大数据时代的移动图书管理系统的研究与实现
2018-09-20张晴李琦程彭洲
张晴 李琦 程彭洲
摘要:大数据时代,深入挖掘图书馆海量图书信息和借阅信息等数据资源,是实现图书馆高质量个性化服务的核心。本文分析图书管理系统中现存的问题,提出基于数据挖掘技术的移动端图书管理系统的设计和解决方案,选择关联规则算法实现图书推荐,聚类算法实现书友推荐,分类算法实现新书上架预测,从而提升用户的体验,提高图书资源的使用率。
Abstract: In the era of big data, digging deep into the data resources such as massive library information and lending information is the core of the library's high quality and personalized services. This paper analyzes the existing problems in the library management system, proposes the design and solution of mobile library management system based on data mining technology, and chooses association rules algorithm to implement the recommendation of books. Using book clustering algorithm to achieve book recommendation, classification algorithm to achieve new book prediction. This will enhance the user's experience and increase the use of library resources.
關键词: 数据挖掘;移动图书管理;个性化服务
Key words: data mining;mobile library management;personalized service
中图分类号:G250.7 文献标识码:A 文章编号:1006-4311(2018)26-0044-03
0 引言
随着互联网迅速覆盖,移动用户持续增加,各类信息呈爆炸型积聚,大数据时代来临。图书管理系统作为服务大众的平台,其数据规模庞大、可分析性高,传统的数据处理方式和PC设备已无法满足需求,深层次的数据挖掘将会为用户提供更优质的服务。
从图书馆大量的信息资源中准确高效地获取图书信息,提升用户的体验,已成为学者的热门研究。刘军军研究了移动图书馆服务平台框架结构,提出了建立一个集成资源整合、服务和用户的一站式学习支持环境的移动图书馆服务平台[1]。杨利军等发现了图书馆个性化服务中大数据可视化分析的重要意义,研究设计了一种具有较完善可视化分析功能的系统框架,从而保障读者的个性化阅读[2]。Yi等着重讨论了将数据挖掘算法中的关联规则算法和聚类算法应用于高校图书馆大数据个性化推送服务 [3]。常雅红通过实例分析说明了大数据环境下基于数据挖掘的数字化图书馆服务新模式,提出了包括智能化推送服务、移动服务等在内的四项内容[4]。熊太纯等为更好地满足读者的个性化需求,提出整合图书馆的馆藏信息,充分利用Web2.0、云计算等网络信息技术,改进图书馆的个性化互动服务方式[5]。李艳等借助宏观上对高校图书馆大数据挖掘与决策分析体系的研究及设计,证明基于“大数据+微服务”模式的重要价值[6]。
