基于协同过滤的个性化选课推荐与评论系统
2018-09-07周泽宇王春玲
周泽宇,王春玲
(北京林业大学 北京 100083)
1 绪论
1.1 研究背景及意义
随着现代信息技术的广泛应用,移动互联网、云计算、大数据等新兴技术迅猛发展,全球数据量呈爆炸式增长,全球数据中心流量仅2015年就已经达到4.7ZB,预计到2020年的时候,全球的数据总量将达到40ZB。那么,如何使用户更加方便地、容易地从海量数据中检索出所目标资源,如何有效地、合理地组织和管理网络数据信息,成为电子信息领域进一步发展所遇到的重要问题之一。
推荐系统能够为用户提供个性化的服务,它针对于“信息超载”现象,能够有效地进行信息过滤、信息细化等工作,并帮助用户高效的查询目标。
协同过滤推荐技术是目前发展较为完善的推荐技术之一。近年来,协同过滤推荐系统逐步广泛应用于社交、电商、新闻等领域,其发展历史上主要有Tapestry、GroupLens、Netflix、Amazon等典型案例。协同过滤推荐算法融合了大数据、社会网络分析和关键用户分析三方面热点技术,能够有效解决用户兴趣的准确捕捉问题,以提高用户推荐质量。
1.2 国内外研究现状
个性化推荐系统的概念诞生于20世纪90年代,其主要发展是跟随电子商务兴起的脚步,而后逐渐成为一个独立的课题。现如今,个性化推荐技术的应用已经拓展至诸多领域,包括影音娱乐、社交媒体甚至阅读学习等方面[1]。个性化推荐技术的技术核心在于推荐算法和推荐应用两方面,根据不同推荐应用的推荐需求和限制条件,应选择使用不同的推荐算法。
协同过滤算法的发展受到用户反馈数据稀疏性问题和系统扩展性问题的制约,近年来,国内外学者在提高推荐效率和系统拓展性方面做出许多研究。为有效提高推荐系统的可拓展性,有学者提出利用二维矩阵将项目表示成用户项目矩阵,以确定用户或项目之间的关系并计算得出推荐项目[2]。另有人提出可以使用奇异值分解技术,进行特征向量的降维处理,从而减少算法查找最近邻居所需的计算量,以提高可拓展性[3]。为提高系统的推荐质量,Elkahky等人提出了一种跨域用户模型的多视图深度学习方法,该方法使用用户浏览历史和搜索内容的特征集来代表用户,然后用深度学习的方法将用户和项目映射到一个潜在空间使用其用户与首选项目之间的相似性最大化,产生推荐[4]。
个性化推荐技术的推荐效率、实用性和准确性在不断提升,但用户需求也在不断提高。尽管有关于协同过滤技术的理论研究及应用系统实现两方面都取得了不错的成果,但该算法仍存在诸多问题,如数据稀疏性、推荐准确性、冷启动、拓展性和稳定性等。
2 协同过滤推荐技术
2.1 个性化推荐技术
个性化推荐技术是根据用户的兴趣特点和购买行为,经过数据分析,从而向用户推荐其可能感兴趣的信息和商品的过程。推荐算法可以在计算用户之间相似度时,加入用户个人项目偏好信息,以丰富用户数据,确保相似度的准确性,尽量避免数据稀疏性带来的不利影响。
个性化推荐系统的标准形式化定义为:设用户集合U={u1,u2,……,un},项目集合I={i1,i2,……,im},有关推荐的相关系数Res(),Res(u,i)表示系统对于项目i推荐给用户u的预测评价,全序集合Res(u,i)在一定范围内浮动,是非负实数。个性化推荐的本质就是找到关于推荐目标用户u来说推荐度最大的N个项目的集合Iu,并返回给用户。
2.2 协同过滤推荐技术
2.2.1 基于用户的协同过滤算法(User-based Collaborative Filtering) 基于用户的协同过滤算法的基本思想是:假设过去有相同爱好的用户在将来也会有相同的爱好。基于假设,协同过滤算法无需考虑网络信息资源,只需要依靠系统中系统筛选出的与目标相似的用户或项目信息,即可通过计算分析得到推荐依据。
基于用户的协同过滤算法的基本原理是:根据系统中用户的历史活动记录和偏好信息,计算目标用户与其他用户之间的相似度,得到用户之间的相似度矩阵,进而为活动用户选择近邻集,最后,分析近邻用户对候选推荐项目的反馈信息,预测目标用户对候选推荐项目的评分,进而确定推荐项并推荐给目标用户[5]。
2.2.2 基于项目的协同过滤算法(Item-based Collaborative Filtering) 实践发现基于用户的协同过滤算法在数据稀疏性和系统可拓展性方面具有较大的问题,Sarwar等人经过研究并在2001年,提出了基于项目的协同过滤算法。
