昆明市4个主要针叶树种林分断面积生长模型研究
2018-09-10朱丽艳罗春林吴雪琼
吴 恒 朱丽艳 李 华 罗春林 吴雪琼
(国家林业局昆明勘察设计院,云南 昆明 650216)
林分立地质量的准确评价是森林科学经营的前提,地位级法作为立地质量评价的可靠手段在林业生产实践中被广泛的运用[1-2]。林分断面积生长模型以林分总体特征为基础预估整个林分的生长和收获量。 Richards和Schumacher是可变密度生长模型的2种主要形式,Richards模型适应性强、拟合优度大[3],Schumacher模型形式简单、实用性强[4]。对不同生长模型的性能比较将有助于模型形式的不断改进。
基于生物学理论或假设而推导出来的理论生长模型,其参数有一定的生物学意义并且适用性较强[2-5],林分断面积生长模型参数求解常将非线性方程线性化,再利用最小二乘法或极大似然估计法等求解[6-7]。最小二乘法和极大似然估计法都是建立在具有连续可导的光滑搜索空间的假设基础上,且是在梯度方向上寻优的局部搜索技术[8],可能陷入局部最优解,参数求解时搜索速度随反演参数增多呈级数减慢,误差传递导致不收敛等缺点[9-12],参数求解误差影响着林分断面积生长模型的预测精度。昆明市地处云贵高原中部,分布有云贵高原典型森林植被类型,但长期以来缺少对林区主要针叶树种立地质量的准确评价和生长过程的模型研究。采用优化算法进行林分断面积生长模型参数估计,对提高模型预测精度和确保参数稳定性具有积极意义。本研究旨在建立昆明市4种主要针叶树种地位级表和林分断面积生长模型,基于不同优化算法建立针叶树种林分断面积生长模型,比较不同优化算法效率,分析模型形式和参数求解稳定性,为优化算法在生长模型参数估计中的运用提供参考。
1 材料与方法
1.1 数据来源与处理
基于昆明市森林资源二类调查数据(2015—2016),选取昆明市主要针叶树种华山松 (Pinusarmandii)、云南松 (Pinusyunnanensis)、油杉 (Keteleeriafortunei) 和柏木 (Cupressusfunebris) 林分为研究对象,筛选树种组成系数大于6成的林分作为 “相对纯林” 小班[13],计算林分平均年龄、平均树高、平均胸径、每公顷断面积平均值,以 ±3倍标准差为上下限剔除异常值[1],各树种满足建模要求的数据样本量分别为华山松19 275组、云南松35 821组、油杉2 847组、柏木3 799组,样本基本信息见表1。

表1 样本基本信息Table 1 Basic information of sample
1.2 立地质量评价方法
