基于堆栈稀疏自编码融合核极限学习机的近红外光谱药品鉴别
2018-09-11张卫东李灵巧胡锦泉冯艳春尹利辉胡昌勤杨辉华
张卫东 李灵巧, 胡锦泉 冯艳春 尹利辉 胡昌勤 杨辉华*,
1(桂林电子科技大学计算机与信息安全学院,桂林 541004)2(北京邮电大学自动化学院,北京 100876) 3(中国食品药品检定研究院,北京 100050)
1 引 言
由于生产工艺、包装、原材料等形式的差异,不同厂商生产的同一种药品的质量,也有一定差异。对这些差异性的鉴别,在药品的监督中具有重要意义。近红外光谱分析技术以其快速、无损、无污染、高效等优势,已广泛应用于疾病诊断、制药等领域[1~4]。
近红外光谱分析技术结合化学计量方法已经广泛应用于药品的快速、无损、无污染类别分析。Mbinze等[5]将近红外光谱与拉曼光谱用于抗疟药品的质量检测对比,结果表明两种光谱具有同样好的效果。Storme-Paris等[6]结合主成分分析法和软独立建模分类法,在Fluoxetine和Ciprofloxacin两种数据集上取得了良好效果。Deconinck等[7]利用决策树构建分类器,分别对Viagra和Cialis药品光谱进行鉴别,分类准确率83.3%和100.0%,但是该方法没有对多分类问题进行研究。Anzanello等[8]使用主成分分析(Principal components analysis, PCA)结合K邻近算法(K-nearest-neighbour, KNN)和支持向量机(Supporting vector machine, SVM)对Viagra和Cialis进行真假药品鉴别,结果表明,SVM优于KNN。刘振丙等[9]采用波形叠加的极限学习机(Summation wavelet extreme learning machine,SWELM)构建分类器模型,以琥乙红霉素药品为研究对象,提出一种新的拟合核函数,该方法针对小样本,而且多分类准确率不高。Yang等[10]提出引入随机隐退机制的深度信念网络(Dropout-DBN)构建分类器,针对琥乙红霉素药品及其它药品的近红外漫反射光谱进行鉴别,取得了较好的分类效果,但是训练时间太长。由于多分类问题较二分类问题更复杂,光谱的多类别分类方面的研究目前还较少。
深度学习是一种基于无监督特征学习和提供更高抽象层次的学习方法,并成功应用在自然语言处理、语音识别和计算机视觉等领域[11~13]。同时,由于其深层的网络结构和非线性激活能力,各类深度学习模型特别适合高维、非线性的大数据建模。深度学习已经应用到近红外光谱的建模分析[10,14,15]。
堆栈稀疏自编码(Stacked sparse auto-encoders,SSAE)[16]由多层稀疏自编码器堆叠组成,采用逐层贪婪训练的方法进行训练,如此重复,以提取更高层次的抽象特征。核极限学习机(Kernel extreme learning machine, KELM)[18]引入了核函数的思想,相对于极限学习机 (ELM)[17]算法,具有更强的分类和回归预测能力, 并且SSAE和KELM已经广泛应用在多个领域[19,20],但在药品鉴别领域应用较少[9,14]。
针对近红外光谱数量较小、提取特征有限而且多分类准确率不高的特点,本研究提出了一种基于SSAE-KELM的近红外光谱药品鉴别方法。通过对不同厂商生产的同一包装形式(铝塑或非铝塑)药品的近红外光谱数据集进行二分类和多分类实验,验证SSAE-KELM在准确率、稳定性和训练时间方面的性能,并与ELM、SSAE、BP、SVM及Dropout-DBN方法进行了详细比较,结果表明,本方法简便、有效。
2 SSAE-KELM模型
