自适应目标变化的时空上下文抗遮挡跟踪算法*
2018-10-08范洪博
张 晶,王 旭,范洪博
(昆明理工大学信息工程与自动化学院,云南 昆明 650500)
1 引言
目标跟踪在计算机视觉领域是一个热门话题,通过信息融合技术将不同种传感器获取的目标特征信息进行融合来实现场景中的目标跟踪将越来越引起人们关注。目标跟踪过程会受多种因素干扰,其中包括遮挡、环境光照变化、目标连续变化而导致的颜色、边缘的相应变化。这些常见问题是目标跟踪亟需解决的。近年来研究者针对这些问题提出了很多优秀的跟踪算法,比如:多示例学习MIL(Multiple Instance Learning)算法[1]对当前跟踪结果小邻域采样构成正包,在其大邻域圆环内采样构成负包进行多示例学习,从而获得分类器进行目标判断;改进的多示例学习IMIL(Improved Multiple Instance Learning)算法[2]根据压缩感知理论设计随机测量矩阵,然后利用多示例学习,后面的处理与MIL算法一致;快速压缩跟踪FCT(Fast Compressive Tracking)算法[3]是一种基于数据独立的多尺度图像特征空间的特征模型,稀疏的测量矩阵压缩了前景目标和背景图像,并不断更新,最后通过贝叶斯分类器进行目标判断;增量视觉跟踪器IVT(Incremental learning for robust Visual Tracking)[4]在获得当前帧之前若干帧跟踪结果所构成的图像空间条件下,对所得图像空间进行主成分分析PCA(Principal Component Analysis)处理,获得历史跟踪结果的均值和特征向量,构成特征子空间,每5帧更新一次,并将粒子滤波确定的候选模型送入特征空间,计算其与特征子空间中心的距离,输出距离最优者;视觉跟踪分解VTD(Visual Tracking Decomposition)算法[5]将基本的观测模型和基本的运动模型联系起来,设计多个基本跟踪器,然后将所有的基本追踪器都集成到一个复合跟踪器中,在这个框架中,基本跟踪器在并行运行的同时进行交互。通过与其它跟踪器交换信息,每一个跟踪器进一步提高性能,从而提高了跟踪的整体性能;基于盒粒子滤波的群目标跟踪Box-PF(group targets tracking algorithm based on Box Particle Filter)算法[6]是一种基于广义似然加权方法改进的粒子滤波算法,利用广义似然函数的定积分来计算区间测量中粒子的权重,提出了一种基于方框粒子滤波的群跟踪算法;TLD(Tracking-Learning-Detection)[7]将传统跟踪算法和传统检测算法相结合,同时,通过一种改进的在线学习机制不断更新跟踪模块的“显著特征点”和检测模块的目标模型及相关参数,从而使得跟踪效果更加稳定、鲁棒、可靠。但是,为了达到跟踪的鲁棒性,近年来研究者引入了时空上下文的思想,将时间上下文环境与空间上下文信息结合进行跟踪,提出了时空上下文STC(Spatio-Temporal Context)算法[8]。
许多学者对时空上下文算法进行了研究并提出了很多改进,文献[9]提出了干扰项和有贡献区域的定义,在此基础上进一步细化上下文结构。文献[10]根据上下文不同区域与目标区域运动的相似性,对目标周围的灰度信息赋予不同的权值,增加算法的抗干扰能力。文献[11]利用在线结构化支持向量机建立物体间的空间约束信息模型来提高跟踪的准确性。文献[12]提出了抗遮挡机制,将上下文区域分块并基于颜色的相似度来判定目标是否被遮挡,遮挡后采取分块匹配来定位目标的位置。文献[13,14]提出将核粒子滤波KCF(Kernerlized Correlation Filters)算法输出框进行保守相似度计算,对相似度低的输出框进行检测器检测,检测到单一聚类框再输出。
文献[9,10]提出的算法不具有抗遮挡机制,而文献[12]提出的算法采取了颜色直方图相似度进行遮挡判断,准确率不高,文献[13,14]在一些复杂情景中,对于检测器检测到的多个候选目标,却不做输出,降低了算法的跟踪成功率。以上算法都存在目标跟踪过程中输出窗口长期不变的问题,因此为了适应目标大小变化,解决STC算法跟踪失败问题,本文结合TLD框架思想提出一种自适应目标变化的时空上下文抗遮挡跟踪算法STC-ALD(Anti-occlusion and adaptive target change visual tracking algorithm based on Spatio-Temporal Context)。初始化跟踪点并进行中值流跟踪算法,预测下一帧跟踪点位置,同时计算STC算法得到的目标框的保守相似度,超过设定阈值即认为跟踪有效,然后将跟踪点与STC前后输出框的中心像素进行运动相似度计算[10],对运动相似度高的跟踪点进行窗口调整后输出。相反地,跟踪判定为无效就利用检测器进行检测,对检测到的单一聚类框直接输出结果,直接输出,而对多个聚类结果,目标很有可能是其中的一个,本文算法将逐个计算其时空上下文模型并利用当前空间模型计算置信度,最终将置信值最大的聚类框作为目标输出。
2 时空上下文视觉跟踪
STC算法基于贝叶斯框架,在当前帧确定上下文集合:Xc={c(z)=(I(z),z)|z∈Ωc(x*)},其中x*是目标区域中心,I(z)是目标区域像素z的灰度值,Ωc(x*)是由目标矩形确定的局部上下文区域的图像灰度与位置的统计建模。通过一些基本的概率公式,计算置信度找到似然概率最大的位置,即为跟踪结果。
置信度公式为:
(1)
其中,x和z表示像素坐标,P(x|c(z),o)是目标o与局部上下文区域空间关系的条件概率,P(c(z)|o)是局部上下文各个点x的上下文先验概率。
P(c(z)|o)上下文先验模型在STC算法进行以下计算:
P(c(z)|o)=I(z)ωσ(z-x*)
(2)
(3)
其中,ω′是归一化参数,取值为[0,1],σ是一个尺度参数,σ2是高斯函数方差,ωσ(z-x*)是区域中心加权的高斯函数,区域中心像素贡献大,区域边缘像素贡献小。
在STC算法中将P(x|c(z),o)称为空间上下文模型,定义为:
P(x|c(z),o)=hsc(x-z)
(4)
公式(1)中置信函数c(x)在STC算法中计算如下:
(5)
其中,b是归一化参数,a是尺度参数,β是目标形状参数。将公式(2)和公式(5)代入公式(1)得:

