基于变分循环自动编码器的协同推荐方法
2018-09-26李晓菊顾君忠
李晓菊 顾君忠 程 洁
1(华东师范大学计算机科学与技术系 上海 200062)2(上海智臻智能网络科技股份有限公司 上海 201800)
0 引 言
随着信息技术和互联网的发展,人们逐渐从一个信息匮乏的时代步入了信息过载的时代。在一些电子商务平台,由于商家提供的商品种类繁多,用户很难快速地从大量的商品信息中发现对自己有价值的信息,而个性化的推荐系统就是解决这一问题的有效工具。推荐系统可以联系用户和商品,让特定商品能够展现在对它感兴趣的用户面前,节省用户精力,提高用户满意度,并且最大化商家利益。近年来,越来越多的推荐方法相继被提出,根据模型构建方式,可分为三大类:基于内容的推荐方法[1]、基于协同过滤的推荐方法[2]和混合推荐方法[3-4]。
在上述推荐方法中,协同过滤是应用最广泛的算法。协同过滤算法的核心思想是:利用用户的历史反馈数据来挖掘用户的喜好,将用户划分群组,并为其推荐与其偏好相同的用户所喜欢的物品。随后,基于物品的协同过滤算法[5],基于用户的协同过滤算法[6]和基于矩阵分解的协同过滤算法[7]相继被提出。其中,基于矩阵分解的协同过滤算法(如概率矩阵分解)因其扩展性好,灵活性高等诸多优点,得到了越来越多研究者的关注。
PMF(概率矩阵分解)[8]的核心思想是:将用户-商品的评分矩阵分解成两个服从高斯分布的低维矩阵:用户特征矩阵和商品特征矩阵,通过重构这两个低维矩阵来预测用户对商品的评分。概率矩阵分解模型对推荐对象没有特殊要求,不需要领域知识,能发现用户潜在的兴趣爱好。但是由于该模型只利用了评分矩阵,在评分数据非常稀疏的情况下,预测准确性会下降。
鉴于概率矩阵分解中的稀疏问题,一些学者提出可利用除评分数据以外的信息(如商品的描述文本)来提高推荐性能。近年来,深度学习已经在计算机视觉[9]和自然语言处理领域[10]中取得突破性的进展,深度学习模型对文本的挖掘能力恰好适用于商品文本内容上,一些研究者[14]提出将深度学习模型与推荐系统相结合,将深度学习模型应用到商品的文本内容中,再与评分数据联系起来,以缓解矩阵分解中的稀疏问题。
