基于双神经网络通道的时间序列预测框架∗
2018-09-27吴双双宋恺涛陆建峰
吴双双 宋恺涛 陆建峰
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
时间序列是按照时间顺序采样得到的一系列有序数据,它描述了某个变量随着时间的推移而变化的规律。近年来,时间序列预测在金融[1~2]、交通[3]和能源[4]等多个领域都得到了广泛的应用。时间序列预测方法主要分为两类,一类是传统的基于数学建模的预测方法,如经典的自回归积分滑动平均(Auto Regressive Integrated Moving Average,ARI⁃MA)模型[5]。另一类是基于机器学习的时间序列预测方法。传统时间序列方法根据时间序列直接建模,模型较为简单易用。在实际应用中,由于时间序列具有不规则、混沌等非线性特征,很难对其建立理想的模型来进行预测。机器学习方法的输入不限于单一的时间序列输入,而是可以根据具体应用场景,选取可能影响预测值的特征。因此,基于机器学习的时间序列预测方法往往能取得更高的预测精度。神经网络作为一种常见的机器学习工具,具有自组织、自学习以及强大的非线性逼近能力,将它用于时间序列预测时,往往能够取得较好的结果。目前,已经有多种神经网络模型被用于时间序列预测,包括径向基(Radial Basis Function,RBF)网络[6]、多层感知机(Multilayer Perceptron,MLP)[7]和回声状态网络(Echo State Network,ESN)[8]网络等。此外,为了提高时间序列预测方法的预测精度并增强其适用性,Bates等提出了组合模型来对时间序列进行预测的思想。文献[9]提出了同时使用ARIMA模型与配备权值及结构确定(weights and structure determination,WASD)算法的幂激励前向神经网络对时间序列进行建模和预测。文献[10]提出了一种组合深度信念网络(Deep Belief Net,DBN)和ARIMA模型的时间序列预测方法。
本文采用组合方法的思路,提出了一种组合卷积神经网络和循环神经网络的双通道时间序列预测框架。卷积神经网络(Convolutional Neural Net⁃work,CNN)在各种视觉任务中的巨大成功已经展现出了其强大的特征提取能力[11~12]。循环神经网络(Recurrent Neural Network,RNN)引入了时序概念,比起无循环的前向网络结构,能够更好地处理时序分析问题[13]。在所提框架中,利用卷积神经网络通道的卷积和池化操作提取出时间序列的深层特征,利用循环神经网络通道的记忆单元提取出长序列依赖特征,然后将两个通道所提的特征合并后输送到全连接层得到最后的输出。
2 相关理论
2.1 卷积神经网络
主要介绍针对一维输入特征向量的卷积神经网络的卷积操作。用x∈Rn表示输入向量,用w∈Rk表示长度为k的一维卷积核参数。为了使卷积操作后得到的向量与输入向量具有相同的维度,我们用边缘值扩展x向量,扩展后的x∈Rn+k-1,用x[i:i+k]表示x向量的第i到第i+k个值。设定卷积步长为1,对输入向量x的子向量重复应用卷积核操作:

其中,i=1,…,n,·表示内积运算。单个卷积核对x操作后得到一个长度为n的向量o。我们对每个输出oi添加一个偏置项b∈R和一个激活函数f,得到最后的特征图c∈Rn,其中

对于同一个输入向量x,我们可以使用多个卷积核,目的是让每个卷积核都学到尽量互补的特征。同时,对于卷积核的大小我们也可以做不同的选择。
2.2 循环神经网络
RNN是一种通过维持内部隐藏状态来对任意长度的动态时间序列行为进行建模的神经网络,内部的隐藏状态是通过隐层神经元的定向循环连接实现的。它可以被认为是一个隐马尔可夫模型的扩展,采用非线性转换函数,并能够建模长时序依赖关系。一个最简单的RNN结构如图1。图1中左边为RNN未展开时候的结构,右边为RNN展开后的结构。st为隐藏层的第t步的状态,它是网络的记忆单元。ot是第t步的输出,xt为第t步的输入。展开后的RNN与传统神经网络的唯一区别在于,RNN中每一层的参数U,V,W都是共享的,而传统神经网络中每一层的参数都是不同的。图1中每一步都会有输出,但是每一步都要有输出并不是必须的。
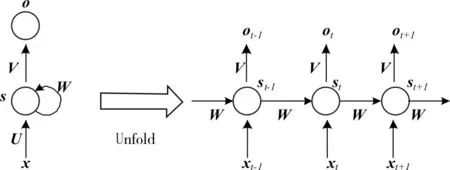
图1 RNN结构
原生的RNN在训练时容易出现梯度消失的问题,因此在大多数应用中,都使用RNN的改进版本长短期记忆(Long Short-Term Memory,LSTM)网络来代替原RNN。LSTM在RNN的基础上加入三个门来控制信息流入输出:一个遗忘门f来控制先前信息的输入比例;一个输入门i来控制当前信息的输入比例;一个输出门o来控制输出状态。这些门使得LSTM能够学习到一个序列中的长期依赖关系,因为这些门帮助输入信号有效地通过隐层记忆状态r传播而不影响输出。LSTM神经元的公式如下:

