性调整算法;文献[143]设计了一个算法提出一致性直觉模糊偏好关系作为目标偏好关系再对直觉模糊偏好关系进行改进;文献[144]提出了一个规划模型,通过求解规划模型构建了一个一致性目标直觉模糊偏好关系然后再对原始偏好关系进行调整;文献[145]通过转换函数构造出一致性的直觉模糊目标偏好关系再设计偏好关系一致性调整算法.基于直觉模糊偏好关系乘性一致性的概念:文献[127]构造了具有乘性一致性的直觉模糊偏好关系,然后设计直觉模糊偏好关系一致性调整算法;文献[128]通过构造具有加性一致性的直觉模糊语言偏好关系,构造了直觉模糊语言偏好关系一致性的调整算法;文献[117]考虑决策者本身按照语言偏好关系中元素的不一致性信息重新定义语言偏好关系,然后设计待调整的语言偏好关系一致性改进算法;文献[120]和文献[122]根据语言偏好关系一致性的概念,构造了具有一致性的语言偏好关系,并以该偏好关系为调整目标设计了偏好关系一致性改进算法;文献[146]通过一个混合0-1规划提出了一致性的不平衡语言偏好关系,然后再设计一致性调整算法;文献[131]通过一个正态犹豫模糊语言偏好关系来讨论目标偏好关系,然后设计偏好关系的调整算法.
对于第二类方法,文献[147-148]利用乘性偏好关系的排序权重定义一致性目标偏好关系矩阵然后构造了一个偏好关系调整算法;文献[149-150]利用加性偏好关系的排序权重建立了一致性加性偏好关系再设计偏好关系改进算法;文献[151]利用区间加性偏好关系的排序权重提出了一个非线性规划来改进原始的偏好关系;文献[152]利用群决策共识性测度和贝叶斯分析方法来对单个的乘性偏好关系进行调整.
上述研究表明,基于现有的各种偏好关系一致性测度构建方法,至少有两个方面的问题有待深入研究:一方面是针对新型模糊偏好关系的一致性调整,包括区间直觉模糊偏好关系、犹豫模糊偏好关系、区间犹豫模糊偏好关系、二型模糊偏好关、中智偏好关系等多种模糊偏好关系的一致性调整;另一方面是针对各种偏好关系利用排序权重来构建一致性调整算法,这一方面的研究目前相对较少.
3.3 偏好关系的排序方法研究
对于不同偏好关系的排序权重的求解,均是基于偏好关系的一致性,从偏好信息与排序权重的关系出发,构建不同的优化模型,通过求解优化模型来求解排序权重.经典的方法有特征向量法、最小偏差法、对数最小偏差法、卡方法等.文献[72]给出了乘性偏好关系排序的特征向量法;文献[153]根据乘性偏好关系和加性偏好关系之间的转换公式,从最优化角度提出了加性偏好关系的最小平方法和特征向量法;文献[154-55]分别从乘性偏好关系和加性偏好关系的关系角度出发研究了求解偏好关系排序向量的卡方法和目标规划法;文献[156]基于特征向量法和行几何平均方法,考虑到决策者不同的风险态度,讨论了两种求解区间乘性偏好关系的区间权重向量的方法;文献[157]通过分析区间加性偏好关系与区间乘性偏好关系之间的关系,给出了一种求解一致性或非一致性区间加性偏好关系排序权重算法;文献[158]基于相对熵的概念,构建了一种最优化模型用以求解区间加性偏好关系的排序向量;文献[159-160]分别构建了两个目标规划模型求解区间乘性偏好关系的区间排序权重;文献[161]基于加性三角模糊偏好关系可能度概念提出了一种排序向量求解方法;文献[74]基于三角模糊偏好关系与其排序向量之间的关系,构建了非线性优化模型用以求解三角模糊偏好关系的排序向量;文献[162]利用C-OWA算子梯形模糊数的期望值函数将加性梯形模糊偏好关系转化为期望值加性偏好关系然后求解排序权重;文献[163]构造了一种最小偏差模型用以求解加性梯形模糊偏好关系的排序向量;文献[140]构造了一种对数最小二乘模型用以求解乘性梯形模糊偏好关系的排序向量;文献[164]讨论了一种基于误差分析的直觉模糊偏好关系排序算法;文献[126]引入了一种生成直觉模糊偏好关系排序权重的分式规划法;文献[125]提出了一种线性规划模型求解直觉模糊偏好关系的直觉模糊排序权重;文献[165]基于区间直觉模糊偏好关系一致性的概念,提出了一种对数最小优化模型用以求解区间直觉模糊偏好关系的排序向量;文献[166]研究了改进仁慈型语言偏好关系交叉效率DEA模型,并提出了该模型的区间加性语言偏好关系的排序方法;文献[167]基于乘性偏好关系与加性偏好关系之间的转换关系,针对不完全乘性偏好关系,研究了基于迭代算法的最小偏差方法用以求解排序向量;文献[168]构建了不完全犹豫模糊偏好关系的目标规划模型求解排序向量.