本文分析图书管理系统中现存的问题,基于关联规则、聚类、分类等数据挖掘算法提出相应的对策,构建基于数据挖掘技术的移动图书管理系统,实现图书推荐、书友推荐、新书上架预测等个性化服务,从而提高图书资源的使用率和用户的满意度。
1 现存问题和对策分析
目前,大多数图书管理系统实现在PC端,使用受到时空的限制,且往往只实现了基础层面的图书信息整合、用户基础借阅、管理员基础信息操作等功能,能满足有明确借阅目标的读者的需求,而绝大多数读者容易迷失在海量的图书资源中,尽管目前多数系统支持热门书籍的推荐,但用户转化率也不一定理想,读者需要的是个性化的推荐。对于图书管理员而言,如何优化选择图书资源,提高图书资源的利用率也很难提供帮助。针对以上问题,提出相应对策:
1.1 移动端的图书管理系统的设计
移动互联网和智能手机的飞速发展使得用手机访问互联网资源成为主要的上网方式,手机上网有着它特有的优势。一方面,手机上网不受地域限制,基于智能手机的图书借阅管理系统使得读者能更方便地接触到图书信息资源;另一方面,手机上网更符合大众的日常生活习惯,各年龄段均能够熟练使用智能手机,通过手机端快捷地访问图书信息资源。
1.2 选择Apriori算法实现图书推荐
图书推荐功能的实现,可以满足读者对兴趣书籍的免查询浏览。当读者进入图书借阅系统,系统会在醒目位置为读者进行相关书籍推荐,大大减少读者寻找及查询书目的时间,提高图书借阅效率。将所有读者的借阅记录作为源数据,采用关联规则分析的Apriori算法,发现在同一次借阅事件中,出现不同图书的相关性,推荐同时借阅的图书。采用序列模式挖掘的类Apriori算法,发现图书借阅在时序上的规律,根据读者已借阅的图书,归还以后,推荐后续借阅的图书。
1.3 选择聚类算法实现书友推荐
大数据时代下社交网络普及,互联网用户乐于在虚拟网络、移动端社交平台中结识朋友,书友推荐使读者更易找到相同兴趣者,解决现存系统缺乏人性化交流的问题,增加用户交流度,侧面提高读书效率和兴趣。书友推荐是未知类别及类别数的对象划分,将相同兴趣读者聚簇,本质上是将读者进行模糊聚类,形成具有最高隶属度的簇。在为读者进行书友推荐时,识别读者所属类别进而进行同类推荐即可,推送顺序则按照与读者的距离值依次递减排序。
1.4 选择分类算法实现新书上架预测
管理运营者更多考虑到的是图书馆藏利用率问题,书籍信息海量多样,甚至鱼龙混杂,需要通过引进预计受欢迎的新书、淘汰借阅率和兴趣度低的旧书优化图书馆藏结构。采用分类分析法中的朴素贝叶斯分类器,利用借阅数据作为训练样本集,通过贝叶斯定理,提供从先验概率计算后验概率,从而获得图书分类器,预测新图书所属类别,即新书是否受欢迎,从而能大大减少传统图书馆人工管理带来的主观偏差[7]。
2 系统的设计
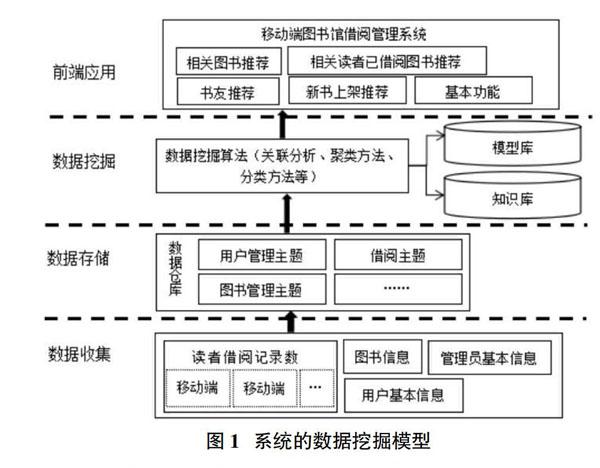
基于图书管理系统现存问题和对策的分析,构建基于数据挖掘技术的移动图书管理系统模型,如图1所示,模型中主要模块分为数据收集、数据存储、数据挖掘和前端应用。通过收集读者手机借阅数据、管理员手机的管理数据等,存储到数据仓库当中,进行数据的预处理,分为用户管理主题、图书管理主题、借阅主题等,接着应用数据挖掘相关算法,如关联规则、聚类、分类等,分析用户的借阅行为,最后结果体现在前端应用层,实现图书个性化推荐、新书上架预测等个性化服务。
3 系统的实现
