基于近红外光谱技术的信阳毛尖品质判别研究
2018-09-08刘洋余天星李明玺王敏黄莹捷郭桂义王子浩万春鹏
刘洋,余天星,李明玺,王敏,黄莹捷,郭桂义,王子浩,万春鹏
(1.江西农业大学农学院,茶学与茶文化研究中心,江西南昌 330045)(2.河南省豫南茶树资源综合开发重点实验室,信阳农林学院,河南信阳 464000)
信阳毛尖是主产于河南省信阳市的中国名优绿茶,属中国地理标志产品,也是河南省著名的土特产之一,素来以“圆、细、直、紧、多白毫,味浓、香高、色绿”的独特风格而享誉中外[1]。目前对信阳毛尖的研究较多,主要集中在香气成分检测[2],烘焙制茶工艺[3],微量营养成分[4]和茶文化等方面,近红外光谱无损检测方面仅见其对信阳毛尖茶中茶多酚含量的测定报道[5]。信阳毛尖茶叶等级、品质判别主要是通过茶艺师的感官评审及常规理化分析,而茶叶的感官评审主要是依靠人的视觉、嗅觉、触觉和味觉等综合信息判断,往往受评审者的经验、心理与生理等多种因素的影响。为了使信阳毛尖茶在生产、流通等过程中有一套一致的、准确的评价方法,需要使用快速无损检测新技术、新仪器对其进行辅助检测。近红外光是指波长在780~2526 nm范围内的电磁波,其记录的主要是含氢基团CH、NH、OH等振动的倍频和合频吸收带。近红外光谱技术(NIRS)是无损检测技术中一类重要的检测技术,具有无需前处理、快速、无损、多组分同时测定等优点。NIRS在许多领域均有应用,尤其是近几年在食品研究领域应用广泛,可用于食品微生物检测[6]、食品新鲜度预测等[7]。目前,利用近红外光谱分析技术在茶叶品质上的研究主要在定量分析与定性分析,一方面是对茶叶品质成分的快速定量分析测定,另一方面是对茶叶等级、品种和产地等进行定性分类判别[8,9]。
Schulz等[10]采用 NIRS技术结合偏最小二乘法(PLS)分析了韩国绿茶中茶多酚和生物碱含量,没食子酸(GA),表儿茶素(EC),表没食子儿茶素(EGC),表儿茶素没食子酸酯(ECG),表没食子酸儿茶素没食子酸酯(EGCG),咖啡因,可可碱,均获得了较好的校正模型,相关系数R2>0.850,近红外光谱可用于绿茶中茶多酚和生物碱含量预测。陈全胜[11]等采用净分析物预处理法(NAP)对提取的近红外光谱进行预处理、利用偏最小二乘法(PLS)建立了绿茶中三种儿茶素(EGCG、ECG和EGC)含量的定量模型,考察了利用NAP法进行光谱预处理对建模的影响。三种儿茶素单体定量模型校正时的相关系数分别达到 0.951,0.967和 0.968,预测时的相关系数则达到 0.930,0.940,0.946,模型效果良好,NAP预处理可以有效简化绿茶中儿茶素含量预测模型。
NIRS技术在茶叶理化成分模型的简化与优化上的研究也比较多,采用其他光谱预处理方法(相关分析、正交信号、净分析和小波消噪等)和特征谱区选择方法(遗传算法、移动窗口PLS、间隔PLS、联合区间PLS等)并结合线性(PLS、MPLS)、非线性的建模方法(人工神经网络、支持向量机等)建立模型[12~15]。Chen Q[16]将应用最多的三种不同的线性和非线性回归分析工具,偏最小二乘(PLS)、反向传播神经网络(BP)和支持向量机(SVM)研究快速和有效地测量绿茶中的抗氧化活性,通过所建模型,根均方预测误差和相关系数的比较,发现SVM 构建的模型最优。
