一种递归K均值算法与上市公司绩效分类研究
2018-09-10石广龙
石广龙
摘 要:K均值算法的两个不足——最终聚类结果中簇的数目即K值需要用户事先设定以及用户一般不能直接对聚类结果中簇的半径作限定,限制了它的特定场合应用。本文结合上市公司绩效分类背景,对K均值算法作了改进,提出一种递归K均值算法。递归K均值算法不需用户在聚类之前就设定最终聚类结果中簇的数目,一定程度上减轻了用户负担;并且可以直接对聚类结果中簇的半径作出限定,有利于对簇内数据对象的相似程度进行控制。递归K均值算法的上述特性使得它可以很好地应用于上市公司绩效分类当中,提升分类的客观精确性。
关键词:递归K均值算法 聚类分析 上市公司绩效分类
中图分类号:F224 文献标识码:A 文章编号:2096-0298(2018)10(c)-169-02
聚类分析是数据挖掘中最重要的技术之一,主要目的是根据数据的对象特征及关系信息将数据对象分簇,使簇内的对象之间区别足够小,相似性足够大,而不同簇的对象之间相似性足够小,区别足够大;同一个簇内的对象之间的相似程度越高,不同簇之间的差异程度越高,说明聚类分析的效果越好。K均值算法是一种经典的聚类算法,但是它也存在一些不足,限制了它的应用和发展。本文结合上市公司绩效分类的背景,尝试对K均值算法作出改进,提出一种递归K均值算法,并将其应用于上市公司绩效分类,以提高分类的客观精确性。
1 K均值算法的不足
1.1 K均值算法基本思想
首先,由用户根据应用问题选择K的值,即选择把数据对象分为K个簇;对于每一个数据对象,都被归纳到一个质心,这个质心此时离它是最近的;所有被归纳到同一个质心的所有数据对象组成一个簇;其次,根据上一步得到簇的情况,更新每个簇的质心。然后,重复归纳每个数据对象到最近的质心;最后,重复以上更新质心和归纳数据对象到质心的过程,直到质心不再发生变化[1]。
1.2 K均值算法的两个不足
K均值算法的不足,使得它在一些特定应用中受到限制[2],两个主要不足包括以下内容。
(1)聚类数目K的值需要用户事先给定:在大多数实际应用中,用户事先无法准确判断多少个簇最理想。K值过大,会使聚类结果过于复杂难于分析;K值过小,会使聚类结果失去很多有价值的信息[3]。
(2)用户不能限定聚类结果的簇的半径:K均值算法的输入是数据对象集与人为设定的K,输出是K个簇。通常,它输出的K个簇的半径(一个簇的所有数据对象到质心的最大距离为这个簇的半径)不受人为约束,即聚类形成的K个簇,有些簇的半径可能很大,有些簇的半径可能很小[4]。
2 一种递归K均值算法
2.1 递归K均值算法思想
对于含有n个数据对象的数据集,以根为节点,利用K均值算法做聚类,并计算每个簇的半径,若半径不大于事前设定的阈值,则这个簇不再划分;若半径大于给定阈值,则利用K均值算法对其进行划分,程序递归执行,直到所有叶节点簇的半径都不大于给定阈值。
2.2 递归K均值算法特点
(1)树型结构中叶子(簇)的数目取决于簇的半径阈值Y,Y可以根据聚类的特定目的而设定。Y越小,簇的数目就越多并且簇内数据对象的相似程度就越高;Y越大,簇的数目就越少并且簇内数据对象的相似程度就越低,这使得簇内对象相似性可控。
(2)不同于基本K均值算法在聚类之前就设定最终聚类结果中簇的数目,递归K均值算法仅仅设定每次调用基本K均值算法对数据对象集聚类簇的数目,一定程度上可以减轻用户负担。
3 递归K均值算法在上市公司绩效分类中的应用