公式中W∈Rm×n,U∈Rm×m,b∈Rm为要学习的参数,其中m为隐层神经元的个数,n为输入向量的维数。◦为逐元素相乘操作,σ为激活函数,r͂t为候选的记忆状态。通过遗忘门 ft控制上一状态的影响和输入门it控制候选状态的影响得到最终的记忆状态rt。ht是隐层的输出,其由输出门ot和记忆状态rt共同决定。图2是对LSTM神经元更直观的展示。

图2 LSTM神经元内部结构
3 双通道框架
3.1 总体架构
本文所设计的双通道框架如图3。框架分为CNN和RNN两个通道,两个通道并行提取出输入序列的特征,得到两个特征向量p和q。为了平衡两个通道对最后预测结果的影响,将p和q向量的维度都设定为d。两个通道提取出的p和q向量最后连接到全连接层得到输出y。

图3 双通道框架
3.2 CNN通道
本文设计的CNN通道构造如图4所示。图中n1为第一个卷积层中卷积核的个数,n2为第二个卷积层中卷积核的个数。CNN通道主要由卷积层和池化层组成。卷积层是通道中最核心的单元,通道包含了两个卷积层,第一个卷积层提取出时间序列的低阶邻域特征,第二个卷积层将低阶邻域特征组合成高阶的复杂特征。每个卷积层后加入最大值池化层以减少模型参数,同时增强模型鲁棒性。CNN通道最后连接了一个全连接层,将CNN提取到的特征映射到一个长度为d的向量上,方便后面将双通道的特征合并。
3.3 RNN通道
Google mind团队在2014年发表了一篇使用注意力(attention)机制的RNN模型来进行图像分类的论文[14],引起了研究人员对于attention机制的关注。attention机制的原理是模拟人脑的注意力模型。当人脑在分析某个事物时,虽然得到的是关于这件事物的全貌,但是在我们想要获得这件事物的相关信息的时候往往注意的是这件事物的某些部分。在时间序列问题中也存在类似的问题,即所要预测的值并不是均衡地依赖所有历史时间序列的值,而是有侧重地依赖某几个时间点上的值。因此本文在RNN通道中加入attention机制,以提高原RNN通道的预测精度。

图4 CNN通道构造

图5 RNN通道构造
本文所设计RNN通道的构造如图5所示。原RNN模型中,只使用最后一个时间步上LSTM层的输出hn进行预测,加入了attention机制后的RNN模型能够有偏重地考虑每一个时间步上的输出。本文所设计的attention机制公式如下:

4 实验
4.1 数据集
实验所用的数据集来自于EEM2016举办的能源价格预测比赛,可以从 http:∕complatt.smartwatt.net上下载到。该数据集是一个描述市场上某个现货价格的数据集,时间从2015年1月1日00:00开始,到2016年4月27日21:00结束,以小时为单位。数据集一共有11590个时间点的数据,将最后的2000个数据点作为测试集来评价算法有效性,其余时间点用来训练网络。
4.2 评价指标
实验中用到了三个回归问题中的常用评价指标:均方根误差(RMSE),平均绝对误差(MAE)和平均相对误差(MRE)。均方根误差是观测值与真值偏差的平方与观测次数l比值的平方根,用来衡量观测值同真值之间的偏差。平均绝对误差是所有观测值与真值偏差的绝对值的平均。与平均误差相比,平均绝对误差由于偏差被绝对值化,不会出现正负相抵消的情况,因而,平均绝对误差能更好地反映预测值误差的实际情况。平均相对误差是所有观测值与真值偏差除以真值的绝对值的平均,是一个衡量偏差的相对量。三个评价指标的公式如下:

其中,l为测试样本的总量,yi为第i个数据点的真实值,ŷi为第i个数据点的预测值。
4.3 实验配置
实验中用到的CNN通道和RNN通道配置分别见表1和表2。

表1 CNN模块配置
配置表中maps表示卷积核数量,k,s,p分别表示卷积核长度,步长和填充大小,windows表示池化层窗口大小。Dense层为全连接层,units为神经元的个数。输入序列长度n的设置为12。用来合并两个通道的全连接层的神经元个数设置为8。

表2 RNN模块配置
4.4 模型训练
双通道模型本质上也是一个神经网络,可以定义损失函数后,用BP算法进行参数学习。但是考虑到CNN和RNN的构造存在一定的差异,有时难以选择一个合适的学习步长和学习方法来对整个网络的参数进行训练。实验中也发现,网络的整体训练经常出现难以收敛的情况,一方面是因为参数的初始值选取不当,另一方面网络过于复杂也会增加出现这种情况的概率。因此,借鉴机器学习中的stacking模型融合方法,提出一种分层训练方法。此外,分层训练方法存在另一个优势,即可以对两个通道进行并行训练,节约训练时间。具体步骤如下:
Step1:将数据集划分为两个互不相交的子集Dataset1和Dataset2;
Step2:用Dataset1分别训练CNN模型和RNN模型;
Step3:用训练好的CNN模型和RNN模型对Dataset2的数据进行预测;
Step4:将step3得到的中间结果,即两个模型全连接层的输出p和q整合为新的输入特征;
Step5:将step4得到新的输入特征和对应的真实输出值作为训练样本,训练用来融合双通道的高层神经网络;
Step6:将step2训练好的双通道模型参数和step5训练好的高层神经网络参数复制到整体框架中。
4.5 attention实验对比
为了验证引入attention机制的改进RNN的效果,将改进模型与原RNN模型进行效果对比。将改进后的模型简称为RNN_attention模型。表3为RNN与RNN_attention在2000个测试点上的预测效果对比。从表中可以看出,添加了attention机制的改进模型能够取得比原RNN模型更好的效果。为了有更直观的展示,选取测试集中前100个时间点,将真实值与两个模型预测值的曲线展示在图6和图7中。可以看出,图6中灰线的RNN预测曲线可以基本拟合真实值曲线,但是在某些时间点上的预测结果仍然存在较大的偏差。图7中灰线曲线的RNN_attention预测曲线比起图6中的灰线拟合效果更好,在绝大多数时间点上的预测结果都要优于RNN。从而可以得出结论,attention机制能够使RNN模型更加关注那些对预测结果有影响的时间步上的输出,从而提高RNN模型的预测精度。

表3 RNN模型与RNN_attention模型预测效果对比

图6 RNN与Ground Truth对比图

图7 RNN_attention与Ground Truth对比图
4.6 双通道实验对比
为验证双通道框架的有效性,将双通道模型与单通道模型进行对比。将2000个测试点分成十组,每组200个数据,每组分别计算RMSE、MAE和MRE的值,结果见表4。从表中可以看出,在十组预测结果中,双通道模型预测结果大多数时候都能取得优于单通道模型的预测结果。图8和图9展示了前200天单通道和双通道的绝对误差对比图。在两张对比图中,双通道预测误差要整体低于单通道预测误差。并且可以看出,在预测误差出现峰值的地方,黑线曲线代表的单通道预测误差值通常要高于灰线曲线代表的双通道预测误差值,这是因为双通道模型能够综合考虑两个通道的特征,对预测结果进行权衡。因此当某个通道的预测结果出现了较大偏差时,双通道框架能够考虑到另一个通道的特征,从而使最后的预测误差不会太大。

图8 CNN模型与双通道模型绝对误差对比

表4 单通道与双通道结果对比

图9 RNN模型与双通道模型绝对误差对比
5 结语
本文提出了一种用于时间序列预测的双神经网络通道框架,具体而言,框架利用CNN通道提取深层时序特征,利用RNN通道提取长时序依赖特征,然后将两个通道所提取的特征合并后输送到全连接层得到最后的输出。另外,本文对RNN通道进行改进,将attention机制引入RNN,相比于原RNN只使用LSTM层最后一步的输出信息进行预测,改进后的RNN能够有偏重地考虑所有时间步上的输出。真实数据集上的实验表明,所提的双通道框架能够取得比单一的CNN框架和RNN框架更高的预测精度。