NIRS技术在茶叶理化成分测定应用中的研究也已经越来越成熟,涉及的指标有:水分、游离氨基酸、咖啡碱、茶多酚、全氮量、水溶性蛋白质、纤维素、主要儿茶素(EGC,EC,EGCG和ECG)、茶多糖、总抗氧化能力(TAC)等十几种,模型的精确度也较高。可以建立模型来同时检测茶叶中的多种有效成分并应用到茶叶生产与流通过程中,实现快速检测的目的。本文以不同等级的河南省名茶信阳毛尖为研究对象,应用近红外光谱偏最小二乘法(NIRS-PLS)建立其茶叶等级品质的识别模型,为其快速识别提供一种方法。
1 材料与方法
1.1 实验样品采集与处理
试验采用的所有样品于2017年11月购买河南省信阳市浉河区茶叶市场,均为2017年浉河区产的信阳毛尖茶。将每个样品各20 g经粉碎机粉碎处理1 min,过50目筛,取筛下茶样用于后续实验。所有样品均装于密封袋中置于冰箱中,0 ℃左右冷藏保存备用。样本采集信息如表1所示。

表1 实验用茶样品的来源信息Table 1 The information of tea samples used in the experiment
1.2 光谱采集及分析
所有茶样的近红外光谱数据均采集于 U-4100紫外/可见/近红外分光光度计(日本日立公司生产),随机附带的软件UV Solutions 2.1程序(日立公司,东京)操作,漫反射旋转扫描模式采集数据。采集时室温控制在25 ℃左右,湿度保持稳定,所有数据当天采集完毕。精确称取0.500 g茶样于石英样品槽中(直径=22 mm,深度=2.5 mm),用石英玻璃盖片轻轻压紧,使样品形成平整的表面,光谱扫描波长范围为800~2500 nm,分辨率2 nm,扫描次数32次,共采集851个数据点,同一样品每次采集光谱3次,平均光谱用做后续数据分析。反射吸光度A的计算参照下述公式[17](R为样品相对漫反射率,光路参照标准为硫酸钡)。
A=log[1/R]=-log[R]
1.3 生化成分测定
茶多酚含量测定采用酒石酸亚铁显色法(GB/T 8313-2008《茶-茶多酚的测定》);咖啡碱含量测定采用紫外分光光度计法(GB/T 8312-2013《茶-咖啡碱测定》);氨基酸含量测定采用茚三铜比色法(GB/T 8314-2013《茶-游离氨基酸总量测定》)。
1.4 数据分析
在Matlab R2006a软件平台上自编脚本,对光谱信息进行方差分析(ANOVA),选取特征波长。利用SIMCA14.1软件(Umetrics),进行数据预处理、正交偏最小二乘法-判别分析(OPLS-DA),并采用偏最小二乘法(PLS)预测茶叶的产地,以交叉验证均方根误差(RMSECV)和相关系数评价预测的准确程度。
2 结果与讨论
2.1 波长范围的选择

