嵌入式GPU存储管理单元的设计与实现
2018-09-10张丽果
张丽果, 刘 雄
(西安邮电大学 电子工程学院, 陕西 西安 710121)
图形处理器(graphics processing unit,GPU)以其强大的渲染能力被广泛应用于PC机、多媒体以及嵌入式设备中,已经成为图形处理技术的研究重点之一[1]。随着嵌入式设计复杂度不断提升,存储管理成为嵌入式GPU设计的关键部件。虚拟存储技术是一种基于操作系统的存储管理方法,为用户提供比实际物理存储器更大的存储空间。
存储管理单元(memory management unit,MMU)是虚拟存储技术的硬件基础,其中地址转换后援缓冲器(translation look-aside buffer, TLB)则是MMU的核心部件,用于完成虚拟地址到物理地址的映射,并提供访问权限检查。嵌入式GPU支持32位地址总线,因此,MMU最大可以管理4G(232)的虚拟内存空间。内存管理方式分为页式管理和段式管理。在嵌入式系统中,一般采用页式管理。对于连续的内存空间存放页表的问题,采用两级页表的TLB结构。在进行地址翻译时,传统的TLB结构[2]只能按级进行查找,一旦TLB失靶,就会导致页表切换,造成能量消耗和时钟延迟,从而导致处理器的性能降低[2-3]。
为了高效并灵活地管理内存空间,减少页切换[4],本文拟设计一种适用于嵌入式GPU存储管理单元的硬件结构。采用树状页表结构[5]进行地址翻译,将一级页表索引和两级页表索引同时与TLB比较,若两级页表命中,直接翻译出物理地址。最后采用DC工具进行综合,并在ZC706开发板上进行验证。
1 地址映射
MMU的主要功能是地址翻译和内存保护。嵌入式GPU中存储管理单元采用两级页表的管理方式进行地址翻译,两级页表的结构如图1所示,其中每页的大小为4 KB。第一级为页目录(page directory),共有1 024(210)个目录表项(directory table entries,DTEs);第二级为页表(page table),共有1 024(210)个页表项(page table entries,PTEs)。

图1两级页表结构
将虚拟地址的高10位(DTE索引)与TLB中的DTE_Tag、虚拟地址的高20位(DTE和PTE索引)与PTE_Tag同时比较,实现两级页表同时匹配,有效的减少了页切换。地址变换机构如图2所示,具体翻译过程如下。
(1) PTE_Tag命中时,直接读取PTE对应的物理页号与虚拟地址的页内偏移拼接为32位物理地址,完成地址翻译。
(2) DTE_Tag命中、PTE_Tag失靶,读取DTE对应的物理页号并与PTE索引位拼接后,组成寻找PTE的“虚拟地址”,访问L2cache或主存,读取PTE后,更新PTE_Tag和TLB,最后,读取PTE对应的物理页号与虚拟地址的页内偏移拼接组成32位物理地址。
(3) DTE_Tag和PTE_Tag失靶,硬件逻辑产生一个基址(DTE_ADDR),再拼接DTE索引,组成寻找DTE的“虚拟地址”,访问L2cache或主存,读取DTE后,更新DTE_Tag和TLB后,读取DTE对应的物理页号,接下来的操作和情况(2)相同。
PTE在TLB中以4字节(32 bits)存储,高20位存储物理页表;对主存和cache同时管理,PTE[11∶3]为cache控制位;低3位为存储保护位,提供访问权限检查。

图2 地址变换机构
2 TLB硬件设计与实现
TLB是MMU的核心部件,用于保存最近使用的页表项以及相应的访问权限控制信息,并利用程序访问的局部性原理,加速虚拟地址到物理地址的转换。TLB的结构如图3所示,主要由CAM和SRAM组成,CAM用来存储最近使用的4个页目录标签(DTE_Tag)和28个页表项标签(PTE_Tag),SRAM中主要存储16个DTE、112个PTE,其中PTE中包含物理页号、cache控制信息以及存储保护信息。
TLB的相联方式对时钟频率和功耗的影响较大[6]。对面积、功耗、速度的折中考虑,采用全相联的TLB结构。
MIPS是最早提供软件管理TLB的商用体系结构之一[7]。软件管理TLB失靶的方式就是,硬件向操作系统发送中断请求信号并转移到查表中断处理子程序处理中断,处理完中断后,本条指令重新访问TLB,继续执行后续指令[8]。
这种软件管理TLB失靶的机制具有非常高的灵活性,但却带来了大量时钟周期的开销。TLB失靶时,需要到cache或外部存储器中查找页表,用于查表的处理程序是一段10~100条指令组成的操作原语[9],如果处理程序的指令不在cache中,那么查找失靶的页表所需要的时钟周期将比传统硬件状态机遍历页表所需的时钟周期更长,并且在更新页表时,暂停和清除流水线又将浪费多个时钟周期,此外,还需清除缓存中的多条指令,这将为查表增加成百上千个时钟周期开销[10]。
为了减少软件在查表过程中造成的额外的开销,采用硬件管理TLB失靶,当DTE失靶时,硬件逻辑产生页表基地址,并写入寄存器DTE_ADDR[11],基址拼接DTE索引组成查找DTE的“虚拟地址”;PTE失靶,DTE和PTE索引组成查找PTE的“虚拟地址”,如图3所示。硬件管理TLB失靶的方式不用暂停或清除流水线,减少了时钟周期的开销。查表的整个过程由状态机控制。
3 存储保护与异常处理
3.1 存储保护
MMU另一个重要的功能就是存储保护,如果试图访问没有权限的存储空间就会产生错误。对于虚拟存储而言,多个进程可以共享数据,然而,非法的读写操作会产生“硬件陷阱”,因此,对不同的进程,应赋予不同的读写权限,这样既能保证信息安全,又能满足运行需要。

