包簇框架中基于匈牙利算法的云计算能耗优化
2018-09-26陈世平
陆 乐 陈世平,2
1(上海理工大学光电信息与计算机工程学院 上海 200093) 2(上海理工大学信息化办公室 上海 200093)
0 引 言
云计算技术刚出现时,其主要方向是如何使其成为高性能计算的巨大数据中心,并通过按需使用来使得云服务商获得报酬而从中获利。然而,计算能力的日益普及也带来了问题,特别是能源效率问题。
在为数据的处理、存储和通信上,数据中心消耗了不可估量的能量,而消耗的能源对二氧化碳的消散具有巨大的影响,增加了温室效应所形成的碳排放对生物和环境造成破坏性影响。据估计,世界总能源的约10%被互联网消耗。数据中心的能源成本每五年翻一番。2011年,数据中心的能源消耗量约为10 000万千瓦,已造成40 568 000吨的二氧化碳排放。另根据美国自然资源保护委员会(NRDC)的数据,到2020年将达到1 390亿千瓦时[1]。
由此可知,在云计算中能耗问题是一个十分重要的研究方向,而对于能耗的优化,又有着不同的方向,例如计算机硬件的能源优化、虚拟化技术的提升、虚拟机放置策略以及云计算任务分配优化等。其中,虚拟机放置策略是非常重要的一个研究方向之一。现有的研究已经提出了一些十分有效的算法来实现虚拟机放置策略,用以提升服务器的使用率,从而使云计算更环保高效。
文献[2]中提出了降低云计算基础设施能耗的研究,该技术允许最大限度地减少物理服务器的数量,并允许虚拟机迁移到有限数量的服务器上,以便让集中式物理服务器利用最大资源,将其他服务器设置为低功耗模式。然而该算法需要依靠许多参数例如CPU、内存和网络带宽等来判断服务器过载或负载的时间。
此外,一般用于能耗优化算法的有能耗感知最佳适应递减算法PABFD(Power Aware Best Fit Decreasing)[3]。PABFD算法的思想是按照当前CPU利用率的降序对所有虚拟机进行排序,然后将新虚拟机分配给物理机,从而使得物理机的能耗最小化。
启发式算法也常常被用于解决此类问题。文献[4]提出了一种适用于虚拟机放置策略的改进遗传算法。文献[5]使用模拟退火算法,文献[6]使用粒子群算法进行节能的虚拟机放置。
除此之外,还有通过多目标的虚拟机放置策略来进行能耗优化。文献[7]通过使用粒子群算法,使得不同资源得到有效利用,从而实现了能耗最小化。在文献[8-9]中,通过使用遗传算法来解决多目标虚拟机放置,尽可能减少了运行物理机的数量以及通信流量,同时最大化利用了数据中心内同时使用的不同资源。文献[10]同样使用了遗传算法,通过最大限度地减少运行物理机数量并最大化资源使用效率来降低功耗。此外,文献[11-12]中,还使用蚁群优化算法来最小化能耗、减少额外的资源浪费。文献[13]通过蚁群算法重新放置虚拟机,以减少资源的能耗和负载平衡。在文献[14]中,通过使用生物地理优化算法BBO(Biogeography-Based Optimization)来同时降低功耗、减少资源浪费、提升服务器均衡性,并减少了虚拟机间流量、存储流量和迁移时间。
