基于Hadoop平台的大数据图像分类机制
2018-10-09张睿萍马宗梅
张睿萍, 马宗梅
(中原工学院 计算机系, 郑州 450007)
在图像自动组织管理系统中, 图像分类是一项关键技术[1-3]. 图像分类的基本思想: 先用计算机根据图像内容对图像信息进行理解, 然后将图像分为不同的类别, 帮助用户更快地找到所需的图像[4-5]. 图像分类主要分为两种类型: 基于场景识别的图像分类和基于目标识别的图像分类. 基于场景识别的图像分类方法根据图像语义内容将图像划分为多个类别; 基于目标识别的图像分类方法是对一幅图像中的不同目标进行识别, 包括前景和背景区, 前景即为目标. 目前图像分类主要针对于场景识别, 因此本文主要考虑基于场景识别的图像分类方法[6-7]. 最初的图像分类主要依赖文本特征, 即图像分类的关键字, 然后采用人工方式根据关键字对图像进行标注和识别, 由于每个人对图像的理解不同, 因此对同一对象, 不同人得到图像的分类结果差别较大, 并且随着图像规模越来越大, 人工标注方式工作量大, 图像的分类效率低, 已经不能满足图像处理的要求[8]. 基于内容的图像分类方法不需进行人工标注, 克服了人工标注图像分类方法的主观和盲目性, 直接根据图像信息进行图像分类, 该图像信息主要指图像的特征, 如颜色、 形状、 灰度特征、 仿射特征等, 通过这些特征对图像内容进行描述, 并根据图像特征和图像类别之间的关联, 采用机器学习算法建立图像分类器[9-10]. 传统基于内容的图像分类方法主要采用全局特征和机器学习算法进行图像分类, 如小波变换提取图像空间域特征, 将其作为神经网络的输入向量, 建立图像的分类器, 由于全局特征对光照变化、 遮挡等敏感, 鲁棒性差, 因此对一些复杂的图像, 难以得到理想的图像分类结果[11-12]. 全局特征还存在特征维数高的缺陷, 易出现“过拟合”的图像分类结果, 使图像分类错误率较高. 为了克服全局特征的缺陷, 文献[13]提出了基于局部特征的图像分类方法, 相对于全局特征, 局部特征可更好地刻画特征的细节信息, 局部特征对光照变化、 遮挡等图像具有较强的鲁棒性, 已成为当前图像分类中的主要研究方向. 由于图像处理技术的不断成熟, 图像数量不断呈指数形式增长, 传统单机图像分类模式已无法满足图像分类的实时性要求, 因此如何对大数据图像进行快速、 准确地分类面临巨大的挑战[14].
云计算是一种新兴的数据处理模式, 具有分布式和并行处理能力, 可将分散、 大量不同地点的硬件和软件资源组织在一起, 形成一个庞大的资源池, 用户通过申请服务方式利用资源池中的资源, 加快任务完成的速度. 为了解决大数据图像分类耗时长、 实时性差等问题, 本文提出一种基于Hadoop平台的大数据图像分类机制. 首先提取图像分类的有效特征, 然后采用Map函数和Reduce函数得到图像分类结果, 最后仿真模拟测试本文分类机制的优越性.
1 Hadoop平台

图1 Hadoop平台的基本架构Fig.1 Basic architecture of Hadoop platform
Hadoop平台是云计算中的一种分布式处理系统, 具有强大的容错能力和计算能力, 易扩展, 对数据的处理和分析结果可靠, 适合于大数据的开发和处理. Hadoop平台的基本架构如图1所示, 主要包括核心组件、 分布式文件系统、 Map/Reduce编程模型、 文件存储数据库等. 核心组件主要用于对文件的远程处理和调度, 分布式文件系统简称为HDFS, 主要负责对数据的读取和写入, 包括名称节点(Name Node)、 数据节点(Data Node)、 客户(Client), 其中名称节点的任务主要包括存储和管理文件信息; 对文件系统目录之间的映射关系进行维护; 对用户任务进行分析, 并为其分配相应的数据节点; 对文件任务进行管理和控制, 一个分布式文件系统只有一个名称节点. 数据节点属于工作节点, 一个分布式文件系统有多个数据节点, 主要完成名称节点和任务之间的通信, 根据通信协议和客户端进行通信. 客户的功能是分布式文件系统和用户之间的关联, 当用户要进行数据读取操作时, 则为该用户建立一个数据传输的通道. Map/Reduce是进行大数据处理的模块, 文件存储数据库主要用于处理规模数据, 容错能力强, 可靠性高, 主要包括Job Tracker负责为任务服务器分配相应任务, 并划分相应的计算资源; Task Tracker负责任务的执行; Job负责上传用户提供的任务; Task为最小的任务单元; Speculative_Task主要负责备份任务.
