基于三维激光雷达的无人车障碍物检测与跟踪∗
2018-09-14谢德胜徐友春王任栋苏致远
谢德胜,徐友春,王任栋,苏致远
(1.军事交通学院研究生管理大队,天津 300161; 2.军事交通学院军用车辆系,天津 300161)
前言
近年来,随着人工智能和机器人技术的不断发展,无人驾驶汽车作为人工智能领域的一个重要的分支已经成为国内外的研究热点。无人车主要通过使用相机、激光雷达、GPS等传感器对周围环境进行实时感知[1]。障碍物检测和跟踪是无人车环境感知的重要内容,对无人车的路径规划和决策控制有重要影响。
国内外对障碍物检测和跟踪的研究主要集中在基于计算机视觉的方法[2]和基于激光雷达的方法[3-4]上。基于深度学习的视觉目标检测和跟踪技术已经获得了很大的发展[5],但基于计算机视觉的方法易受光线影响而使检测和跟踪效果不佳。激光雷达因其能够获得障碍物的基本形貌、距离和位置等信息,同时具有精度高等优点,而被广泛运用于无人装备的障碍物检测和跟踪中。
文献[6]中建立了包含目标中心点位置、速度等用以表示动态障碍物信息的盒子模型,并采用了MHT(多假设跟踪算法)在一定程度上解决了多运动目标的跟踪问题。但未考虑在跟踪过程中点云会随动态障碍物运动而变化,且在跟踪过程中,所采用方法的最小变化量为1个栅格,导致跟踪结果不理想。文献[7]中将四线激光雷达与三维激光雷达HDL-64E相结合实现了对动态障碍物的检测和跟踪,一定程度上改善了文献[6]中存在的问题,但未能很好地解决障碍物运动过程中点云变化致使跟踪点不稳定的问题,其实验结果中速度方向的剧烈变化反映了此点。文献[8]中则采用定向包围体来描述目标障碍物,首先除去异值点云,然后用RANSAC算法找出剩余点云的主成分分布方向,进而得到障碍物的航向角。这种做法得到的结果比文献[6]中方法的结果更加稳定,但实际情况中受车辆遮挡或是自身遮挡因素的影响易出现过拟合的情况。
为解决上述文献方法中存在的瑕疵,本文中提出了一种基于三维激光雷达障碍物检测和跟踪的方法。首先将路面分割后的点云栅格化,再进行栅格增补。在障碍物聚类之后,结合无人车RTK-GPS数据和INS的航向角数据实现了多帧融合的静态障碍物检测,并利用静态障碍物检测结果形成的可行驶区域和动态障碍物模板匹配算法检测出了动态障碍物。最后,利用标准卡尔曼滤波器对动态障碍物的运动状态进行了平滑滤波,得到了稳定可靠的跟踪结果。
1 点云预处理
本文中所采用的HDL-64E三维激光雷达由Velodyne公司生产。每帧可以产生近13万个点云,这些点云是在同一空间参考坐标系下可以表征障碍物空间分布特征的大量点的集合。面对如此巨大的数据量,须对点云进行预处理以方便后续进行障碍物检测和跟踪。
先采用文献[9]中路面分割的方法去除了路面点云,在无人车前后左右各40m范围内对剩余的点云采用40cm×40cm大小的栅格进行栅格化。栅格内点云数量小于2个的视为非障碍物栅格,栅格内点云数量大于等于2个的栅格视为障碍物栅格。当两个障碍物栅格中间存在非障碍栅格时,若二者的最大点云高度相近,则将中间的非障碍物栅格变为障碍物栅格,并将原两端障碍物栅格的属性值赋给非障碍物栅格,沿无人车纵向增补时,如果中间非障碍物栅格的数量超过3个则不再增补,沿无人车横向增补时,如果中间非障碍物栅格的数量超过1个则不再增补。栅格增补可以极大地增强一帧点云反映无人车周边环境的能力,从而完成一帧点云的栅格化,图1是去除地面点云后进行栅格增补前后的对比。

