一种基于遗传算法优化BP神经网络的陶瓷原料分类方法
2018-09-10杨怡涵柳炳祥
杨怡涵,柳炳祥
(景德镇陶瓷大学 信息工程学院,江西 景德镇 333403)
0 引 言
对陶瓷原料科学、快速、准确的分类,能为陶瓷配方中关键性的陶瓷原料遴选提供重要依据,有利于缓解日趋紧张的优质陶瓷原料供应现象,使得陶瓷原料这种宝贵的天然资源得以发挥其最大的价值作用。陶瓷原料的分类是一个复杂的材料学问题,陶瓷原料的种类繁多、结构复杂、成分多样,用传统实验方法进行分类效率低、错误率高。随着计算机科学和统计学的快速发展,越来越多的学者把这两门学科结合在一起,创立了许多新的分类方法。本文运用遗传算法优化的BP神经网络构建模型对陶瓷原料进行科学的分类。
1 BP神经网络模型
1.1 BP神经网络原理
BP神经网络是由Rumelhard和McCelland于1986年提出,从结构上讲,它是一种典型的多层前向型神经网络,具有一个输入层、数个隐含层和一个输出层。层与层之间采用全连接的方式,同一层的神经元之间不存在相互连接。BP神经网络是一种按照误差逆向传播来训练的多层前馈学习网络,网络中各个神经元之间的连接强度靠改变权值和阈值的大小来实现。BP神经网络的最大优点在于,通过训练样本反向传播调节网络的权值和阀值,来达到网络的误差平方和最小的目的。
1.2 BP神经网络设计
本文以某工厂收集的四种类别的30组陶瓷原料样品作为依据,构建了一个只有单隐含层的三层BP神经网络。如表1所示,以1-左云土、2-水曲柳、3-黑粘土、4-贵溪高岭、5-广东白泥、6-宽城土、7-飞天燕土胆、8-河北章村土、9-明水土、10-三节土、11-紫木节、12-黑山膨润土、13-四班瓷土、14-东北膨润土、15-飞天燕原矿、16-沩山东堡、17-三坪土、18-宜兴西山嫩泥、19-宜兴紫沙泥、20-宜兴红泥,这20组陶瓷原料样品数据作为BP神经网络训练数据;如表2所示,以21-安口土、22-宁海黏土、23-东莞黑泥、24-星子高岭、25-上店土、26-西丰土、27-易县土、28-大林泥、29-东山甲泥、30-朔县土,这10组陶瓷原料样品数据作为BP神经网络测试数据。
由表1、表2可以看出,陶瓷原料的特征值有9个,分别是:SiO2、Al2O3、Fe2O3、CaO、MgO、K2O、Na2O、TiO2、LOI,所以该网络的输入层节点数为9,输出层采用二进制字符进行识别,由于陶瓷原料有4个类别,所以输出层节点数为4。评价等级共有4个类别,如表3所示。

表1 训练样本的陶瓷原料数据Tab.1 Training samples of ceramic raw materials

表2 测试样本的陶瓷原料数据Tab.2 Testing samples of ceramic raw materials

表3 输出层类别Tab.3 Output layer classification
BP神经网络部分的参数设置为:激活函数为tansig,输出层函数为tansig,网络训练函数为trainlm,训练步数为1000,训练目标为0.0001,学习速率为0.01。根据Kolmogorov定理及相关经验,BP神经网络构建中间隐含层数目n2,输入层数目n1,输出层数目m;n2= sqrt(n1+m+1)+a;a=1-10,or n1=log2(n2)。通过试探法逐一测试隐含层节点数,得出最佳隐含层节点个数为23。至此一个9-23-4的BP神经网络就建立好了,网络训练步数和误差的关系曲线如图1所示,BP神经网络陶瓷原料测试样本输出结果如表4所示,训练步数为18,误差低于1×10-6,达到了预定目标,训练结束。
1.3 BP神经网络性能分析
由分析可知,BP神经网络的样本训练结果与输出设定存在一定误差。如表4所示,10个测试陶瓷原料样品预测的类别如下,类别Ⅰ:21、22、30;类别Ⅱ:23;类别Ⅲ:26、27、28;类别Ⅳ:29。通过对比表2的陶瓷原料类别可知,10组陶瓷原料的类别中只有8种被识别准确,其中24-星子高岭土和25-上店土的实际类别均为类别Ⅱ,而预测类别均与实际不符。通过对比可以发现,BP神经网络的预测精度低,识别准确率只有80%。

