强光干扰下基于多目视觉交叉注意的物体识别系统
2018-09-26徐小伟赵浩苏
徐小伟 邢 凯 赵浩苏 梁 科
1(中国科学技术大学软件学院 江苏 苏州 215123)2(中国科学技术大学计算机科学与技术学院 安徽 合肥 230026)3(西安铁路信号有限责任公司 陕西 西安 710054)
0 引 言
随着物联网和人工智能的快速发展,各类智能设备在生产生活中开始扮演重要角色,如自动驾驶汽车、服务机器人、工业机器人等。这些智能设备的视觉感知尤其是物体识别能力,在其对周围环境感知学习的过程中往往会起到关键作用。这促使机器视觉尤其是物体识别研究成为当前重要研究方向之一。
基于机器视觉的物体识别是指利用计算机视觉、模式识别等技术,自动识别视觉中存在的一个或多个物体,广义扩展的话还包括对物体进行图像区域和空间定位等。基于机器视觉的物体识别研究从最早的模板匹配[1]、Booting算法[2-4]、支持向量机[5]发展到现在所广泛使用的深层神经网络方法[6],其图像特征抽取方式也从传统的手工设定到基于模型的半自动化提取[7-13],演变为如今的自动学习方法[14-20]。
随着计算机算力的大幅度提升和大规模数据资源的成熟可用,基于深度学习的机器视觉物体识别技术发展迅速,其在现有的大规模数据集上,如ImageNet[21]、PASCAL VOC[22]、Microsoft COCO[23],均取得了较好的识别效果。深度学习网络按使用途径一般可分为:(1) 直接训练并识别,在待分类的数据集上直接训练一个深层神经网络,例如VGG-16[24],GoogleNet[25]等;(2) 特征抽取+组合模型,深度学习网络用作特征提取器,在已训练好的网络上提取特征,提取的特征可以用做其他的后续操作。
近年来随着物体识别领域的新技术不断涌现,新的研究问题也不断被提出。其中一个吸引了众多研究者注意的问题是,生产生活环境中各种光线干扰和复杂背景干扰,如自动驾驶中来往汽车远光灯干扰等,会对物体识别的准确性和健壮性带来极大挑战。如果要让智能设备参与到人们生产生活中的各种场景,其必须拥有认识所处环境的能力。那么如何解决各种光线干扰/复杂背景干扰下物体识别的准确性和健壮性,是当前基于机器视觉的物体识别领域亟需解决的问题。
同时,考虑到视觉/光线干扰和复杂背景干扰的场景纷繁复杂,建立这样一个数据集所需要的数据量会大大超过ImageNet,从成本、时间和可行性上都具有极大挑战。本文的研究目标是,如何在强光干扰/复杂背景干扰环境下,在不额外增加海量干扰环境训练数据的前提下,实现健壮的、高准确率的物体识别。
目前在强光干扰/复杂背景干扰下的物体识别研究工作主要是基于注意力的细微特征区分和基于多视角的目标检测。注意力机制[26-27]往往用来区分细微特征,这在解决背景干扰问题中具有重要意义,但是并没有证据表明其适用于强光干扰环境。多视角技术[28-29]一定程度上可以解决强光干扰、视角变化、背景淹没导致物体识别准确率下降的问题,但目前这个方向的研究多聚焦于特定目标检测,不适用于通用物体识别。理论上通过扩展目标种类的训练数据集可以解决干扰问题。然而,考虑到物体种类、背景干扰场景和强光干扰场景的多样、复杂性,制备一个完备的用于训练和测试各类干扰场景下各类物体识别的数据集是极其困难的。