图1 栅格增补结果
2 障碍物检测
利用文献[10]中的聚类算法可实现对障碍物栅格的聚类。在完成聚类之后,先进行静态障碍物的检测,再进行动态障碍物的检测。目前,单帧静态障碍物的检测结果中往往存在漏检的情况,因此提出在单帧静态障碍物检测结果的基础上采用多帧融合的方法来检测静态障碍物。在进行动态障碍物检测时,单一依靠模板匹配算法[6]易出现误检的情况,本文中提出先利用静态障碍物检测结果确定出可行驶区域,然后再结合动态障碍物模板匹配算法来对可行驶区域内的动态障碍物进行检测的新思路,有效地避免了部分动态障碍物的误检。
2.1 静态障碍物检测
单帧点云中静态障碍物的聚类结果主要包含2种:(1)第1种聚类结果包含路边界及与之相邻接的静态障碍物如建筑物等,这类聚类结果的长度和宽度明显大于车辆、行人等动态障碍物的长度和宽度。(2)第2种聚类结果则是只包含路边界,这类聚类结果的显著特征是狭长,且高度明显低于较长的公交车和高速公路上的货物运输车。
通过静态障碍物聚类结果的几何特征能检测出单帧中的部分静态障碍物。因运动的车辆等动态障碍物的遮挡和HDL-64E激光雷达不同激光线之间间距的影响,将使路边界等静态障碍物易出现漏检的情况,提出在单帧静态障碍物检测结果的基础上采用多帧融合的方法来检测静态障碍物。
采用多帧融合检测静态障碍物须先进行2帧的融合,在此基础上再实现连续多帧的融合。利用文献[11]中经纬度转平面坐标的方法将记录各帧点云数据时无人车RTK-GPS的经纬度转到大地平面直角坐标系XOY下,可以得到无人车第t帧时在坐标系XOY下的平面坐标(xt,yt),大地平面直角坐标系XOY的y轴始终指向正北方向,x轴始终指向正东方向,坐标系原点O为无人车第一次记录RTKGPS时的位置,进而可得任意连续2帧中无人车的相对平移量(Δxt,Δyt):

式中(xt-1,yt-1)为无人车第t-1帧时在坐标系XOY下的平面坐标。
由于在记录各帧点云时,无人车的航向不同,INS提供的航向角数据会不一样,将2帧点云融合时需考虑二者之间航向角β的关系,参考图2,首先将第t-1帧的车体坐标系ot-1-xyz下静态障碍物的点云先旋转到第t-1帧与大地平面直角坐标系XOY坐标轴方向相同的局部车体坐标系ot-1-x′y′z下,然后根据2帧的相对平移量(Δxt,Δyt)平移到第t帧的坐标系ot-x′y′z下,最后再从第t帧的坐标系otx′y′z旋转到第 t帧的车体坐标系 ot-xyz下,完成2帧静态障碍物点云的融合。
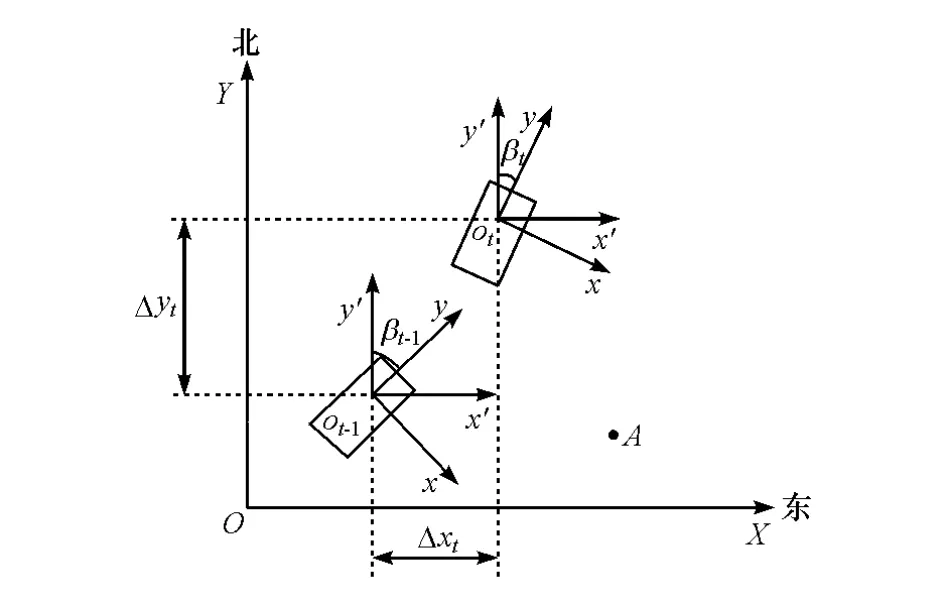
图2 静态障碍物2帧融合示意图
若第t-1帧无人车的航向角为βt-1,第t帧无人车的航向角为βt,定义为无人车运动方向与坐标系XOY正北方向的顺时针夹角,将第t-1帧属于静态障碍物的一个扫描点A点()旋转平移到第t帧的局部车体坐标系 ot-x′y′z下的坐标():
式中R1为旋转平移变换矩阵。
经旋转平移后得到此扫描点在第t帧的局部车体坐标系 ot-x′y′z 下的坐标(),然后再将此扫描点旋转回第t帧的车体坐标系ot-xyz。通过式(4)得到第t-1帧的车体坐标系ot-1-xyz下的一个静态障碍物扫描点A点()在第t帧的车体坐标系ot-xyz下的坐标():
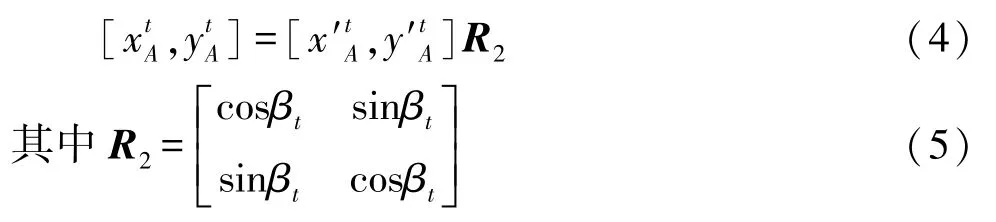
一帧点云包含13万个点,若对所有属于静态障碍物的点云都进行旋转平移变换,则计算量庞大,部分静态障碍物栅格里的点云在旋转平移变换后仍会落到同一个栅格里,所以随机选取每个静态障碍物栅格里的3个扫描点(不足3个的取所有扫描点)作为变换点,不再对静态障碍物栅格里所有点云做处理,将原来属于静态障碍物的扫描点在旋转平移变换后所在的栅格标记为静态障碍物栅格。本文中在2帧融合的基础上,融合了连续6帧的数据。

