一种针对类别不平衡的代价敏感集成算法
2018-09-17田爱奎吴志勇
谭 浩,田爱奎,吴志勇
(山东理工大学 计算机科学与技术学院,山东 淄博 255049)
由于现代社会信息爆炸式发展,如何从海量的信息中提取有用的知识越来越受到重视.其中分类是一种重要方法.分类已经被广泛运用到各领域,而大多数的分类方法都要求各种类型的数据具有较为均匀的分布,但是有一些特殊的事件比较罕见.针对罕见事件的分类是许多领域中常见的问题,如欺诈交易、网络入侵检测和医学诊断等.而分类中伴随着分类成本不同的问题[1],如将病人误诊为健康人的代价比将健康人误诊为病人的大得多,后者只是增加成本,而前者会导致失去生命.针对包含罕见事件的不平衡数据集的研究方法主要分为两个方面:数据层方法和算法层方法[2].数据层方法是先对数据进行预处理,然后用于学习.主要的方法可分为过抽样和欠抽样两种.过抽样是通过增加数据集中少数类实例的数量以提高少数类分类精度,本文所用的SMOTE算法就是一种过抽样算法;欠抽样就是减少数据集中多数类实例的数量来平衡数据集的类别分布,如文献[3]为此提出了一种基于样本权重的欠抽样方法,该方法引入了样本权重来反映样本所处的区域,通过多次聚类修改样本权重,然后根据样本权重进行抽样.过抽样与欠抽样都可以达到平衡数据集的目的,但一般欠抽样算法优于过抽样算法[4].算法层方法就是通过修改分类算法本身,来提高少数类的分类精度,当不同类被错分的代价不等时, 便引出了代价敏感(Cost-sensitive) 分类,较为著名的有 MetaCost方法[5],但它不能估计后验概率;FU[6]提出一种多标签代价敏感分类集成学习算法,算法的流程类似于自适应提升,可以自动学习多个弱分类器来组合成强分类器;文献[7]提出了一种局部代价敏感算法.代价敏感学习要求设计的分类器满足错分代价最小而非分类错误率最小,从而提高错分代价高的样本分辨率.本文将两者结合,通过在AdaCost算法每次迭代前插入合成的少数类以提高分类器在分布不平衡的数据集上的表现,实验验证了算法的有效性.
1 评价标准和相关算法
1.1 不平衡数据集分类的评价标准
表1所示的混淆矩阵通常被用于评估机器学习算法的性能.在分类问题中,假设C类为少数类,在代价敏感分类算法中也被称为正类,而NC作为所有其他类的结合,在代价敏感分类算法中也被称为负类,在检测C类时有四种可能的结果.通过表1,精确率(Precision),召回率(Recall),F-measure有如下定义:

式中:β表示Recall和Precision的相对重要性,在本文中β=1.只有Recall和Precision都比较大时,F-measure才会相应比较大.因此,F-measure可以合理评价分类器对于少数类(正类)的分类性能.
表1 分类混淆矩阵
Tab.1 Confusion matrix defines

预测的正类“C”预测的负类“NC”真实的正类 “C”真实的负类“NC”TPFPFNTN
1.2 相关算法
1.2.1 SMOTE算法
SMOTE (Synthetic Minority Oversampling Technique)算法[8]是为减小数据集中少数类影响而提出的人工合成抽样技术.算法在“特征空间”中操作,而不是在“数据空间”中合成少数类实例,算法伪代码如图1所示.

图1 伪代码Fig.1 Pseudocode
对于连续性特征:
(1)取少数类样本的特征向量和它K近邻中任意一个少数类样本的特征向量之间的差.
(2)用0到1之间的随机数乘以这个差.
(3)将第(2)步计算结果添加到原始特征向量的特征值中,从而创建一个新的特征向量.
对于标称特性:
(1)少数类样本的特征向量和它K近邻中少数类样本的特征向量进行投票选择.在平局的情况下,随机选择.
(2)将该值分配给新合成的少数类样本.
使用这种技术,可以在连接少数类样本及其最近邻的线段上创建一个新的少数类样本.通过合成少数类实例可以拓宽决策树(如C4.5)、规则学习算法(如RIPPER算法)的决策区域[9].
1.2.2 AdaCost算法
AdaCost算法是AdaBoost算法[10]的一个变种.AdaCost算法[11]保持了AdaBoost算法核心理论.而在AdaCost算法中,权值更新规则给予被错误分类的错分代价高的样本更高的权重,而被正确分类的错分代价高的样本较为保守的权重.这是通过在权重更新公式中引入误分类代价调整函数来实现的.在这种更新规则下,错分代价高的样本权重较高,而错分代价低的样本权重相对较低.这样,每轮迭代产生的弱分类器都更加关注错分代价高的样本,最终投票产生的强分类器也将正确地识别错分代价更高的样本.
2 Cost-SMOTEBoost算法
AdaCost通过错分代价来更新每轮迭代中训练样本的权重,给予少数类(正类)更大的权重,算法更关注那些少数类样本.通过SMOTE合成实例可以改善样本的类别分布.本文将两者结合,提出了Cost-SMOTEBoost算法,在每轮迭代的开始向数据集中插入合成的少数类实例,改善少数类的分布,同时分类结果向更被人们关注的错分代价更高的少数类(正类)倾斜,通过关注分类困难的少数类(正类)样本来提高整体的精度.利用SMOTE人工合成实例也可以增加集合中分类器之间的多样性,因为在每次迭代中,产生了不同的合成训练集.
Cost-SMOTEBoost算法流程为:

(2)在每一轮迭代中都会调用一个弱分类器h(xi)进行训练,并运用SMOTE算法合成少数类(正类)实例加入训练集中,改善训练集中类别的分布.


3 实验与分析
3.1 数据集
实验是在表2中3个数据集上进行的.这些数据来源于UCI公开数据集[12-13]. Credit-g是来自德国的信用卡数据,由一组属性描述一个人的行为,评估每个人信用风险的高低;Seismic-bumps是采矿地震预测数据,采矿活动经常发生采矿威胁,这种威胁的一个特例就是在许多地下矿井经常发生地震危险,由于地震过程中低能和高能现象的地震事件数量之间不相称的复杂性,导致统计技术不足以预测地震灾害.因此,有必要利用机器学习方法寻找更好的危险预测方法;Thoraric Surgery是在弗罗茨瓦夫胸外科中心回顾性地收集2007—2011年期间接受肺癌切除术患者的数据,该中心与波兰的弗罗茨瓦夫医科大学和下西里西亚肺病研究中心的胸外科有关,研究数据库是国立肺癌登记处的一部分.
表2 实验数据集
Tab.2 Dataset

数据集多数类(负类)实例数量少数类(正类)实例数量属性数量类别Credit-gSeismic-bumpsThoraric Surgery7002 41440030017070211917222
3.2 实验结果与分析
图2显示了Cost-SMOTEBoost算法和AdaCost算法在Credit-g数据集上的对比.随着迭代次数的增加两个算法的精确率和召回率都有不同程度的增加,两个算法有着接近的精确率,但是Cost-SMOTEBoost算法明显提高了召回率,得到了更高的F-measure值.

图2 在数据集Credit-g上的对比Fig.2 The contrast on the Credit-g dataset
图3显示了Cost-SMOTEBoost算法和Adacost算法在Seismic-bumps数据集上的对比.两个算法在经过5次迭代后精确率和召回率都趋于平稳,同样两者的精确率比较接近,Cost-SMOTEBoost算法在召回率上有更好的表现从而得到了更高的F-measure.

图3 在数据集Seismic-bumps上的对比Fig.3 The contrast on the dataset Seismic-bumps
图4显示了Cost-SMOTEBoost算法和Adacost算法在Thoraric Surgery数据集上的对比.在迭代初期两算法的表现比较接近,随着迭代次数的增加Cost-SMOTEBoost算法的精确率和召回率都超过了AdaCost算法.
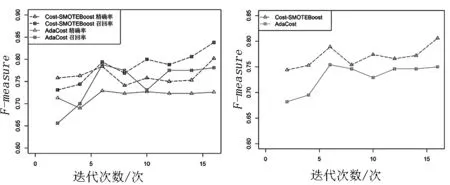
图4 在数据集Thoraric Surgery上的对比Fig.4 The contrast on the dataset Thoraric Surgery
由图2、图3和图4可知,Cost-SMOTEBoost算法在3个数据集上有更高的召回率,它在不降低精确率的情况下,提高了召回率从而得到了更高的F-measure.
4 结束语
本文提出了一种基于AdaCost的集成算法——Cost-SMOTEBoost算法,该算法通过在每轮迭代前加入由SMOTE算法合成的人工实例以改变数据的分布,同时利用成本敏感函数使分类结果向更被人们关注、错分代价更高的正类倾斜.在实验中使用的数据集包含不同程度的不平衡和不同的规模,从而提供了一个多样化的测试,以精确率(Precision),召回率(Recall)和F-measure为度量指
标对算法进行评价,并与AdaCost算法进行比较.实验结果表明,Cost-SMOTEBoost算法平衡了精确率和召回率,在不降低整体精确率的同时提高了针对少数类(正类)的表现.