(6)
而为了加快STC算法的运行速度,将公式(6)两边进行快速傅里叶变换,得空间上下文模型为:
(7)
空间上下文模型更新成时空上下文模型为:

(8)
其中,ρ为模型更新的学习率。
公式(1)~公式(7)均来自文献[8]。
具体STC算法跟踪过程概括如下:
(1)在t帧,将选定的目标计算其置信度,以及计算得到上下文先验模型。
(2)计算当前帧空间上下文模型。

(4)利用t帧的Ωc(x*)区域在t+1帧计算上下文先验模型。
(5)根据公式(1)、公式(6),已知t+1帧的上下文先验模型以及空间上下文模型,利用公式(6)计算其置信度。
(6)将t+1帧得到的置信度最大点,做为目标在t+1帧的位置,随后返回第一步继续计算下一帧。将每一帧的置信度的极值点作为目标位置输出。
3 自适应目标变化的时空上下文抗遮挡跟踪算法
3.1 跟踪点与STC前后输出框运动相似度计算
传统的TLD算法采取中值流跟踪算法,对跟踪点进行F-B(Forward-Backward)误差消除,此算法在文献[15]已经详细介绍,本文就不再阐述。但是,实验发现直接利用F-B误差消除错误跟踪点,利用剩下的跟踪点集进行目标尺度变化分析是不准确的。如图1所示,左侧白色点表示经过F-B误差消除后的剩余跟踪点,黑色线条表示跟踪点位移向量。从图中可以观察到,在目标框中的跟踪点有些处于遮挡物上,利用这些跟踪点对目标尺度变化分析将带来误差。于是本文引入了跟踪点与STC前后输出框的中心像素运动相似度计算方法,一旦相似度值大于阈值,即为可靠跟踪点,利用这些跟踪点进行目标尺度分析具有很高的准确性。

Figure 1 Tracking point once removed and that compared to the two erasure图1 跟踪点一次消除与两次消除的效果对比图

(9)

(10)
最后,将每个跟踪点与目标中心像素的距离转换成一种权值,即相似度,公式如下[10]:
(11)

3.2 目标尺度变化的窗口调整

(12)

s1=λ*(MS-μ)*wt-1,
s2=λ*(MS-μ)*ht-1,
wt=wt-1*MS,
ht=ht-1*MS,
xt=xt-1+MDx-s1,
yt=yt-1+MDy-s2
(13)
其中,λ,μ为尺度参数,wt-1,wt,ht-1,ht为第t-1、第t帧目标的矩形框的长、宽,(xt-1,yt-1),(xt,yt)为第t-1、第t帧的目标矩形左上角坐标。
即经过两次消除错误跟踪点后,利用可靠跟踪点分析目标尺度变化,并输出具体目标矩形{(xt,yt),wt,ht}。
3.3 STC-ALD算法的时空模型更新