本文根据仿生学的进展[30-33],借鉴了生物复眼视觉系统具有多子眼、子眼结构简单、三维信息丰富的特点,提出了一种基于多目视觉交叉注意的物体识别方法。该方法基于子眼间的交叉注意提高物体识别准确率,并对识别结果存在潜在冲突的多目数据进行全局融合,有效解决了强光、背景等干扰问题。
本文贡献如下:
(1) 提出了一种不需要构建海量强光/复杂背景干扰训练/测试数据集,能够融合现有物体识别算法和多目视觉优点的物体识别系统,为当前强光干扰和复杂背景干扰场景下的研究推进,特别是从特定目标检测到通用物体识别的研究提供了新的思路;
(2) 提出了一种多目视觉交叉注意方法,通过子眼间交叉注意来提高物体识别准确率,提高了在强光、复杂背景等干扰下物体识别的准确率;
(3) 基于证据融合理论,提出了一种针对子眼间识别结果存在潜在冲突的多目数据融合方法,提高了在强光、复杂背景等干扰下物体识别的查全率和准确率;
(4) 实验结果表明,与现有物体识别算法Faster R-CNN,SSD512,YOLOv2相比,本系统能显著提高在强光、复杂背景干扰下物体识别的查全率、准确率和可信度。
1 相关工作
面向强光干扰环境的多目视觉的物体识别的相关工作划分为两个部分:物体识别和复眼系统。
1.1 物体识别
物体类别检测一直是计算机视觉的研究热点。随着深度学习的发展,传统的物体识别算法慢慢退出历史舞台。文献[34]提出了OverFeat特征提取器,综合了识别、定位和检测任务,训练了两个CNN模型,一个用于分类,一个用于定位。OverFeat在输入图像上使用滑动窗口策略,通过使用分类CNN模型确定每个窗口中物体的类别,然后使用相应类别的定位CNN模型预测物体的候选区域,并根据分类得分合并每个类别的候选区域获得最终的检测结果。Ross Girshick提出的R-CNN[35]使用选择性搜索策略代替滑动窗口机制提高了检测效率。R-CNN使用选择性搜索策略在输入图片上选择若干个候选区域,使用CNN对每个候选区域提取特征并输入到训练好的SVM物体分类器中,以获得候选区域属于每个类别的分数,最后通过非最大抑制方法丢弃部分候选区域,得到检测结果。受到R-CNN目标识别框架的启发,Kaiming He提出的SSP-net[26]对整幅图像进行卷积运算,得到整幅图像的卷积特征,然后根据原始图像中每个候选区域的位置,提取卷积特征图中的卷积特征送入分类器。SSP-net解决RCNN需要对每个候选区经行卷积的问题。在fast-RCNN[27]中,Ross Girshick仅对候选区域进行标准分割,然后直接降采样得到特征向图,将边框回归和分类任务统一到一个框架中,解决了SSP-net和RCNN网络复杂的训练训过程同时提高了识别精度。