不充分SIMD向量化技术研究
2018-09-26姚金阳陶小涵
王 琦 韩 林 姚金阳 陶小涵
(数学工程与先进计算国家重点实验室 河南 郑州 450001)
0 引 言
随着个人计算机的不断增强,人们对计算机的期望也越来越高,这也要求计算机的计算速度越来越快。目前多数通用处理器上已经集成了SIMD(Single Instruction Multiple Data)扩展部件[1]。SIMD扩展部件一次可以对多个数据进行操作,减少指令执行次数,因此其越来越多的应用于高性能计算中[2],同时越来越多的研究利用SIMD扩展部件对程序进行加速[3-4]。为了方便对SIMD扩展部件的使用,大部分编译器也都集成了自动向量化模块[5-6]。为了实现更多程序的向量化,出现了很多面向向量化的分析方法[7-9],这些方法基本原理是依据数据依赖关系寻找可并行的语句,然后将可并行的语句用向量方式并行执行。
为了获得更高的程序执行效率,SIMD扩展部件的位宽越来越长,以英特尔处理器的SIMD扩展为例,从最初的64位的MMX到128位的SSE,以及256位的AVX。目前英特尔最新的Knights Landing处理器可以支持512位向量指令[10],向量寄存器的宽度越来越长,这使得应用程序执行速度越来越快,然而这也使得一次向量执行所需要的元素个数越来越多。一些程序由于其迭代次数不足,或者基本块内向量并行的语句不够多,不足以为向量寄存器提供足够的并行,因而不能向量化。例如若向量因子(向量计算中一次操作处理的元素个数)为4,针对图1所示循环,gcc编译器识别为not enough data-refs in basic block,不能向量化。
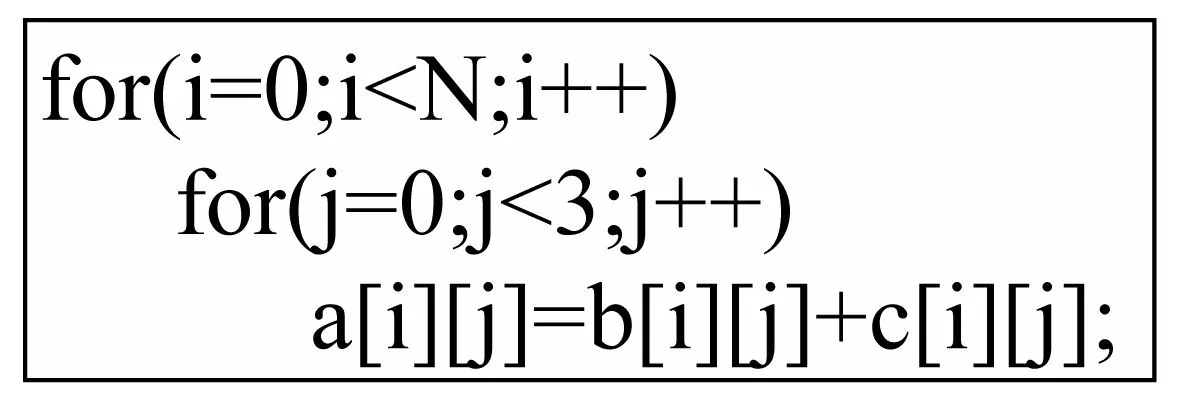
图1 示例程序
而随着向量寄存器长度的增加,程序会有越来越多的循环或者基本块会被识别为数据引用不足,因此当向量因子较大时,如何对向量寄存器进行部分使用是亟待解决的问题。
