基于改进多层感知机的手写数字识别*
2018-09-29刘紫燕
何 平,刘紫燕
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
0 引 言
手写数字识别是光学字符识别(Optical Character Recognition,ORC)技术的分支之一,研究的对象是如何利用计算机自动辨识写在纸张上的阿拉伯数字(0~9)[1]。手写数字识别在财务报表、邮政编码、银行票据等方面有着广泛应用。实际应用中,对数字识别技术中单字识别正确率的要求比文字识别技术更苛刻。这是因为数字没有上下文关系,每个单字的识别都非常重要,而且数字识别通常会涉及到金融、财会等领域,重要性不言而喻。手写数字识别是将测试样本的特征与训练样本的特征进行模式匹配,以最大相似度(Maximum Similarity,MS)为度量原则输出识别结果。其中,最关键的是特征提取和分类器的设计。但是,由于手写数字随意性大,经常出现断笔、连笔等现象,导致识别精度及效率不高。近年来,国内外研究学者提出了一些识别方法[2]。Guo Mingzhao等人提出将KNN算法及决策树算法用于手写数字识别问题的研究,对于一些书写不规范的数字能较为准确的识别。张红、马静等人提出的共轨梯度BP算法、自适应BP算法、LM-BP算法,能有效加快BP算法的训练速度,提高识别效率。赵朋成、冯玉田等人对传统深度残差网络进行改进,通过对卷积核大小、移动步长等参数进行调整,使其适合手写体数字识别。在池化层使用重叠池化方案,以有效保留上一层有用信息,可以有效提高识别准确率。Yutao等人提出把稀疏自编码器无监督学习得到的权值矩阵应用于卷积神经网络,并利用提取的特征训练分类器,最终得到的网络分类效果较理想,对图像的平移具有一定的容忍能力,且不容易出现过拟合等。这些方法要么只提高了识别准确率,要么只提高了识别效率,没有同时提高准确率及效率[3-4]。用户的要求不仅是高准确率,更重要的是极低的误识率。此外,大量数据处理对系统速度又有较高要求,许多理论上非常完美,但速度过低的方法通常是行不通的。因此,研究高性能的手写数字识别算法是一个相当具有挑战性的任务[5-6]。
虽然专家学者对手写数字识别算法做了大量研究,取得了很大成功,但这些方法存在局限性,无法适应各种各样的字符特征。针对这一问题,本文对传统的多层感知机模型进行改进,引入Dropout解决过拟合问题,Adagrad优化参数调试过程,ReLU解决梯度弥散问题,提出了用于手写数字识别的MLP网络模型,并将该模型在TensorFlow平台下实现构建。在进行网络结构的性能调优后,相比基本的MLP模型,该改进模型具有较高的识别精度和识别效率,节省了大量处理时间。
1 手写数字识别原理
手写数字的写法带有明显的民族性和区域性。因此,选择一个可供模型训练和测试使用的样本库,是进行手写数字识别算法研究的重要基础,对识别模型的性能也有重要影响。通常,对所需的样本库有两种选择:一是根据需要建立专用的样本库,二是选择其他机构做好的样本库。前者的优点是贴近自己的应用,缺点是耗费精力且难以保证代表性,与他人的研究结果不好比较。因此,目前的趋势是使用具有权威性的通用样本库[7]。目前,样本数量较大、比较有代表性的手写数字样本库有由美国国家标准与技术局收集的MNIST数据库。本文选取MNIST数据库进行算法验证。
作为一个识别系统(Recognition System),最终要用某些参数来评价其性能的高低,手写数字识别同样如此。评价指标除了借用一般文字识别的指标外,还需要根据数字识别的特点进行相应补充及修改。对于手写数字识别系统,通常可用3方面的指标表征其性能。
(1)正确识别率

(2)误识率(替代率)

(3)拒识率

三者关系为:

在数字识别应用中,最重要的指标为“识别精度(RecognitionAccuracy)”,即在所有识别字符中除去拒识字符,正确识别的比例大小。定义识别精度为:

一个理想的系统应是S、R尽量小,而P、A尽可能大。然而,在一个实际系统中,S、R通常是相互制约的。因此,在评价手写数字识别系统时,必须综合考虑以上几个指标。另外,由于手写数字的工整程度、书写风格可能不尽相同,因此必须明白评价指标是在何种样本集合下获得的。
2 改进的多层感知机模型
2.1 多层感知机模型结构
多层感知机(Multi-Layer Perceptron,MLP)通常也称为人工神经网络,除了输入、输出层外,中间还可以有很多个隐层(Hidden Layers)[8-9]。其中,最简单的MLP模型只含有一个隐层,即为三层结构,如图1所示。