Map/Reduce编程模型的工作原理如图2所示, 步骤如下:
1) 将文件传输给Map/Reduce模型, 根据节点数、 文件大小及用户要求, 将文件划分成多个数据片(Split), 每个数据片与一个Map对应, Map数据不能太大, 因此数据片的合理设置十分重要;
2) 根据key/value的格式, Map对数据进行读入, 并将数据存储在本地节点上, 采用编写的代码对任务进行执行操作;
3) 对Map的输出数据进行排序、 复制、 合并等操作, 实现数据的初步整合, 可对数据进行压缩和简化, 节约数据的存储空间;
4) 将初步整合的结果发送给Reduce( )函数进行处理, 对数据进行再一次合并;
5) 将Reduce( )函数处理结果发送到分布式文件系统中.
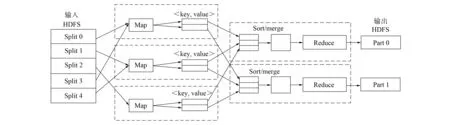
图2 Map/Reduce编程模型的工作原理Fig.2 Working principle of Map/Reduce programming model
2 Hadoop平台的大数据图像分类机制设计
2.1 图像的预处理
由于受光照、 设备、 外界环境等因素的干扰, 采集的图像会产生一定失真, 因此需对原始图像进行预处理, 以提高图像分类的效果. 首先, 用平滑卷积滤波器对原始图像进行去噪处理, 消除图像中的噪声, 计算公式为
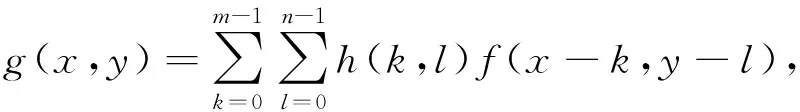
(1)
其中:f(x,y)表示原始图像的像素点;h( )表示平滑卷积滤波器;k,j表示滤波的尺度和大小;m×n表示图像的总像素. 其次, 采用如下仿射变换对平滑卷积滤波器的图像进行校正:
(2)
其中aij表示变换系数. 然后用最小二乘(LS)算法对图像输入和输出点之间的映射关系进行拟合:
(3)
最后根据如下仿射变换参数的求解公式进行去噪后图像校正:
2.2 提取图像特征
尺度不变特征转换(SIFT)算法是一种尺度空间变换处理算法, 可对图像的位置、 尺度和旋转等局部特征进行提取, 因此本文选择SIFT算法提取图像分类的特征, 步骤如下:
1) 对图像进行尺度变换, 产生不同尺度的空间序列, 对一幅图像f(x,y), 采用高斯卷积核函数G(x,y,σ)进行卷积操作, 得到尺度空间为
L(x,y,σ)=G(x,y,σ)*f(x,y),
(6)
其中: *表示卷积;G(x,y,σ)定义为
(7)
式中σ表示尺度空间因子. 对高斯卷积操作后的图像进行降采样操作, 可得到图像的金字塔分层结构:
D(x,y,σ)=(G(x,y,kσ)-G(x,y,σ))*f(x,y)=L(x,y,kσ)-L(x,y,σ).