SSAE-KELM的网络结构如图1所示,其中前三层是SAE、后三层是KELM,SSAE的输出作为KELM的输入,并且在KELM的隐含层中引入了核函数,作为SSAE-KELM模型的输出。SSAE-KELM是由栈式自编码与KELM组成的具有深层网络结构的算法模型。通过引入核极限学习机代替BP神经网络微调SSAE,减少了模型的训练步骤、训练参数以及训练时间,提高了深度学习网络的实际应用能力。其中,SSAE由多个稀疏自编码叠加组成,用于初始化整个网络模型并且从输入数据中学习到有用的特征;KELM用于实现分类任务。对于传统的栈式自编码,前一层编码器的输出作为下一层编码器的输入进行逐层贪婪训练,在预训练之后,在SSAE的最顶层,加上一个Logistic或者Softmax进行数据的二分类或多分类,然后利用传统的反向传播算法对整个网络进行微调。而SSAE-KELM中的SSAE舍去了最顶层的分类和微调过程,采用KELM代替SSAE的顶层结构。由于KELM解决了ELM算法随机初始化的问题,并且引入了核函数,使得模型具有较好的稳健性和快速的学习能力。因此,SSAE-KELM相对于传统的SSAE不仅减少了模型的训练步骤、训练参数和训练时间,同时提高了模型的分类性能。
特征学习阶段:
(1)
其中l=1,2,…,L, 每一层参数初始化的自编码网络模型如下:
(2)
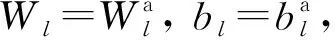
核极限学习的分类阶段:
(3)
在KELM中,无需给出隐含层节点的特征映射函数,只需确定核函数k(x,xi)的具体形式,即可求出f(x)的值。对应KELM中的核函数,可以选择径向基、线性、多项式和感知机核函数。本研究选择线性核函数。在f(x)中的xl-N为SSAE第l层自编码输出的Xl,C是正则化参数,K(x,xi)=xTxi是线性核函数。
本研究的药品预测模型SSAE-KELM如图1所示,其中SSAE用于光谱药品数据的降维和特征提取,KELM用于光谱药品的鉴别,其中核函数的引入提高了模型的分类能力。算法的流程如下:(1)将完整的光谱药品数据(2074维)通过归一化处理,消除光谱数据间数量级的差别,作为SSAE-KELM网络的输入层。(2)将多个SAE网络堆叠成SSAE,前一层SAE的输出作为其后一层SAE的输入,采用逐层贪婪的方式进行训练,最终将归一化之后的光谱数据通过SSAE进行两级降维得到200维的光谱特征,作为KELM的输入。(3)通过KELM对降维后的光谱药品进行鉴别,其中最优的核函数通过对比试验选择,超参数C和γ通过网格寻优的方式获取。(4)重复10次实验,获取10次实验的平均结果,并与其它鉴别方法的实验结果进行对比。
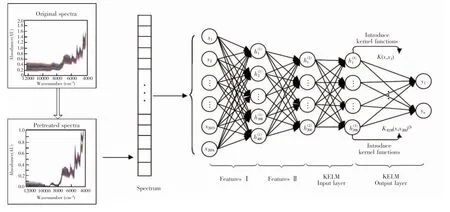
图1 SSAE-KELM神经网络模型Fig.1 Stacked sparse auto-encoders combine kernel extreme learning machine (SSAE-KELM) neural network model
3 实验部分
3.1 实验数据采集
实验数据由中国食品药品检定研究院收集,包括湖南方盛制药和其它药厂生产的铝塑和非铝塑包装形式的头孢克肟片。通过Bruker Matrix光谱仪测定每个样本在不同波长下的吸光度值得到其光谱曲线,每个光谱数据的波长范围是4000~11995 cm——1,间隔4 cm——1,一条完整的光谱有2074个吸光点。
表1 药品样本的详情
Table 1 Details of the pharmaceutical samples
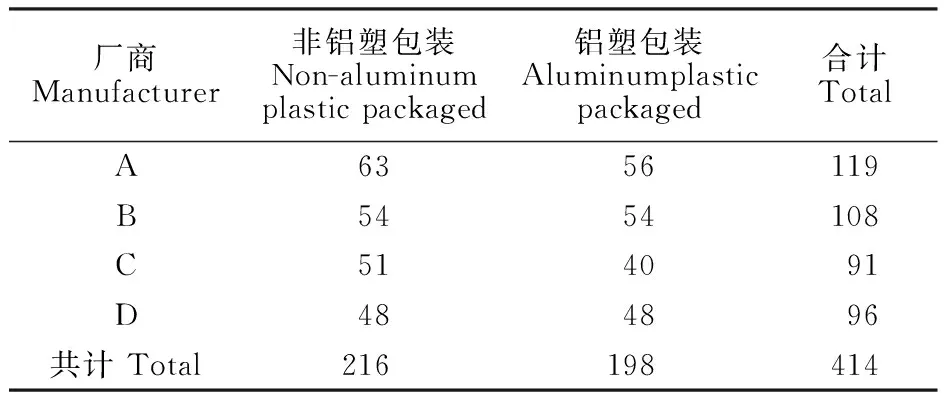