图3 TLB的结构
存储保护保证当前读写访问是合法的,当DTE_Tag命中,在SRAM中读取DTE时,应检查有效位(DTE[0])是否有效,若有效位为0,则该DTE不能指向下级页表;当PTE_Tag命中,在SRAM中读取PTE时,不仅需要检查有效位是否有效,还需检查读写访问权限,存储保护规则如表1所示。PTE[0]为PTE有效位,PTE[2∶0]为读写检查的标志位,若违反以下规则中任意一种情况,会导致异常,硬件向操作系统发送中断请求信号并转移到中断子程序处理中断。

表1 存储保护规则
3.2 异常处理
MMU的工作过程主要由状态机来完成,如图4 所示。页错误状态、停顿状态、总线错误状态为异常状态,状态机之间的跳转由控制信号(page_fault、read_error等)以及系统配置MMU命令寄存器来完成。
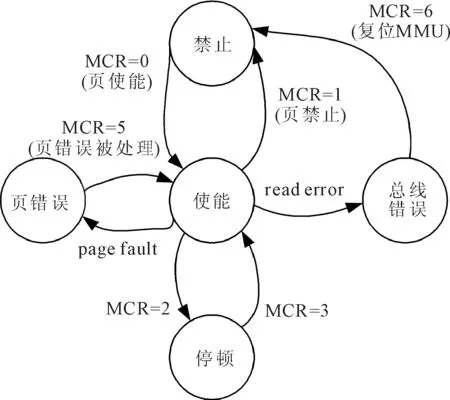
图4 MMU工作状态转移图
(1)禁止状态:系统复位之后,MMU是处于禁止访问状态,此时命令寄存器(MMU_CMD_register,MCR)的值为1。
(2)使能状态:当MMU发现GPU或cache发送访问存储器请求时,此时MCR的值是0,MMU进入使能状态,MMU开始进行地址翻译。
(3)页错误状态:当DTE或PTE失靶、有效位为0或没有读写访问权限时,会产生page fault信号,状态机会跳到页错误状态,硬件会产生页错误中断请求信号,同时虚拟地址将会被存储到Replay_buffer中,等待总线没有访问请求时,将失靶虚拟地址再次匹配;页错误处理完后,MCR的值为5,并跳出页错误状态。
(4)停顿状态:当总线空闲时,MCR中的值为2,MMU进入停顿状态,停止地址翻译;等待GPU或Cache发送请求时,MCR的值为3,状态机跳出停顿状态。
(5)总线错误状态:如果出现读请求失败,产生read error信号,MMU会进入总线错误状态,同时会产生总线错误中断请求信号,MCR中的值为6,此时复位MMU。
当TLB命中且没有违反存储保护规则时,直接完成地址翻译;若TLB未命中或违反存储保护规则,状态机跳到页错误状态;若出现总线读错误时,状态机跳转到总线错误状态;若总线空闲时,状态机跳转到停顿状态,状态机跳转到这三种状态下,则会导致异常。
硬件会修改中断状态寄存器(MMU_interrupt_status_register,MISR)和状态寄存器(MMU_status_register,MSR)的值,并跳转到中断子程序处理中断[9],处理完中断后重新访问TLB,继续后续地址翻译,MMU异常处理如表2所示。

表2 MMU异常处理
4 测试的结果与分析
为了验证嵌入式GPU的存储管理单元的硬件电路的正确性。利用DC工具进行仿真与综合,在SIMC 0.18 μm工艺库下,频率可达225 MHz,满足嵌入式GPU设计频率要求。将带有MMU的GPU封装为IP核下载至ZC706开发板中,并在开发板上移植Linux操作系统,采用OpenGL ES 2.0图形应用程序语言编写牛和兔子的测试场景,并在GPU下运行,如图5所示,牛和兔子的轮廓清晰,图形效果逼真。由此可知,MMU硬件电路设计可行,且满足嵌入式GPU存储管理的要求。
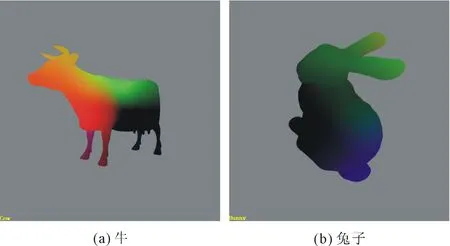
图5 OpenGL ES 2.0图形应用程序效果
5 结语
采用树状页表的TLB结构以及硬件处理TLB失靶的方式,设计并实现了一种嵌入式图形处理器的存储管理单元的硬件设计结构。在SIMC 0.18 μm工艺库下进行了综合,并在ZC706开发板进行系统级验证,结果表明,该设计频率可达225 MHz,能够实现嵌入式GPU存储管理的要求。