将提出的递归K均值算法应用到上市公司绩效分类中:一方面,检验递归K均值算法在上述两个方面改进的有效性;另一方面,基于递归K均值算法建立一种上市公司绩效分类方法,提升分類的客观精确性。
3.1 传统分类方法及不足
(1)传统分类方法。国外常见的上市公司绩效分类方法有《财富》500强分类方法、《商业周刊》分类方法;国内比较常用的上市公司业绩评价方法有诚信评估公司、《上海证券报》以及上海证券交易所的绩效评价分类方法[5]。
(2)传统分类方法的不足。第一,指标选取较少,而且各指标权重由人为设定,难于科学全面地体现上市公司经营绩效真实情况;第二,过度追求上市公司个体最终得到一个综合分数,只关注上市公司排名,忽略了上市公司群体的绩效分类,也没有深层次挖掘上市公司绩效相关的更多信息[6]。
3.2 上市公司绩效分类对聚类算法的特定要求
(1)通过聚类分析,发现某一行业中,可以根据经营绩效划分为几个群;但是在聚类之前不知道划分为几个群比较合适,即聚类结果数目(K)不能在聚类之先人为指定,而要根据具体聚类数据确定。
(2)对一个群内上市公司经营绩效相似程度作出限定,这样的分群才有实际分析意义,即聚类形成的簇的半径R应该在一定程度之内,R在聚类之前人为指定。
3.3 基于递归K均值算法的上市公司绩效分类
(1)分类模型与过程。建立基于递归K均值聚类算法的上市公司经营绩效分类模型与过程:第一,上市公司指标选取,选取体现上市公司的偿债水平、盈利水平、成长水平三大类16个财务指标(2017年A股电子信息行业331家上市公司真实数据);第二,利用主成分分析方法,分别对偿债、盈利、成长水平三大类指标进行降维,将每家公司的特征属性降至三维;第三,针对主成分分析处理后的数据,分别使用基本K均值算法与递归K均值算法做聚类实验,得到结果簇;第四,对实验结果做对比分析,验证递归K均值算法在K值选取与聚类结果簇的半径约束方面的改进是否有效;第五,基于递归K均值算法的聚类结果,做上市公司绩效分类,并初步验证。
(2)结果对比分析:聚类结果对比如图1、图2所示,两种算法比较如表1所示。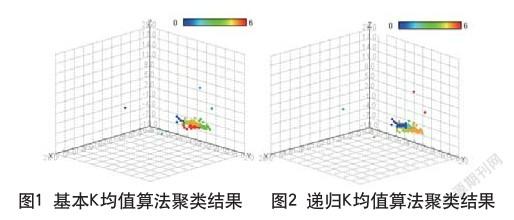
实验中簇的半径区间:K均值算法为[0,27.884];递归K均值算法为[0,8.090],小于阈值10,簇较均匀。由聚类结果可以证明递归K均值算法在K值选取与聚类结果簇的半径约束方面的改进是有效的。
(3)绩效分类效果初步验证:根据递归K均值算法的聚类结果,电子信息行业331家上市公司被分为了7个群,经初步验证,每个群内的公司在经营绩效方面都具有较高的相似性,即该方法提升了上市公司绩效分类的客观精确性。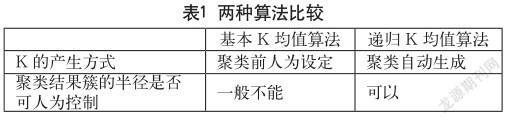
4 结语
本文结合上市公司绩效分类的具体应用背景,提出了一种递归K均值算法,并将其应用于上市公司绩效分类当中,提升了分类的客观精确性。
参考文献
[1] 冯超.K-means聚类算法的研究[D].大连理工大学,2007.
[2] 赵恒.数据挖掘中聚类若干问题研究[D].西安电子科技大学, 2005.
[3] 段明秀.层次聚类算法的研究及应用[D].中南大学,2009.
[4] 孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1).
[5] 马璐.企业战略性绩效评价系统研究[M].北京:经济管理出版社,2004.
[6] 冯必容.基于价值的企业战略绩效评估体系[J].技术经济与管理研究,2006(1).