Ross Girshick针对选择性搜索策略计算速度慢等问题,创建了区域推荐网络替代选择性搜索算法来选择候选区域,实现了端到端的计算,把所有的任务都统一到深度学习的框架下,大大提高了计算速度和精度,这就有了著名的faster-RCNN[28]物体识别网络,其平均识别精度MAP(mean average precision)高达73.2%。尽管faster-RCNN物体识别网络在计算速度方面取得了长足的进步,但仍不能满足实时检测的要求。因此,基于回归的方法直接从图片中回归物体的位置和类型被提出。具有代表性的两种物体识别网络是SSD[18]和YOLO[19]。YOLO暴力的将输入图片划分为7×7个网格代替区域推荐网络,将物体检测视为回归问题,使得系统处理时间得到大幅提升,在GPU上每秒处理45张图片。SSD使用回归方法来检测物体,同时引入Faster R-CNN的archor机制使物体的分类精度和定位有了很大的提高。
1.2 仿生复眼系统
自然界中大多数昆虫都有一个或多个复眼作为其视觉器官。复眼由不定数量的子眼构成,通常位于昆虫的头部突出位置。不同昆虫的复眼子眼数量差别很大,从最少几个到最多数万个不等。昆虫的敏捷性离不开复眼对环境的感知,有些昆虫的视觉范围可达到360度,具有广阔的视野。成千上万的子眼同时工作,使其可以快速察觉周围环境的细微变化,并作出反应。学术界、工业界的放声复眼分为二维(2D)平面结构和三维(3D)曲面结构[32-33]。在2D平面结构复眼系统方面,文献[36]提出的TOMBO复眼成像系统,具有易于组装、结构紧凑等特点。经过多年的发展,文献[37]使用光刻胶技术制作的微透镜阵列成功搭建了仿生复眼成像系统。张洪鑫等[38]提出了单层和三层两种曲面复眼成像系统,采用三层曲面复眼成像系统有效提高了边缘成像质量差、视野小等问题。Floreano等[39]研究并生产了一种新型仿生复眼成像系统CurvACE,该系统创造性地利用平面微透镜阵列来构建曲面复眼,从而实现大角度成像,视场角度能够达到180°×60°。复眼在获取准确的三维信息问题上有着优异的表现[32],文献[40]模拟复眼功能,使导弹获得目标的三维空间位置信息。复眼在智能机器人的视觉导航中扮演者重要的角色[41]。智能机器人的视觉系统可以准确地感知周围环境中物体的位置,因此可顺利穿行于有障碍物的环境中。
2 多目视觉系统设计
当前物体识别研究所用的数据集,往往是具有较少干扰的图像数据,这就导致了其上训练的物体识别算法在强光干扰或者复杂背景干扰下的识别准确率会明显下降。
本文原理设计的出发点是从生产生活环境中各种光线干扰和复杂背景干扰出发,基于多目间丰富的几何三维信息和各子眼视觉结果互为冗余的特点,在强光干扰、视角变化、背景淹没等情况下提高物体识别的准确率和查全率。
2.1 交叉注意原理设计
本文通过各子眼的空间几何关联和立体视觉来计算指定区域中特征点的空间三维坐标和其在不同子眼图像上的投影。