图1 BP神经网络训练步数和误差的关系曲线Fig.1 Relation curve of BP’s training epochs and MSE
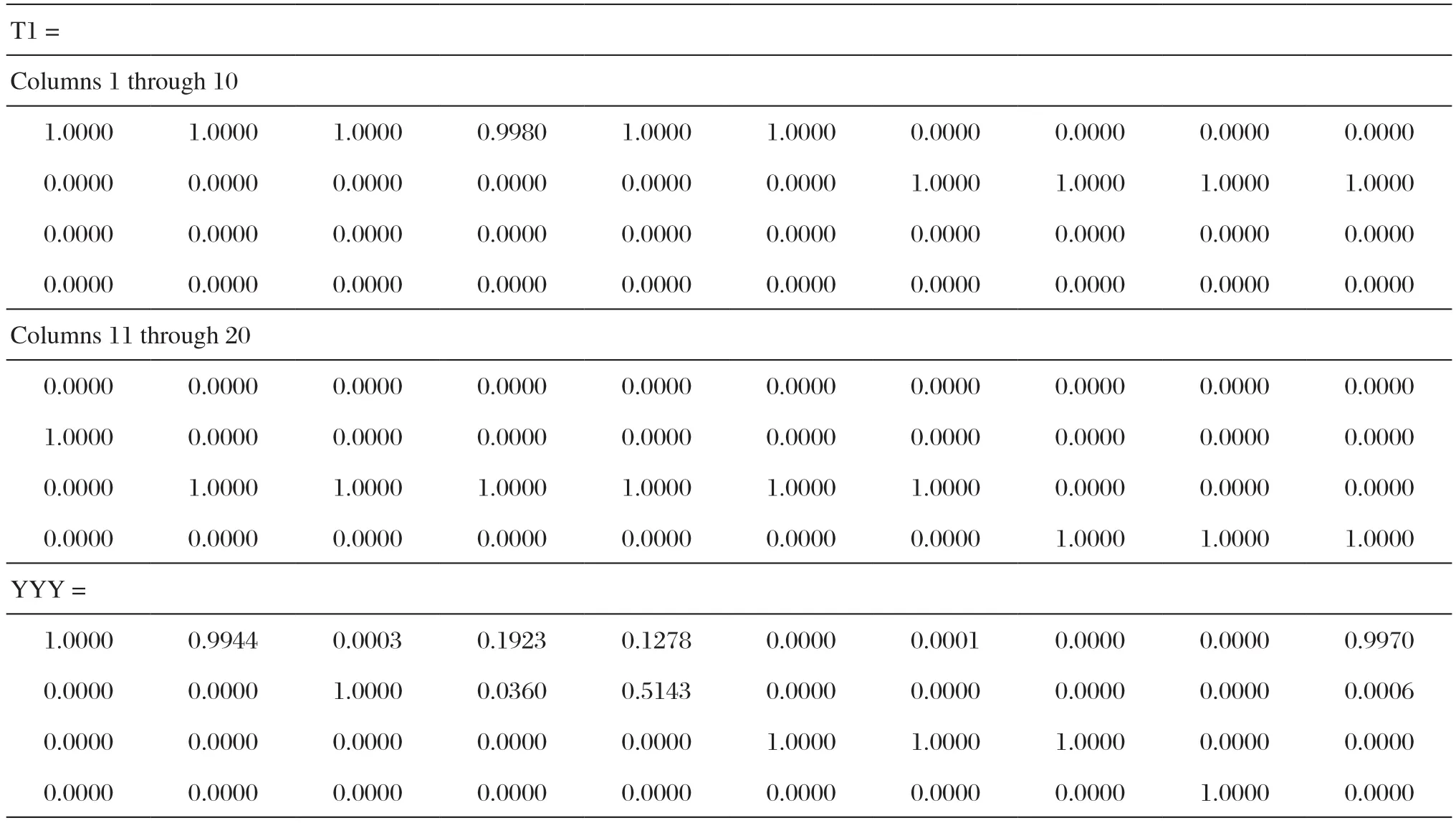
表4 BP神经网络陶瓷原料测试样本输出结果Tab.4 BP’s output result of testing samples
传统的BP神经网络的权值和阈值都是随机初始化的参数,网络学习的收敛速度慢,往往会有可能收敛于局部最优,精度低,需要进一步改进。
2 BP神经网络模型的改进与优化
2.1 遗传算法优化BP神经网络权值和阈值
遗传算法(Genetic Algorithm,简称GA)是一类借鉴生物界自然选择和自然遗传机制的随机化搜索算法。它模拟自然选择和自然遗传过程中发生的繁殖、交叉和基因突变现象,在每一次迭代中都保留一组候选解,并按某种指标从解群中选取较优的个体,利用遗传算子(选择、交叉和变异),对这些个体进行组合,重复此过程,最终收敛于全局最优解。遗传算法的流程如图2所示,遗传算法的优化过程如图3所示。
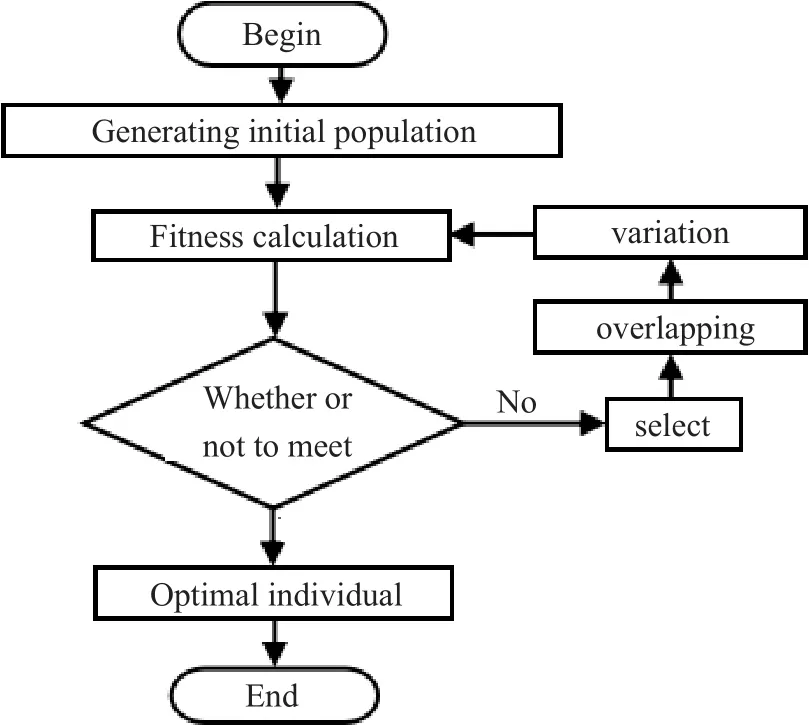
图2 遗传算法流程Fig.2 The flow chart of GA
2.2 实验参数设置