本文提出一种基于变分循环自动编码器的概率矩阵分解模型(vraeMF),该方法使用无监督的深度学习模型对商品的描述文本进行编码,得到一个低维并且服从高斯分布特征向量,作为该商品的初始特征向量,然后将其融合到PMF中来缓和稀疏问题。在编码特征向量时,我们考虑了文本的上下文信息和语义信息,并且利用变分自动编码器的思想,提取出来的特征向量服从高斯分布。
1 相关工作
1.1 基于协同过滤的推荐方法
协同过滤是推荐系统中应用最广泛的方法,可分为基于邻域的协同过滤和基于模型的协同过滤。基于邻域的协同过滤算法通过用户的历史反馈数据将用户(或商品)划分群组,找到与目标用户(商品)最为相似的其他用户(商品),然后利用与目标用户(商品)相似度高的邻居来预测用户感兴趣的商品列表。该算法主要包括基于用户的协同过滤和基于商品的协同过滤两类。基于用户的协同过滤算法核心是找相似用户,基于商品的协同过滤找相似的商品。
基于邻域的协同推荐早期研究很多,随着推荐系统的发展,基于模型的协同过滤收到越来越多的关注。其中矩阵分解(包括SVD[12]、PMF等)是基于模型的协同过滤中应用最广泛的方法。SVD算法假设用户对商品的评分只受到少数几个特征因子的影响,先将用户和商品映射到相同的特征空间中,再通过评分矩阵来学习用户和商品的特征矩阵,最后利用用户和商品的特征矩阵来补全评分矩阵。PMF在SVD的基础上,从概率生成的角度来解释用户和商品的特征向量,PMF假设用户和商品的特征向量均服从高斯先验分布,通过最大化后验概率的方式来求解用户和商品的特征矩阵。
1.2 基于深度学习的推荐方法
深度学习已经在计算机视觉、自然语言处理领域取得巨大的成功,将深度学习和推荐系统结合起来的模型也受到越来越多研究者的关注。如文献[14]提出,为了缓解评分矩阵的稀疏性对协同过滤算法的影响,可将商品的内容作为辅助信息,首先使用SDEA (降噪自动编码器)[13]提取商品内容的一个非线性特征表示,再将该特征表示结合到协同过滤中。