(8)
从图像金字塔分层结构中提取图像的候选特征点, 通过对三维二次函数进行拟合, 估计关键点的位置和尺度, 可去掉部分无用特征点, 即
(9)
图像的候选特征点检测结果如图3所示. 根据特征点的邻域像素梯度分布为其分配一个方向, 则特征点的梯度大小和方向分别为
(10)
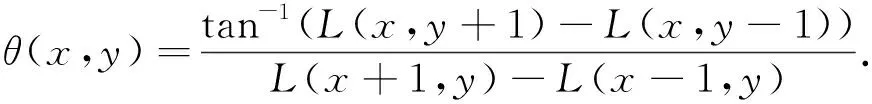
(11)
根据梯度方向直方图得到主梯度方向如图4所示. 每个特征点的位置、 尺度和方向均可确定, 从而完成了图像关键特征点的检测.
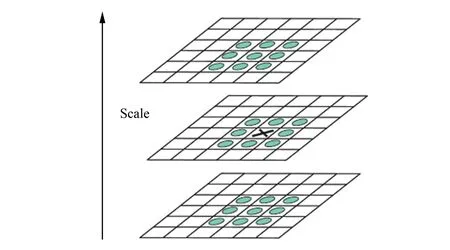
图3 空间特征点的检测Fig.3 Detection of spatial feature points

图4 主梯度方向Fig.4 Direction of main gradient
2) 将坐标轴旋转作为关键点的方向, 每个特征点能产生128维的特征向量, 该特征向量对光照变化、 尺度变化、 几何旋转具有较强的鲁棒性. 由于每个特征向量为128维, 图像特征点较多时, 特征存储空间较大, 对图像分类实时性产生不利影响, 因此采用主成分分析算法对特征进行融合和处理.
2.3 图像分类器的构建
支持向量机的基本思想是找到一个可将两类样本分开的分类线, 对一个高维空间, 最优分类线即为最优分类面. 设样本集为(xi,yi),i=1,2,…,n,x∈d, y∈{+1,-1}表示分类标签, 则最优分类面为
wT·x+b=0.
(12)
使两种样本分类间隔最大的分类面为
yi(wT·xi+b)≥1, i=1,2,…,n.
(13)
将式(11)作为分类的约束条件, 对
(14)
的极小值进行求解. 当样本为线性不可分时, 在式(11)的分类约束条件中引入松驰项ξi≥0, 则有
yi(wT·xi+b)≥1-ξi.
(15)
在支持向量机的分类过程中, 很难发现样本错分现象, 因此引入错误惩罚因子C, 将式(15)变为