采用洪玲霞等[14]在建立蒙古栎 (Quercusmongolica) 林全林分生长模型时使用的地位级指数 (SCI) 作为立地质量评价指标,建立各针叶树种地位级模型;采用Richards、Schumacher和Compertz模型拟合林分平均年龄和平均树高间的关系,模型形式见公式 (1)~(3),参数a1表示林分平均树高生长的上限水平,参数a2与平均树高生长速率有关,参数a3决定了树高生长曲线形状。依据林分平均年龄与树高关系建立地位级曲线簇,编制各针叶树种地位级表,并进行落点检验,将检验样本作散点图,绘制到地位级曲线簇中,算出散点落在曲线簇内的概率,即为地位级表能够解释树高生长的概率值。
HT=a1(1-e-a2A)a3
(1)
HT=a1e-a2e-a3A
(3)
式中:HT为林分平均高;A为林分平均年龄;a1、a2和a3为参数。
1.3 建模方法
森林的生长和收获取决于年龄、立地、林分密度等3个主要因子,本研究结合数据特征利用林分密度指数 (SDI) 作为竞争指标[15],引入到生长模型中拟合不同立地条件下林分的生长过程,其计算方法见公式 (4)。

备选模型有Schumacher、Richards和Korf 3种,模型形式见公式 (5)~(7)。模型的参数估计为在最小二乘法意义下极小化离差平方和,采用麦夸特算法 (LM)[16]、差分进化算法 (DE)[12]、遗传算法 (GA)[17]、模拟退火算法 (SA)[11]和粒子群算法 (PSO)[8-10],运用MatlabR2014b编写各算法代码进行最优值求解,得到不同优化算法下林分断面积生长模型参数,根据拟合优度 (R2)、均方根误差 (RMSE) 综合考虑拟合参数稳定性,筛选一组最优参数估计值作为模型拟合结果。
式中:G为林分每公顷断面积;A为林分平均年龄;SCI为地位级指数;SDI为林分密度指数;a1、a2、a3、a4和a5为参数。
1.4 模型拟合结果评价方法
采用残差对模型拟合结果进行分析,比较模型形式对林分生长预测的偏差。采用不同算法求解参数迭代次数比较算法效能,并用各算法拟合不同生长模型参数间欧式距离分析求解参数稳定性。不同拟合参数间欧式距离的计算方法见公式 (8)。

(8)
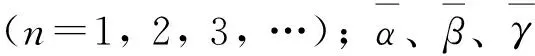
2 结果与分析
2.1 林分年龄与树高的模型拟合
立地质量的准确评价是林分断面积生长模型构建的基础,也是林分科学经营的前提。根据林分平均年龄和平均树高曲线拟合结果 (表2) 可知,Richards模型和Compertz模型拟合优度均高于Schumacher模型,Richards模型拟合华山松、云南松和柏木的生长上限水平、生长速率和曲线形状相近,符合树高生长的生物学规律,因此4个树种均采用Richards模型。