图1 多层感知机模型
MLP层与层之间是全连接的。最底层是输入层,中间是隐藏层,最后是输出层。输入层神经元负责接收信息,如输入一个n维向量,就有n个神经元。隐藏层神经元负责对输入信息的加工处理。首先,它与输入层之间是全连接的。假设输入层由向量X来表示,则隐含层输出的计算形式为:

式中,W1为连接系数(也叫权重矩阵),b1为偏置向量,函数f(Function)可以是函数Sigmoid,即sigmoid(a)=1/(1+e-a),或者函数tanh即tanh(a)=(ea-e-a)/(ea+e-a)。
输出层神经元负责计算机对输入信息的认知,隐含层到输出层可以看作是一个多类别的逻辑回归(也即Softmax回归),所以输出层的输出为Softmax(W2X1+b2),X1表示隐含层的输出f(W1X+b1)。上述三层MLP模型可总结为:
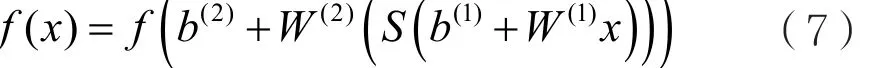
式中,f是函数Softmax。所以,MLP模型的所有参数就是各个层之间的连接权重W矩阵和偏置b向量,其中包含b1、W1、b2、W2。对于具体的问题,这些参数的确定,其实就是求解最佳参数的最优化问题(Optimalization Problem)。解决最优化问题,通常最简单的方法是随机梯度下降法(Stochastic Gradient Descent,SGD),即首先随机初始化所有参数,然后进行迭代训练,不断计算梯度和更新参数,直到满足某个条件(比如误差足够小或迭代次数足够多)为止。该过程常常会涉及代价函数、规则化、学习速率和梯度计算等[10-11]。
2.2 改进的多层感知机模型结构
2.2.1 引入Dropout解决过拟合问题
过拟合是机器学习中的一个常见问题,是指模型预测准确率在训练集上升高,但是在测试集上反而下降,通常意味着泛化性不好。模型只是记忆了当前数据的特征,不具备推广能力[12-13]。Dropout的基本思想是在每次训练时以一定的概率P使部分节点(Nodes)的输出值变为0,即相当于在这次训练中把该部分节点从整个网络中“删除(Cut Out)”,这样在反向传播时就不会更新其对应的参数。而在测试阶段,使用完整的网络进行测试。图2为Dropout的原理。
Dropout在每次训练时,都相当于训练完整网络的一个子网络。假设网络共有M个节点,则可用的子网数为2M个。当M足够大时,每次训练使用的子网基本不会相同,整个网络可以看作是对多个子网模型求平均,从而可以避免训练集在某个子网上出现过拟合(Overfitting)现象,增强网络的泛化能力。
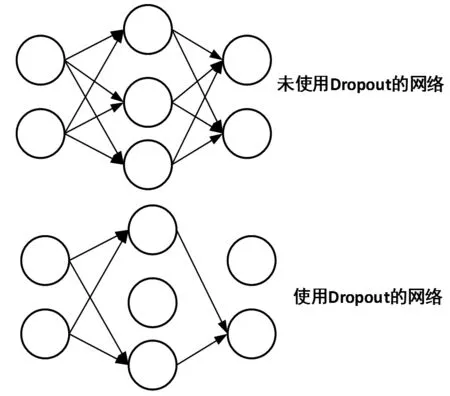
图2 Dropout原理
2.2.2 引入Adagrad优化参数调试
参数难以调试,是神经网络的另一大痛点,尤其是随机梯度下降法(Stochastic Gradient Descent,SGD)的参数。对SGD设置不同的学习速率,最后得到的结果可能差异巨大。神经网络通常不是凸优化问题,存在局部最优。SGD本身也不是一个比较稳定的算法,结果可能会在最优解附近波动,而不同的学习速率可能导致神经网络落入截然不同的局部最优中。Adagrad自适应方法可以减轻调试参数的负担。Adagrad是对学习率进行了一个约束,即:
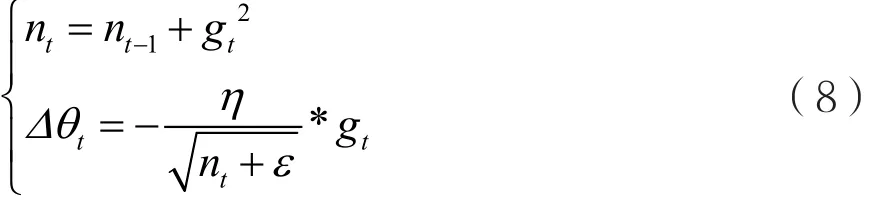
式中,对gt从1到t进行递推,形成一个约束项正则化矩阵(Regularizer),即:

式中,ε用来保证分母非0。Adagrad具有如下特点:(1)前期gt较小时,regularizer较大,能够放大梯度;(2)后期gt较大时,regularizer较小,能够约束梯度;(3)适合处理稀疏梯度。对于Adagrad优化算法,通常使用其默认参数设置,就可以取得一个较好的效果。
2.2.3 引入ReLU解决梯度弥散问题
梯度弥散(Gradient Vanishment)是另一个影响神经网络训练的问题[14]。传统的神经网络训练用Sigmoid作为激活函数。但是,当神经网络层数较多时,Sigmoid函数在反向传播中梯度值会逐渐减小,经过多层传递后呈指数级急剧减小。因此,梯度值在传递到前面几层时会变得非常小。这种情况下,根据训练数据的反馈更新神经网络的参数将会非常缓慢,基本起不到训练作用。而ReLU能比较完美地解决该问题。ReLU是一个简单的非线性函数,即:

式中,当x≤0时,y=0;当x>0时,y=x。它在坐标轴上是一条折线,非常类似于人脑的阈值响应机制。在信号超过某个阈值时,神经元才会进入兴奋和激活状态,平时则处于抑制状态。ReLU可以很好地传递梯度,经过多层的反向传播,梯度依旧不会大幅缩小,因此非常适合训练神经网络。
从信号方面来看,即神经元同时只对输入信号的少部分选择性响应,大量信号被刻意屏蔽了,以提高学习精度,更好更快地提取稀疏特征(SparseFeatures)。ReLU函数相对于Sigmoid函数,一方面大大降低了运算量,另一方面在输入信号较强时,仍然能够保留信号之间的差别。
2.3 改进的MLP模型设计与实现
在TensorFlow软件平台下构建出用于手写数字识别的改进MLP网络模型,并使用Dropout解决过拟合问题,使用自适应学习速率的Adagrad优化参数调试过程,使用激活函数ReLU解决梯度弥散问题。改进的MLP模型实现流程的详细描述如下:步骤1:载入TensorFlow并加载MNIST数据集,创建一个TensorFlow默认的Session;
步骤2:定义算法公式(隐含层使用ReLU作为激活函数);
步骤3:定义损失函数和选择优化器来优化Loss;这里的损失函数使用交叉信息熵,优化器选择自适应的优化器Adagrad,并把学习率设为0.3;
步骤4:训练网络模型;加入keep_prob(即引入Dropout规则)作为计算图的输入,并且在训练时设为0.75,即保留75%的节点,其余的25%置为0;
步骤5:对模型进行准确率和识别效率评测;这里需要加入一个keep_prob作为输入。因为是预测部分,所以直接令keep_prob等于1即可,这样可使模型达到最好的效果。
3 实验结果与分析
3.1 实验环境与数据
整个测试过程中使用的操作系统为Windows,深度学习框架为TensorFlow,开发软件为Python3.0x,主要硬件配置:处理器为I7-7700CPU@3.30 GHz;内存为16 GB;硬盘为Intel 600p 256G;GPU为GTX 1050TI 4G。
选择测试的数据集为标准手写数据集(MNIST数据库),MNIST数据集来自美国国家标准与技术研究所。训练集(training set)由来自250个不同人手写的数字构成,其中50%是高中学生,50%来自人口普查局(the CensusBureau)的工作人员。测试集(test set)也是同样比例的手写数字数据。
3.2 实验结果
训练完成后,将测试样本输入到网络模型中进行测试。测试样本是10 000例手写数字图片。在测试过程中,测试样本通过的是同样的网络结构,但是网络中的偏置参数b向量及权值参数W矩阵是由训练部分进行训练得到。本文选取一组具有代表性的手写数字图片测试识别结果(包括识别效率及识别精度),结果如表1所示。