对于不充分向量化,目前已经有了一定的研究,文献[11]通过添加冗余的语句,将不充分的向量化构造为充分的向量化,达到程序向量化的目的,但是其不能结合SLP超字并行算法来实现基本块内的不充分向量化。文献[12]利用AVX指令集中的permute指令将有效数据填充到冗余数据的槽位,以确保计算时的数据不会出现异常,同时利用insert和extract指令实现不充分向量化的存取。但是这种向量存取的方法需要多条指令来实现,会有额外的开销,而且在向量计算中,一个槽位中的数据出现异常不会对向量中的其他数据产生影响。所以实际上不需要数据整理指令以使得向量寄存器中的所有数据均有效,只需要确保冗余数据没有被写回到内存中即可。文献[13]利用循环的向量并行度指导循环进行向量化,而当向量并行度低时,利用提取指令将有效数据写回到内存中,实现不充分的向量化。
上述研究对于不充分的向量化处理有了一定的研究,并且在性能上取得一定的提升,但是仍然存在额外的开销。随着向量指令集越来越丰富,实现不充分向量化的方案越来越多,额外的开销也会变的越来越少,因此本文针对不充分的SIMD向量化技术进行研究分析,旨在为不同场景下的不充分向量化提供更高效灵活的方案。
具体本文的主要贡献有:
1) 为向量并行度低的循环和基本块提供不充分向量化的实现方案;
2) 对基于256位AVX指令集的不充分向量化进行收益分析。
1 不充分向量化问题描述
1.1 向量寄存器的使用方式
向量寄存器一次可以容纳多个数据,现有的编译器将向量寄存器作为一个整体使用,一次性从内存中读取多个数据,一条指令对多个数据同时进行计算,最后一次性的将向量寄存器中的数据写回到内存中,而且,在这个过程中,向量寄存器中的所有的数据均为有效的,向量寄存器被当成一个整体来使用。
但是在很多情况下,可以进行向量处理的数据不足以充满整个向量寄存器,而现有的很多编译器,例如GCC,不能对这一部分进行向量化。如果这一部分串行执行则会浪费其向量化机会,所以,这里需要对向量寄存器进行不充分的使用,即在向量寄存器中,有一部分数据是冗余数据,其余部分是有效数据,只针对有效数据进行计算,达到不充分向量化的目的。
向量寄存器的使用方式可以分为如图2所示的4种:1) 充分使用;2) 不充分使用——有效部分连续;3) 不连续使用;4) 不规则使用。

图2 向量寄存器使用方式