文献研究表明,偏好关系排序权重主要集中于乘性偏好关系、加性偏好关系、区间偏好关系、三角模糊偏好关系、梯形模糊偏好关系、直觉模糊偏好关系、区间直觉模糊偏好关系等偏好关系,构建的模型也大多是常规优化模型,而对于比较复杂的语言型偏好关系、犹豫模糊偏好关系、犹豫模糊语言偏好关系等偏好关系的排序研究则较少.
3.4 偏好关系共识性模型研究
偏好关系共识性模型研究是解决群体决策问题的重点之一,主要包括共识性测度的构建和依据共识性测度对偏好关系进行共识性调整,所以其关键是共识性测度的定义方法.目前关于偏好关系共识性测度的定义方法主要表现为两种方式:一种是直接定义单个偏好关系与群体偏好关系的偏差测度或者相似性测度,并将其作为共识性测度,其中群体偏好关系是单个偏好关系依据一定的集结准则或者信息集成算子的综合集成方式;另一种是定义群体决策中某单个偏好关系和另一单个偏好关系之间的偏差测度或者相关性测度,再依据一定的集结准则或者信息集成算子进行综合构建综合共识性测度.针对不同的共识性测度,许多学者提出了大量的共识性调整算法,表2说明了不同偏好关系的共识性测度构成方式、偏好关系调整方式和相应的参考文献,其中CRI1表示给出的共识性测度是按照第一种方式来定义,CRI2表示给出的共识性测度是按照第二种方式定义.
文献研究表明,共识性模型主要集中于传统的乘性偏好关系、加性偏好关系、区间偏好关系、梯形模糊偏好关系、语言偏好关系、区间语言偏好关系等偏好关系,新型的二元语义偏好关系、多粒度非平衡二元语义偏好关系、直觉模糊偏好关系、犹豫模糊语言偏好关系等较为复杂的偏好关系研究仍然较为少见.另外,很多共识性模型只讨论了共识性测度的构建以及相关性质,对于不满足共识性的偏好关系未给出相应的调整算法.
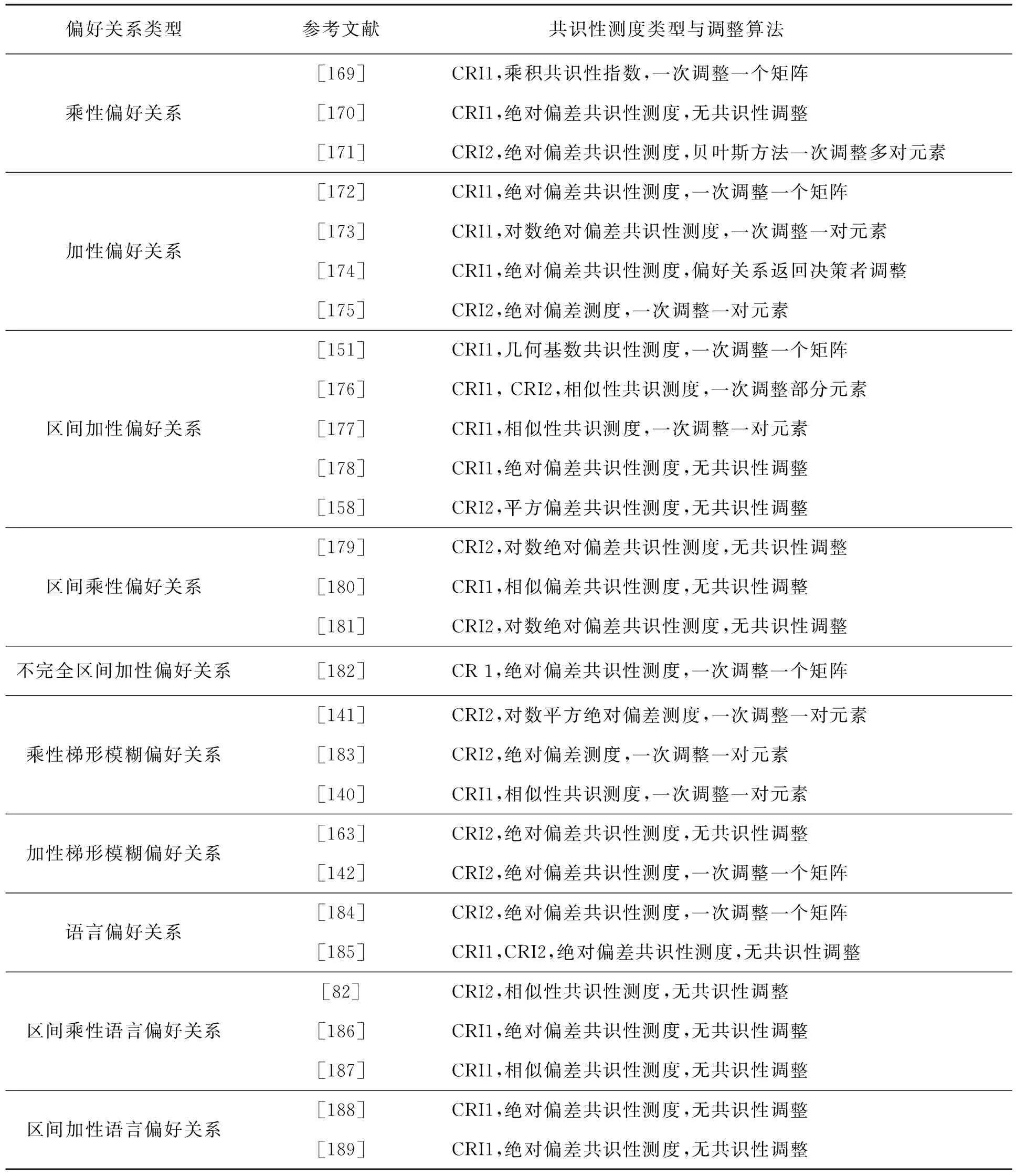
表2 基于不同偏好关系的共识性测度与调整算法
4 结束语
通过不确定信息环境下多属性决策研究的成果的梳理,未来至少可以在以下几个方面进行更多的有益探索:
(1) 探讨多属性决策问题中属性或专家权重确定的更加科学和合理的方法.随着人们对于实际经济和管理决策问题理解的不断深入,以及大数据科学技术的不断进步,有望将新兴的学科发展的新方法拓展到多属性决策问题中,给出更加符合客观规律的赋权方法.
(2) 考虑基于序关系的多属性决策方法.仅仅依赖方案之间的序关系构造相应的多属性决策问题在现实生活中是常见的,但现有的研究有待进一步深入探索,未来尚需进一步研究现有多属性决策信息中所蕴含的代数结构.