2.1.1 子眼模型
子眼相机将三维空间中的坐标点(单位mm)映射到二维图像平面(单位像素),用子眼相机模型可以对其建模,子眼相机投影模型如图1所示。
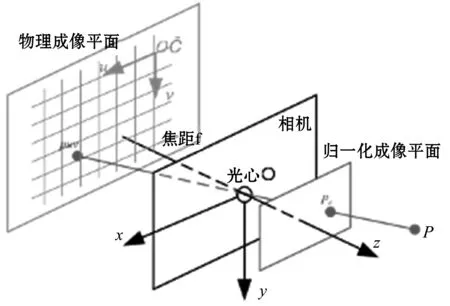
图1 子眼相机投影模型
空间点P在相机坐标系o-x-y-z中坐标设为[x,y,z],经过小孔投影后落到物理成像平面Z=1上,在像素坐标系上的坐标为Puv=[u,v],坐标关系为式:
(1)
式中:K为相机内参数矩阵,为固定值,通过相机标定可以获得其值。在归一化平面Z=1上,点P归一化的相机坐标为Pc=[X/Z,Y/Z,1]T。
2.1.2 交叉注意机制
视觉注意是人类信息加工过程中的一项重要的信息感知机制,它能够对有限的信息加工资源进行分配,使感知具备选择能力[42]。人眼的注意力机制保证了人眼信息获取的高效性。人眼在从宽视野聚焦到感兴趣区域时,可以观察到更多的细节。
本文通过各个子眼在不同视角下的图像特征提取与匹配,得到各子眼可能的交叉注意区域,交叉注意系统模型如图2所示。
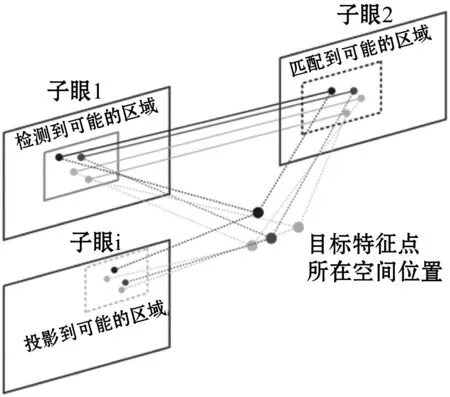
图2 交叉注意系统模型
其具体流程如下:对同一场景下不同子眼采集的图像,各子眼对其进行特征提取,对同一特征,通过验证其空间一致性可以增强检测的置信度。当某一子眼或部分子眼受光照或背景干扰强烈时,通过其他子眼的特征提取结果和当前视角,集中注意力到指定区域进行特征提取,以提高物体识别准确率和查全率。
给定子眼1在其图像1中获取该图像中的特征点,基于子眼1和其他子眼的空间3D位置关系,可以计算其他子眼在子眼1的视角下的投影,并与子眼1图像中的特征点做匹配。对未匹配的特征点所在区域进行图像增强后进行特征抽取。基于已匹配的特征点和交叉注意后提取出的特征点,子眼1可以利用现有物体识别的深度网络模型进行识别。
2.2 多目视觉物体识别系统设计
本文的多目视觉系统由四个子眼模块组成,每个子眼负责一个视角下的图像数据采集。其具体工作原理设计如下:基于特征抽取+组合模型的方式,利用已有的深度学习网络作为单子眼的特征提取器,基于四目间的几何三维关联信息和各子眼的部分视觉数据互为冗余的特点,利用子眼间的交叉注意来提高物体识别准确率,然后对识别结果存在潜在冲突的多目数据进行全局融合,多目视觉物体识别系统设计如图3所示。
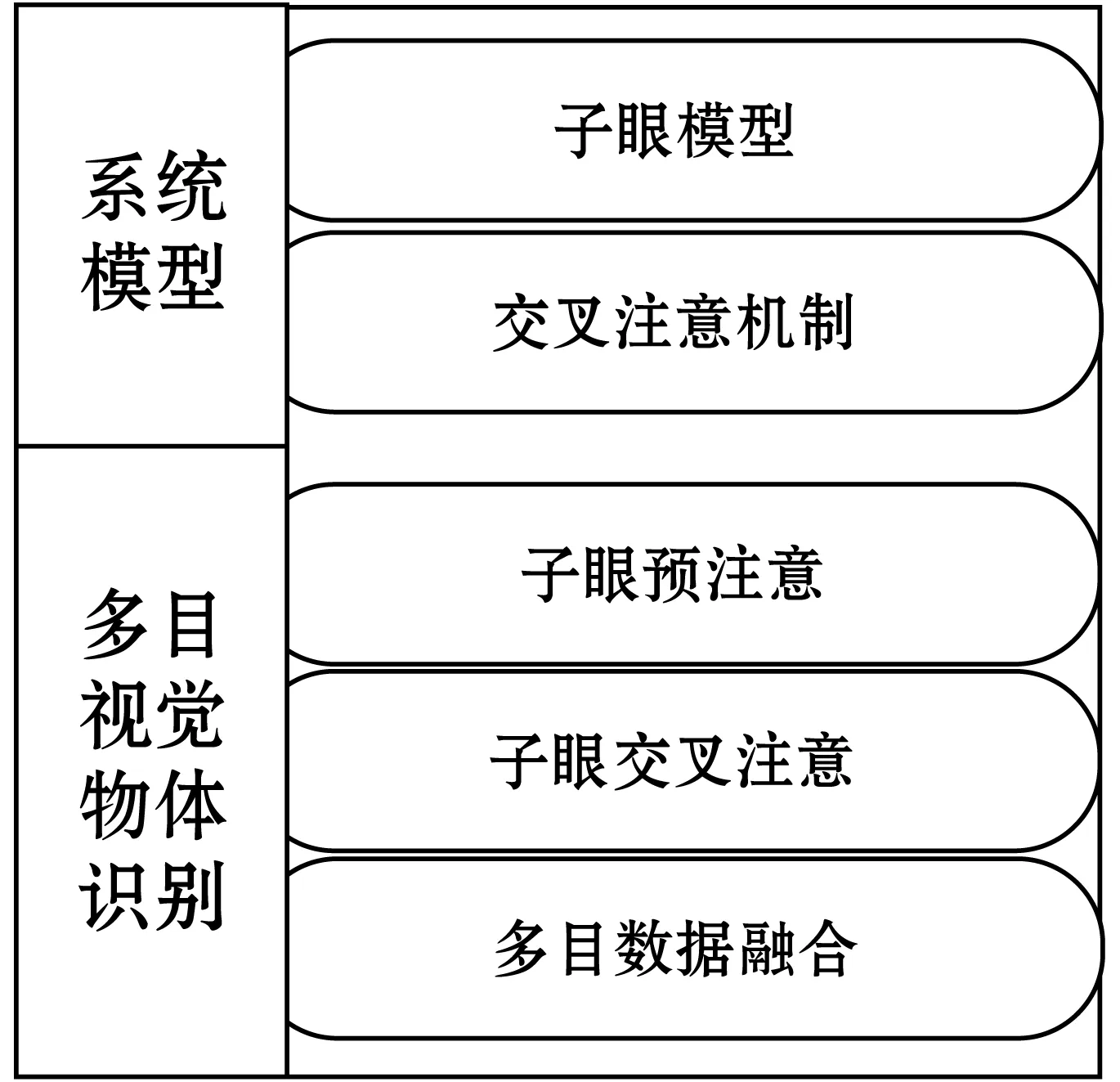
图3 多目视觉物体识别系统设计
本文以SSD512为示例,取其全连接层的第一层及之前的卷积结构作为特征提取器,如图4所示。给定某一时刻子眼ei采集的图片记做pici,特征提取结果记做rlti,rlti=feature(pici)。假设rlti包含m个特征,记做rlti={fi1,fi2,…,fim},然后得到所有子眼的特征全集U=U{rlti},找出各子眼与U的差集{fij}=diff{U,rlti},以及该特征fij在pici中对应一个区域Region(fij)。子眼模块将注意力集中到Region(fij),对区域Region(fij)图像增强后进行物体识别,这样每个子眼识别后得到一个识别结果子集di。对所有di进行置信度和不确定性计算,对所有数据包括有潜在冲突的子眼间数据进行数据融合得到最终结果R=Weighted{di}。
