基于改进FOA优化的CS-SVM轴承故障诊断研究
2018-09-28何大伟彭靖波胡金海李腾辉贾伟州
何大伟, 彭靖波, 胡金海, 李腾辉, 贾伟州
(空军工程大学 航空航天工程学院,西安 710038)
诊断是以机械学和信息论为依托、多学科融合的技术,本质是模式识别[1]。现代机械设备结构复杂、故障率高,且故障征候难以判断,无法完全依靠传统方法建立精确的物理模型进行管理监控[2],同时,机械设备在实际的运行过程中会随时间产生大量的性能参数数据。通常情况下,对象的性能参数与其运行状态具有一定联系,例如在航空发动机的运行过程中,其性能参数在不同的工作状态下表现出不同的函数形式和映射关系[3],因此基于数据驱动的故障检测方法不仅有效、合理,同时,能避免基于模型方法要求的模型必须定量、准确等缺点,已成为研究的热点[4-5]。
SVM(Suppot Vector Mechine)算法使用结构风险最小化准则构造决策超平面,在处理高维样本时具有较高的精度和泛化能力[6],由于其应用性强和拓展空间较大的特点,目前已广泛应用在机械故障诊断研究领域。文献[7]提出了一对一SVM多分类方法,并对轴承故障进行了有效诊断;文献[8]基于SVM研究了轴承故障检测方法,提高了轴承故障的诊断精度。但上述方法的基本假定前提是每个样本的误分类代价相等,在实际故障诊断中,该假设一般情况下难以满足,同时,由于故障类样本数量远少于正常类样本,且当故障发生时,设备已无法进行工作,会造成样本类数据不平衡的问题[9],这在航空发动机轴承的故障诊断中尤为显著。
在样本类不平衡的问题中,SVM分类算法会在多数据类样本中产生过拟合[10],忽略样本数少的类别。针对这一问题,文献[11]基于代价敏感的半监督Laplacian支持向量机在7个UCI 数据集和8个NASA 软件数据集上有效解决数据集的不平衡性问题,文献[12]研究基于委员会投票选择(Modified Query By Committee,MQBC)和代价敏感支持向量机(Cost-Sensitive Support Vector Machine,CS-SVM) 的故障检测方法,提高了CS-SVM对类不平衡样本的故障检测率。
上述文献对基本CS-SVM进行了改进,提高了对类不平衡样本的识别准确率,但在CS-SVM的参数选取中具有随机性,且未证明其合理性。在CS-SVM算法中,核函数参数的选择是至关重要的,传统的SVM参数大都由人工设定,凭借的只是个人经验,通常需要做多次试验,才能选择一个较为合适的参数,不仅耗时费力,得到的参数可能仍然不是最优参数[13],针对此问题,本文提出利用改进FOA算法优化CS-SVM参数,并结合随机共振、KPCA(Kemel Principal Component Analysis)特征提取方法,对IMS(Intelligent Maintenance Systems)航空轴承数据进行测试,为有效提高轴承故障诊断和预测正确率提供思路和手段。
1 代价敏感支持向量机及其参数
1.1 基本支持向量机
Vapnik[14]在20世纪60年代对有限样本情况下的机器学习进行了研究,限于理论研究瓶颈,并未将其付诸实践,直到20世纪90年代,随着统计学习理论的逐渐成熟,SVM成为了一个较完善的机器学习方法。SVM最优超平面分类原理,如图1所示。
按照确定的非线性映射将样本集向量{xi},i=1,2,…,n映射至高维特征空间Z, 即φ:Rm→Z,x→φ(x), 则训练集能被一个最优超平面H:w·{φ(x)}+b=0准确无误地分为两类
(1)
式中:H1与H2为两个平行于H且平面之间无样本点、距离最大的超平面,此距离称为分类间隔,其值为2/‖w‖;ξi≥0;为松弛量。
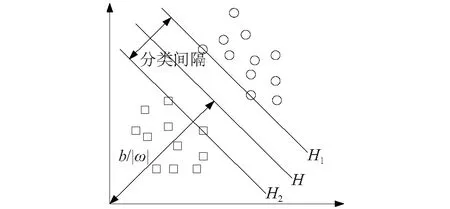
图1 支持向量机最优超平面分类原理图Fig.1 The diagram of SVM optimal hyper-plane classification principle
为使两超平面之间的分类间隔最大且无样本点,则约束方程描述为
yi({ω}{φ(xi)}+b)-1+ζi≥0,i=1,2,…,n
(2)
1.2 代价敏感支持向量机
求解最优分类超平面H就是求解
(3)
式中:C为规则化常数,即经验风险与VC维复杂性之间的权衡。
建立此凸二次规划优化问题的Lagrange函数, 对式中{ω},b,ξi求偏导并令其为0, 可推导其Lagrange函数的对偶形式及其对应的决策函数。
对于ξi=0的标准支持向量,有
{ω}{φ(xi)}+b=1
(4)
即满足
(5)