根据林分平均年龄和平均树高建立的地位级曲线簇,落点检验见图1。华山松落点检验值为97.9%、云南松为98.3%、油杉为98.1%、柏木为98.9%。建立的地位级曲线簇通过落点检验,精度满足立地质量评价适用性检验,可编制各树种地位级表,用于指导林业生产。
2.2 林分断面积生长模型参数拟合
采用不同优化算法拟合林分断面积生长模型参数,拟合结果见表3。各生长模型R2介于0.87~0.92、平均值为0.90,RMSE介于1.48~1.99、平均值为1.80,符合模型拟合精度要求。4个针叶树种模型形式均采用Richards模型,参数a1和a2与立地质量的生长上限有关,参数a4和a5与林分密度的控制的生长速率有关。本研究中华山松和云南松林分生长上限参数相似,且均高于油杉和柏木,云南松的生长速率参数与其他针叶树种存在差异。华山松、云南松、油杉和柏木模型预测值和观测值的相关系数分别为0.95、0.94、0.93和0.96。华山松、云南松、油杉和柏木模型的t检验显著性p值分别为0.93、0.88、0.97和0.58,表明4个针叶树种模型预测值和观测值间差异均不显著。

表2 林分年龄-树高曲线模型参数Table 2 Parameters of age and height growth model
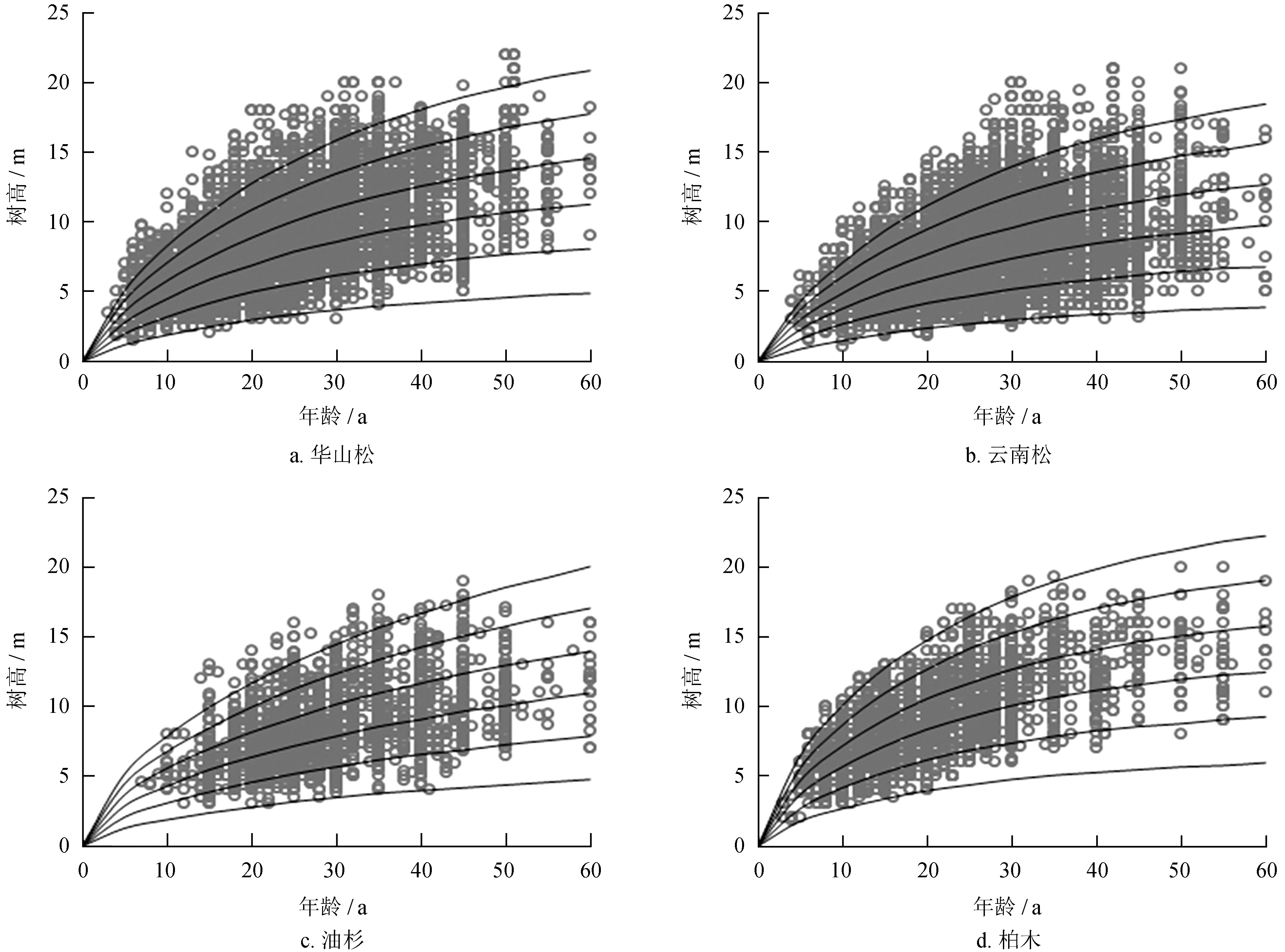
图1 各树种地位级曲线簇及落点检验Fig.1 Site class curves for different tree species and falling point test results

表3 各针叶树种林分断面积生长模型参数拟合结果Table 3 Fitting results of stand basal area growth models for different coniferous species
2.3 模型拟合结果评价
2.3.1参数稳定性分析
Richards模型拟合4个针叶树种R2平均值为0.90,Schumacher模型拟合4个针叶树种R2平均值为0.79,Korf模型拟合4个针叶树种拟合优度平均值为0.88。不同模型形式残差分布见图2。
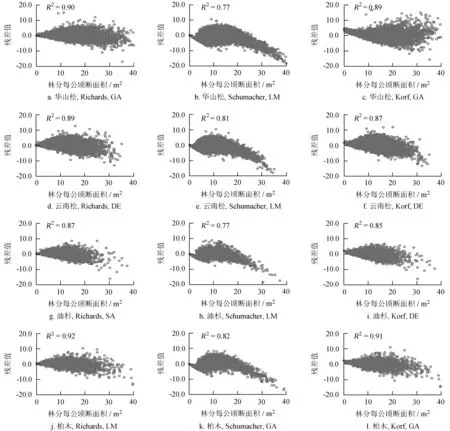
图2 不同模型形式残差分布Fig.2 Distribution of residuals of different models