图3 静态障碍物检测结果
城市场景环境下动态障碍物多,静态障碍物的遮挡情况较其他场景环境下更严重,图3为采用本文方法在城市场景环境下多帧融合的静态障碍物检测结果。对比图3中1号和2号椭圆形,可以明显看到多帧融合的静态障碍物检测方法可避免因车辆遮挡导致静态障碍物漏检情况地发生,同时有效地保留了历史帧的静态障碍物检测结果,这对短期内无人车路径规划和控制决策起到了积极的作用。
2.2 动态障碍物检测
基于单一几何特征的动态障碍物检测算法[12]可实现部分动态障碍物的检测,但这种检测方法在非封闭的场景环境下易出现误检的情况,本文中利用多帧融合的静态障碍物检测结果,确定了对无人车路径规划和决策控制(如超车、跟车、换道等)影响较大的本车道的可行驶区域,将所有位于本车道可行驶区域内已检测出来的动态障碍物视为需要被跟踪的动态障碍物,其它不在可行驶区域内的障碍物视为普通障碍物,仅将其位置信息传给无人车,不再进行跟踪,这样做可很大程度上地避免误检情况的出现,同时可很好地满足无人车进行路径规划和决策控制的感知需求。
根据特定的动态障碍物模板[6]进行匹配,可将动态障碍物模板分为4类:(1)“L”型动态障碍物,这类动态障碍物多为在城市道路上行驶的汽车,因激光雷达只扫描到汽车的两面,而呈现出类似“L”的形状;(2)“I”型动态障碍物,这类障碍物多为行驶的过程中位于无人车正前方或者正后方的车辆,因自遮挡而致使障碍物点云出现类似“I”的形状;(3)“口”型动态障碍物,这类模板能较好地反映障碍物的真实形状;(4)行人和骑车人员动态障碍物,这类障碍物点云形状接近“I”型。通过将聚类结果与特定的动态障碍物模板进行匹配,可以初步确定出绝大部分动态障碍物。
但这种检测方法并不能将所有类型的动态障碍物囊括进来,易出现误检的情况,如图4所示,1~4号椭圆形内黑色的障碍物聚类结果即为采用文献[6]中模板匹配算法误检为动态障碍物的障碍物,所以本文中利用多帧融合的静态障碍物检测结果,确定了无人车所在车道的可行驶区域并结合动态障碍物模板匹配算法确定了可行驶区域内的动态障碍物,避免了误检情况地发生。
在确定本车道可行驶区域时(见图5),由无人车所在栅格O的位置出发先沿正前方和正后方做纵向搜索,遇到静态障碍物栅格或末端栅格则终止搜索,确定出正前方终止栅格A和正后方终止栅格B。之后,按照从O到A和B的顺序依次向两侧做横向搜索,遇到静态障碍物栅格则终止本次搜索。由于4级及以上公路车道宽度应在3m以上,如果前一次横向搜索终止位置与本次横向搜索终止位置相差3m以上则认为未找到静态障碍物栅格,如栅格C,但如果此时遇到普通障碍物栅格则将普通障碍物栅格作为搜索终止栅格,如栅格D,否则将前一次终止栅格的位置作为本次搜索终止的位置,由此可以得到图5中多边形所包围的本车道的可行驶区域,受益于静态障碍物多帧融合的良好检测效果,可很好地确定出无人车所在车道的可行驶区域。