(16)
引入Lagrange乘子ai得到式(16)的对偶形式为

(18)
其中K(xi·x)表示核函数. 根据式(18)建立图像的分类器, 对待分类的图像进行识别和分类.
2.4 Hadoop平台的大数据图像分类步骤
1) Client向Hadoop平台的Job Tracker提交一个图像分类任务, Job Tracker将图像特征数据复制到本地的分布式文件处理系统中;
2) 对图像分类的任务进行初始化, 将任务放入任务队列中, Job Tracker根据不同节点的处理能力将任务分配到相应的节点上, 即Task Tracker上;
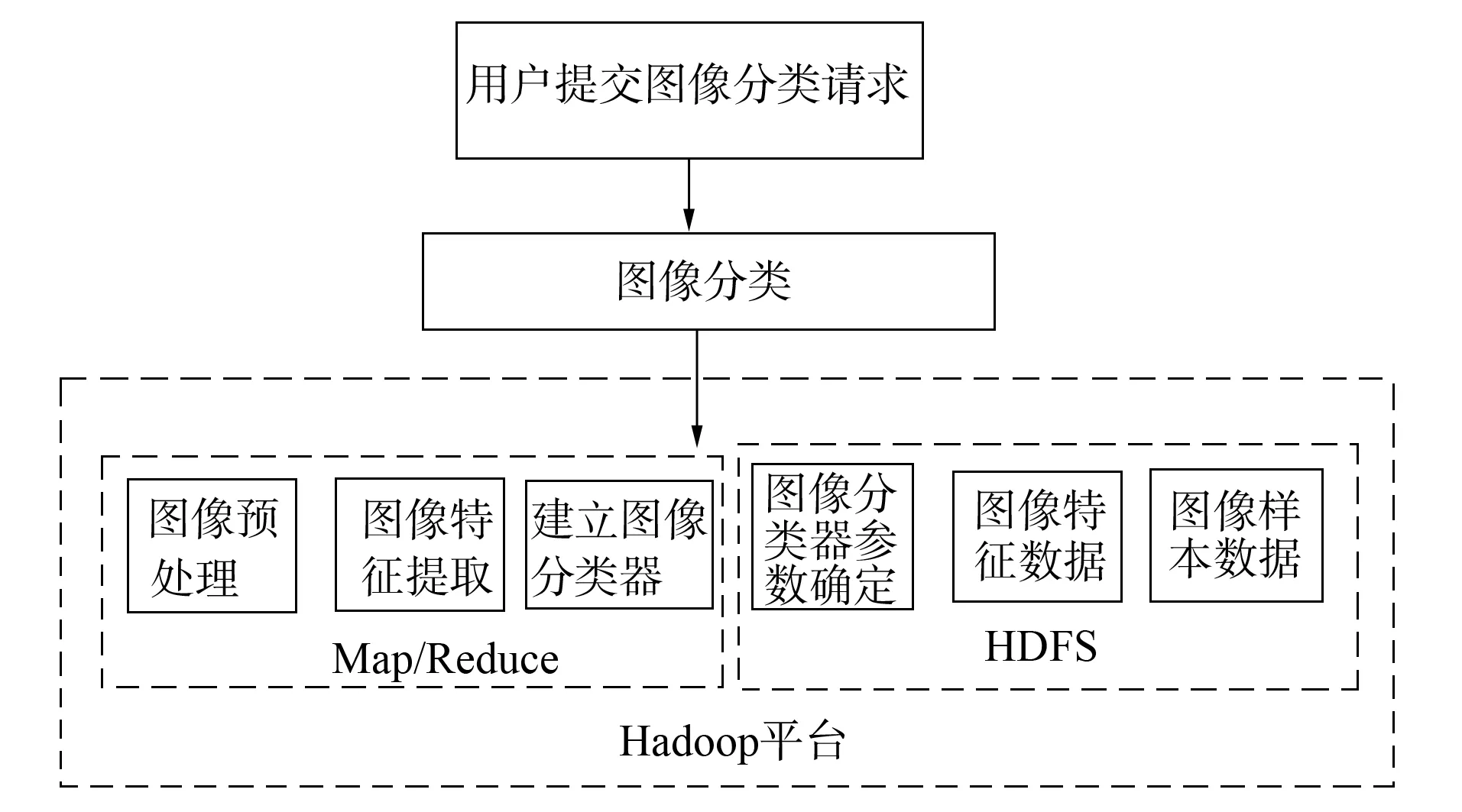
图5 基于Hadoop平台的大数据图像分类流程Fig.5 Flow chart of large data image classification based on Hadoop platform
3) 各Task Tracker根据分配的任务, 采用支持向量机拟合待分类图像特征与图像特征库之间的关系, 得到图像相应的类别;
4) 将图像相应的类别作为key/value, 保存到本地文件磁盘中;
5) 如果图像分类中间结果的key/value相同, 则对其进行合并, 将合并的结果交给Reduce进行处理, 得到图像分类的结果, 并将结果写入到分布式文件处理系统中;
6) Job Tracker将任务状态进行清空处理, 用户从分布式文件处理系统中得到图像分类的结果.
基于Hadoop平台的大数据图像分类流程如图5所示.
3 图像分类的实验结果与分析
3.1 搭建Hadoop平台
Hadoop平台包括1个主服务器(Master)和5个从服务器(Slave), 其中主服务器负责对所有资源的管理和分配, 从服务器主要实现数据节点和Task Tracker功能, 其配置列于表1. 采用VC++6.0作为开发工具实现大数据图像分类算法.