(6)
则满足稳定性的阈值为
(7)
在故障诊断中: 一方面是正常类样本数量远多于故障类;另一方面是考虑到将故障类错分为正常类的危害性远大于将正常类错分为故障类,因此要对正、负类样本分别采用不同的规则化常数C+,C-[15],此时对应的最优分类超平面H优化问题为
(8)
式(4)~式(8)联立即可得到代价敏感支持向量机(CS-SVM)。为了使CS-SVM模型更加聚焦于数量少的故障样本,降低将故障样本错分为“正常”的错分率,则需要将数量较少的故障类别样本集对应的规则化常数C+或C-取值增大,即增大故障类样本错分代价。
2 基于改进FOA优化的CS-SVM
2.1 果蝇优化算法
果蝇优化算法FOA(Fly Optimization Algorithm)[16]是根据果蝇觅食行为提出的优化算法。作为一种新型进化算法,相比蚁群算法、遗传算法、鱼群算法等其他传统优化算法具有参数设置少、程序实现简单和运算速度快等优点,在科学和工程领域都得到了应用。
2.2 基于混沌优化的FOA改进策略
果蝇优化算法的本质为果蝇依靠嗅觉搜索食物源并逐渐向食物方向靠近[17],果蝇群体搜索食物源的过程,如图2所示。
步骤如下:
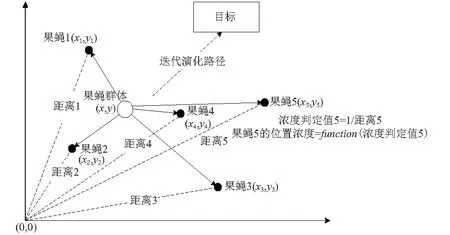
图2 果蝇群体搜索食物的过程Fig.2 The diagram of FOA algorithm
步骤1初始化FOA算法参数;

(9)

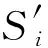
(10)
(11)
步骤5找出浓度值最大个体的位置
(12)
步骤6保留最大浓度位置并更新群体位置(X′,Y′);
步骤7进入迭代寻优,重复执行步骤2~步骤6,并判断味道浓度是否优于前一迭代味道浓度,直至迭代次数达到最大迭代数。
尽管果蝇算法有诸多优点,但通过分析可知,其搜索步长为固定值,根据介值相关理论[18],在实际优化问题中,较优解周围可能存在更优解,从而易陷入局部最优,因此为了改进由于固定步长取值带来的全局搜索与局部搜索能力的不足,提出利用混沌搜索方法[19],在步长选取前进行混沌优化,从而避免陷入局部最优。
Logistic映射系统模型如下
zk+1=f(m,zk)=mzkg(1-zk),zk∈[0,1]
(13)
当μ=4时,系统处于混沌状态。具体IFOA(Improved Fly Optimization Algorithm)的实现策略如下:在初始化FOA参数,进行完第一次浓度计算后,对果蝇种群个体随机生成两个n维变量。
根据混沌模型式(13),将得到的(a2,b2)各个分量载波至扰动范围[-d,d],则扰动量式(14)、搜索步长增益式(15)如下
(14)
(15)
(16)
将改进策略加入果蝇优化算法,则式(9)改进为
(17)
根据算法的改进, 改进FOA算法在每次迭代时,步长将执行一次混沌搜索,全局寻优能力增强,随着进化代数的增加,将避免陷入局部最优,更好实现全局搜索。
2.3 基于IFOA算法的CS-SVM参数优化机制
本文提出采用改进IFOA算法对CS-SVM规则化常数C+,C-与核函数参数g进行优化选取。参数选择步骤如下:
步骤1初始化FOA参数;
步骤2根据群体的当前位置,获取C+,C-及g值;并利用训练数据建立CS-SVM分类模型,再利用测试数据计算适应度函数,并考虑适应度函数的奖励与惩罚机制输出得到适应度函数值;
步骤3根据最佳浓度函数更新果蝇种群中最佳个体的浓度;并更新果蝇种群的位置;
步骤4基于混沌搜索理论对FOA算法的优化策略,对果蝇种群的位置进行更新,实现全局寻优;
步骤5判断算法收敛准则是否满足。如不满足收敛准则,则转步骤2;如满足收敛准则,则输出最优参数C+,C-及g,算法结束。
3 应用实例与分析
3.1 改进FOA算法验证性分析
为了测试所提出算法的寻优性能,选取遗传算法(Genetic Algorithm,GA)、粒子群优化算法(Particle Swarm Optimization,PSO)、FOA和IFOA,通过测试函数进行对比仿真,本文在此仅列举Sphere函数的测试结果。
Sphere函数
(18)
该函数在(0,…,0)处取得最小值0。
测试函数的复杂度会随着维数和迭代次数的增加而增加,适合测试算法的寻优性能。四种算法参数设置基本保持一致,同时考虑到果蝇算法与其他智能算法之间可能存在的最优种群参数带来影响,迭代次数iter依次选取为50,100,150,200, 种群规模N依次选取为10,20,30,40,50。iter=200,N=50的测试结果如图3所示。