1.2 不充分向量化适用场景
当向量并行度低时,则需要不充分向量化,这里包括迭代内的并行和迭代间的并行,例如图3所示程序为SPEC2006 中435.gromacs的核心循环,其迭代间存在间接数组索引以及规约求和操作,而且迭代间极有可能存在数据依赖。所以其迭代间并行难以挖掘,而迭代内可以并行执行的数据个数为3,当向量寄存器可以处理的元素个数大于3时,则需要不充分向量化。

图3 示例程序—435.gromacs
当数据非连续时,例如循环跨步不是1时,导致数组访问非连续,如图4所示为FFT(快速傅里叶变换)中复数乘法计算。当然,此时如果可以利用数据整理指令,将离散的数据组合为一个向量,或者利用类似gather/scatter指令,以使得计算时对向量寄存器充分使用,这样效果可能会更好。但是一些处理器的向量指令集不支持丰富的数据整理指令,例如国产的申威处理器在主核上不支持shuffle指令,所以此时利用不充分向量化对程序进行并行度较低的向量计算也是比较好的选择。
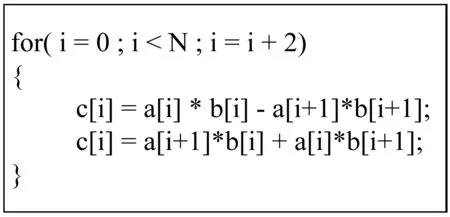
图4 示例程序—复数乘法计算
当循环中存在if条件语句时,受if条件语句的控制,对数据访问不规则,一些数据不需要参与当前计算。例如图5所示程序为SPEC2006 中456.hmmer的核心循环,所以这里需要向量寄存器的部分使用,对需要作数组赋值的部分进行不充分的向量化操作。

图5 示例程序—456.hmmer
2 不充分向量化的实现
不充分向量化的实现主要分为:不充分向量化读、不充分向量化计算和不充分的向量化写操作,而不充分向量化的实现最主要的目的是避免冗余数据写回到内存中,确保写回内存的数据均为有效数据。所以,读数据时,读取相应向量长度的数据,不需要计算的数据则为冗余数据,在计算过程中,冗余数据同样参与计算,但是将计算结果写回时,不写回冗余计算的结果,只将有效数据写回到内存中即可,这样就确保了计算的正确性。因此,如何实现不充分的向量化写操作是不充分向量化技术实现的关键,图6展示了不充分向量化写的预期功能,将向量寄存器中的部分数据写到内存中。