基于Android平台实现了移动端的图书信息管理系统,取名泰科图书,图书信息来源于本校图书馆馆藏图书,在本校试运行三个月,积累一定的图书借阅数据,能够利用数据挖掘算法实现个性化服务功能。
3.1 图书推荐功能
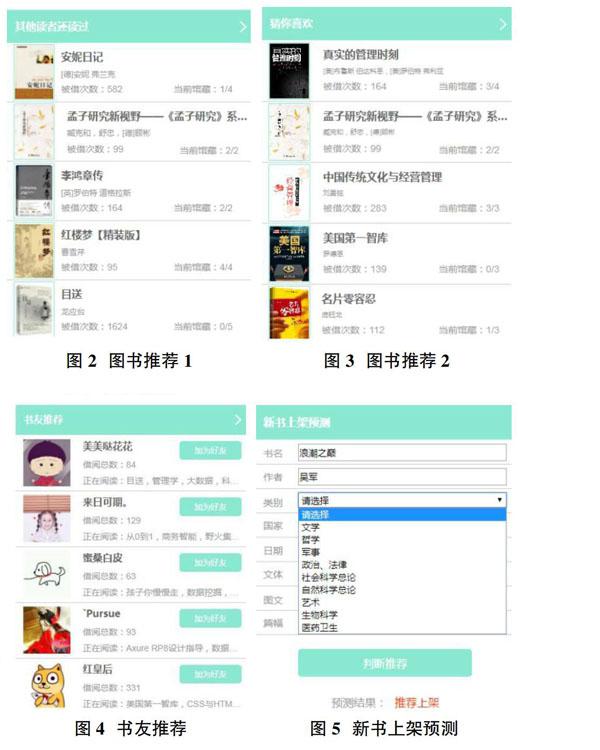
在借阅模块,通过“其他读者还读过”实现一次借阅多本图书的推荐,如图2所示。该功能的实现,将输入的借阅主题数据作为事务数据集,读者所借阅的书目信息即为项集,由管理员设定最小支持度阈值和最小置信度阈值,利用Apriori算法,產生频繁项集,输出结果表述为满足条件的图书项集。通过“猜你喜欢”实现归还已借图书后相关图书的推荐,如图3所示。该功能的实现,首先将借阅数据按时序转换为序列借阅数据集,利用类Apriori算法,产生序列模式,输出结果表述为满足设定最小支持度阈值的图书项集。
3.2 书友推荐
在为读者进行书友推荐时,识别读者所属类别进而进行同类推荐即可,推送顺序则按照与读者的距离值依次递减排序,如图4所示。该功能的实现首先将读者类型大致分为文学艺术爱好者、政法经济爱好者、自然社科爱好者等6类,以“6”作为聚簇数;选取借阅主题数据,从读者目标中选取符合数量的初始簇中心,设置读者各类书目借阅数量为距离参考值,计算每个目标对象与簇中心的欧几里得距离、根据距离划分不同的簇;算法迭代执行,直到结果收敛,输出即为6类读者类型的聚类划分。
3.3 新书上架预测
管理员端实现了新书上架的预测功能,每当要上架新书,管理员可以在“新书上架预测”页面输入书名,并在下拉列表中分别选择图书细节信息,点击“判断推荐”按钮系统将自动给出分类判断,如图5所示。该功能的实现,首先选择图书的类别、国家、出版社等属性作为属性数据集,选择借阅主题数据仓库作为训练集;接着,通过训练集中每类样本所占的比例估计每项属性的先验概率值;然后,当有测试样本需要分类时,由朴素贝叶斯分类器得到样本在不同属性下的后验概率;最后,选取后验概率最大值对应的类别(四种:不适合上架、谨慎上架、可以上架、推荐上架)即可。
4 结语
大数据时代,充分考虑读者群体和图书管理者的综合个性化需求,对数据资源进行深入挖掘,完善数字化图书馆建设,实现个性化服务,不仅能提高读者的借阅效率,更提升了读者互动活跃度、间接提升读者的阅读积极性、扩大了读者的阅读面,同时也为图书管理工作提供了极大的便捷,提高了图书资源的使用率。
参考文献:
[1]刘军军.移动图书馆服务平台框架结构研究[J].农业图书情报学刊,2018,30(4):52-55.
[2]杨利军,高军.图书馆个性化服务中的大数据可视化分析与应用研究[J].现代情报,2015,35(7):68-72.
[3] Yi C,Xia Y,Zhang Zy.Study on the Personal Push Service of University Library Based on Big Data Mining[J].Advanced Materials Research,2014(1).
[4]常雅红.基于大数据挖掘的数字化图书馆服务新模式研究[J].图书情报导刊,2016(7):11-15.
[5]熊太纯等.CALIS贮存图书馆个性化服务研究[J].图书馆工作与研究,2014(12):94-97.
[6]李艳,吕鹏,李珑.基于大数据挖掘与决策分析体系的高校图书馆个性化服务研究[J].图书情报知识,2016(2):60-68.
[7]廖宇峰.数据挖掘技术在图书馆的应用研究[J].四川图书馆学报,2017(216):33-36.