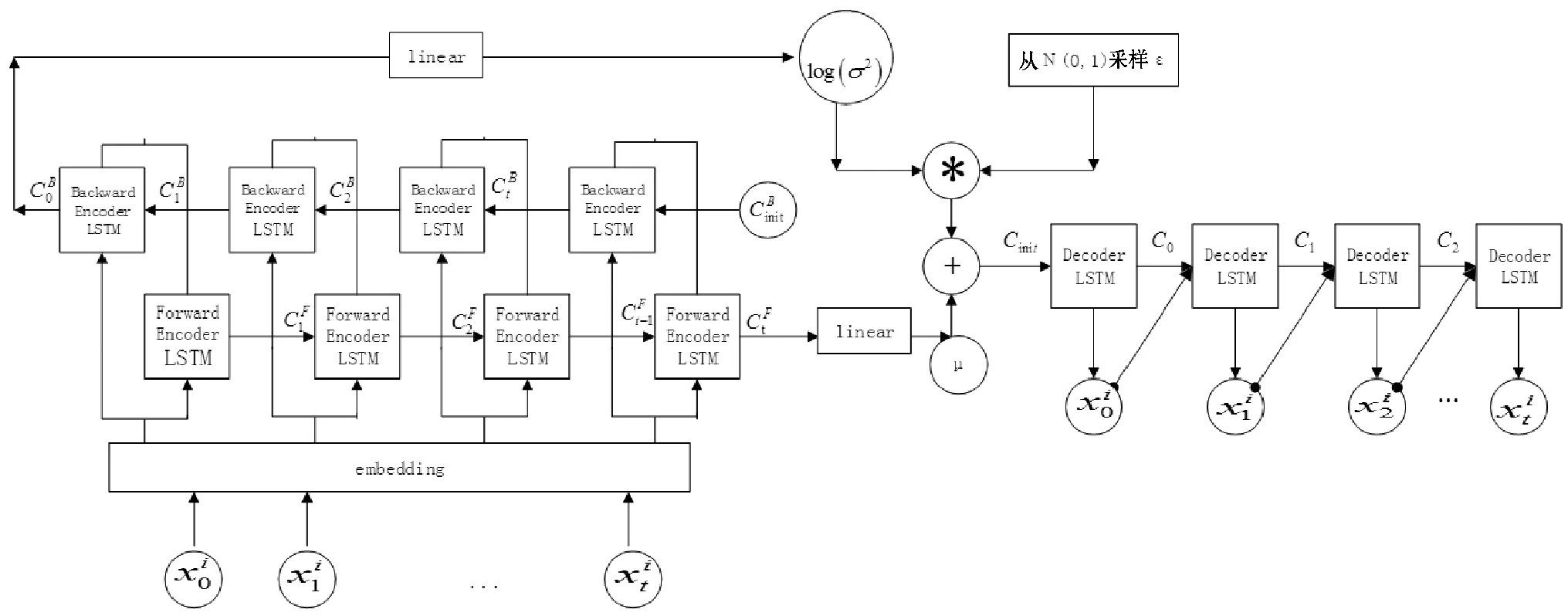
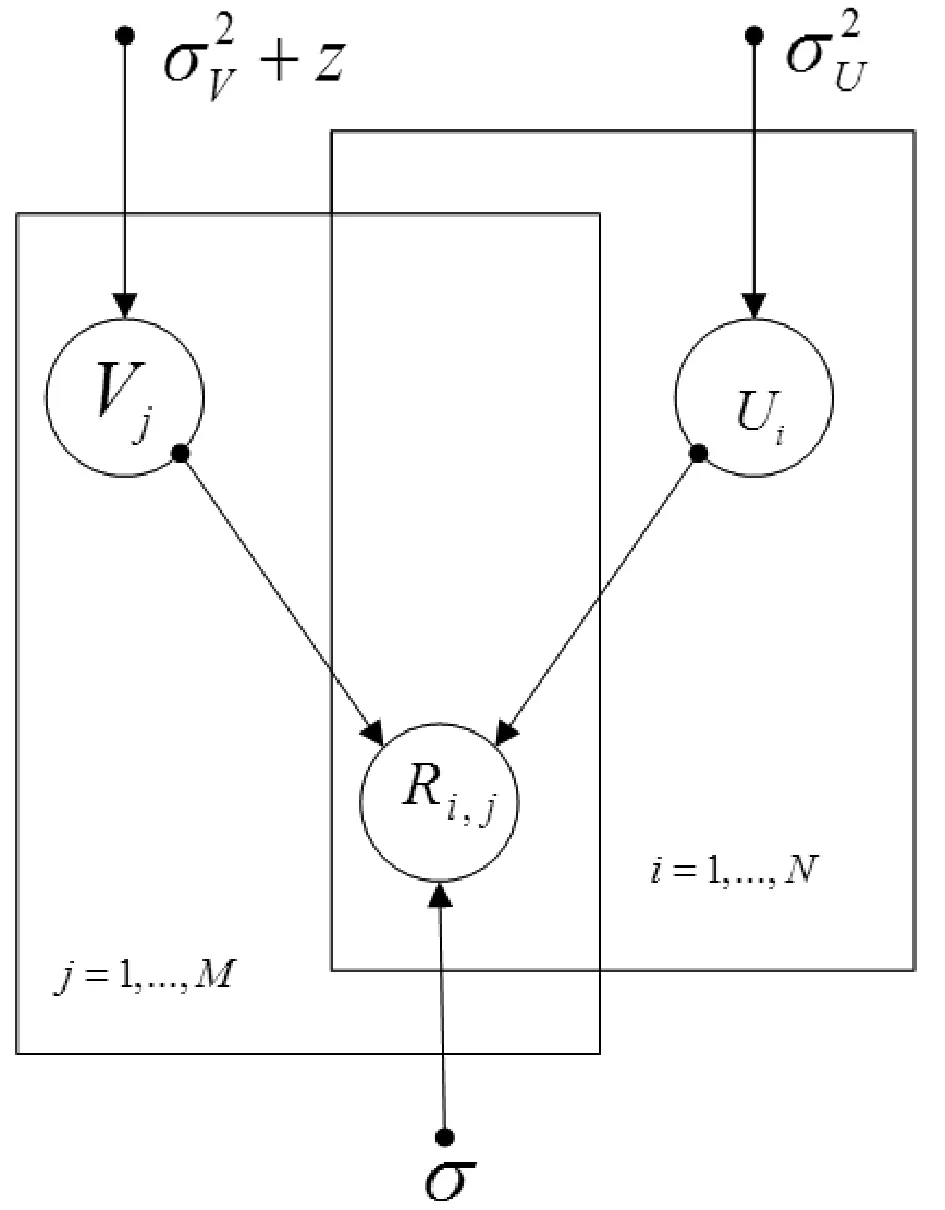
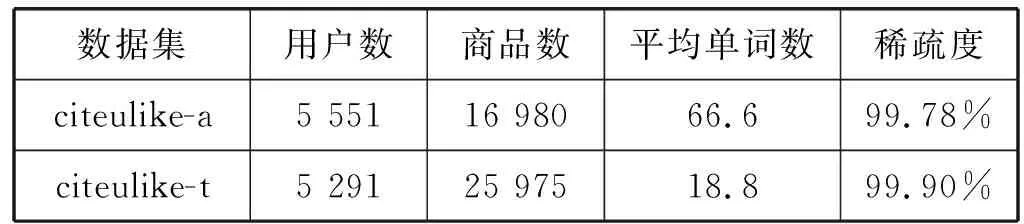
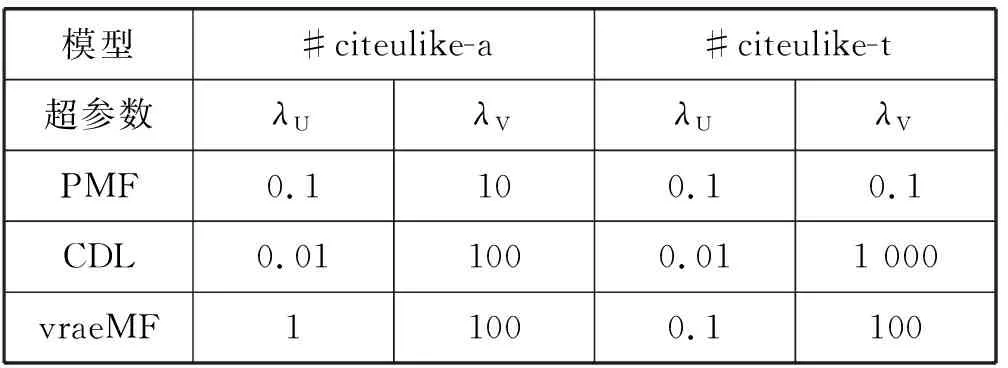
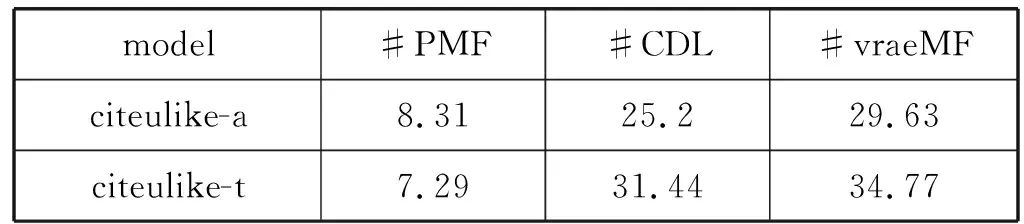
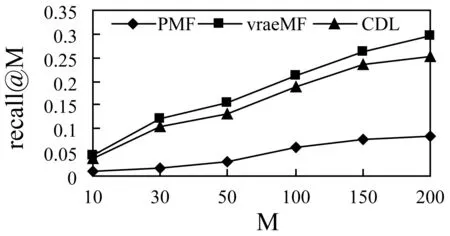
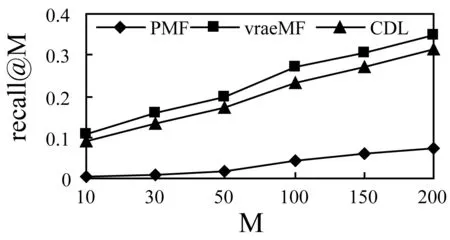
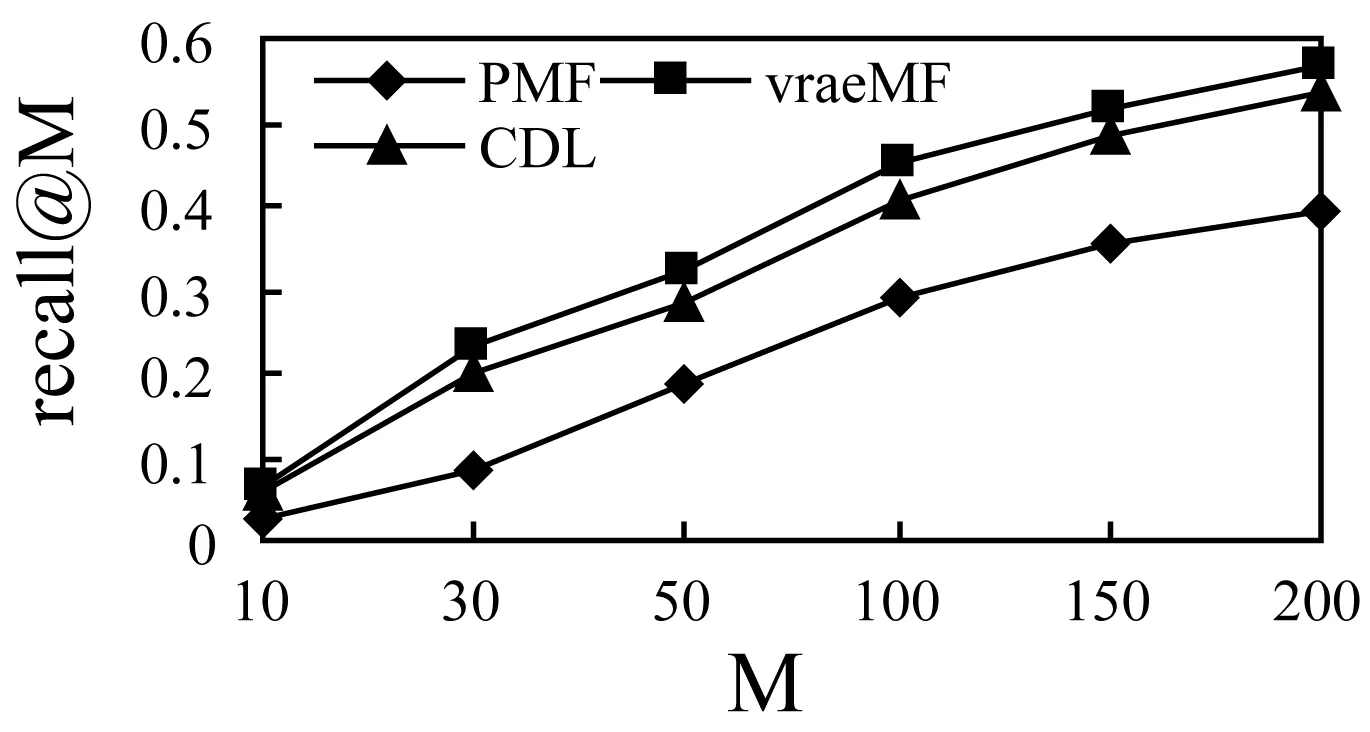
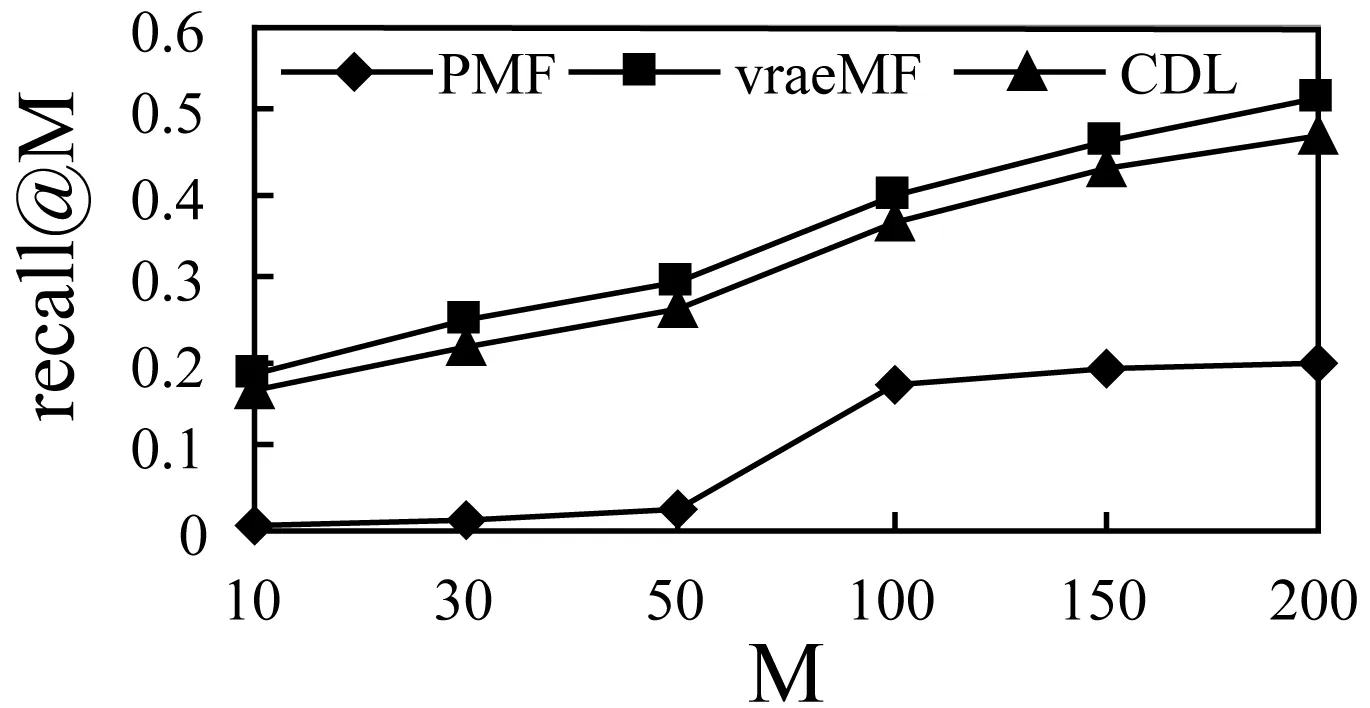
SDEA是一个特殊形式的多层感知机网络,是一种无监督模型。由三部分构成:编码器,解码器和重构损失函数。编码器将输入x∈d通过一个非线性的变换映射到一个中间表示z∈d′,如式(1)所示,其中,W∈d′×d是权重矩阵,b∈d′是偏置向量(d′ z=fe(Wx+b) (1) 解码器将编码器的输出z作为输入,再通过一个非线性变换fd重构输入x,如式(2)所示。其中,权重矩阵W′∈d×d′,常用编码器的权重矩阵W的转置矩阵WT来代替W′,偏置向量b′∈d。 x′=fd(W′z+b′) (2) (3) 但是SDEA在提取文本特征时,用词袋向量作为输入,并使用一个前向反馈网络去编码文本。这种模型结构在处理像文本这样的序列数据时,无法有效地捕捉文本中的语义信息和上下文信息。如“这篇文章的主题是决策树,不是随机森林”和“这篇文章的主题是随机森林,不是决策树”,这两句话想表达的意思完全不一样,但是经过SDEA编码后,却会得到同样的表示。