3 基于多目视觉的物体识别
3.1 基于交叉注意的物体识别
本文的交叉注意机制由聚焦到目标区域和目标区域细节增强两个部分组成。这和人眼的注意力机制相契合。首先,各子眼通过预注意来提取各自视角下的图像特征,获取其与特征全集的差集{fij},通过子眼的坐标变换聚焦到区域Region(fij);然后,通过图像增强,弱化该区域的光线干扰,增强物体细节特征,进行物体识别。
3.1.1 子眼预注意
子眼在预注意阶段需要为子眼交叉注意阶段提供场景中的可能存在的特征及其位置分布。我们通过现有的深度学习网络进行前期视觉特征提取。本文中以SSD512为示例,取其全连接层的第一层及之前的卷积结构作为特征提取器来获取其特征及其位置分布。直观起见,我们用SSD512自有的物体分类器作为其特征描述。
在这一特征提取阶段,我们首先基于物体识别网络对子眼采集图片进行预处理,将输出值高于0.8的物体标注为可信物体,无需进行交叉注意,输出值高于0.5但小于0.8的物体,标注为疑似物体,需要进行交叉注意来识别。各子眼识别结果如图5所示,图5中四张图片分别是四个子眼采集的实景图,红色框表示识别出的特征物体fij。实验表明在强光干扰及背景干扰下,预注意阶段各子眼只能识别出视野中的极少部分物体rlti,不足10%。

图5 子眼预注意识别结果
这是因为某些子眼受强光干扰下,其采集的图片中的大部分物体不能被现有的物体识别网络识别。因此需要对该区域进行交叉注意识别。
3.1.2 子眼交叉注意
在交叉注意阶段,首先将所有子眼识别结果合并得到U。将各子眼识别结果rlti按照式(3)在物体集合U中取差集di就是子眼未识别到的物体。利用标定好的子眼阵列计算出物体在各个子眼中的区域位置Region(fij)。
为了得到大量、准确的匹配关系,我们采用基于Grid的运动平滑估计来进行指定局部区域的特征匹配估计[43]得到交叉注意区域,至此完成子眼间的交叉注意区域匹配,获得物体在各个子眼中的区域位置Region(fij)。
在子眼交叉注意阶段得到的区域Region(fij)即是子眼ei需要聚焦的目标区域。然后对目标区域进行图像增强,弱化该区域的光线干扰,增强物体细节特征。考虑到Retinex方法[44]将成像分成光照分量(环境的入射光)和物体反射分量(物体的反射性质),较为适合处理强光干扰情况。因此我们选用Retinex算法进行图像增强处理。本文使用单尺寸Retinex算法,高斯核半径sigma设定为250,对图像的R、G、B三个通道下分别进行Retinex算法增强。