图1 所有茶叶样品800-2500 nm近红外光谱图Fig.1 Near-infrared spectrum of all tea samples with wavelength range from 800 nm to 2500 nm
近红外光谱对茶样的无损检测模型的准确率与样品数量关系较大,张正竹等[18]基于近红外光谱技术对不同产地的红茶样品进行了产地溯源研究,对产自安徽(14个样)、湖北(26个样)、云南(30个样)、印度(25个样)、肯尼亚(11个样)、斯里兰卡(17个样)和缅甸(17个样)的红茶样品进行了准确的溯源。图1为61个茶叶样品波长范围为 800~2500 nm的近红外光谱原始图,长波长一端吸收峰较为集中,延伸至短波长方向,吸收峰则相对发散。不同的波长吸收反映的是样品中化学组成官能团的特征吸收。选择特定的波长,实际上是选择分析特定的功能团。不同种类的样品均含有对分类鉴定有重要贡献的物质,其特征吸收峰因样品类型不同而有差异,因此选择波长范围,对于建立预测模型非常重要。孙耀国等[19]将绿茶近红外光谱图划分为Ⅲ个波段(Ⅰ:800~1400 nm,Ⅱ:1400~1860 nm,Ⅲ:1860~2500 nm),这与本研究得到的信阳毛尖茶近红外光谱图类似。其中波段Ⅰ是近红外光谱的二级倍频谱区,信息相对为最弱,它主要反映的是茶叶样品中分子结构相对简单的一些有机小分子化合物结构信息,主要为茶叶中的香气成分结构信息;波段Ⅱ是近红外谱的一级倍频谱区,较波段Ⅰ信息稍强,它主要反映的是茶叶样品中单糖、寡糖、纤维素等的分子结构信息;波段Ⅲ是近红外谱的合频谱区,信息最强,它主要反映蛋白质、氨基酸、多糖等的分子结构信息。
通常选择波长的范围的方法,是通过肉眼观察,凭直觉选择,然后建立模型,根据不同的预测结果对所选波长范围进行评价,以确定波长范围。
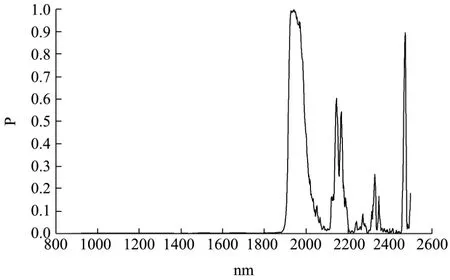
图2 波长与相伴概率的关系图Fig.2 The relationship of wavelength and concomitant probability
本文在波长选择方式上进行了改进,对三个不同等级的茶叶的所有波长的响应进行单因素方差分析,结果如图2所示:横坐标为近红外光谱的波长,纵坐标为相伴概率P,P小于0.05,说明不同等级样品间有显著性差异。800~1800 nm的近红外光谱数据P值远小于1800~2500 nm波段数据,因而选择800~1800 nm作为后续分析波长。
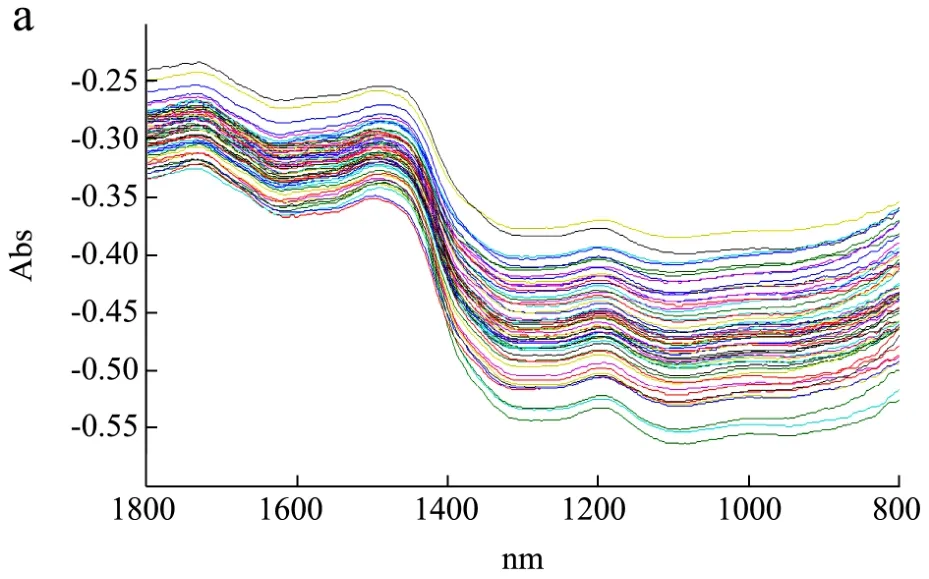

图3 所有茶叶样品800-1800 nm近红外光谱图(a),一阶导数图(b)Fig.3 Near-infrared spectrum of all tea samples with wavelength range from 800 nm to 1800 nm (a) first derivative spectra (b)