其次,我们也无法知道,经过SDEA编码后,得到的中间表示z服从什么分布。 本文提出一个基于变分循环自动编码器的概率矩阵分解模型(vraeMF),该模型首先使用基于循环神经网络的变分自动编码器从商品的描述文本中提取出商品特征向量,再将该特征向量与概率矩阵分解模型相融合,来补全评分矩阵。 假设数据集一共有N个用户,M个商品,观测评分矩阵R=[Rij](i=1,2,…,N;j=1,2,…,M)是一个二元值矩阵,每个商品有一段长度为l的描述文本x。我们的任务是根据观测评分矩阵R和商品描述文本x来对每个用户推荐一个其可能感兴趣的商品列表。 本文采用基于循环神经网络的变分自动编码器从商品的描述内容中提取该商品的内容特征表示z。该编码器结合了循环神经网络和变分自动编码器的优点:循环神经网络由于其本身天然序贯的结构性质,能更有效地处理文本这样的序列数据。变分自动编码器是一种生成模型,用该编码器编码得到的中间表示z服从高斯分布。本节中我们会详细讨论该模型的结构,如图1所示,该模型由三部分构成:编码器,内容特征表示z的生成和解码器。 图1 基于循环神经网络的变分自动编码器 2.2.1 编码器 2) 双向动态LSTM层 我们用一个双向动态LSTM网络作为编码器。首先由于商品的文本内容长短不一,所以我们采用动态LSTM网络。其次,由于传统RNN能够存取的上下文信息范围有限,在处理长度较长的序列数据时,RNN能将信息串联起来的能力就越来越弱,为了解决这个问题,我们采用双向LSTM[15]网络。LSTM的关键就是贯穿整个序列的细胞单元状态Ct和三个精心设计的“门”:遗忘门ft,输入门it和输出门Ot,这三个“门”有选择的让信息通过序列,从而更新细胞状态Ct和隐藏状态ht,相应的门的计算公式如下: (4) (5) (6) ht=Ot×tanh(Ct) (7) (8) 2.2.2 商品内容特征表示z的生成 (9) (10) z=σ×ε+μ (11) 式中:WF,WB∈k×m,bF,bB∈k,μ,σ∈k,我们将μ和σ2分别视作为k个高斯分布的均值和方差,并且z~Ν(μ,σ2),所以我们可以从Ν(μ,σ2)采样生成特征表示z,但是这个采样操作对μ和σ不可导,无法使用通过梯度下降法来优化,参考文献[11],我们首先从Ν(0,1)上采样得到ε后,然后利用式(11)来计算z。