(14)

Figure 2 STC-ALD algorithm learning process of the spatial context model for target scale expansion图2 STC-ALD算法对目标尺度扩展的空间模型学习图
3.4 算法流程
综上所述,自适应目标变化的时空上下文抗遮挡跟踪算法具体流程如下:
(1)初始化跟踪框。
(2)检测器的学习。
(3)采取TLD中值流算法初始化跟踪点以及利用目标与局部区域的时空关系学习时空上下文模型,与上下文先验模型计算置信度,得到STC算法在下一帧的目标框,同时对初始跟踪点采取金字塔光流法来预测下一帧的跟踪点位置。并采取3.1节的方法进行相似度计算,同时计算STC的目标框的保守相似度。
(4)若步骤(3)的保守相似度值大于0.5,则将跟踪点进行窗口调整并输出。小于0.5就根据检测器的检测结果,对检测到的单一聚类框直接输出。而对多个聚类结果,目标很有可能是其中的一个,利用当前空间模型逐个计算其置信度,将置信度值最大的聚类框作为目标输出。
(5)学习与更新:本文算法对检测器参数在线学习和更新与TLD算法一致,而对于STC算法的时空模型更新采取的是3.3节的方法。
(6)跟踪下一帧,返回步骤(3)。
算法框图如图3所示。

Figure 3 Tracking flow chart of the STC-ALD algorithm 图3 STC-ALD算法跟踪流程图
4 实验结果
为验证STC-ALD算法的鲁棒性,本文对STC、STC-ALD进行实验对比验证,除了原始的STC算法外,还挑选了上文提到的TLD算法,这些算法均有公开的C++代码。而实验的视频资源来自吴毅老师发表的目标跟踪评测文献[16]提到的评测视频库,保证了实验的可信度。
本文算法是在STC公开的多尺度C++代码上改写的,主要增加了目标尺度变化分析以及目标检测过程。因STC算法计算速度快,而本文在此基础上增加了基于金字塔稀疏光流算法以及位移向量相似度判断,以及跟踪判定失效利用检测器检测,对多个聚类框进行逐个置信度计算,故STC-ALD算法的实时性不会很低,具体算法运行速度将在4.2节给出。本文的实验环境为:Intel(R) i5-4590 3.30 GHz处理器、8 GB内存,软件环境为:Windows 7+VS2013+OpenCV。本文实验对CarScale,David,Boy,FaceOcc2,Sylvester视频序列直接采用评测文献[16]中提供的 Ground truth 以及初始框的位置与大小,实验序列包括目标旋转、遮挡、形变,快速运动等挑战条件来验证本文算法的鲁棒性,实验视频序列描述如表1所示。