图3 Sphere函数的收敛曲线Fig.3 The convergence curve of Sphere
由测试结果可知,IFOA算法相较于其它智能算法表现出较好的收敛速度和精度,GA算法虽然前期收敛较快,但后期不稳定。其他组合种群参数的收敛结果与此趋势相同,限于篇幅不在列出,由此确定了IFOA算法在寻优过程中的优越性。
3.2 基于IMS航空轴承试验数据的验证分析
通过美国辛辛那提大学智能维护中心(IMS)的航空轴承疲劳寿命试验数据[20]对“2.3”节方法所提方法进行验证。IMS航空轴承疲劳寿命试验机由主体部分、传动部分、加载系统、润滑系统及控制电路等组成,其结构示意图如图4所示。试验轴上安装着4个试验轴承。交流电机驱动试验轴,试验转速为2 000 r/min。径向载荷为26.67 kN。

图4 IMS航空轴承试验台结构示意图Fig.4 The structure diagram of IMS aviation bearing test
试验轴承为ZA-2115双列腰鼓形滚子轴承。每列含16个滚子,节圆直径为71.501 mm,滚动体直径为8.407 mm,压力角为15.17°。振动信号通过安装在轴承座上的PCB(Printed Circuit Board)的高灵敏度ICP(Integrated Circuits Piezoelectric)加速度传感器353B33进行监测,同时选用4个热电偶温度传感器监测轴承温度和润滑情况。振动信号利用NI公司的DAQCard-6063E数字采集器记录,采样频率为12 kHz。
在机械故障诊断系统中,有效值通常用于描述振动信号的能量,是信号的二阶矩统计平均,有效值Xrms又称为均方根值
(19)
考虑到轴承方根幅值与有效值Xr在反映轴承运转状态上的相似性及目前体现方根幅值的研究内容较少,本文选用方根幅值来对轴承振动的异常情况进行表示,方根幅值计算公式
(20)
由于轴承在发生故障前已存在故障征候,真实故障点在试验中无法准确识别,为了实现模型对轴承故障的预测,需要人工提前设定故障预判点,以试验1的 3#轴承内圈故障数据为例进行分析。图5为该轴承的方根幅值在全寿命期内的变化趋势,本文设定故障预判点如图5所示。故障预判点到轴承停止工作点的时长为轴承内圈故障的总时间,即故障类样本时间为44 100~47 700 min,正常样本时间为0~44 100 min,有效试验采样间隔为20 min采样1次,选取正常类样本900组,故障类样本153组,选取的故障类样本主要为故障征候区域样本。