图4 模板匹配算法检测结果

图5 可行驶区域检测示意图
动态障碍物检测结果如图6所示。图中被小矩形包围的障碍物是在确定了本车道可行驶区域后再结合模板匹配算法确定的动态障碍物,可以看出这样做可很好地检测出动态障碍物,同时有效地避免了文献[6]中方法在复杂的城市道路环境下误检情况地发生,提高了算法的鲁棒性。

图6 动态障碍物检测结果
3 动态障碍物跟踪
3.1 数据关联
将上一帧的动态障碍物与当前帧的动态障碍物进行数据关联,在进行数据关联时,采用边界位置相似度关联方法,将在第t帧第i个动态障碍物的4条边界位置定义为:
可得到前后2帧之间各个动态障碍物之间的相似度矩阵 Sm×n:


式中:m为前一帧中动态障碍物的个数;n为当前帧中动态障碍物的个数。
在无人车所在车道的可行驶区域进行数据关联时,前后两帧间的任意2个动态障碍物之间的相似度sij为

在数据关联时,会有3种情况:(1)上一帧和当前帧中同一个动态障碍物确实仍然存在;(2)上一帧中的动态障碍物在当前帧中已经不存在;(3)在当前帧中新出现的动态障碍物,而上一帧没有此动态障碍物。因此即使是相似度最大,也不一定是同一个动态障碍物,所以可通过设置合适的阈值(本文中的合适阈值为0.005)来区别无人车所在车道可行驶区域的同一个动态障碍物是否同时存在于上一帧和当前帧中。
3.2 动态障碍物运动状态估计
跟踪点的选择对跟踪效果影响很大,在使用HDL-64E三维激光雷达进行跟踪时,利用障碍物点云形状结合车辆形状的先验知识可以反推车辆中心位置[6-7,9],但实际上,受动态障碍物遮挡或是自遮挡的影响,同时各种动态障碍物的形状尺寸并不严格满足特定的模型,这种推导出来的中心位置存在一定的偏差,本文中借鉴了文献[13]中跟踪点的选取思想,并结合RTK-GPS数据和INS航向角数据来计算动态障碍物的运动状态,而不通过点云分布特征来确定动态障碍物的航向角,可很好地避免文献[8]中在动态障碍物运动过程中因点云分布不均致使错误估计动态障碍物运动状态的情况出现,同时也使得跟踪结果更稳定。
将动态障碍物的运动状态表示为

动态障碍为跟踪示意图如图7所示,图中障碍物为第i个动态障碍物。式(9)中的(是第 t帧时第i个动态障碍物跟踪点在大地平面直角坐标系XOY下的横坐标和纵坐标,由式(10)求出;和是动态障碍物分别在正东方向上和正北方向上的速度;是动态障碍物的合速度,由式(11)求出;是动态障碍物的航向角,定义为动态障碍物运动方向与正北方向的顺时针夹角,由式(12)和式(13)求出。