Table 1 Video sequence description of the experiment表1 实验视频序列描述
4.1 实验参数
在实验过程中,STC-ALD算法提到的参数设置如下:公式(5)参数α=2.25,β=1,公式(8)参数ρ=0.075,与原STC算法是一致的,而本文提出的公式,如公式(11)的参数γ=4,与文献[10]中的一致,公式(13)的参数λ=0.5,μ=1,与TLD算法公开源码中的参数一致。
4.2 实验结果
本文采取了跟踪重叠率这一评判标准进行评测,跟踪重叠率定义为R=Area(Os∩Og)/Area(Os∪Og),其中Os是跟踪器输出的目标框,Og是目标真实大小框。∩、∪表示两种框之间的交集与并集,Area(·)表示面积大小。5个测试视频序列的跟踪重叠率如图4所示。图5~图8给出了具有代表性的跟踪结果截图。本文也给出了平均跟踪精度,即平均中心位置误差CLE(Center Location Error)以及跟踪成功率,跟踪重叠阈值取0.5。
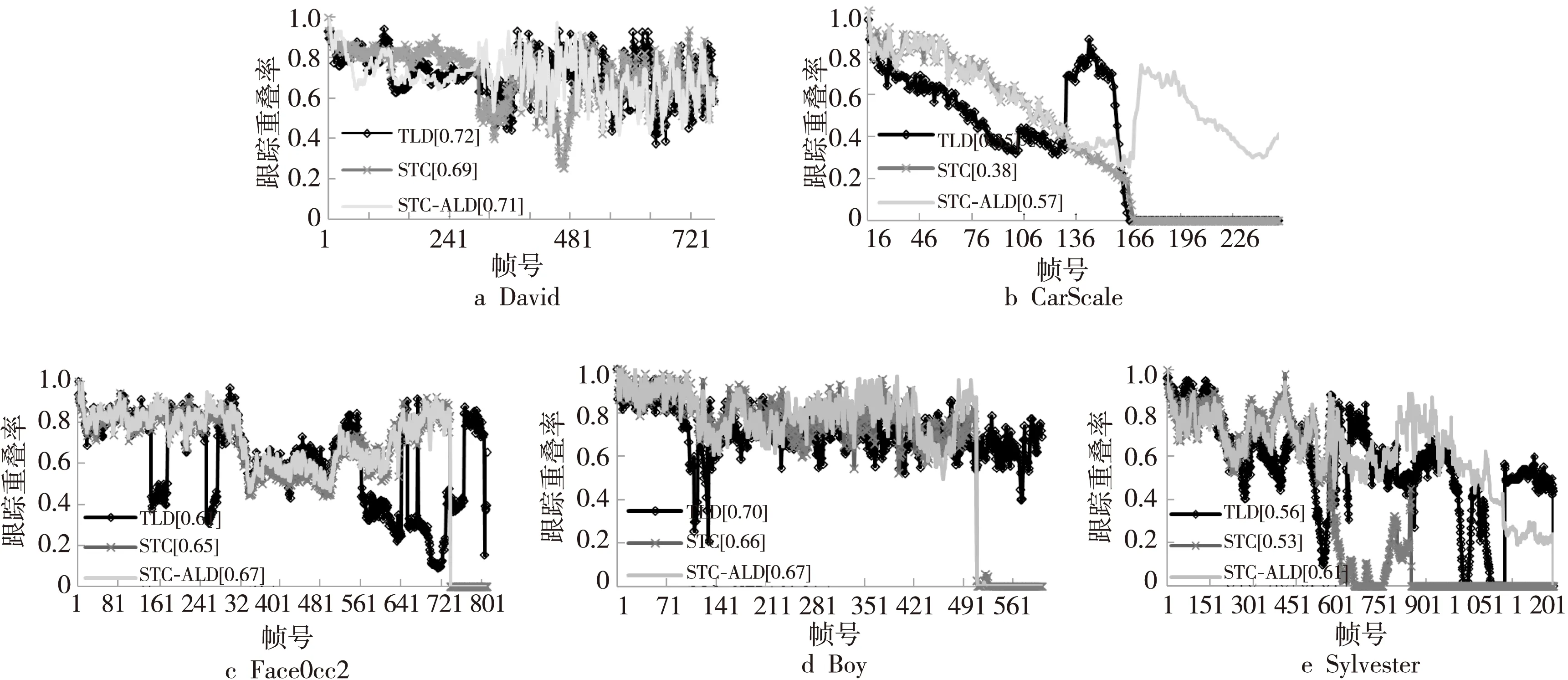
Figure 4 Overlapping rate of the video sequence to be tested图4 测试视频序列的跟踪重叠度图

Figure 5 Tracking of scale changes图5 尺度变化的跟踪情景

Figure 6 Occlution图6 遮挡情景

Figure 7 Scale variation 图7 旋转情景

Figure 8 Fast-moving (Test sequence of Boy)图8 快速移动(测试序列Boy)
具体结果如表2和表3所示。而表4给出了在5个测试视频中的平均帧率。