这种操作下,从编码器输出到z,只涉及线性操作,因此,可通过梯度下降法优化。 2.2.3 解码器 解码器pθ(x|z)将上一步的商品内容特征表示z作为输入重构输入数据x。我们采用长度和对应编码器相同的单向LSTM网络。其中每个LSTM单元的隐藏单元数量跟编码器一样为m。和编码器网络不同的是,在解码器中,我们设置初始输入为0,在后面的每一步中,将上一步的输出作为下一步的输入。解码器中,LSTM网络的初始细胞状态值Cinit由z经过式(12)所示的一个线性变换得到,其中Wd∈m×k,bd∈m。我们希望解码器在每一步t的输出和编码器的输入尽可能相同。 Cinit=Wdz+bd (12) 2.2.4 训 练 数据xi目标损失函数由两部分构成:pθ(z)与qφ(z|xi)的KL散度和重构损失,KL散度可以看作是一个正则因子,用来衡量两个分布的相似程度,相应的损失函数如下所示: ξ(θ,φ,xi)=-DKL(qφ(z|xi)‖pθ(z))+ Εqφ(z|xi)[logpθ(xi|z)] (13) 根据变分贝叶斯理论[11],上式可以简化为: (14) 我们通过随机梯度下降法优化上述损失函数,得到最优的μ和σ,然后用式(11)得到z,作为商品的初始特征向量,用于下一步的概率矩阵分解中。 我们将上一步得到的特征表示z作为商品的初始特征矩阵融合到概率矩阵分解模型中,融合过程如图2所示。用户特征矩阵为U(U∈k×N),商品特征矩阵为V(V∈k×M),这里用户和商品的特征向量维度和z相同,然后用这两个特征矩阵的乘积UTV来补全评分矩阵R。 图2 vraeMF模型框架 2.3.1 融合过程 (15) 对商品特征矩阵V,我们假设其由两部分构成:(1) 由商品内容得到的特征向量z;(2) 高斯噪声ε,用来优化商品特征矩阵。