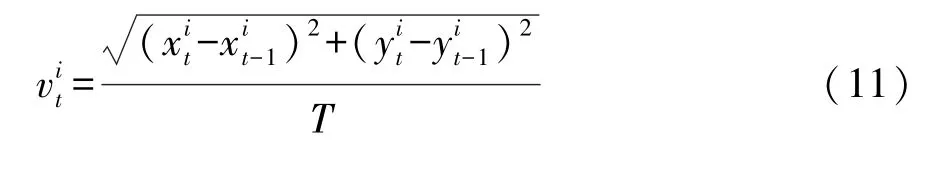

图7 动态障碍物跟踪示意图
式中T为连续2帧的时间间隔,T=0.1s。

将式(9)所述状态量代入标准卡尔曼滤波器[14],并将标准卡尔曼滤波器中状态转移矩阵A定义为式(14)中的4阶方阵,将观测矩阵H定义为4阶单位矩阵,这样可确保在状态转移时是从t-1时刻的位置转移到t时刻的位置,其中σ为高斯白噪声。同时优化了噪声矩阵参数,最终将状态转移噪声矩阵Q定义为均值为0、标准差为0.37m的高斯白噪声协方差4阶对角阵,观测噪声矩阵R定义为均值为0、标准差为0.75m的高斯白噪声协方差4阶对角阵,利用上述标准卡尔曼滤波器可以稳定地跟踪动态障碍物。

4 实验结果与分析
实验平台是课题组自主研发的“JJUV-5”智能车(见图8),主要传感器包括有1台Velodyne HDL-64E激光雷达、1套RTK-GPS系统和1台Inertial+惯导,计算机CPU是主频为3.1GHz的Intel i5-3350p处理器,内存为4G。

图8 实验平台
为了检验所提障碍物检测与跟踪方法的有效性,利用“JJUV-5”无人车在真实城市环境中进行了大量的测试,本节选择其中一段动态障碍物较多的具有代表性的路段进行介绍和分析,并与文献[8]中采用的方法进行了比较。
图9为动态障碍物连续跟踪的结果。由图可见,本文方法可以一直对同一个动态障碍物的颜色和编号保持不变,如程序中标为“1号”的障碍物(本文中的1号障碍物)和“0号”的障碍物(本文中的2号障碍物)在整个跟踪过程中都始终保持各自的颜色,且始终是同一个编号,这表明本文方法可以很稳定地跟踪同一个障碍物。同时,在动态障碍物较多的时候,如图9(e)~图9(h),本文方法仍能准确地跟踪各个动态障碍物,如1号障碍物和2号障碍物。图9的8幅图所展现的8帧障碍物的检测与跟踪结果中,几乎所有的静态障碍物和不在可行驶区域的动态障碍物都为黑色,这表明了本文方法可有效地区分静态障碍物、非可行驶区域动态障碍物和需跟踪的动态障碍物。选取1号障碍物为代表来说明本文方法对动态障碍物的跟踪能力。
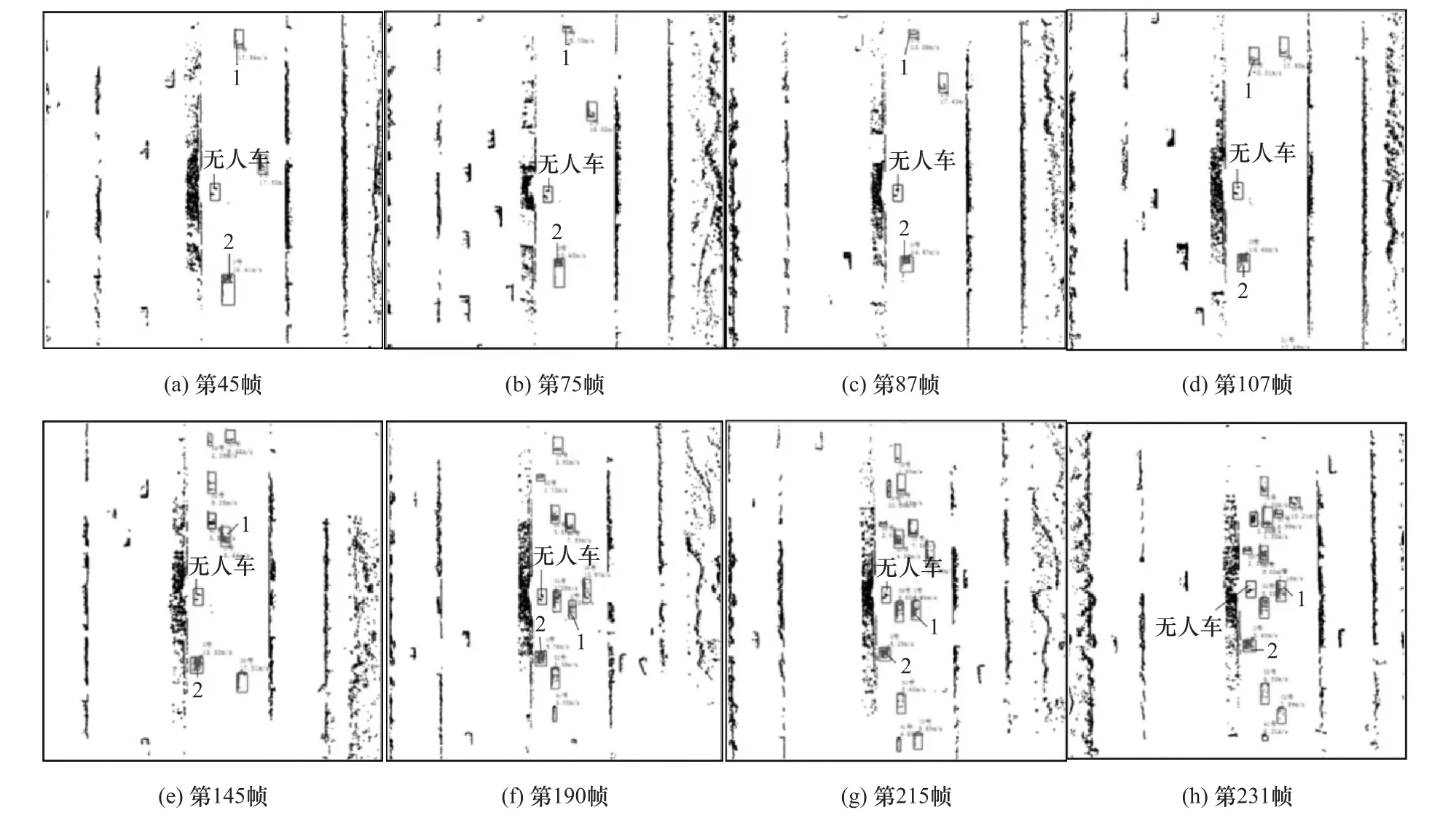
图9 动态障碍物连续跟踪结果
图10分别为采用本文中方法和采用文献[8]中方法对1号动态障碍物的进行跟踪的速度结果。1号动态障碍开始时速度高于无人车速度,离无人车越来越远,但随着1号障碍物速度越来越低,其距离无人车也越来越近,从图10的障碍物速度估计过程可看出本文中方法和文献[8]中方法都可有效地反映动态障碍物的实时速度。