图5 IMS航空轴承试验1的3#轴承的方根幅值Fig.5 The root amplitude of IMS 1st No.3 aviation bearing
为提高预测准确率,需剔除轴承信号中的噪声影响,首先采用经改进免疫粒子群优化参数的随机共振预处理方法[21]对轴承振动信号进行降噪处理,提取时域、频域、时频域特征[22],通过振动信号描述转子工作状态的指标众多,本文选择了8个常用的基于统计特性的指标
{Pt1,Pt2,TV,UV,Cf,If,Clf,Sf}
(21)
式中:Pt1为绝对平均值;Pt2为均方值;TV为歪度指标;UV为峭度指标;Cf为峰值指标;If为脉冲指标;Clf为裕度指标;Sf为波形指标。以上8个原始特征无量纲指标形式简单、数量有限,且可分性指标较差,图6列出了Pt1,Pt2的可分性关系。
为能更好构造和选择轴承故障本质的特征参数,利用KPCA法[23]进行特征提取,计算选取贡献率最高的两类特征,得到新的特征集:KPC1,KPC2,并进行归一化处理,投影至二维平面如图7所示。
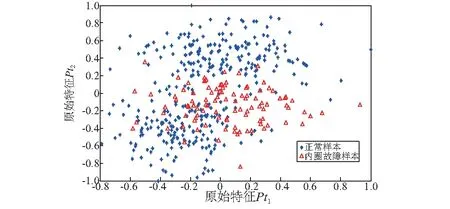
图6 试验1的3#轴承原始特征Pt1,Pt2的2维平面投影Fig.6 The 2D plane projection of IMS 1st No.3 aviation bearing original Pt1 and Pt2 feature
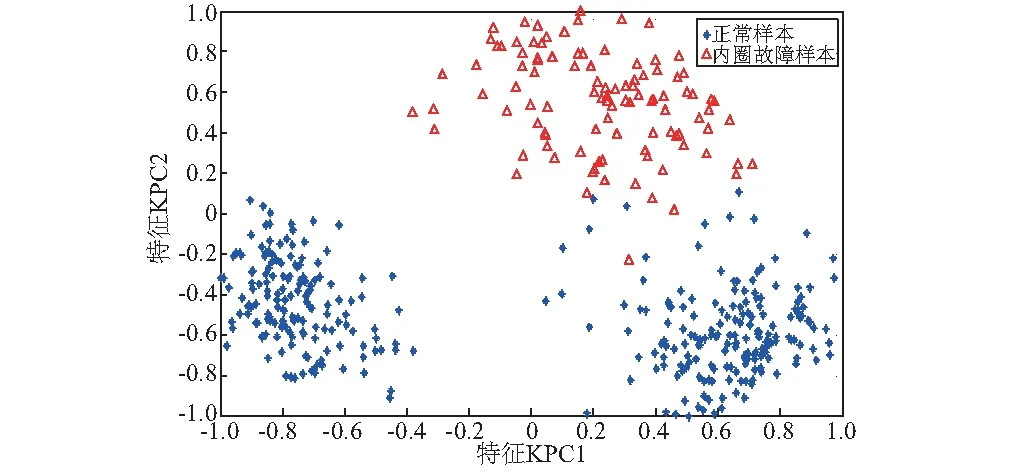
图7 经随机共振预处理的试验1的3#轴承KPCA特征2维平面投影Fig.7 The 2D plane projection of IMS 1st No.3 aviation bearing original feature
表1为图6、图7两种特征集的可分性参数比较,可分性数值越大代表可分性越好,经所选预处理方法处理后的特征具有更好的可分性,有利用后期轴承故障征候识别。