本次实验也以表1、表2中四种类别的30组陶瓷原料样品作为依据,其中以表1中20组陶瓷原料样品数据作为GA-BP神经网络测试数据,以表2中的10种陶瓷原料样品数据作为GA-BP神经网络测试数据。通过试探法逐一测试隐含层节点数,得出在隐含层节点个数为23时达到最佳。遗传算法部分的参数设置为:个体数N=60,最大遗传代数MAXGEN=60,变量的二进制位数PRECI=10,代沟GGAP=0.95,交叉概率px=0.7,变异概率pm=0.01。

图3 遗传算法进化过程Fig.3 Evolution process of GA

表5 GA-BP陶瓷原料测试样本输出结果Tab.5 GA-BP’s output result of testing samples
3 结果与讨论
GA-BP网络训练步数和误差的关系曲线如图4所示,GA-BP陶瓷原料测试样本输出结果如表5所示。
从图4中得出,当训练步数为19,误差低于1×10-6,达到了预定目标,训练结束。将表5中陶瓷原料预测类别的输出结果与表2对比可以看出,10种陶瓷原料测试样本类别与GA-BP神经网络的测试输出结果一致,识别率准确率可达100%。

图4 GA-BP网络训练步数和误差的关系曲线Fig.4 Relation curve of GA-BP’s training epochs and MSE
4 结 论
本文运用遗传算法优化神经网络的算法对陶瓷原料进行分类,优化了BP神经网络的连接权值和阈值,使识别精度与传统BP神经网络相比有了极大提高。实验结果表明,遗传算法优化的BP神经网络的分类结果和实际类别基本一致,识别精度较高,是一种可行且有效的陶瓷原料分类方法,具有一定的实际应用价值。