根据不同模型形式的残差分布图 (图2) 可知,Richards模型拟合林分每公顷断面积生长预测值与观测值间残差分布合理,随林分每公顷断面积的增大,残差变动幅度逐渐扩大,未表现出系统性偏差;Schumacher模型拟合林分每公顷断面积生长预测值与观测值间残差分布不合理,林分每公顷断面积介于0~5 m2和20~40 m2时,预测值系统性低于观测值,林分每公顷断面积介于5~20 m2时,随林分每公顷断面积的增大,残差变动幅度逐渐减小;Korf模型拟合林分每公顷断面积生长预测值与观测值间残差分布较合理,残差变动幅度大于Richards模型,林分每公顷断面积介于0~5 m2时,预测值系统性高于观测值。因此,针叶树种更适宜采用Richards模型。
不同优化算法求解各针叶树种Richards模型各参数拟合结果间欧式距离为1 988.44,其中华山松断面积生长采用不同优化算法求解参数间欧式距离最大为7 912.49;Schumacher模型各参数拟合结果间欧式距离为4.08;Korf模型各参数拟合结果间欧式距离为8.44。采用Schumacher模型和Korf模型拟合参数稳定性优于Richards模型,但Richards模型的拟合优度大于Schumacher模型和Korf模型。
2.3.2算法效能分析
不同优化算法求解断面积生长模型参数迭代次数见表4。
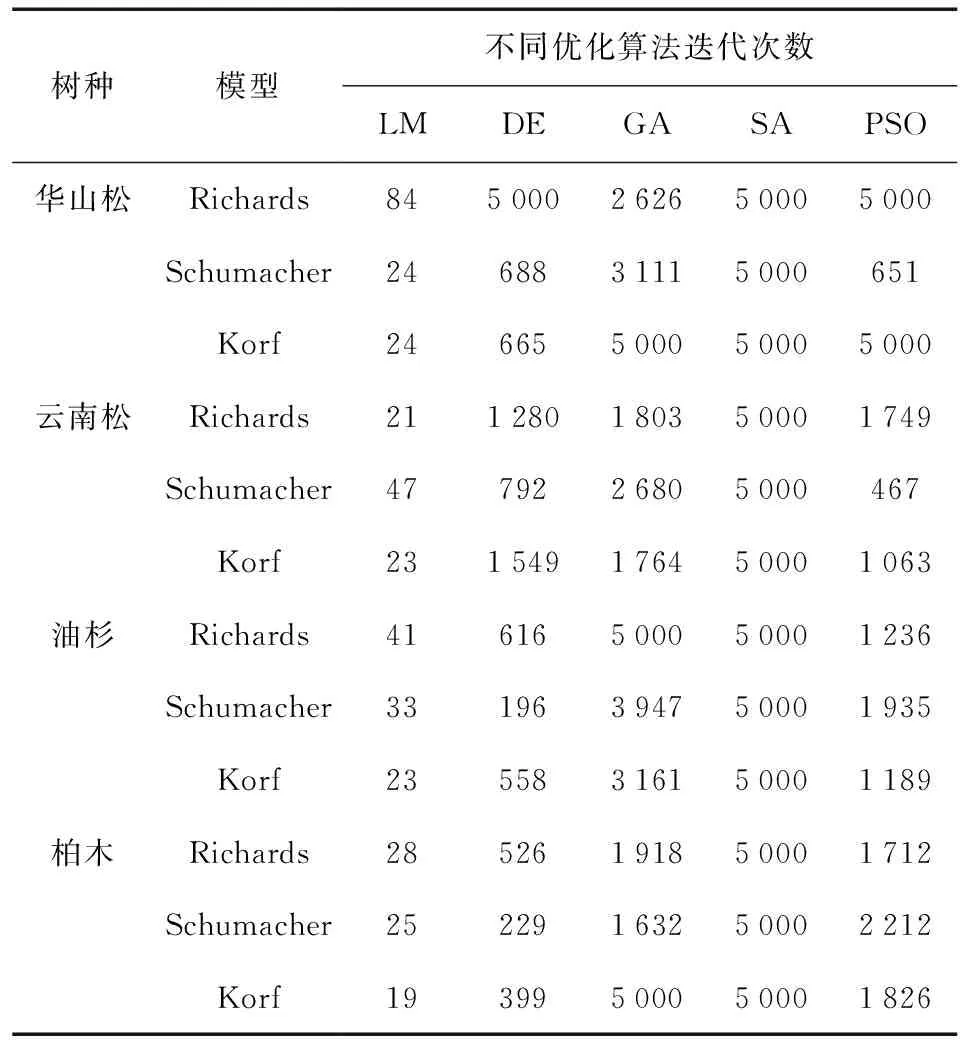
表4 不同优化算法求解断面积生长模型参数迭代次数Table 4 Iterations of parameter solving for basal area growth models by different algorithms
由表4可知,LM、DE、GA、SA和PSO迭代次数平均值分别为33、1 042、3 137、5 000和2 003。LM迭代次数平均迭代次数最小,SA迭代次数均达到了算法设置的最大迭代次数 (5 000次)。不同模型形式对优化算法求解参数效能也存在差异,Richards模型拟合迭代次数普遍高于Korf模型和Schumacher模型,Schumacher模型拟合迭代次数普遍最小。PSO迭代次数介于中间,但求解参数的拟合优度较差。SA、DE对不同模型的参数拟合优度较高。
3 结论与讨论
采用不同优化算法对昆明市4个主要针叶树种进行林分断面生长模型构建,比较不同优化算法求解参数效率和稳定性,得出以下结论:
1) Richards模型拟合华山松、云南松和柏木的生长上限水平、生长速率和曲线形状相近,符合树高生长的生物学规律;建立的地位级曲线簇通过落点检验,精度满足立地质量评价适用性检验。
2) 建立了华山松、云南松、油杉和柏木可变密度断面积生长模型,模型R2平均值为0.90,均方根误差平均值为1.80,模型精度符合要求。