3.2 Map和Reduce的性能测试
选择1 500幅图像作为测试对象, 提取它们的SIFT特征作为分类器的输入向量, 并采用主成分分析对特征向量进行降维, 不同数量的Map和Reduce条件下, 图像的分类时间列于表2. 由表2可见:
1) 当Reduce的数量固定不变时, 随着Map数量的不断增加, Map的任务执行时间不断减少, Reduce的任务执行时间略有下降, 但下降的幅度没有Map大, 但当Map的数量增加到一定程度时, Reduce的任务完成时间却略有增加, 这主要是因为随着Map数量的增加, 中间数据产生的规模不断增加, 导致Reduce的任务完成时间延长;
2) 当Map的数量和Reduce的数量分为16和8时, 任务的总执行时间最短, 因此选择该数值进行图像分类测试.
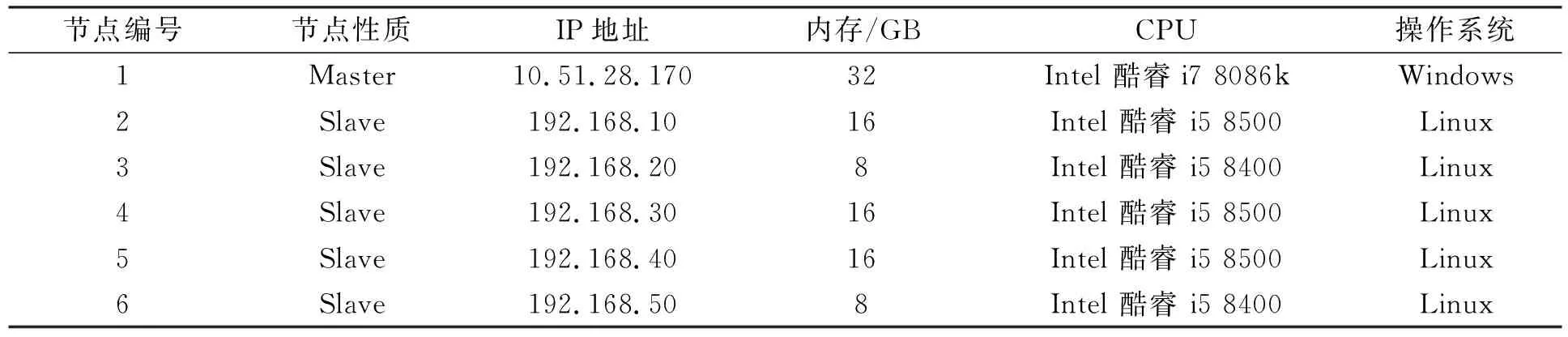
表1 Hadoop平台的配置

表2 不同数量Map和Reduce的图像分类时间
3.3 与传统单机平台的图像分类性能对比
当测试图像数量从2 000增加到10 000时, 传统单机平台、 单节点的Hadoop平台、 6个节点的Hadoop平台的图像分类任务执行时间如图6所示. 由图6可见:
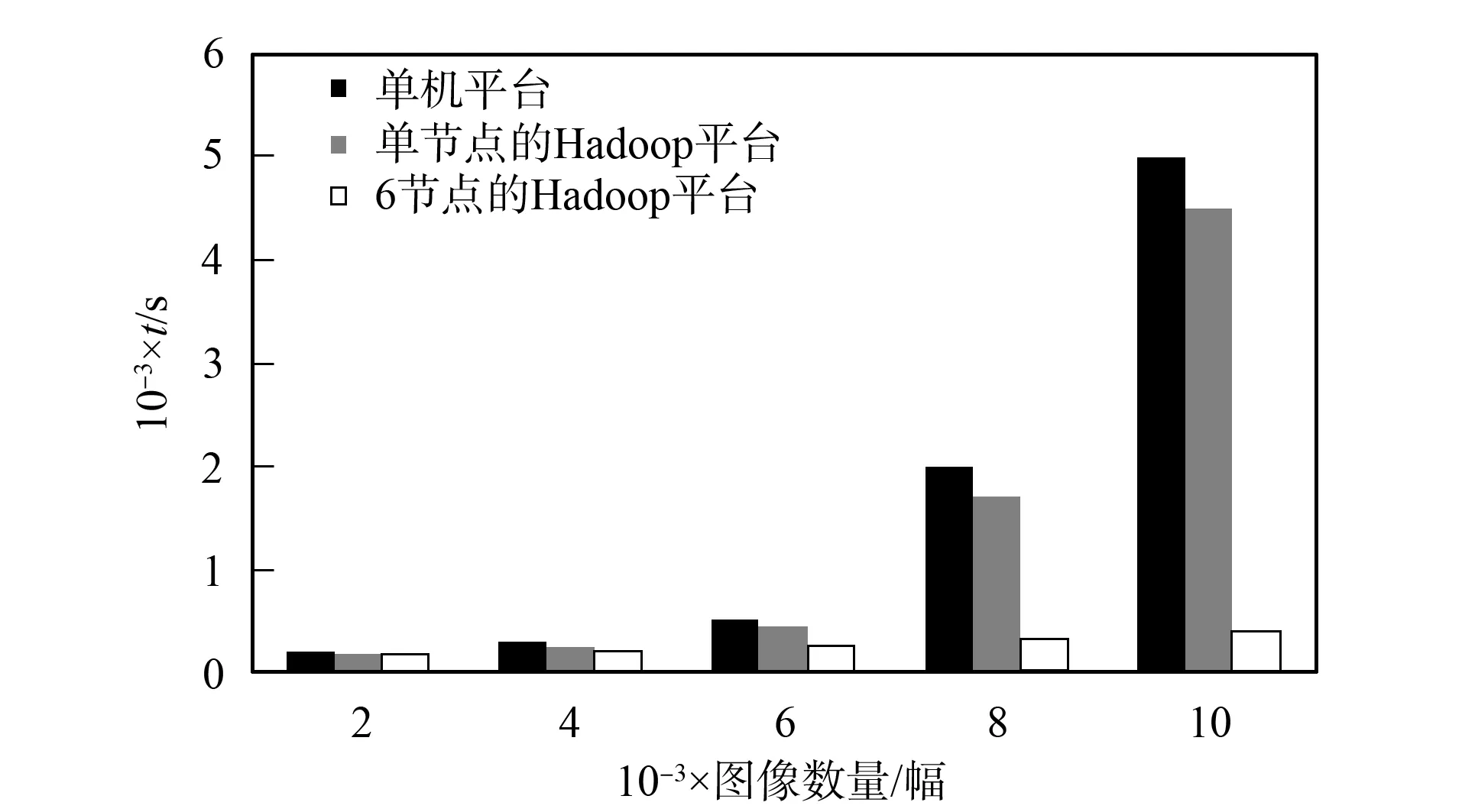