以上的研究方案均有以下的问题:其一是虚拟机与物理机的映射层次过于扁平,所有的映射关系都是在单个虚拟机与单个物理机之间进行,不但造成分配时间过长,而且一旦发生资源的变化,所有的映射关系都会重新分配。其二是能耗管理的灵活性不高,所有的能耗计算都是在物理机的基础上计算,没有更加高层次的精细化能耗管理方案,对于减少物理机集群节点的计算也不够清晰。
基于以上的文献总结,本文基于文献[15]提出了一种新的云计算虚拟机放置策略——即包簇映射框架。在这个框架的基础上,建立一个基于CPU使用率的能耗模型,并以最小化能耗为目标,通过不同的约束条件,使用改进的匈牙利算法进行虚拟机和物理机的高效分配,尽可能地提升分配速度并有效降低能耗,以满足未来绿色云计算的趋势。
1 问题描述
1.1 包簇概念
在包簇映射框架中,包(Package)和簇(Cluster)是两个重要的概念,分别是对应虚拟机和物理机多级层次的抽象定义。在这里,把一个资源共享的虚拟机群组称之为包,包的需求是需要根据云计算用户的需求所定制的。同时,组成包的元素不仅仅是虚拟机,也可以是包,也即多个低级别的包可以被组成一个高级别的包。通过这样的构建方式,可以由虚拟机、低级别包和高级别包组成一个具有清晰组织层次的需求结构。对簇来说也是一样的定义,物理机组成低级别簇,低级别簇又可以组成高级别的簇,从而同样组成一个多级别的层次结构。由此,虚拟机放置策略从原来的虚拟机与物理机之间扁平的映射关系转换为包与簇之间的映射关系。这样的好处就在于,把虚拟机与物理机之间的映射问题进一步降解规模,提高了虚拟机的分配效率以及资源共享,更易于实现对虚拟机和物理机的精细化管理。
1.2 包簇模型
有了以上的概述,就可以对包簇框架进行进一步定义。假设在包的层次结构中有一任意包γ,在包γ下可能存在M个虚拟机或子包v,在这里虚拟机或子包的数量限制为1≤v≤M。在包簇框架分配时,要将同级别的包γ分配给同级别的簇ρ,假设簇ρ下有M个服务器或子簇p,1≤p≤N。本文需要解决的是:在最小化能耗的前提下来将M个子包分配到N个子簇上,并且保证要使子包的子包(或虚拟机)映射到子簇的子簇(或物理机)上。
可以用一个资源分配矩阵表示包簇映射的框架关系:
(1)