厂商Manufacturer非铝塑包装Non-aluminumplastic packaged铝塑包装Aluminumplasticpackaged合计TotalA6356119B5454108C514091D484896共计 Total216198414
NIRs样品的详细信息如表1所示。
3.2 光谱数据预处理
首先,通过OPUS软件消除偏移和漂移引起的光谱偏差,获得414条一致性药品光谱。如图2所示,光谱之间相似度较高,重叠严重,信息解析困难。通过对药品光谱归一化处理,消除光谱数据间数量级的差别,避免输入输出数据间数量级差别较大而影响模型的预测性能。
3.3 确定KELM层的最佳核函数
在微调SSAE-KELM的过程中,需要为KELM选择最佳的核函数。实验数据来源如表2中的A组数据集。在不同规模的训练集下,不同的核函数对应的二分类准确率如图3所示。实验结果表明,线性核函数具有最优的分类准确率。因此在SSAE-KELM中的KELM层选择线性核函数。
3.4 建立分类模型
实验选择Deep Learn Toolbox工具箱,软件开发平台MATLABL R2014a。SSAE-KELM的网络结构设置为2074-400-200-200-2/4,其中第二、三层的网络节点确定,通过调整隐含层的节点数实现网络结构的优化。二分类和多分类有相同的预测过程和预训练过程。具体过程如下:(1)预处理:对头孢克肟片近红外光谱进行预处理和归一化处理。(2)预训练阶段:SSAE-KELM的前三层采用SSAE,其中,SSAE的结构为2074-400-200。在SSAE的训练过程中,迭代次数是5,两层的学习率为0.05,稀疏参数0.1,激活函数为Sigmoid。(3)KELM微调阶段:SSAE-KELM的后三层采用KELM。其中,KELM的结构为200-200-2/4。 在KELM的训练过程中,迭代次数1,核函数为线性核,通过网格寻优获取最优的C=1,γ=1。 SSAE的输出作为KELM的输入,结合训练样本对应的真实标签微调SSAE-KELM模型。(4)对比实验:选择ELM、SVM、BP、Dropout-DBN和SSAE算法作为对比实验。其中ELM的结构设置为2074-train×0.4-2/4(train代表训练样本个数),激活函数为Sigmoid;SVM选择线性核函数,通过网格寻优SVM的核参数c=1,Gamma=0.3;两层BP的结构设置为2074-400-200-2/4,激活函数为Sigmoid,学习率为0.01,迭代次数为50;Dropout-DBN的结构设置为2074-400-200-2/4,激活函数为Sigmoid,两层的学习率均为0.05, Dropout参数为0.4,迭代次数为50;SSAE的结构设置为2074-400-200-2/4,激活函数为Sigmoid,两层的学习率均为0.01,稀疏参数0.1,迭代次数为50。
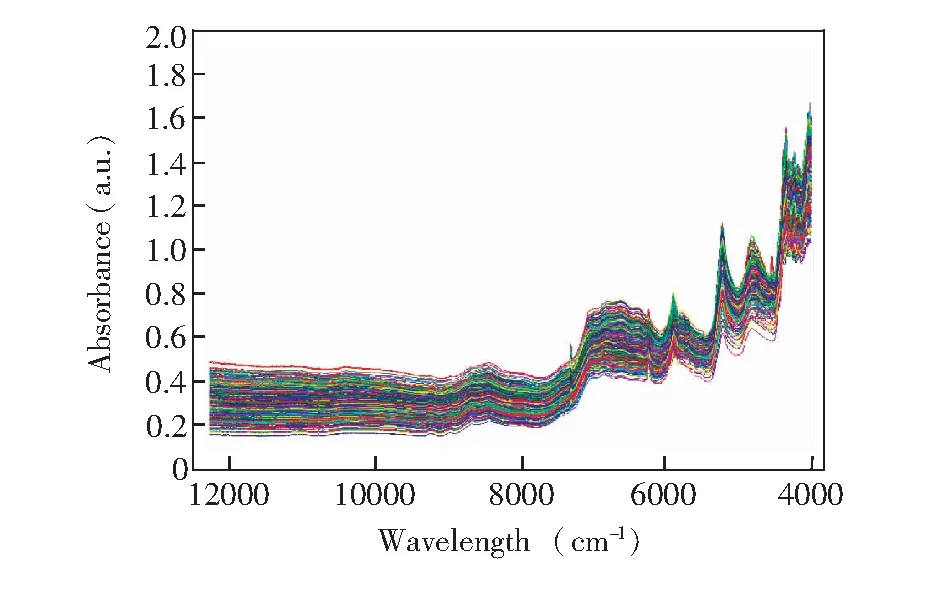
图2 药品样本的近红外光谱Fig.2 Near infrared (NIR) spectra of pharmaceutical samples
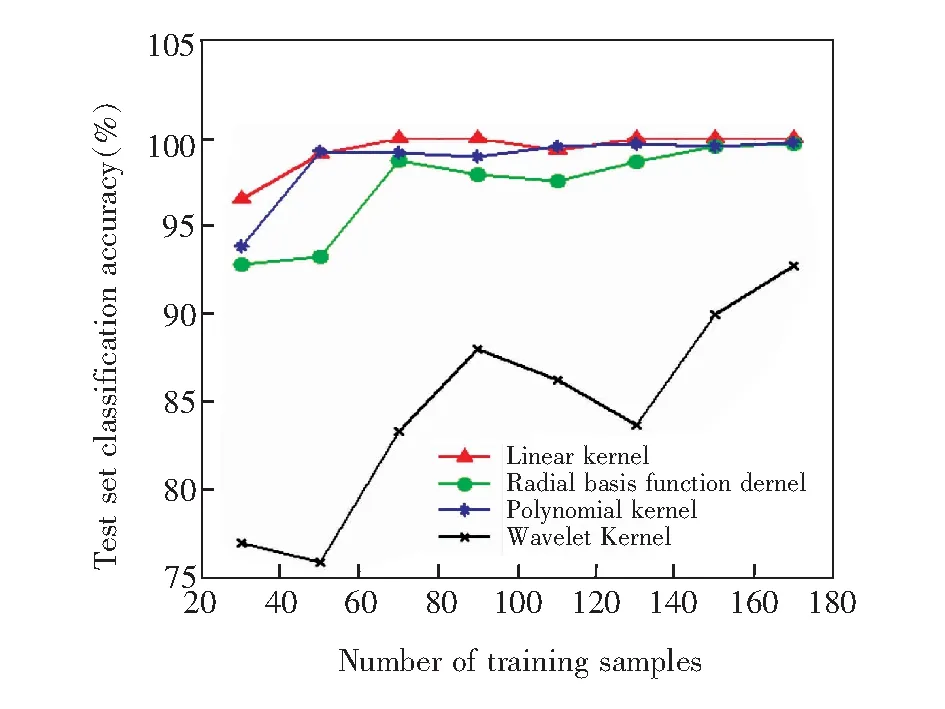
图3 不同的核函数对应的分类准确率Fig.3 Accuracies of classification of different kernel function
4 结果与讨论
为了验证SSAE-KELM模型对近红外光谱药品的鉴别能力,利用此模型分别对不同厂商生产的不同包装形式的同一种药品进行二分类和多分类实验,并与其它方法进行对比评价。
4.1 二分类对比实验