当子眼完成交叉注意后,使用深度识别网络如SSD512对新处理的交叉注意区域及其疑似物体进行识别得到结果rdi,每个子眼的识别结果为r_rlti=rlti∪rdi。多目视觉系统的各个子眼预注意提取特征情况如图5所示。
3.2 基于不确定性的多目数据融合
由于每个子眼的观测角度不同,受干扰程度不一,对物体的识别结果可能存在冲突。怎样解决不同子眼间识别结果的潜在冲突,是准确识别物体的关键。
针对子眼间识别结果存在潜在冲突的情况,本文进行多目数据融合的基本思路是:利用证据融合理论,首先对来自各个子眼的物体识别结果(即证据)进行预处理;然后构建出物体识别场景下各个证据的基本可信度分配函数,并据此计算出各个证据的可信度和似然度;再根据Dempster合成规则[45-46]来计算所有子眼物体识别结果联合作用下的基本可信度分配函数、可信度和似然度。
物体识别场景下识别框架Θ可由PASCAL VOC数据集中20类物体类别和背景组成的集合表示。证据的基本可信度分配函数和计算规则如下:
m(A)=m1(A)⊕m2(A)⊕…⊕mn(A)=
(2)
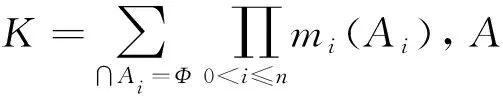
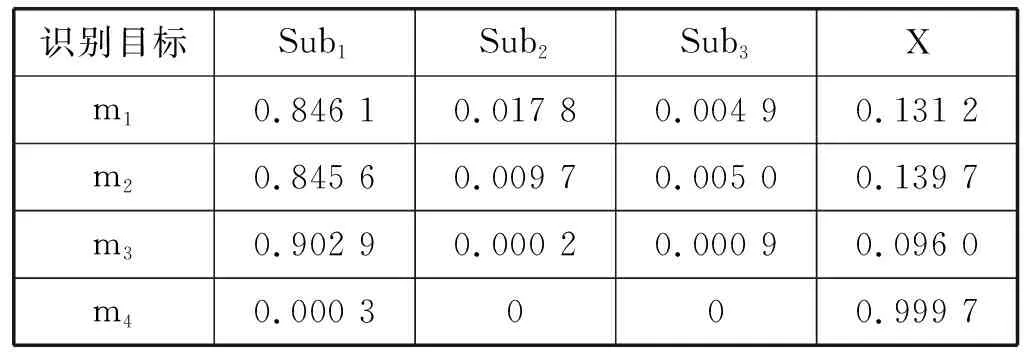
表1 4个子眼的基本信任分配
由表1的4个子眼的基本信任赋值,根据Dempster合并法则式(2)的计算,可以得到由两个子眼、三个子眼、四个子眼的数据组合后的基本概率赋值,结果如表2所示,其中m12、m123、m1234分别表示1~2号子眼的融合结果、1~3号子眼的融合结果和1~4号子眼的融合结果。
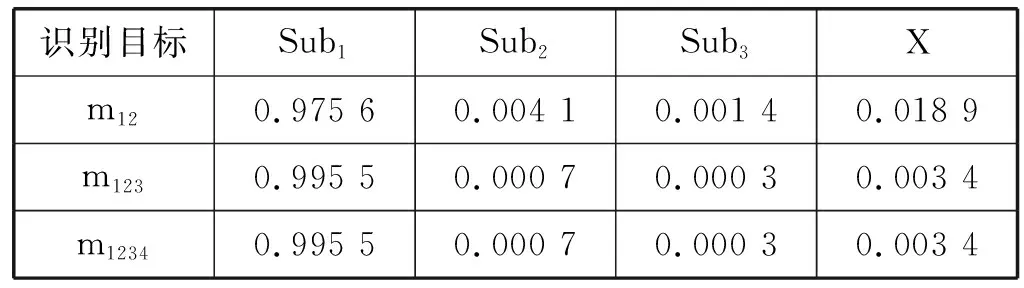
表2 不同子眼组合后的基本信任分配
从表2的D-S的融合结果可以看出参与融合的子眼越多各个证据的可信度分化越明显,更利于决策。本文采用基于基本信任分配的决策方法,即物体类别应具有最大的可信度,物体类别的可信度和其他类别的可信度的差值必须大于某一阈值ε1,不确定区间的长度小于某一阈值ε2,且目标物体的可信度必须大于不确定区间的长度。本文阈值选择ε1=ε2=0.1,最终的决策结果为Sub1。
4 实验分析
4.1 复杂背景下交叉注意机制性能分析
本节分析了交叉注意机制对提高物体识别的准确率和查全率的影响。实验图片样本选取自google图片库和baidu图片库中图片背景以街道为主的cat类、dog类和person类。从中取出100张在使用物体识别网络一次识别未识别出全部物体的图片作为交叉注意实验分析的图片样本,部分样本图片如图6所示。

图6 交叉注意实验分析的部分图片样本
采取本文的交叉注意机制之前和之后,物体识别网络框架的物体识别查全率R(Recall)和准确率P(Precision)对比分析如表3所示。可以看出采取交叉注意机制后查全率显著提高,从不到10%提高到90%以上,其中70%以上的物体在背景环境淹没时通过交叉注意机制可以被正确识别,平均识别准确率达到90.3%。该结果表明当多目视觉系统中部分子眼被干扰或由于角度问题无法识别目标物体时,可以通过未被干扰的子眼的识别结果将注意力聚焦到目标物体区域,进而通过背景增强来减少背景环境对其的干扰和提高识别的准确率。