式中:xv,p[t]代表在任意时间t中,子包v是否分配给子簇p。xv,p[t]=[1|0]也即xv,p[t]的取值只有0或1,当子包v分配给子簇p,则xv,p[t]=1,否则xv,p[t]=0。
在这里同时要求:
(2)
式(2)代表了在任意时间t内,每一个子包v都必须且只能分配一个子簇p上,但是一个子簇上可以承载多个子包,这是为了保证所有的需求包都可以获取对应的资源。
此外,假设i代表一种资源,存在J种资源。这个资源代表了每一个子包所需的资源量,每一项代表一个类型,相应的子簇也同样如此。
有了包簇映射的关系,还需要对其给予一些约束,即任意的子簇可用资源总量必须大于该子簇上所分配到的子包的需求总量:
(3)
式中:Rv,i[t]表示每一个子包v在时间t对资源i的需求总量。Ap,i[t]则表示每一个子簇p在时间t对资源i的可用总量,其中i=1,2,…,J。
1.3 能耗模型
服务器的能耗占数据中心的大部分总能耗,因此,本文的目标是最大限度地减少数据中心内所有物理机的总功耗。而物理机中的各个部分都会消耗功耗,如内存、网络接口、磁盘存储器、CPU、电源等,但能耗与CPU利用率之间存在线性关系[16-17]。所以可得:
Pph=k·Pmax+(1-k)·Pmax·uph,cpu
(4)
式中:Pph代表了物理机ph当前功率,k是空闲物理机运行所损耗功率的参数,Pmax则代表当前物理机在满负荷的时候所产生的最大能耗,也即额定功率,uph,cpu代表CPU使用率,0≤uph,cpu≤1。当uph,cpu=1时,Pph=Pmax,即物理机能耗达到最大功率,即额定功率;当uph,cpu=0时,Pph=k·Pmax,代表达到物理机达到最小功率,即空闲功率。
但式(4)仅仅是用于表示物理机的能耗,在包簇框架下,任意一个簇包含了一个或多个子簇或服务器,每个服务器的CPU使用率是各不相同的,同时每一个CPU的k和Pmax又都有所差异,要满足这些多样化的条件,需要对式(4)做一些调整和补充:
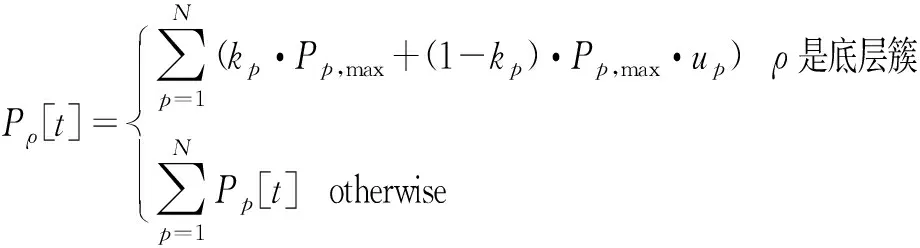
(5)
式中:Pρ[t]代表在时间t中,子簇p的上层功率,当簇ρ是最底层簇时,直接使用物理机的能耗进行计算,kp代表物理机p的CPU运行时所损耗功率的参数,Pp,max代表物理机p在CPU满负荷的时候所产生的最大能耗,up则代表物理机p的CPU使用率;当簇ρ不是最底层簇时,Pp代表子簇p的能耗,只需要将子簇p下的所有簇或物理机的能耗值相加,即可取得整个簇的能耗。
总能耗的公式为:
(6)
式中:t代表时间,1≤t≤T,M为子包V的个数,N为子簇W的个数,1≤V≤M,1≤W≤N。
在包簇框架下,包簇资源分配的目的就是使得能耗最小化:
(7)
约束条件为式(2)、式(3)。