图3a为61个茶叶样品波长范围为800~1800 nm的近红外光谱原始图,所有样品经过一阶导数预处理的光谱如图3b所示。在波长1164 nm和1416 nm处的峰,他们分别与水的伸缩一弯曲组合模式和茶多酚物质的 OH键一级泛频振动有关[20];在1522 nm和1600 nm处的峰可能由于茶叶中氨基酸NH2官能团和葡萄糖的泛频振动带[21];在波长为1702 nm处的波带对应于CH键伸缩的一级泛频振动[22],而位于1562 nm和1762 nm波带分别对应于茶多酚OH键和茶氨酸C=O键的二级倍频振动[23]。
2.2 生化成分测定
不同等级信阳毛尖茶的化学成分测定结果见表2。茶叶中富含20多种氨基酸,尤其是茶氨酸含量最高,是构成绿茶茶汤鲜爽滋味的主要成分,绿茶等级越高,氨基酸含量就越高;除了氨基酸,茶多酚及咖啡碱也是绿茶滋味的重要物质。信阳毛尖的茶多酚含量相对较高,为25.97%~27.87%,且咖啡碱含量也均高于4%,这与我们之前研究结果一致[24]。

表2 不同等级信阳毛尖茶的氨基酸、茶多酚和咖啡碱含量Table 2 The contents of amino acids, tea polyphenols and caffeine of three grades Maojian tea
2.3 OPLS-DA分析
在NIRS漫反射光谱中,存在各种干扰,如光散射等,必须对NIRS光谱进行数据预处理,以消除基线漂移及噪声,提高所建立模型的预测精度。实验采用SIMCA 14.1软件对800~1800 nm的所有样品进行小波变换去噪,母基函数为Daubechies,分解水平为4级,将预处理后的数据进行OPLS-DA分析。
OPLS-DA是有监督的模式识别方法,目前广泛应用于代谢组学分析,其优点是可以通过散点图和t检验确定差异显著的变量或参数。图4为OPLS-DA的散点图,图中所有样品均置于置信区间为0.050%的椭圆内,表明无异常数据,如果有样品处于椭圆之外,则为异常值,分析时需要剔除。图4结果显示:一芽二叶、一芽一叶和单芽信阳毛尖茶在X轴方向顺序排列,明显分开,均得到了正确分类。其中单芽茶叶在图中更集中,另两个等级的茶叶略分散,这也进一步说明了信阳毛尖单芽等级茶样本间的差异较小,而一芽二叶、一芽一叶等级茶样本间的差异较大。本实验中,OPLS-DA 的 R2X(cum)为 1,R2Y(cum)为0.738,Q2(cum)为0.582。R2越接近1,说明样品受噪声干扰越小,组内重复性越好,所建模型越稳健。Q2大于 0.500,则说明该模型的预测能力好。由上可知,本实验所建立的数学模型稳健,具有良好的预测性。

图4 三个等级信阳毛尖茶的OPLS-DA散点图Fig.4 OPLS-DA scores plot of three different grades of maojian tea