表1 不同特征集的可分性指标
在CS-SVM训练及测试中,将上述经预处理的900组正常样本归为正类(yi=1),将153组内圈故障样本归为负类(yi=-1),选择各正类、负类样本的2/3样本作为训练集,剩余1/3样本作为测试集。
采用所提出的IFOA算法对CS-SVM模型进行参数优化。取果蝇种群规模为50,初始步长为30,最大迭代次数为200,选择测试正确率作为适应度函数,C+,C-及g的寻优范围设为[0.01,1 000]。
3.2.1 IFOA优化的CS-SVM方法验证
在诊断模型建立阶段分别采用CS-SVM、基本SVM方法进行测试验证。由于故障类样本错分代价高于为正常类错分代价,因此需提前确定好C-与C+的关系。通常采用的方法是将两类样本数目的反比作为惩罚参数之比,即IR(Imbalance Ratio)方法[24],但是在IR中使用样例的数目之比来弥补分类器的偏斜程度具有一定的局限性,因为数据的不平衡程度可能并不仅仅取决于两类样例的数据差异,也可能和样例在空间中的分布相关。
为此本文采用基于样本总体的平均密度选取参数的 AD(Average Density)法[25],对试验1的 3#轴承内圈故障全寿命期数据进行计算,按照图5划分的正常类和故障类样本确定C-与C+的比例关系:C-=1.4C+,在此比例关系基础上进行寻优计算。
对预处理后数据采用所提IFOA算法优化得到的CS-SVM参数为C+=141.575,C-=198.205,g=160.941 6, 总诊断正确率为86.03%(302/351); 正类正确率为89.67%(269/300); 负类正确率为64.71%(33/51), 即在故障类样本中有35.29%的错分率。
预处理方法不变,采用IFOA优化基本SVM参数为C=67.202 9,g=0.747 68, 总诊断正确率为83.19%(292/351); 正类89%(267/300); 负类49.02%(25/51), 即在故障类样本中有50.98%的错分率。
未经预处理,采用IFOA算法优化基本SVM算分,得到参数为C=104.698 4,g=6.785 1, 总诊断正确率为69.52%(244/351); 正类74%(222/300); 负类43.14%(22/51),即在故障类样本中有56.86%的错分率,分类结果如表2所示。

表2 不同方法的诊断结果比较(900∶153)
综上所述,对于相同模型(如基本SVM)而言,采用本文所提出的预处理方法提高了正类、负类及总体的诊断正确率;对于相同的预处理特征,所提的CS-SVM方法与基本SVM相比,在保证正类和总体样本诊断正确率基本不变的情况下,提高了数量较少、错分代价更高的故障类样本的诊断正确率。测试集真实类别与模型诊断类别的比较,如图8~图10所示。
3.2.2 不平衡样本比例及不同方法的验证性分析
本节验证所提的CS-SVM方法对不同比例的正、负类样本诊断效果。为便于比较,以下仍分别采用CS-SVM和基本SVM方法进行测试验证。
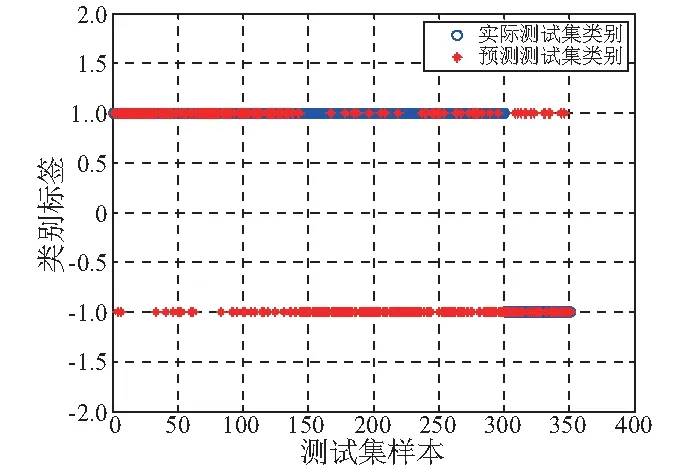
图8 原始特征+改进FOA+基本SVM诊断结果Fig.8 The result of original characteristics+ IFOA+basic SVM classification

图9 自适应SR+KPCA+改进FOA+基本SVM诊断结果Fig.9 The result of adaptive SR+ IFOA+ basic SVM classification

图10 自适应SR+KPCA+改进FOA+CS-SVM诊断结果Fig.10 The result of adaptive SR+ IFOA+CS-SVM classification
由于仍采用试验1的 3#轴承内圈故障数据作为研究对象,C-与C+的比例关系:C-=1.4C+保持不变。分别采用正、负类样本数比为5∶1,4∶1,3∶1,2∶1,1∶1五种不同比例对CS-SVM与基本SVM进行验证,所采用的预处理方法不变:首先采用自适应随机共振方法进行去噪、提取特征值,随后利用KPCA方法对特征值进行变换得到KPCA特征集。
由图11的趋势分析可知,随着样本不平衡比例的逐渐增加,两种方法对于正类、负类和总体样本的诊断正确率都会随之降低;但所提CS-SVM的方法相较于基本SVM算法具有更高的诊断正确率,且受样本不平衡性的影响较小,具有较强的泛化能力。基本SVM与所提CS-SVM对不同样本类比例的诊断正确率,如表3所示。