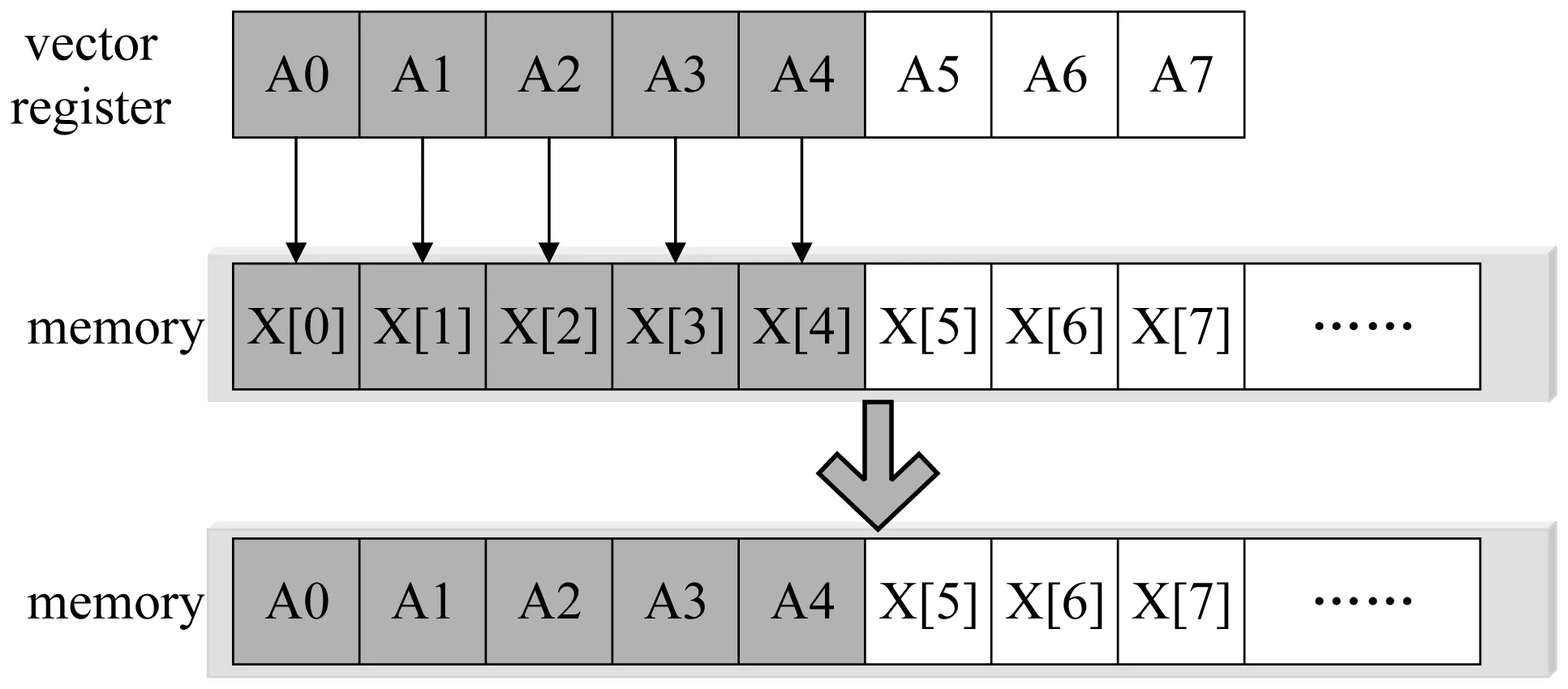
图6 不充分向量化实现过程
2.1 掩码指令实现
一些处理器支持的向量指令集支持掩码操作,例如:英特尔的AVX、AVX512指令集支持带掩码的存取操作,掩码指令写操作相对灵活,通过掩码控制,可以将向量寄存器中的任意数据写回到内存中,所以利用掩码,可以将有效数据写回到内存,完成不充分向量读操作。
如图7所示,示例程序向量并行度为3,当向量宽度为4时,程序可以利用不充分向量化达到并行执行的目的,利用掩码指令实现的具体操作如图8所示。

图7 示例程序—不充分向量化实现
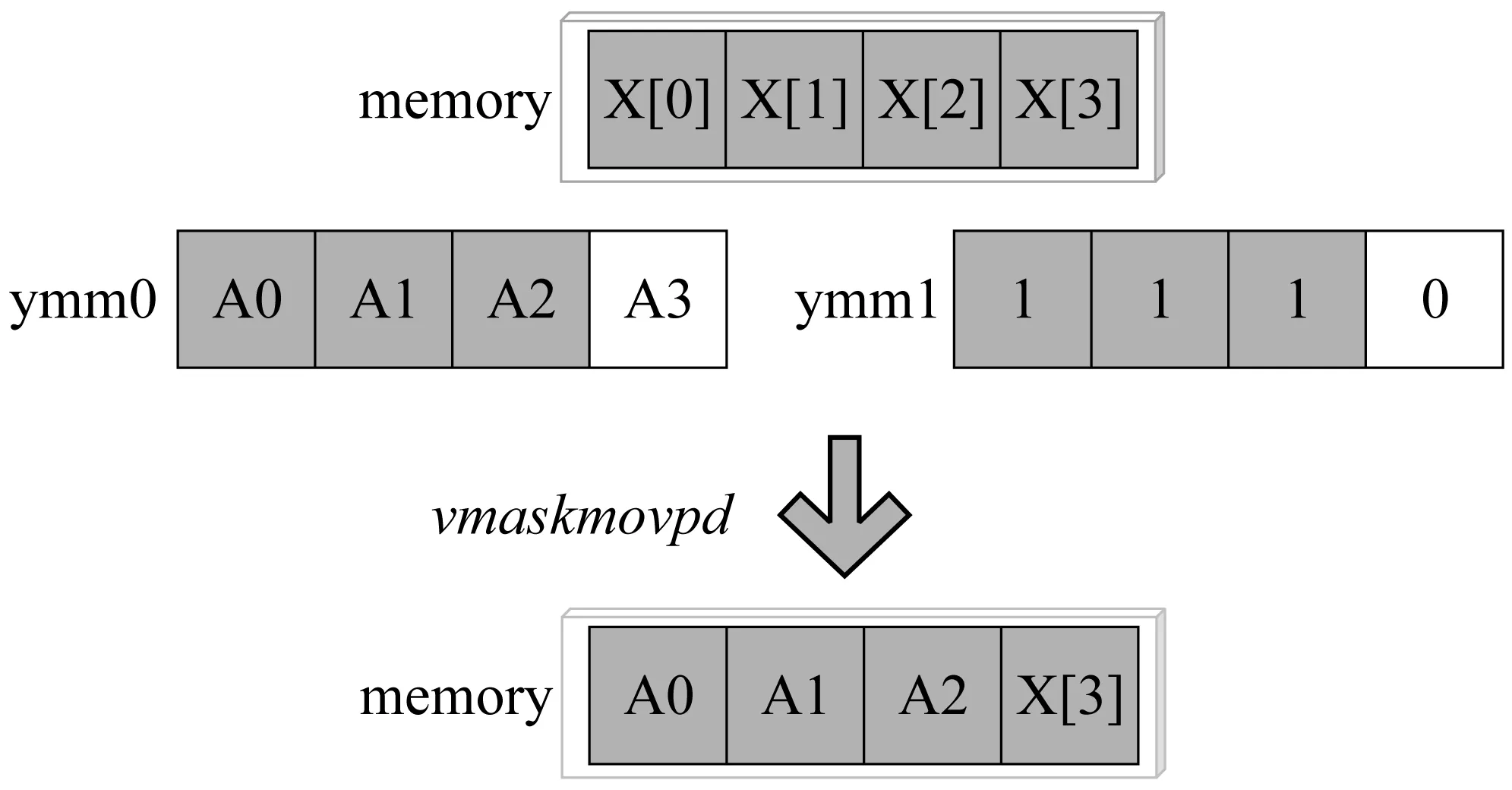
图8 不充分向量化的掩码执行实现
ymm0是要写回到内存中的数据,ymm1中保存的掩码。掩码指令写操作可以确保冗余数据不被写回到内存中去,程序得以正确执行,所以这里应确保掩码ymm1的正确性,在掩码操作中,有效槽位对应的掩码为1,无效槽位对应的掩码为0。当循环迭代内,程序的不充分向量化模式一致时,其利用的掩码是相同的,这样只需要在循环外获取掩码向量,如图8将其赋值给ymm1向量寄存器,此后的掩码存操作可以直接读取向量寄存器ymm1中的掩码,减少循环迭代内的指令条数,更好地提升程序执行的效率。
2.2 选择指令实现
一些处理器不支持带掩码的向量操作,比如:国产的申威处理器。因此,为了确保程序的正确性,需要将冗余数据所在的槽位填充为内存中相对应的数据。这样在进行向量写操作时,虽然也对不进行计算的数据进行了覆盖,但是覆盖的值仍为原始数据,相当于没有对内存中的数据进行修改。所以问题就在于如何将冗余数据所在的槽位填充为内存中相对应的数据,目前大多数的处理器均支持向量的选择指令,利用选择指令对两个向量中的元素进行选择,将向量中的冗余数据替换为内存中的数据,具体实现如图9所示。
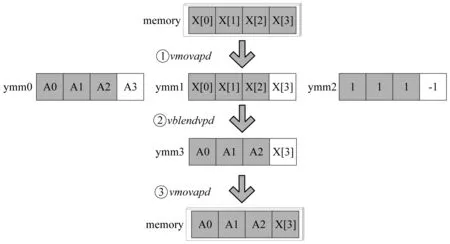
图9 不充分向量化的选择指令实现