图6 不同节点数的图像分类时间对比Fig.6 Comparison of image classification time with different number of nodes
1) 当图像数量不断增加时, 传统单机平台的图像分类时间不断延长, 几乎呈线性增加趋势, 这是因为随着图像数量的增加, 单机内存驻留的数据量过大, 无法满足大数据图像分类的时间要求;
2) 单节点的Hadoop平台图像分类时间与传统单机平台的图像分类时间差不多, 略有下降, 这是因为单节点的Hadoop平台要进行任务的初始化、 任务的细分、 分类结果的传输等操作, 这些均会延长Hadoop平台的运行时间, 导致图像分类的整体时间延长;
3) 6个节点的Hadoop平台图像分类任务所需时间明显短于传统单机平台, 图像分类的分类速度得到大幅度提升, 这主要是通过不同节点之间的协作完成大数据图像分类的任务, 缩短了图像的分类时间.
综上所述, 本文针对传统单机平台存在图像分类时间长、 速度慢而无法满足大数据图像分类要求的缺陷, 提出一种基于Hadoop平台的大数据图像分类机制, 将大数据图像分类任务拆分为Map和Reduce任务, 通过多个节点协同完成大数据图像分类任务, 大幅度提升了图像分类的速度, 尤其当图像数据规模较大时, 图像分类效率的优势更明显.