3) Richards模型对针叶树种生长拟合优度大于Schumacher模型和Korf模型,Schumacher模型采用不同算法求解参数稳定性大于Richards模型和Korf模型。
4) 各优化算法求解生长模型参数效率由高到低顺序为LM、DE、PSO、GA、SA,但PSO求解参数的拟合优度较差。
林分断面积生长模型中,Richards模型[18]、Schumacher模型[19-20]和Korf模型[4]具有较好的数学和生物学意义,得到普遍认可,但本研究表明,Richards模型的拟合优度和解释性更好,但参数求解较困难且不稳定;Schumacher模型拟合参数更易求解且比较稳定,但存在系统性偏差,在实际运用中需要对模型形式进行修正;Korf模型作为Schumacher模型的广义形式R2和参数稳定性均介于中间水平,但仍然存在特定阶段的系统性偏差,相较于Schumacher模型有较好的改善。利用再参数化方法建立生长模型能够兼顾Richards模型和Schumacher模型各自的优点[4]。
林分断面积生长模型是复杂的非线性回归模型[4],常用的非线性模型参数估计方法是基于估计目标函数对优化变量梯度信息的优化,要求优化模型具有连续性和可导性[8],而生长模型的系统非线性特点增加了梯度信息局部搜索方法寻找全局最优解的难度和误差传递的不收敛,从而影响生长模型精度[9-12]。运用单一的优化算法对非线性模型参数进行估计限制了不同优化算法间效能比较和参数稳定性分析[21],降低了各优化算法在实际运用中的可选性。对比分析不同优化算法拟合林分断面积生长模型的性能,为林分断面积生长模型参数求解方法提供了依据。
林分立地质量评价和生长模型是森林经营的重要工具。全林分生长模型能较好的模拟人工纯林的生长[22],采用针叶树种组成系数大于等于6成的小班作为建模样本单元,符合 “相对纯林” 的概念[1,13],能够用于全林分生长模型的构建。建立的全林分生长模型拟合优度介于0.87~0.92,具有较好的预测效能[4]。采用建立的全林分生长模型提取林分小班因子中年龄、平均树高、公顷株数实现对小班树高、胸径、每公顷断面积、蓄积等因子的更新,与采用林分蓄积生长率预测林分蓄积相比,传统生长率更新林分因子的方法不能反映小班间生长差异性,不能实现树高、胸径和公顷株数等林分因子的更新变化。建立全林分生长模型,对探索无干扰林分动态监测和林地 “一张图” 蓄积量等因子更新具有重要作用。地位级指数作为林分立地质量评价的指标在缺乏优势树高数据的情况下用于林分立地质量的评价具有可行性,本研究建立的华山松、云南松、油杉和柏木的地位级指数模型落点检验值均高于97%,具有较好的普适性和外推效能[13],能够用于昆明市针叶树种造林立地质量评价与划分。