图11 不同方法在不同比例样本集上的诊断结果Fig.11 Different diagnosis methods in different proportions of imbalance sample set
综上所述,所提的CS-SVM方法与基本SVM相比有效提高了对故障类样本的诊断正确率,同时还能保证正常类样本和总体诊断正确率略有增加或基本不变。所提的基于IFOA优化的CS-SVM方法能有效处理类不平衡样本问题,更适合处理与轴承故障类似的故障类样本少、样本类数据不平衡以及错分代价不相同的样本集。
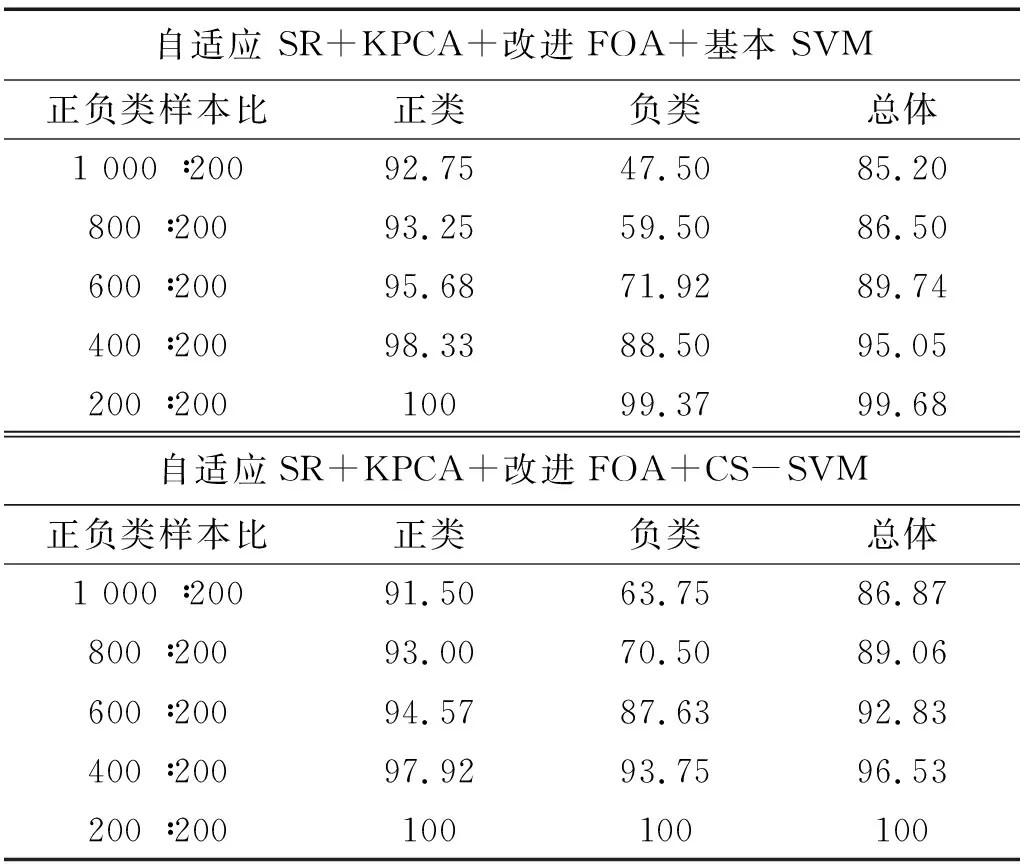
表3 不同方法在不同比例样本条件下的诊断结果
4 结 论
通过对IMS航空轴承试验数据的分析比较可知:采用自适应SR信号预处理以及KPCA特征提取,可提高信号质量和特征效果,从而提高发动机轴承故障诊断正确率;所提的IFOA优化的CS-SVM方法能有效处理误分类代价不同、不平衡、小样本条件下的轴承诊断问题,提高误故障类样本的诊断正确率。
同时,本文提出的方法主要针对二类分类问题,对于实际的多类分类问题,需要以二分类问题为基础,将多类别的分类问题转换为若干二分类问题的组合,采用一对余、一对一等以二分类为基础的多分类方法进行处理,在今后的研究中,将该方法尝试应用在多分类问题中,以期取得更好的多分类效果。