如式(16)、式(17)所示。商品特征矩阵的条件分布可表示为式(18)。 V=z+ε (16) (17) (18) (19) 式(15)-式(19)中:N(x|μ,σ2)表示均值为μ;方差为σ2的高斯分布。Iij是0-1指示函数,如果用户i对商品j有过评分反馈,则Iij为1,否则为0。 2.3.2 优化策略 我们使用最大后验估计(MAP)来优化用户和商品的特征矩阵,如下所示: (20) 对R、U、V的联合密度负对数化,最大化后验概率U和V,等价于求式(21)最小值。 (21) ui←(VIiVT+λUIk)-1VRi (22) vj←(UIjUT+λVIK)-1(URj+λVzj) (23) 用户特征向量u的优化过程为式(22),Ii是一个单位对角矩阵,对角元素为Ii,j(j=1,2,…,M),Ri是一个向量,具体值为:Rij(j=1,2,…,M)。商品特征向量的优化过程为式(23),与用户特征向量优化的过程不同的是,其中考虑了商品内容特征表示Z的影响,Ij和Rj的定义和式(22)中的Ii和Ri类似。我们通过交替的方式,更新U和V,直至收敛。 最后,通过更新得到U和V来重构评分矩阵,补全缺失的评分。用户i对商品j的评分可由(24)式计算。在推荐过程中,对用户i,我们将Ri的按照值的大小从高到低排序,将排在前面的商品认为是该用户感兴趣的商品集。 (24) 我们使用来自CiteULike的两个数据集:citeulike-a和citeulike-t。 CiteULike是一个学术资料库网站。用户可以在该网站创建自己的学术资料库,并在库中收藏自己感兴趣的学术文献。数据集包括:(1) 每个用户库中的文献列表,代表该用户感兴趣的商品集;(2) 所有文献的标题和摘要,作为商品的描述文本。表1列出了这两个数据集的统计情况。在实验预处理过程中,我们删除了收藏文献数据少于5的用户。 