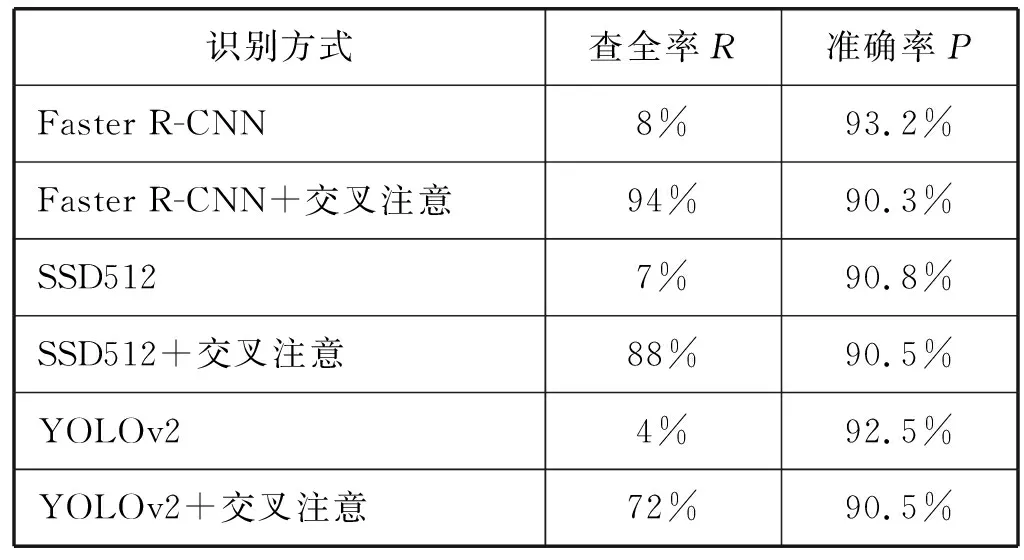
表3 背景干扰下的交叉注意识别结果
4.2 强光干扰下多目视觉系统性能分析
4.2.1 实验设置
本文借鉴2D平面结构复眼系统,在部分子眼受强光干扰情况下的目标检测及获取3D信息,采用布置在2D平面上的4个相机构成的相机阵列。相机间的位置关系通过棋盘法[47]标定好。
本文多目视觉由四个索尼IMX179性摄像头组成,如图7所示。摄像头分辨率1 920×1 080,上下间距40 cm,本文通过调节子眼间水平距离测试在强光干扰和复杂背景干扰下不同子眼的视角差变化对识别结果的影响。我们以左右子眼的的中线为基准线实验数据采集了与多目视觉系统平面不同距离,与基准线不同夹角的多组图像。本文实验设置分为室内场景实验设置和室外场景实验设置。

图7 二维平面结构简易多目视觉模型
本实验使用额定功率24 W,流明值为105 lm的一对汽车远光灯做干扰源,远光灯与多目视觉系统相距5~30米不等。待测物体与多目视觉系统水平相距1~20米不等。室内场景如图8所示,室外道路场景如图9所示。

图8 室内场景采集图像

图9 道路场景采集图
4.2.2 多目视觉系统物体识别性能分析
在强光干扰下,各子眼进行快速的预注意处理,利用未被干扰的子眼识别出物体,将目标物体信息传递给被干扰眼,从被干扰子眼采集的图像中提取目标区域,进行增强处理后,进行交叉注意的物体识别。本文通过实验评估了当前表现最为优异的三种物体识别网络:Faster R-CNN、SSD512和YOLOv2在强光干扰下的物体识别能力。
室内场景,不同强度光照干扰下的多目视觉系统的物体准确率如图10所示,不同强度光照干扰下多目视觉系统的物体查全率如图11所示。由图10和图11可以看出随着光照增强,单眼的识别准确率和查全率都在急剧下降,当光通量达到2 100 lm时单眼完全被干扰失去识别能力,但是此时多目视觉系统仍具有很高的识别准确率和查全率。此结果说明在强光干扰下,由于多目视觉系统的不同子眼间存在视角差,部分子眼受到较小的光干扰甚至没有干扰,故多目视觉系统利用可以识别的图像或区域,再经过多目坐标变换得到被干扰子眼中对应的区域,子眼进行交叉注意。由图11可以看出,子眼交叉注意可以提高子眼的抗干扰能力。
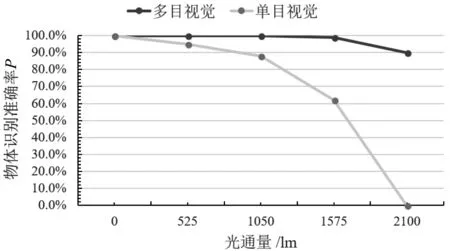
图10 不同强度光照干扰下的多目视觉系统的物体准确率
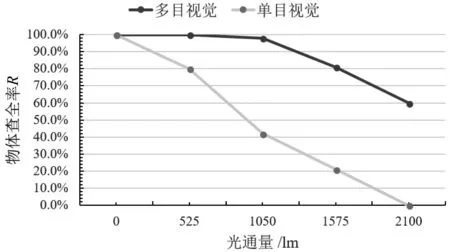
图11 不同强度光照干扰下多目视觉系统的物体查全率
室外道路场景,对采集的图像进行以下两种处理进行实验分析:
(1) 使用物体识别网络处理采集的图像数据,物体识别网络识别结果的准确率(precision)和查全率(recall)曲线图(P-R曲线图)如图12第一行图所示,各物体识别网络的平均识别精度MAP如表4所示。
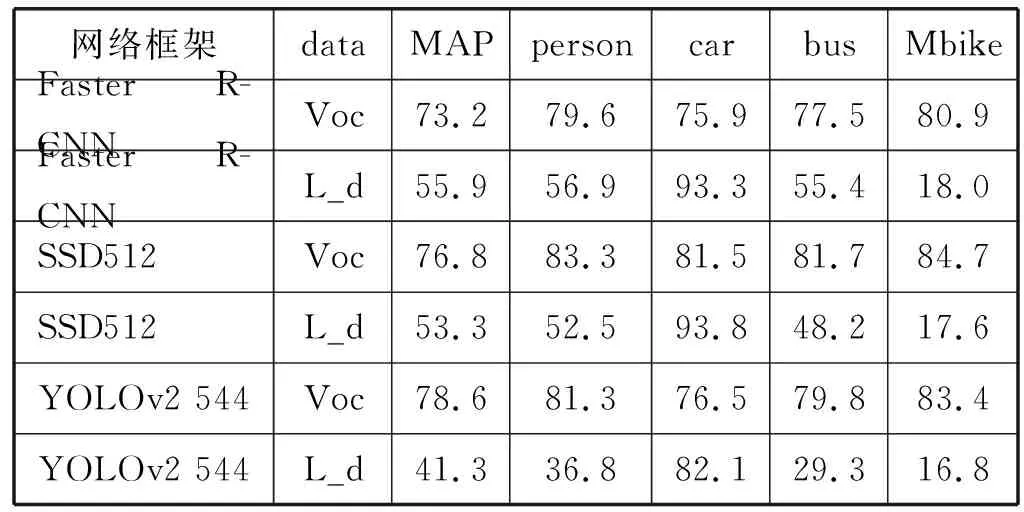
表4 物体识别网络的平均识别精度MAP
(2) 使用多目视觉系统进行处理,物体识别的P-R曲线图如图12第二行图所示,平均识别精度MAP如表5所示。
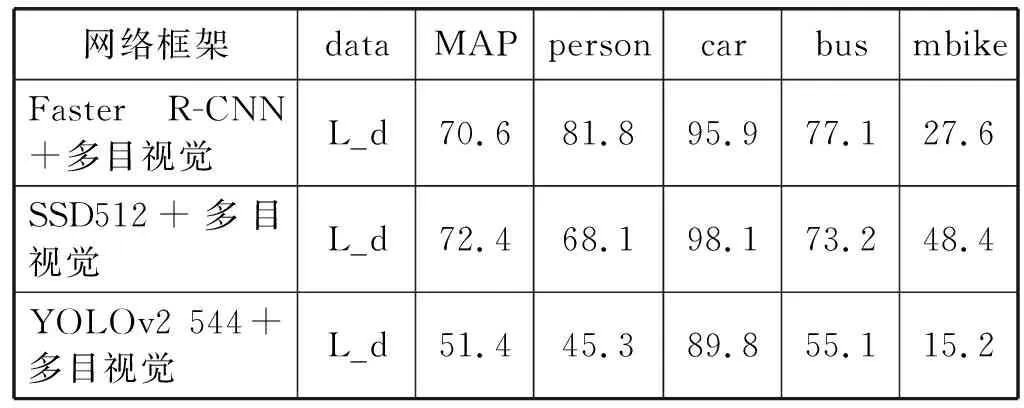
表5 多目视觉物体识别网络的平均识别精度MAP
三种物体识别网络都使用VOC2007和VOC2012数据集训练,表4和表5中data项表示用于测试的数据集,此列中Voc测试数据集为VOC2012,L_d表示测试数据集是强光干扰下的道路场景图片集;MAP列表示该网络框架的识别能力,以百分比计量;person到mbike列表示各网络对此类别的平均识别精度。
从表4中容易看出在无干扰情况下,三种物体识别网络都有优异的识别效果,然而,在强光干扰好和复杂的背景干扰下,三种物体识别网络的识别精度都急剧下降。在有干扰时,Faster R-CNN网络架构的识别精度相对较高为55.9%,但处理速度慢[19],综合考虑处理速度与识别精度,SDD512性能优于Faster R-CNN和YOLOv2,但仍然达不到实际使用的要求。
从表4和表5可以看出,在强光干扰的道路场景中,多目视觉系统的物体识别的平均识别精度MAP比单目的提高了15%左右,其中基于SSD512物体识别框架的多目视觉系统的MAP提高最为显著,提高了19.1%。基于Faster R-CNN物体识别网络框架的多目视觉系统的在person类上的识别精度MAP提高最显著,提高了24.9%。在car、bus、mbike三类物体上,基于SSD512物体识别框架的多目视觉系统的识别精度MAP提高较为显著,分别提高了4.3%、25.0%和30.8%。就多目视觉系统而言,基于SSD512物体识别网络框架的平均识别精度MAP最高,为72.4%。
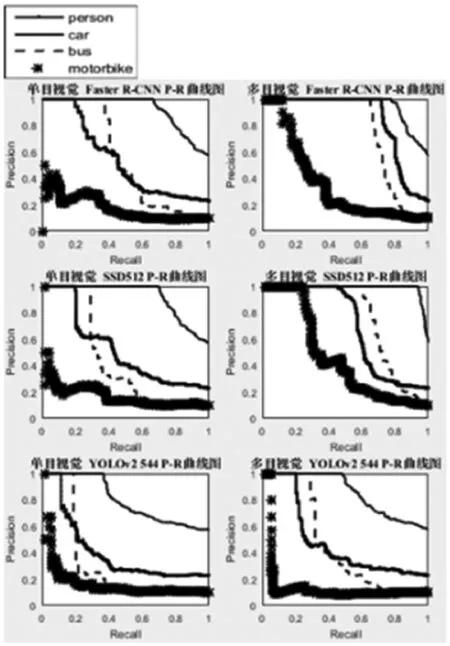
图12 物体识别P-R曲线图
5 结 语
本文提出的基于交叉注意机制的多目视觉系统具有更强的光干扰能力。本文对交叉注意机制和多目视觉系统的性能进行了实验分析,可以看出交叉注意机制在复杂背景下的物体识别有着优异的表现,其中在不损失物体识别网络精度的前提下,将物体识别网络的查全率从平均6.3%提高到84.6%。在强光干扰下的场景基于交叉注意机制的多目视觉系统物体识别的MAP(64.8%)相比于单目的物体识别的mAP(50.2%)提高了14.6个百分点。实验结果表明基于交叉注意机制的多目视觉系统可以在一定程度上降低复杂背景和强光照射对物体识别的干扰。并且,基于交叉注意机制的多目视觉系统物体识别系统使用现有的物体识别网络框架不需要增加额外的训练数据。