(3) 探索多学科交叉在多属性决策方法中的应用.现有的物元分析、集对分析和云计算等技术均在多属性决策分析中得到了应用,图论和博弈理论在多属性决策分析中应用也已见诸报端.将不同学科的背景与方法融入多属性决策分析中,以丰富该领域的理论和实践基础无疑可以进一步深入研究.
(4) 构建新的偏好关系一致性测度.将从偏好关系的乘性一致性和加性一致性两个方面定义复杂不确定环境下的偏好关系一致性,尚需研究新的一致性测度,包括区间直觉模糊偏好关系、区间犹豫模糊偏好关系、区间犹豫模糊语言偏好关系、二型模糊偏好关系、中智模糊偏好关系等偏好关系的一致性测度.另外,还将研究各种残缺偏好关系的一致性测度及其性质.
(5) 探讨偏好关系不一致性的调整算法.基于提出的新型的复杂模糊偏好关系一致性测度,从偏好信息自身和偏好关系排序权重两个角度出发,针对不一致的偏好关系,构建偏好关系一致性调整算法,重点要探讨算法的收敛性和复杂度.
(6) 探讨非常规的复杂偏好关系排序权重的简洁方法.一方面,将针对非常规的复杂偏好关系,已经有文献构建常规优化模型或者集成准则来确定偏好关系排序权重;但是该方法模型和求解均较复杂,因此将针对各类复杂偏好关系,尚需研究简洁有效的权重排序方法.
(7) 构建偏好关系共识性的新测度和调整算法.将以测度论为基础,构建新型的复杂偏好关系的共识性测度,探讨其性质,分析群体共识和个体共识的关系,并针对未达成共识的偏好关系需要进行共识性调整,设计共识性调整算法,研究算法的收敛性和复杂度.
(8) 探索广义集成算子的参数选取的基本原则和适用范围.虽然现有文献提出新的更加广义和灵活的集成算子成为发展的趋势,但是随着新算子的提出,也带来一些附加的问题需要人们去进行深入研究.如新算子的相关参数该如何取值,相关联的导出函数如何定义,不确定信息的排序和比较,基本运算法则的合理性定义,以及算子的赋权方法等都有待人们进一步探索和分析.
猜你喜欢
杂志排行

安徽大学学报(自然科学版)的其它文章
- 多细胞生物自噬的分子机制和生理功能
- 一类时滞不确定系统的有限时间 非脆弱L2-L∞滤波器设计
- Linear (optimal) complexity direct full-wave solution of full-package problems involving over 10 million unknowns on a single CPU core
- The effect of Unruh effect for quantum-memory-assisted entropic uncertainty relation
- Moser-Trudinger不等式及其极值函数的存在性
- 肾脏纤维化的细胞和分子机制研究进展