可以看出,要使得能耗最小化,也就是尽可能降低CPU使用率,减少簇的个数,从而减少簇的能耗,同时又要保证每一个子包都分配到对应的子簇上,且需求的资源量没有超过可用资源量。
2 基于包簇框架的虚拟机放置算法
2.1 匈牙利算法
匈牙利算法HM(Hungarian Method)一种用于解决多项式时间分配问题的组合优化算法。它的工作原理是将给定的成本矩阵(Costs Matrix)最小化为机会成本矩阵(Opportunity Costs Matrix)。如果能够将成本矩阵最小化到每列和每行至少有一个0元素的程度,那么有可能做出更好的分配(机会成本都为0)。
匈牙利算法的一般数学模型是,存在N个资源,需要分配给N个对象,并保证总成本最低。公式如下:
Xi,j=[0|1]
(8)
式中:i=1,2,…,N,j=1,2,…,N,当Xi,j=0时,则说明资源i没有分配给对象j,当Xi,j=1时,则说明资源i分配给对象j。
假设Ci,j是资源i分配给对象j的成本,那么数学模型可以表示为:
(9)
(10)
(11)
式(9)表示最小化资源分配给对象,式(10)和式(11)分别代表了一个资源只能分配给一个对象,且一个对象也只能接受一个资源,两者之间是一一对应的关系。
对于匈牙利算法来说,虽然解决了分配问题,仍然存在以下问题:
(1) 分配问题,匈牙利算法只能是一个资源分配且只分配给一个对象,而在包簇映射框架中,多个包可以分配给一个簇;
(2) 匈牙利算法在大多数情况下是收敛的,但处理一些特殊情况,是无法找出最优解的,而且矩阵阶数越多,越会存在不收敛的情况,在包簇映射框架中,高阶分配矩阵是很常见的。
2.2 改进的匈牙利算法
根据上述的问题,本文参考了文献[18]提出的快速降阶匈牙利算法,在此基础上通过改进算法,设计了改进的匈牙利算法IHM(Improved Hungarian Method)。
对于提出的第一个问题,在计算成本矩阵前,可以做如下的处理:
(1) 将成本矩阵的列数按照行数进行转化,分割成一个行数和列数完全相等的矩阵。
(2) 如果分割的矩阵最后一个不满足行数和列数相等,那么就用×补足。
而对于第二个问题,则需要对整个匈牙利算法进行改进:
(3) 逐行(列)的每个元素减去该行(列)最小值,如果步骤(2)中补足的是行,则顺序相反。
(4) 逐行(列)检查是否存在单独的0元素,并且该0元素也是在列(行)上是单独的0元素,如果存在,则选中它,并删除该列和行的其他0元素。
(5) 如果同一行(列)存在0元素在其所在的列(行)是单独的0元素,那么就进行如下步骤:
① 在其所在的列(行)中找到所有的次小元素,并找出最大值;
② 选中最大值所在的0元素,划去所在的行和列;