图10 1号动态障碍物速度跟踪结果
图11为1号动态障碍物航向角跟踪结果。根据图9,1号动态障碍物与无人车的运动方向基本上一致,反映在图11上,可以看到1号动态障碍物的航向角与无人车航向角几近相同,在第125帧至第160帧左右,1号动态障碍物向无人车右侧行驶,此时图11上1号动态障碍物的航向角明显高于无人车的航向角。本文方法和文献[8]的方法都可有效地反映动态障碍物的航向变化情况。根据图10的1号框和2号框,以及图11的3号框和4号框,可以看到本文方法相比于文献[8]的方法能更为平稳地估计动态障碍物的速度和航向角,在障碍物出现遮挡或是自遮挡时能在一定程度上避免因点云分布不均而致使错误估计的情况,使得跟踪结果更为稳定。在240帧中,平均每帧的检测和跟踪耗时为104.165ms,满足无人车对算法的实时性要求。

图11 1号动态障碍物航向角跟踪结果
5 结论
本文中主要研究了基于三维激光雷达的障碍物检测和跟踪问题。在静态障碍物检测上,结合无人车RTK-GPS数据和INS航向角数据实现了多帧融合的静态障碍物检测,即使是在静态障碍物遮挡较严重的城市环境下,也能有效地检测出静态障碍物。在动态障碍物检测上,利用静态障碍物检测结果形成的可行驶区域与模板匹配算法实现了对动态障碍物的检测,有效降低了动态障碍物的误检率。最后,结合RTK-GPS数据和INS航向角数据来估计动态障碍物运动状态的方法和标准卡尔曼滤波器的有效运用提高了对动态障碍物的跟踪能力并获得了稳定可靠的跟踪结果,可靠的实验结果表明本文中基于三维激光雷达的无人车障碍物检测和跟踪方法的可行性和有效性。
本研究尚未考虑动态障碍物在完全遮挡后再次重现时的情况,同时栅格化尺度过大,当不同障碍物靠得较近时,会将两个不同的障碍物聚类成一个障碍物,下一步将着重解决这些细节问题。