首先,利用指定厂商和其它3个厂商生产的相同包装形式的同一种药进行粗糙分类(二类药品鉴别),验证SSAE-KELM模型的预测能力。如表1所示,共收集414个药品的光谱样本,本实验将数据集分为二组,A组:取A厂生产的非铝塑包装形式的光谱样本63个,作为负类样本集; 取其它3个厂商生产的非铝塑包装形式的光谱样本共153个,作为正类样本集。B组:取A厂生产的铝塑包装形式的光谱样本56个,作为负类样本集;取其它3个厂商生产的铝塑包装形式的光谱样本共132个,作为正类样本集。
为了验证各算法在不同大小数据集下的预测性能,进一步按表2中A、B两组数据集的大小以及正负样本的比例随机抽取正负样本,并独立构造10次训练集和测试集,同时分别对其进行配置。并在此基础上评测各算法10次运行的平均性能。
同时,采用ELM、BP、Dropout-DBN和SSAE算法作对比实验。从分类准确率、算法稳定性和训练时间方面评价SSAE-KELM模型在药品鉴别应用中的性能。
如表3所示,针对A、B两组数据集,SSAE-KELM的分类准确率均高于ELM和SSAE,特别在训练样本较小的情况下,SSAE-KELM仍然表现出较高的分类准确率;随着训练样本的增加,SSAE-KELM的分类精度能达到100%的稳定值,由于核函数的引入提高了数据的线性可分程度,提高了深度学习网络的实际应用能力, SSAE-KELM能够有效提升模型的分类准确率。SVM、BP和Dropout-DBN具有较高且相近的准确率,说明它们复杂的非线性建模能力较好地适用于二分类问题,但在训练样本较小的情况下分类能力较弱于SSAE-KELM。而ELM和SSAE不具备非线性建模能力,其预测能力较差。
表2 针对二分类鉴别训练样本集的大小配置
Table 2 Size configuration of training sample set for binary-class discrimination
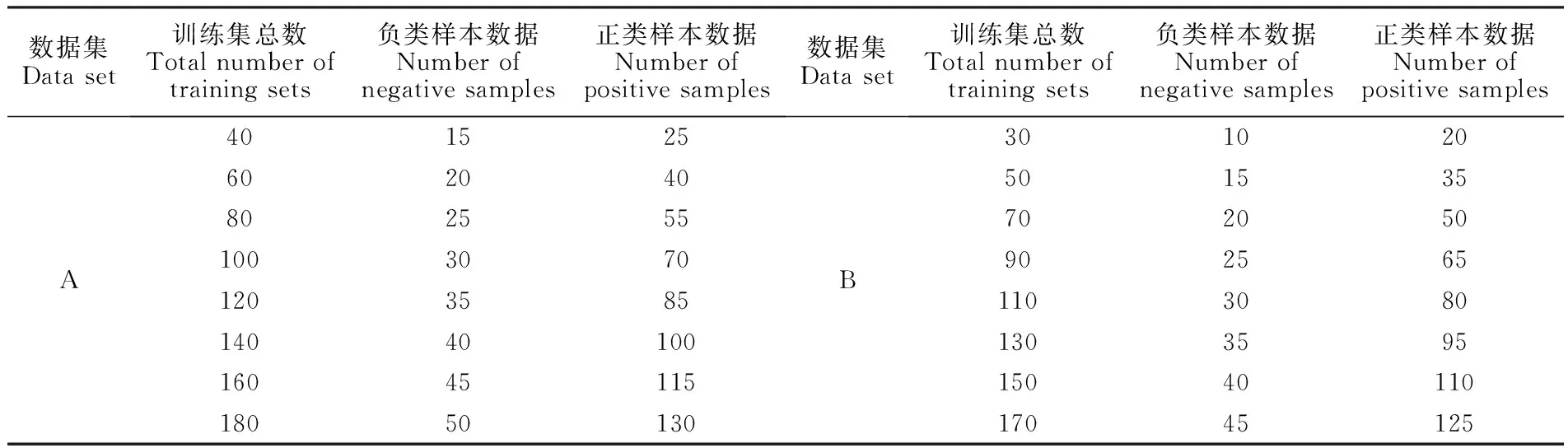
数据集Data set训练集总数Total number oftraining sets负类样本数据Number ofnegative samples正类样本数据Number ofpositive samples数据集Data set训练集总数Total number oftraining sets负类样本数据Number ofnegative samples正类样本数据Number ofpositive samplesA40152560204080255510030701203585140401001604511518050130B301020501535702050902565110308013035951504011017045125
表3 不同比例的训练样本对应的二分类准确率和训练时间
Table 3 Binary-classification accuracy and training time of different ratios of training samples
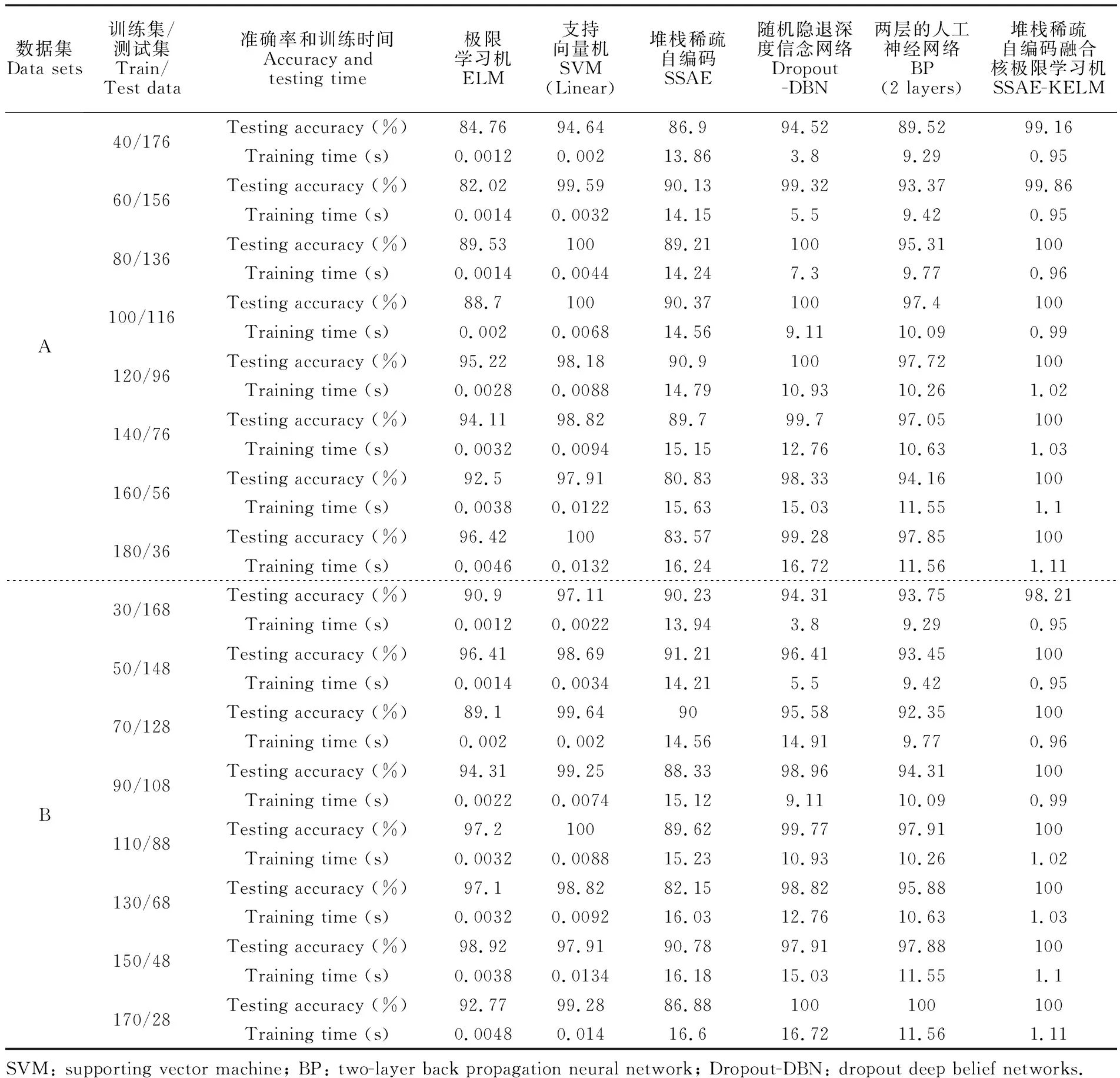
数据集Data sets训练集/测试集Train/Test data准确率和训练时间Accuracy andtesting time极限学习机ELM支持向量机SVM(Linear)堆栈稀疏自编码SSAE随机隐退深度信念网络Dropout-DBN两层的人工神经网络BP(2 layers)堆栈稀疏自编码融合核极限学习机SSAE-KELMA40/17660/15680/136100/116120/96140/76160/56180/36Testing accuracy (%)84.7694.6486.994.5289.5299.16Training time (s)0.00120.00213.863.89.290.95Testing accuracy (%)82.0299.5990.1399.3293.3799.86Training time (s)0.00140.003214.155.59.420.95Testing accuracy (%)89.5310089.2110095.31100Training time (s)0.00140.004414.247.39.770.96Testing accuracy (%)88.710090.3710097.4100Training time (s)0.0020.006814.569.1110.090.99Testing accuracy (%)95.2298.1890.910097.72100Training time (s)0.00280.008814.7910.9310.261.02Testing accuracy (%)94.1198.8289.799.797.05100Training time (s)0.00320.009415.1512.7610.631.03Testing accuracy (%)92.597.9180.8398.3394.16100Training time (s)0.00380.012215.6315.0311.551.1Testing accuracy (%)96.4210083.5799.2897.85100Training time (s)0.00460.013216.2416.7211.561.11B30/16850/14870/12890/108110/88130/68150/48170/28Testing accuracy (%)90.997.1190.2394.3193.7598.21Training time (s)0.00120.002213.943.89.290.95Testing accuracy (%)96.4198.6991.2196.4193.45100Training time (s)0.00140.003414.215.59.420.95Testing accuracy (%)89.199.649095.5892.35100Training time (s)0.0020.00214.5614.919.770.96Testing accuracy (%)94.3199.2588.3398.9694.31100Training time (s)0.00220.007415.129.1110.090.99Testing accuracy (%)97.210089.6299.7797.91100Training time (s)0.00320.008815.2310.9310.261.02Testing accuracy (%)97.198.8282.1598.8295.88100Training time (s)0.00320.009216.0312.7610.631.03Testing accuracy (%)98.9297.9190.7897.9197.88100Training time (s)0.00380.013416.1815.0311.551.1Testing accuracy (%)92.7799.2886.88100100100Training time (s)0.00480.01416.616.7211.561.11SVM: supporting vector machine; BP: two-layer back propagation neural network; Dropout-DBN: dropout deep belief networks.