图中:① 将原始数据利用向量的load指令加载到向量寄存器中;② 根据掩码对两个向量进行数据的选择;③ 将选择后的结果写回到内存中。当利用选择指令实现不充分向量化向量加载指令、向量选择指令以及向量存储指令时,这些额外的操作会使得不充分向量化的收益变小,甚至出现负加速。所以这里需要对程序进行收益分析,如果分析结果为不充分向量化会得到性能收益,则对循环进行不充分向量化变换。
3 不充分向量化收益分析
英特尔的AVX向量化指令集支持向量的掩码指令以及向量选择指令,所以可以分别用两种方式实现不充分的向量化。但是两种实现方式的收益是不同的,所以这里对图10所示程序用掩码指令以及选择指令分别进行测试,测试结果如表1所示。

图10 示例程序—不同实现方式收益分析

掩码实现选择指令实现程序(a)1.501.48程序(b)1.291.27
两种实现方式均有加速效果。利用掩码指令实现,其实现方式简单,可以很灵活地实现不充分的向量化,并且掩码访存指令开销比较小,一般会有比较好的加速效果。而利用选择指令实现不充分向量化需要对向量元素进行选择再写回到内存中,存在额外的开销,所以加速比略低于掩码实现,然而当处理器不支持掩码指令时,利用选择指令实现不充分向量化一定程度上也可以提升程序执行的效率。
示例程序比较简单,当不充分向量化的访存变得复杂时,两种实现方式的实现效率是不确定的,所以在生成相应的指令时,应利用代价模型计算向量化的收益以使程序的加速效果最优。
4 测试以及分析
4.1 实验测试环境
本文使用的硬件环境为处理器:Intel Xeon CPU E5-2620。基本频率:1.20 GHz;最大睿频频率:2.10 GHz;L1 cache 64 KB;L2 cache 256 KB;指令集扩展:Intel AVX;内存:64 GB。实验相关软件环境如表2所示。

表2 实验相关软件环境
4.2 非连续数据访问的向量化测试
为测试本文提出的不充分向量化方法的有效性,选择spec2006程序中的435.gromacs、456.hmmer、482.sphinx3程序,以及科学计算程序高精度有限体积方法CFV(Compact high order finite volume method on unstructured grids)的核心循环进行测试。这些程序的核心计算中存在循环迭代次数低或者基本块内同构计算语句条数低的情况,比较适合做不充分的向量化,分别对这些程序进行测试,并比较串行执行、不充分向量化优化前,以及不充分向量化优化后的执行时间,并做加速比对比,结果如图11所示。