③ 把刚才与其比较的行(列)减去自己行(列)的最小值。
(6) 如果列(行)存在单独的0元素,而在行(列)上的其他0元素不是该列(行)上的单独0元素,那么就选中这个0元素,划去其他的0。
(7) 如果所有行(列)上,都不存在单独的0元素,那么就任意选择0元素最少的行(列)中的任意一个0,如果行(列)存在相同的情况,就进行列(行)的0元素个数对比,选择最少的0元素。
(8) 重复步骤(3)至(7),直到找出所有的0。
2.3 实例验证
由于在包簇映射的框架中,经常会遇到包多于簇的情况发生(也即虚拟机的个数永远大于等于物理机的个数),现假定有7个包要分配到5个簇上,并且能够保证5个簇上的资源足够能满足7个包所需要的资源(上层包簇所分配的必要条件),它们之间的能耗矩阵如表1所示。
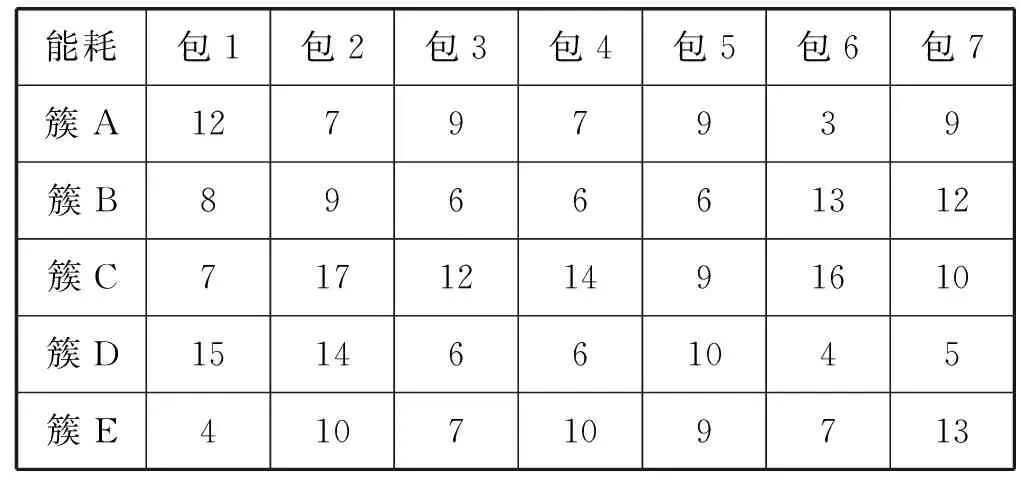
表1 分配7个包给5个簇的能耗矩阵
首先转换为成本矩阵:
并用×元素补齐第二个矩阵中缺失的部分:

接下来对两个矩阵进行改进的匈牙利算法求解:
矩阵1:
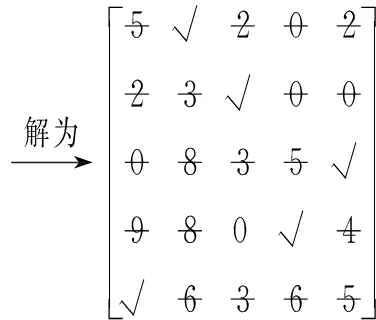
矩阵2:
所以,最后的分配方案为:
方案1:包1分配给簇5;包2分配给簇1;包3分配给簇2;包4分配给簇4;包5分配给簇3;包6分配给簇1;包7分配给簇4;
方案2:包1分配给簇5;包2分配给簇1;包3分配给簇4;包4分配给簇2;包5分配给簇3;包6分配给簇1;包7分配给簇4。
3 相关实验
3.1 能耗模型
在进行实验前,首先需要计算出式(4)中的Pmax和k。通过观察可发现,两者都是定值,也即k·Pmax代表了空闲功率。根据文献[19]可知如下参数,表2是CPU类型为Intel Core 2 Duo 2.93 GHz 和Intel Core i5 2.5 GHz的服务器的能耗值,单位为W。

表2 不同CPU的服务器参数
3.2 仿真实验
为了验证本文IHM算法的有效性,在Cloudsim[20]上进行仿真实验。要对比的算法分别是:基于包簇映射框架下改进的匈牙利算法IHMPC(Improved Hungarian Method based on Package-Cluster),在引言中所提及的能耗感知最佳适应递减算PABFD(Power Aware Best Fit Decreasing)[3],以及混合遗传算法HGA(Hybrid Genetic Algorithm)[4]。
实验主要分为两部分,实验1是验证三种算法的分配时间;实验2是验证三种算法在相同时间内的CPU使用率以及能耗变化情况。
实验1分配时间