Table 2 Average center location error表2 平均中心位置误差 像素

Table 3 Success rate of tracking表3 跟踪成功率 %

Table 4 Average frame rate表4 算法平均帧率 (f/s)
4.2.1 目标尺度变化
从图4的David视频跟踪重叠率结果图可以看出,初始阶段本文算法与TLD算法出入不大,因目标尺度变化不明显,显著跟踪点两次消除与TLD算法的一次消除后的跟踪点基本一致。但是,在中期阶段,即视频序列#201~#488的时间段,目标发生靠近镜头、自身转动等尺度变化,很明显传统STC窗口不变的结果不是最优的。同时,因为TLD算法将目标框内背景上的跟踪点也进行尺度变化计算,就导致了窗口调整过度。如图5的David测试序列#454,明显看出白色虚线窗口缩小过度了,而采取本文的两次消除方法,只对运动相似度高的跟踪点进行尺度变化,计算准确很多,如浅黑色框所示。而从表2也可看出,本文算法较STC算法的平均中心位置误差有所提高,与TLD算法差距也不大。从表3中可看出,本文算法的跟踪成功率总体优于STC算法,与TLD算法差距不大。当目标发生尺度变化时窗口不自适应调整,不对具体目标上下文区域进行空间模型的学习将导致模型的学习不准确,比如目标缩小时,仍然一如既往采取同样的上下文区域进行学习,这将导致学习了过多的非目标的灰度信息,从而导致追踪失败,如图5的Sylvester测试视频的#604。而从表2也可看出,Sylvester测试视频中STC-ALD算法的平均中心位置误差比STC算法的降低了接近70个像素,表示跟踪准确性得到很大提高。同样从表3也可看出,本文算法的成功率也有所提高。
4.2.2 目标遮挡
图6的CarScale、FaceOcc2视频序列出现了传统STC算法发生跟踪漂移现象,加入本文算法后的改进,在CarScale视频序列,因目标一直处于靠近镜头的尺寸变化,而传统STC算法跟踪窗口不随着目标变大而进行扩大化的调整,那么在空间模型学习过程中,就降低了超出上下文区域的目标灰度信息学习率,那么在这个变大的过程中,目标一旦受到遮挡干扰就很容易发生跟踪漂移甚至跟踪失败现象,如图6的CarScale视频序列#168,而本文算法就能很好地解决这样的问题,如图6的CarScale视频序列#191。再结合表2和表3中CarScale序列的结果,本文算法因抗遮挡成功,跟踪的中心位置误差优于STC算法,降低了接近80个像素,比TLD算法降低了接近90个像素,其成功率也是最优的;而在FaceOcc2视频序列中,目标并未发生靠近或者远离镜头的尺度变化,那么传统STC跟踪算法在目标未完全遮挡期间段,跟踪效果很好,而本文算法是采取两次消除错误跟踪点,跟踪效果与传统STC算法出入不大,故中心位置误差以及跟踪成功率差距不大;而只采取一次消除错误跟踪点的TLD算法,就存在目标遮挡时的错误调整,即受到遮挡物上跟踪点的影响,错误地进行目标窗口调整,如图6的视频#141,#255,#493。在最终的遮挡过度情景,STC算法就发生了跟踪漂移现象,但是,本文采取TLD检测机制,在遮挡物与在线目标模型的保守相似度小于0.5后,利用上下文时空模型对检测到的多个目标计算其置信度,输出最大值,所以具有跟踪恢复机制,如图7第2行的视频#812。
4.2.3 目标旋转以及快速移动
Sylvester以及FaceOcc2视频序列存在目标旋转情况,而从图7中Sylvester视频序列的部分实验截图可以看出,STC-ALD算法在目标旋转时仍然可以准确跟踪,最终在视频结束时的跟踪情况也是最优的,如图7第1行的视频#1344。从表3可看出,其中心位置误差比TLD算法还降低了几个像素,即目标旋转对本文算法影响不大。而对于快速移动的目标,如图8中Boy测试视频部分截图,在视频#510之后,STC跟踪发生漂移现象,而本文算法具有跟踪恢复机制,故可以持续跟踪。从图4的视频序列跟踪重叠率来看,本文算法也是最优的,同时结合表2的中心位置误差来看,本文算法的成功率也较STC算法有所提高。
5 结束语
传统时空上下文目标跟踪算法存在两个主要不足点:(1)目标发生尺度变化时跟踪窗口长期固定;(2)目标丢失缺少跟踪恢复机制。故本文提出一种自适应目标变化的时空上下文抗遮挡跟踪算法(STC-ALD),该算法采取TLD算法框架思想,利用中值流算法初始化跟踪点,其次预测下一帧跟踪点位置并利用F-B误差算法消除错误跟踪点,并采取STC算法确定输出框,计算其保守相似度,当保守相似度超过设定阈值即表示跟踪有效,将跟踪点与STC前后输出框的中心像素进行运动相似度计算;然后利用运动相似度高的跟踪点进行窗口调整并输出,从而提高跟踪的准确性。同时,当STC算法跟踪失效时,就利用TLD检测器进行检测,对单一聚类框直接输出,而对多个检测聚类框逐个计算其置信度,输出置信度值最大的聚类框。这样的跟踪恢复机制大大提高了跟踪的持续性。最后,进行在线学习更新分类器的相关参数,提高检测精度。大量实验结果表明,本文的STC-ALD算法性能超过了STC和TLD算法,大大提高了跟踪成功率和鲁棒性。然而,本文算法只提取目标简单的灰度信息进行学习和跟踪,忽略了目标具有的颜色特征以及形状特征,为了提高跟踪的准确性,故接下来的研究重点是如何融合目标多种信息进行学习和跟踪。