表1 数据集统计情况 为了分析本文算法的推荐性能,我们在同等环境下分别使用经典推荐算法PMF和基于深度学习的推荐算法CDL[14]进行对比。在我们的实验当中,Word2Vec词向量维度为250维,LSTM隐藏层单元数量为150维。用户和商品的特征向量维度和文献[14]相同,为50。对于参数λU和λV的设置,我们取在每种模型下结果最好的参数值,具体如表2所示。 表2 参数设置 由于本文使用的数据集中,用户对商品的评分都是隐式反馈,只有0、1两种数据。用户对商品的评分为1代表对该商品感兴趣。用户对一个商品的评分为0,则有两种情况:一是用户对该商品不感兴趣,二是用户没有意识到该商品的存在。所以相比准确率,召回率是一个更合适的评测指标。本文采用recall@M作为实验的评测标准,对于每个用户,recall@M定义为: 3.4.1 试验安排 我们分两种情况在上述两个数据集上来测试三种模型的推荐性能:稀疏情况和稠密情况。对于每个用户,我们从随机选取1个该用户收藏过的商品记录作为稀疏情况下的训练样本,然后随机选取10个该用户收藏过的商品记录作为稠密情况下的训练样本。两种情况下,将剩下的数据作为测试样本。将5次交叉验证结果的平均值作为实验的最终结果。 3.4.2 实验结果与分析 表3列出了在稀疏情况下三种模型在两个数据集下的recall@200值,我们可以得出:在稀疏情况下,vraeMF和CDL的结果都要优于只使用评分矩阵的PMF。其中在citeulike-a数据集下,CDL比PMF要高出17%左右,vraeMF比PMF要高出21%左右。在citeulike-t数据集下,CDL比PMF要高出24%左右,vraeMF比PMF要高出27%左右。说明将商品内容的特征表示融合到概率矩阵分解中,能够提高推荐性能。 表3 稀疏情况下recall@200 % 图3、图4为稀疏情况下,三种模型的recall@M值随着M变化情况,图5、图6为稠密情况下三种模型的recall@M值随着M变化情况。可以看出:(1) 在稀疏和稠密两种情况下,vraeMF的recall@M均高于CDL。