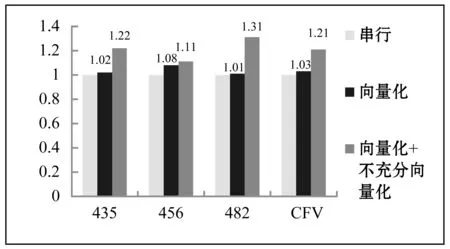
图11 科学计算程序不充分向量化加速比
通过测试结果可以发现,本文提出的不充分向量化方法可以有效地提升程序执行效率,但是456.hmmer加速效果不明显。因为其不充分向量化主要是由if条件语句引起的,而gcc在针对向量化进行循环分析时,如果循环内存在条件语句,则会使循环内的基本块个数变多,这时gcc不会对其向量化,导致其加速效果不明显,所以下一步将针对由if条件语句引起的不充分向量化进行深入研究。
5 结 语
随着人们对计算机期望的增高,要求计算机的计算速度越来越快,但是目前一些自动向量化算法没有很好地解决不充分向量化的问题,而且随着向量寄存器的位宽越来越大,在向量化方面需要针对不充分向量化进行更深入的研究,以提高程序的计算速度。基于此,本文对不充分向量化进行研究,提出不充分向量化的两种实现方法,并对这两种方法进行简单的收益分析,最后选择科学计算程序以及spec2006中的程序来验证本文提出方法的有效性。
但是不同的处理器支持的向量指令不同,而且对于不同的实现方式,其向量指令的代价也是不同的,并且不充分向量化中的访存问题对程序执行效率也是比较大的,所以采用何种方式实现不充分向量化都值得进一步研究。本文对其代价进行简单的分析,后续将设计更精确的代价模型,以使得程序执行效率达到最优。此外,利用向量的数据重组可以将不充分向量化变换为充分的向量化,提升程序的并行度。然而这会带来很复杂的访存问题并且数据重组的实现方案也是难以确定的,不过当计算任务比较大时,这种实现方案虽然复杂,但也会得到比较好的加速效果,值得进一步研究。最后,由if条件语句引起的不充分向量化在向量化分析时,存在分支控制,使得循环内基本块个数变多,gcc则不会对其进行向量化,所以程序还存在进一步提升性能的潜能,下一步将针对if条件语句下的不充分向量化进行研究。