OPLS-DA载荷分析中,VIP值(Variable Importance)大于 1的变量被认为对样品正确分类有显著的贡献。本实验选取VIP值最大的前39个变量(VIP值>1.081)如表3所示。1706~1774 nm对样品正确分类的贡献最大,表明CH键伸缩的一级泛频振动,茶多酚OH键和茶氨酸C=O键的二级倍频振动信号有显著的贡献。1568~1602 nm茶多酚OH键的二级倍频振动信号;800 nm左右信号为茶叶中氨基酸NH的四级倍频振动信号。因此,结果表明茶多酚和茶氨酸对样品正确分类的贡献最大。不同等级的信阳毛尖,其茶多酚、氨基酸、生物碱、叶绿素及水浸出物等内含物差异较大,研究表明随着茶叶等级的降低,叶绿素含量会升高,而茶多酚、氨基酸和生物碱含量会降低[25],说明茶多酚、氨基酸和生物碱等成分对茶叶等级分类具有重要的作用,这与本研究生化成分测定结果一致。
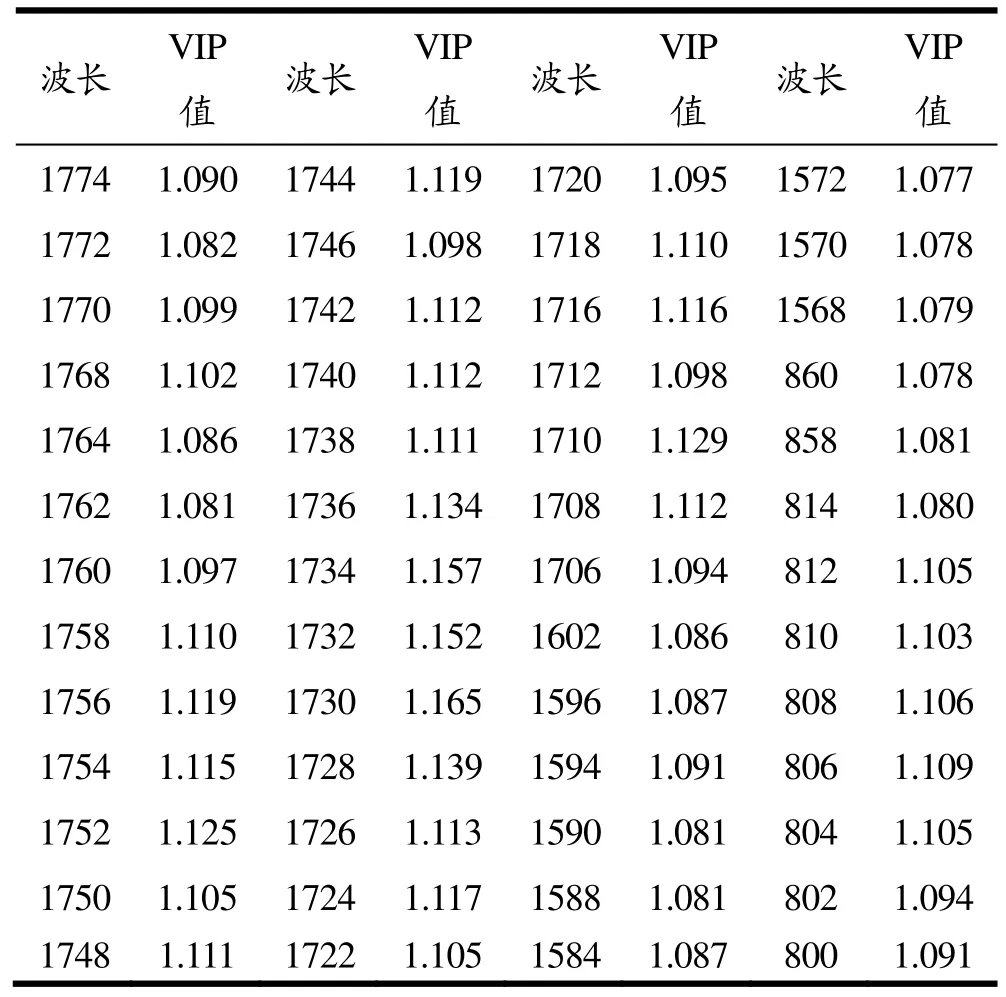
表3 OPLS-DA载荷VIP值大于1的波长变量Table 3 The Variable of VIP value greater than 1 by OPLS-DA loading
2.4 偏最小二乘法预测茶叶等级

图5 PLS预测值和理论值回归图Fig.5 Partial Regression Leverage Plots of theoretical values and predicted values analyzed by PLS
PLS在化学计量学中应用广泛,其结合了多元线性回归和主成分回归,预测能力强,能够应用于复杂的样品体系。本实验通过偏最小二乘法建立信阳毛尖茶等级的判别分析模型,留一法交叉验证。以单芽茶叶为1,预测值在0.500~1.500范围内正确分类;一芽一叶茶叶为2,预测值在1.500~2.500范围内正确分类;一芽二叶茶叶为3,预测值在2.500~3.500范围内正确分类。图5为理论值和预测值的回归图,样品预测正确率为100%,RMSECV为0.090,相关系数为0.994。
分别从三个等级茶样中任意选取二个样品作为预测集,其余样品为训练集(单芽茶样18个。一芽一叶茶样品19个,一芽二叶样品18个),利用SIMCA14.1软件中的PLS模块进行训练,所建PLS模型的R2X(cum)为1,R2Y(cum)为0.904,Q2(cum)为0.755,该模型具有较好的预测性。对预测集进行预测,理论值同上,预测值分别为0.84,1.07(单芽);2.04,1.92(一芽一叶);2.61,2.72(一芽二叶);预测准确率为100%,均方误差(RMSE)为0.21。
3 结论
本文建立了NIRS光谱结合PLS快速无损检测河南信阳毛尖茶不同等级品质的方法。通过方差分析,选择了数据分析的波长范围,采用小波变换滤噪,对光谱进行预处理。OPLS-DA分析表明三个不同等级信阳毛尖茶可以有效区分,茶多酚和茶氨酸对样品正确分类的贡献最大。进行数据预处理后,所建立的PLS预测模型中,理论值和预测值之间具有良好的相关性,相关系数为0.994,预测准确率为100%,交叉验证均方根误差RMEV为0.090,表明模型预测准确、可靠。本实验所建立的近红外光谱检测方法,检测速度快,可用于大批量茶叶的快速无损检测及现场测定,满足生产企业现场收购的质检质控要求,对监督部门进行质量监督有重要意义。