说明vraeMF在根据商品内容提取特征表示的时候,由于考虑了文本内容的语义信息和上下文信息,能更好地表示商品特征。(2) 我们由表1可知,数据集citeulike-t的评分矩阵和商品内容比citeulike-a更稀疏,根据实验结果,即使在稀疏的情况下,vraeMF在citeulike-t上的recall@M比citeulike-a高出5%左右,说明vraeMF更适合与处理稀疏的文本和评分矩阵。 图3 citeulike-a稀疏情况recall@M 图4 citeulike-t稀疏情况recall@M 图5 citeulike-a稠密情况recall@M 图6 citeulike-t稠密情况recall@M 本文针对概率矩阵分解中的稀疏问题,提出一种基于变分循环自动编码器的概率矩阵分解方法。该方法首先从商品内容信息中提取出一个服从高斯分布的商品特征表示,然后将该特征表示融合到概率矩阵分解中来缓和稀疏问题。实验结果表明,本文方法在评分矩阵极其稀疏的情况下,能提高推荐准确性。此外,由于本文算法只考虑了提取初始商品特征表示,在此后的研究中,可以考虑将用户初始特征表示也考虑进来。2 本文算法
2.1 问题定义
2.2 商品特征提取
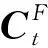
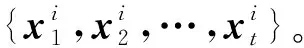
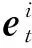
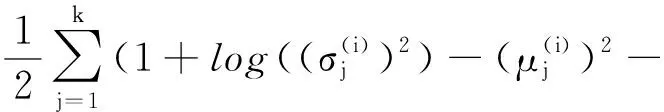
2.3 商品特征融合
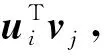
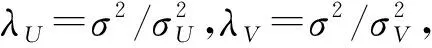
2.4 预 测
3 实 验
3.1 数据集
3.2 参数设置
3.3 评测标准
3.4 实验安排与结果比较
5 结 语