在训练时间方面,针对A、B两组数据集,由于SSAE-KELM的分类和微调阶段采用KELM,不需要过多的迭代和反向微调过程,而SSAE、BP和Dropout-DBN需要BP反向微调优化网络模型。因此,SSAE-KELM相对于SSAE、BP和Dropout-DBN具有较大优势。但是由于ELM和SVM不需要在预训练阶段提取光谱特征,所以ELM和SVM在训练时间上具有很大优势。
如图4所示,针对A、B两组数据集,SSAE-KELM的稳定性均优于ELM和SSAE,特别在训练样本较小的情况下SSAE-KELM仍然具有很好的稳定性;随着训练样本的增加,SSAE-KELM表现出最优的稳定性,尤其在B组数据上,SSAE-KELM具有最优的稳定性。SVM、BP和Dropout-DBN具有很好的稳定性,但弱于SSAE-KELM。
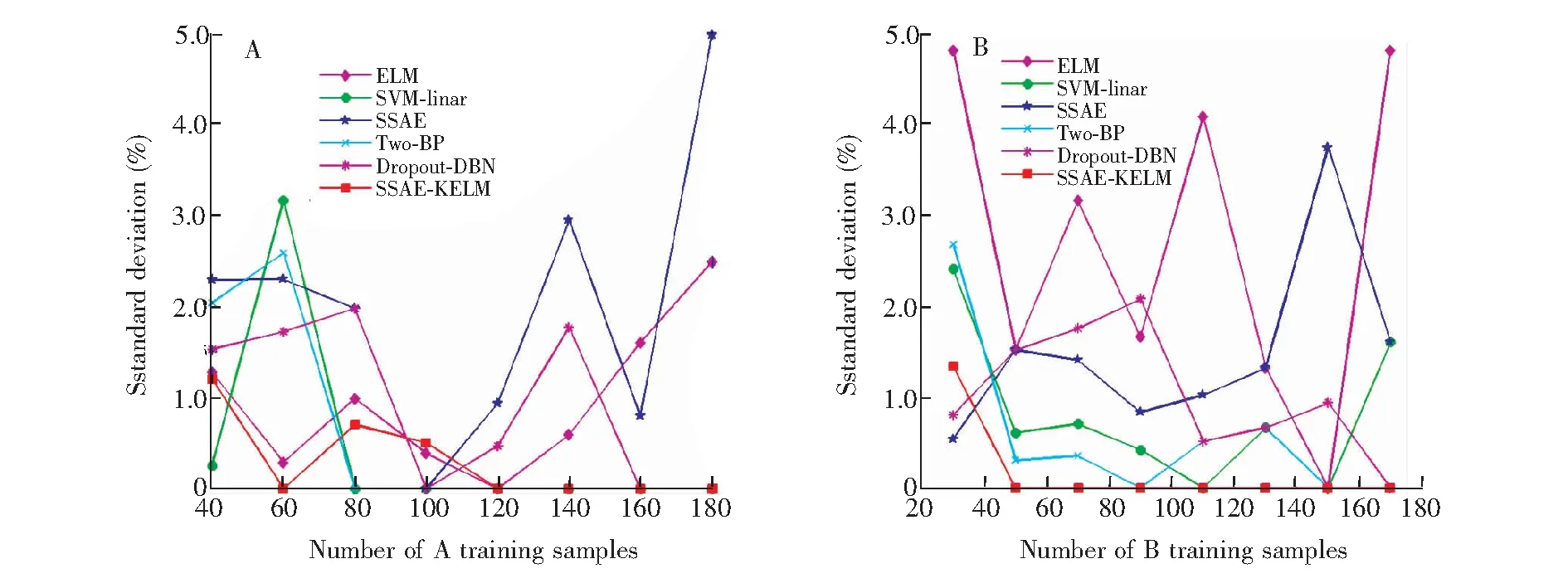
图4 不同的二分类模型准确率的标准偏差:(A)测试集A,(B)测试集B。Fig.4 Standard deviatios (STDs) of accuracy of different binary classification models:(A) Testing set A; (B) Testing set B
4.2 多分类对比实验
利用不同厂商生产的相同包装形式的同一种药进行精细分类(多类药品鉴别),验证SSAE-KELM模型的预测能力。由表4可见,样本光谱分为2组4类,取B厂生产的非铝塑和铝塑包装形式的光谱样本分别作为A组和B组第一类;取其它3个厂商生产的非铝塑和铝塑包装形式的光谱样本分别作为A组和B组的二、三、四类。
与二分类实验类似,为了验证各算法性能,按表5中A、B两组数据集的大小以及正负样本的比例,随机抽取正负样本,并独立构造10次训练集和测试集,同时对其分别进行配置。并在此基础上评测各算法10次运行的平均性能。
表4 针对多分类鉴别训练样本集的大小配置
Table 4 Size configuration of training samples for multi-class discrimination
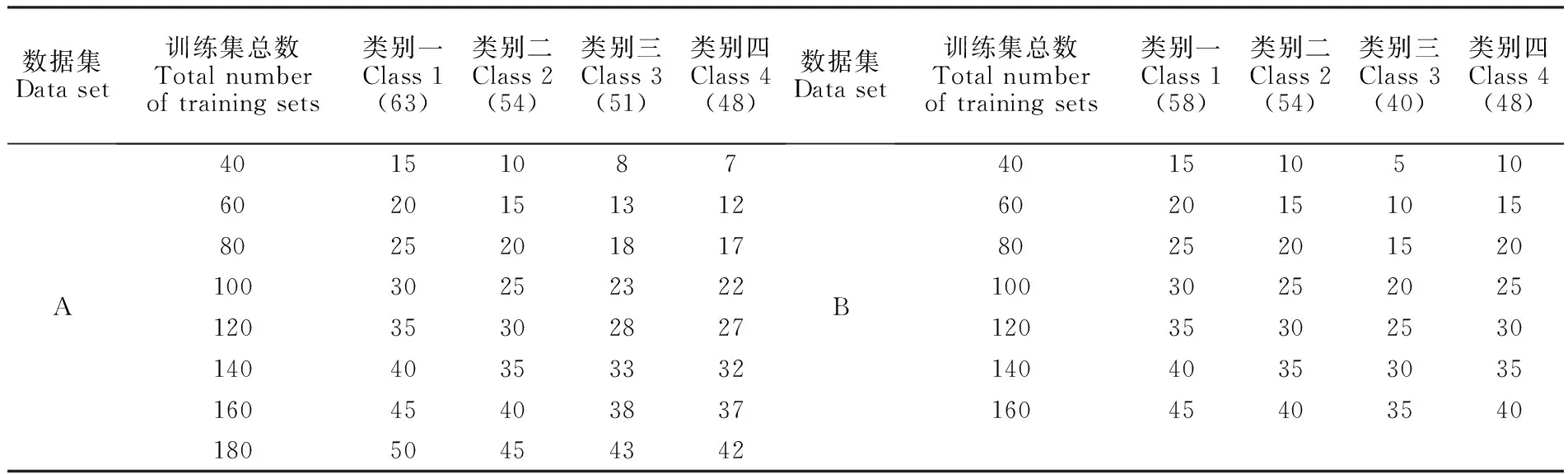
数据集Data set训练集总数Total numberof training sets类别一Class 1(63)类别二Class 2(54)类别三Class 3(51)类别四Class 4(48)数据集Data set训练集总数Total numberof training sets类别一Class 1(58)类别二Class 2(54)类别三Class 3(40)类别四Class 4(48)A40151087602015131280252018171003025232212035302827140403533321604540383718050454342B4015105106020151015802520152010030252025120353025301404035303516045403540