分别用不同数量的虚拟机和物理机进行分配时间的测试。在IHMPC算法中,包簇映射的层次结构为3层结构,顶层包之下各有10个包,二级包下的虚拟机个数分配为虚拟机总个数除以10;簇的分配个数比包少一半,但层次结构相同。例如,500台虚拟机分配到150台服务器上,包簇结构为1个顶层包,10个二级包,50个虚拟机;1个顶层簇,5个二级簇,50个服务器。
图1是三种算法在不同虚拟机和服务器个数的情况下的分配时间。可以看出,前两种算法在虚拟机和服务器数量变多的情况下,分配时间也逐渐变多,而IHMPC始终保持了比较良好的分配时间,在虚拟机数量、服务器数量超过600/220台时,平均比PABFD算法快了将近56.2%,比HGA算法快了将近34.8%。
实验2CPU使用率以及能耗
为了更好地模拟数据中心的庞大数据量,在实验2中模拟了10 000台服务器和15 000台虚拟机。需要特别说明的是,在包簇映射框架下,需要对包的结构层次进行划分,分为5层包结构,如图2所示。
本次实验共划分了1个顶层包、3个二级包、5个三级包、10个四级包,在这里的四级包又称为底层包,每一个底层包中又包含了100台虚拟机。相应地,簇结构也要划分为2个二级簇、10个三级簇、10个四级簇,每一个底层簇又包含了50个服务器。
图3是在不同时间下,三者算法的CPU使用率,可以看出,在相同的条件下,本文提出的IHMPC算法,由于能够使虚拟机较为平均地放置在物理机上,与前两者相比,在CPU使用率上始终不超过68%,较好地保持了在较低的水平,实现了负载均衡。
图4是在不同时间下,三者算法的能耗值曲线图。从图中可以看出,由于保持了较低的CPU使用率,使得改进算法的总能耗也比前两种算法功耗更少,尤其在25分钟至50分钟左右的CPU使用高峰时段,平均比PABFD算法的总能耗降低了4.8%,比HGA算法的总能耗降低了3.7%。这证明所提出的IHMPC算法在能耗优化上有明显的优势,也满足了云计算中虚拟机的快速分配以及服务器的负载均衡。
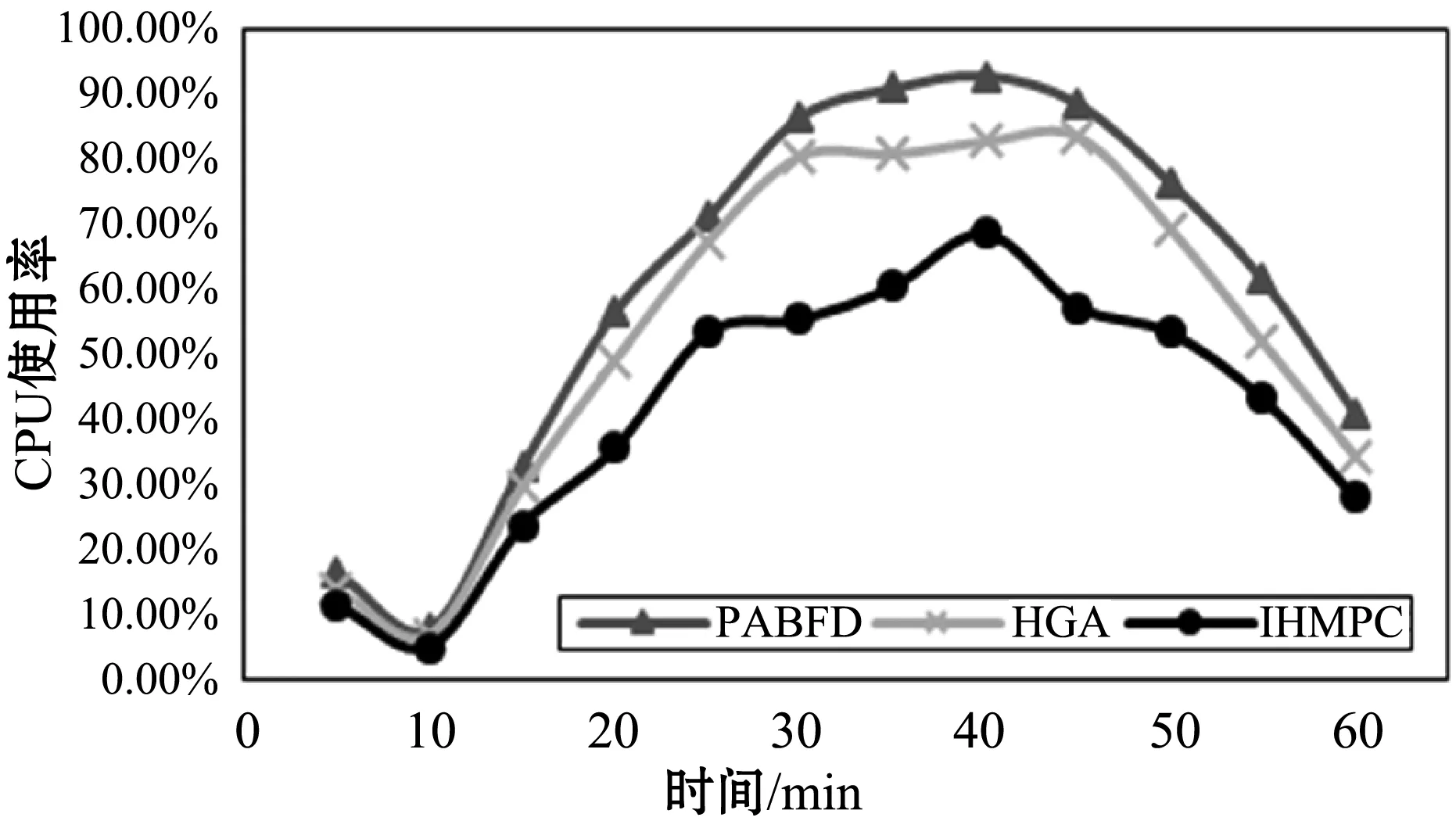
图3 不同时间下的CPU使用率
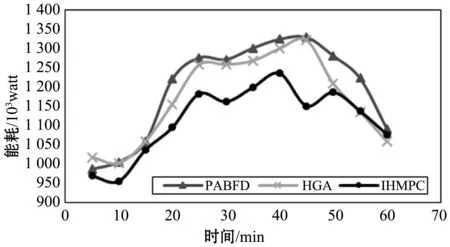
图4 不同时间下的能耗值
4 结 语
本文首先沿用了一种新的虚拟机放置策略,即基于包簇映射框架的资源分配结构,在此基础上,设计了能耗模型和改进的匈牙利算法来进行能耗优化。所提出的算法同时满足了分配速度和能耗。在虚拟机和物理机数量巨大的情况下,数据中心依然能够较快地完成分配。在能耗上,始终保持CPU使用率在一个较平均的水平,以达到降低能耗的目标。实验结果表明,与其他算法相比,该算法在相同条件下可以大大降低云计算系统的能耗。