表1 传统MLP、CNN与改进MLP实验结果
3.3 实验结果分析及讨论
对比表1中的数据,在相同的实验条件下,改进MLP模型在测试集上可以达到98.04%的准确率。相比传统的MLP模型,准确率由91.19%上升到98.04%,识别效率由39.3s提升到了12.0s,对识别银行账单这种精确度要求很高的场景,是飞跃性的提高。
对比表1中后两行数据可知,在相同的实验条件下,虽然卷积神经网络(Convolutional Neural Network,CNN)在识别精度上有一定优势,但这是以增加网络层数和运行时间为代价得到的。因此,实际应用中,改进的MLP网络模型更具实时性。
对比图3中SGD及Adagrad优化效果曲线可知,随着迭代次数(Steps)的增加,使用Adagrad优化方法的识别误差(Loss)比使用SGD更小,优化效果更好,从而能有效地提高识别精度和识别效率。
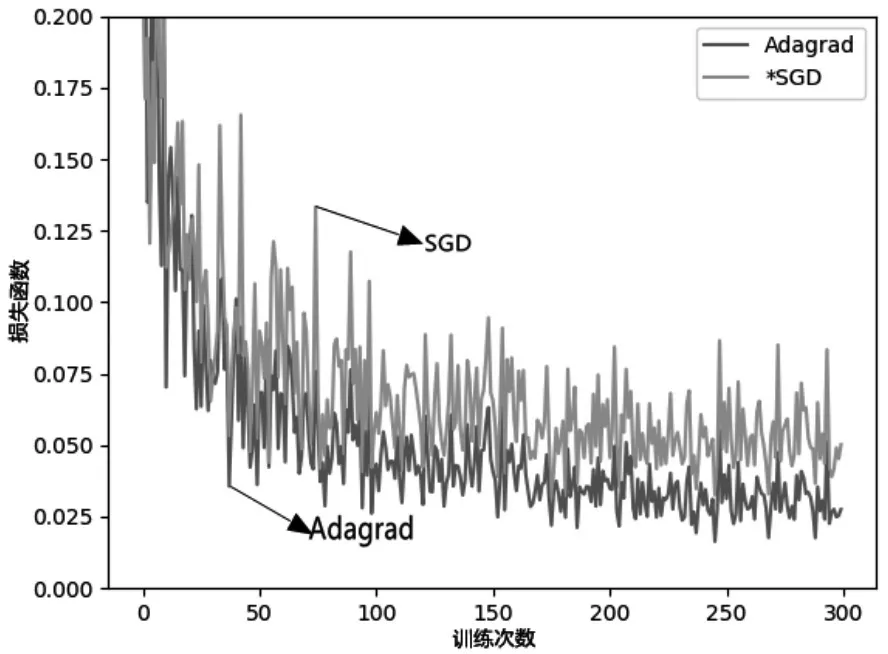
图3 SGD及Adagrad优化效果对比
对比图4及图5中训练及测试误差曲线可知,当训练中keep_prob=1时,出现了过拟合(Overfitting)问 题。keep_prob=0.75( 即 drop掉 25%) 时,Dropout发挥了作用。

图4 keep_prob=1时,train、test误差

图 5 keep_prob=0.75,train、test误差
对比图4中训练及测试误差曲线可知,当keep_prob=1时,模型对训练数据的适应性优于测试数据,存在过拟合。
对比图5中训练及测试误差曲线可知,当keep_prob=0.75(即drop掉25%)时,效果好了很多,基本不存在过拟合问题。
4 结 语
本文提出利用TensorFlow软件平台实现基于MLP模型的手写数字识别,同时引入Dropout、Adagrad、ReLU等改进MLP模型结构,采用MNIST标准数据集设计相应实验,并验证了该改进算法的有效性。实验结果表明,相对传统的MLP模型,改进的MLP模型能够自动学习有效特征并进行识别,识别准确率提高了将近7.0%,识别效率提高了27.3 s;自适应学习速率的Adagrad相比SGD具有更好的优化效果,显著提高了识别效率,节省了大量处理时间;Dropout在解决过拟合方面具有良好的效果;ReLU有效解决了梯度弥散问题,从而能够有效提高识别率。