在分类准确率方面,针对A、B两组数据集,进一步比较各算法在多分类问题(表5)和二分类问题(表3)上的平均准确率,SSAE-KELM在多分类中优势较为明显。相对于二分类药品鉴别,在多分类药品鉴别中,由于ELM中引入核函数,提高了数据的线性可分程度,SSAE-KELM表现出更强的分类能力,而其它算法准确率有所下降。在训练样本较小的情况下SSAE-KELM表现出很高的分类准确率,随着训练样本的增加,SSAE-KELM的分类准确率稳定在100%。
表5 不同比例的训练样本对应的多分类准确率和训练时间
Table 5 Binary-classification accuracy and training time on different ratios of training samples
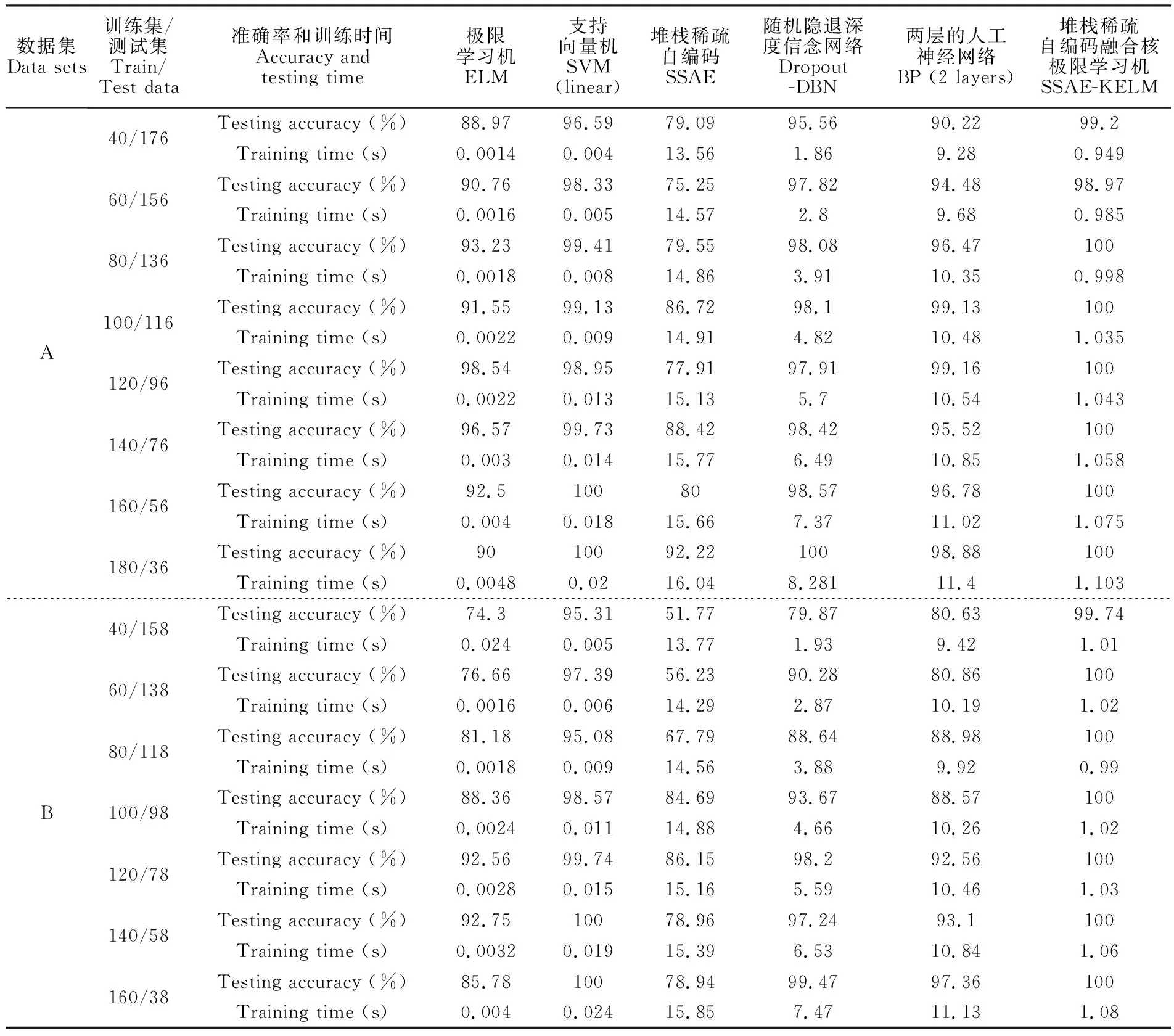
数据集Data sets训练集/测试集Train/Test data准确率和训练时间Accuracy andtesting time极限学习机ELM支持向量机SVM(linear)堆栈稀疏自编码SSAE随机隐退深度信念网络Dropout-DBN两层的人工神经网络BP (2 layers)堆栈稀疏自编码融合核极限学习机SSAE-KELMA40/17660/15680/136100/116120/96140/76160/56180/36Testing accuracy (%)88.9796.5979.0995.5690.2299.2Training time (s)0.00140.00413.561.869.280.949Testing accuracy (%)90.7698.3375.2597.8294.4898.97Training time (s)0.00160.00514.572.89.680.985Testing accuracy (%)93.2399.4179.5598.0896.47100Training time (s)0.00180.00814.863.9110.350.998Testing accuracy (%)91.5599.1386.7298.199.13100Training time (s)0.00220.00914.914.8210.481.035Testing accuracy (%)98.5498.9577.9197.9199.16100Training time (s)0.00220.01315.135.710.541.043Testing accuracy (%)96.5799.7388.4298.4295.52100Training time (s)0.0030.01415.776.4910.851.058Testing accuracy (%)92.51008098.5796.78100Training time (s)0.0040.01815.667.3711.021.075Testing accuracy (%)9010092.2210098.88100Training time (s)0.00480.0216.048.28111.41.103B40/15860/13880/118100/98120/78140/58160/38Testing accuracy (%)74.395.3151.7779.8780.6399.74Training time (s)0.0240.00513.771.939.421.01Testing accuracy (%)76.6697.3956.2390.2880.86100Training time (s)0.00160.00614.292.8710.191.02Testing accuracy (%)81.1895.0867.7988.6488.98100Training time (s)0.00180.00914.563.889.920.99Testing accuracy (%)88.3698.5784.6993.6788.57100Training time (s)0.00240.01114.884.6610.261.02Testing accuracy (%)92.5699.7486.1598.292.56100Training time (s)0.00280.01515.165.5910.461.03Testing accuracy (%)92.7510078.9697.2493.1100Training time (s)0.00320.01915.396.5310.841.06Testing accuracy (%)85.7810078.9499.4797.36100Training time (s)0.0040.02415.857.4711.131.08
在训练时间方面,由于A、B两组数据集较小,相对于二分类训练时间没有太大变化。SSAE-KELM相对于SSAE、BP和Dropout-DBN具有较大优势,同时,ELM和SVM在训练时间上仍然具有很大优势。
如图5所示,无论在训练样本较小还是在训练样本增加的情况下SSAE-KELM均表现出较好的稳定性,而且优于其它5种方法。随着训练样本的增加,SSAE-KELM表现出最优的稳定性。
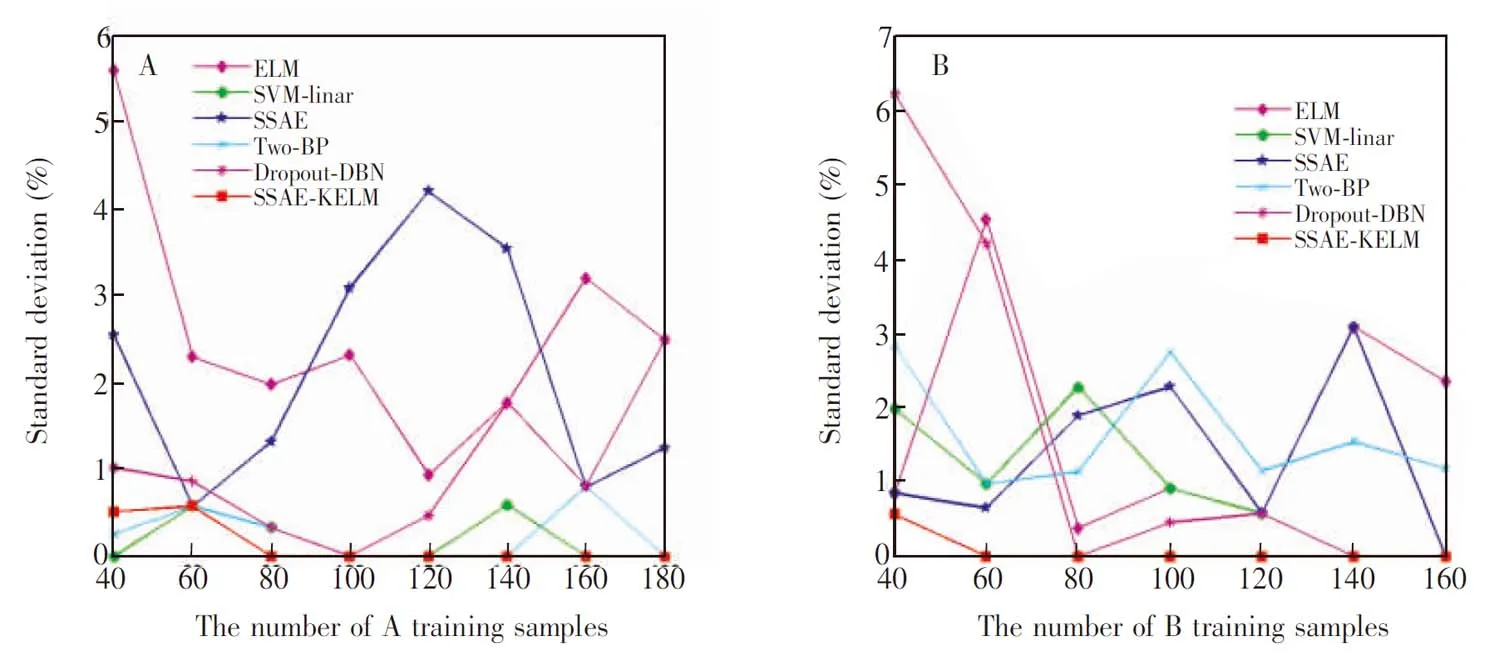
图5 不同的多分类模型准确率的标准偏差:(A)测试集A,(B)测试集BFig.5 STDs of accuracy of different multi-class classification:(A) Testing set A; (B) Testing set B
5 结 论
本研究提出了SSAE-KELM药品光谱鉴别方法,针对不同厂商生产的铝塑和非铝塑包装的头孢克肟片进行鉴别。通过KELM代替SSAE的Softmax分类和BP微调阶段,减少了模型的迭代次数、训练步骤、训练参数以及训练时间,提高了深度学习网络的实际应用能力,核函数的引入提高了模型的分类能力。针对药品的近红外漫反射光谱开展二分类、多分类应用研究。结果表明,SSAE-KELM不但减少了训练时间,而且具有更优的分类准确率和稳定性,样本的数量和类别越多,优势越明显。