其基本原理是:通过分析所有用户对项目的反馈信息,计算得到各个项目之间的相似度,再根据系统中的用户历史信息,分析目标用户的个人偏好,对比偏好信息和项目的相似性,将相似度高的项目推荐给目标用户[6]。
2.2.3 基于模型的协同过滤算法 基于模型的协同过滤算法,通常利用统计方法或者机器学习进行建模运算,使系统能够处理用户在离线状态下所需的计算,根据用户历史信息和对用户建模并进行预计算,在线状态时则使用用户偏好模型进行喜好分析,从而对用户产生推荐,以达到快速响应。该算法具有稳定性高,时效性高的优点,但需要大量用户的反馈数据,且使用条件受限,只在用户兴趣与特征比较稳定的环境中,具有较高的推荐效率。该方法将算法中最为主要的核心问题在于计算用户评分的方法,在推荐精确度上一般比同类其他算法稍差,算法的实用性也受到一定限制。
3 协同过滤在高校课程推荐中的应用
3.1 算法设计
3.1.1 算法功能设计 设计目标是高校课程推荐系统能够在为学生用户提供详细的课程信息的同时,根据其个人偏好,为其智能推荐合适的课程。初次推荐时,系统可根据用户设置的自定义标签,选择具有相同标签的课程为目标用户进行推荐。应用社会标签系统,避免协同过滤算法冷启动现象带来的问题。数据库信息完善后,系统将以课程收藏信息作为用户对项目的反馈数据,根据Collection数据表,获取用户偏好,从而计算用户间相似度,通过相似度较高的用户的收藏信息为目标用户提供课程推荐。
3.1.2 数据库设计 与协同过滤推荐算法实现相关的数据表有Course课程表、User用户表、Collection收藏表等。Course表和User表分别用来存储课程信息和用户信息,Collection表包含userid属性和courseid属性,用以建立课程和用户之间的关联,并向算法提供用户对课程的反馈信息。
3.2 算法实现
3.2.1 协同过滤推荐算法的一般实现过程 用户、推荐方法和项目资源是个性化推荐实现过程中最重要的三个要素。协同过滤推荐系统通常使用的推荐分析方法,首先建立用户个人信息,通过用户反馈评分信息,了解用户的行为特征、习性与偏好信息,然后再将资料库中的所有资料或所有新增资料与用户个人信息进行匹配,进行相关数据处理工作,最后利用算法提取用户的偏好或特征,找出类似的群组提供给用户[7]。
基于用户的协同过滤推荐技术的推荐算法实现步骤一般包括以下三个部分:用户喜好的收集与表示、选择近邻集和根据近邻集为用户返回推荐结果。
(1)用户行为数据收集:应用算法时,通过数据库中用户的历史数据收集信息并表示用户的喜好,将用户偏好信息进行整理。
(2)建立用户邻居:协同过滤技术根据评分矩阵、用户历史行为,选择合适的公式方法计算用户间相似性,得到与目标用户相似的用户集,称之为用户邻居,将这个最近邻居使用过的标签,作为目标用户的推荐标签。根据系统情况选择合适的计算方式,不同的相似度计算方法,可能得到不同的相似度结果。
(3)产生推荐:收集近邻用户对候选推荐项目的反馈信息,预测目标用户对候选项目的评分,主要使用的预测方式有两种,预测活动用户对任意项n的评分和Top-N推荐列表。最终,将预测评分较高的项目推荐给目标用户或为目标用户提供推荐列表。
基于项目的协同过滤推荐步骤与基本相似,但用项目之间的相似性代替基于用户的算法中的用户之间的相似性,作为推荐的计算依据。该推荐算法的一般实现过程包括以下步骤:
(1)计算项目间相似度:与计算用户间相似度相同,建立项目评分矩阵,项目相似度矩阵用行和列表示项目,rij表示项目i和项目j之间的相似度。再根据公式计算项目间相似度。目前主要用于计算项目间相似度的方法有余弦向量相似度、Pearson相关系数等。
(2)选择近邻:目前主要使用设定阈值和K最近邻两种方法,与“基于用户的协同过滤”不同的是,从活动用户的已评分项目集中选择待预测项目的相似近邻。
(3)产生推荐:与基于用户的推荐相同,可以根据Top-N推荐列表选择推荐项,或通过对给定项目预测评分进行挑选。
3.2.2 相似性度量方法 推荐算法中涉及许多用户、项目、商品或标签等之间相似度的计算,相似度的计算方式是有关推荐算法最主要研究的问题之一,在不同的数据量或推荐要求的限制下,选择不同的推荐方法,应使用不同的相关度计算公式。基于夹角余弦的方法和基于皮尔逊相关系数的方法,是应用范围最广的两种相似度计算方法[8]。
(1)余弦相似度:

公式中rU,S是用户u对商品s的打分,SUV是用户u和用户v共同购买的商品。sim(a,b)的取值在0到1之间,其值越大表示用户u,v之间的相似性越大。
(2)Pearson相关系数:

rU表示用户u的平均打分,rV表示用户v的平均打分,rU,S是用户u对商品s的打分,SUV是用户u和用户v共同购买的商品。根据Pearson公式计算得到的相似度取值范围为-1到1,1表示完全正相关,-1表示完全负相关,0表示无关。但是该相似度并没有考虑重叠数对相似度结果的影响。
(3)欧几里得距离:

根据用户u对商品s的打分rU,S和用户v对商品s的打分rv,S,计算用户u和用户v的欧几里得距离。该方法也没有考虑重叠数对相似度结果的影响。
3.2.3 UBCF算法在选课系统中的实现过程
根据上述推荐步骤和2.2.2中基于用户的协同过滤推荐算法的实现原理,本项目中UBCF算法应用过程如流程图图1所示,包括5个步骤,3个主要过程:

(1)选取数据集
共选取北京林业大学信息学院30名学生用户、20门课程的信息作为算法实验数据,近邻K取值为5,即选择5个相似近邻组成近邻集。学生用户和课程属性作为算法输入数据,构造用于表示用户偏好的HashMap:UserPreferMap和用于表示用户相似性的HashMap:UserSimMap。可用一个m*n的矩阵R来表示用户的信息数据,矩阵中的Rij代表示用户i对推荐对象j的反馈,就可以得到用户-项目评分矩阵。用户相似性矩阵与其类似。
在UserPreferMap中,填入用户对课程的评分,即本项目中的收藏情况。用户已收藏用项目评分2表示,用户历史收藏用项目评分1表示,用户未曾收藏用项目评分0表示。
(2)计算皮尔相关系数:
应用上文2.2.5中皮尔逊相关系数公式,分别计算目标用户x与其他用户y之间相似度,相关系数的绝对值越大,相关度越大。
调用数学函数计算公式:

将用户之间的相似度计算结果保存在UserSimMap中。
用户相似度结果如下(推荐度排名前5名):

(3)根据近邻相似度获得对目标用户的推荐课程:
构造用于表示预推荐课程的预测评分的HashMap:predictScoreMap,读取UserPreferMap和UserSimMap数据。课程i关于用户u的预测推荐分数Res(u,i)为,目标用户u与user1,user2,…,userk的相关系数与其对课程i的项目评分Rui乘积之和,即:
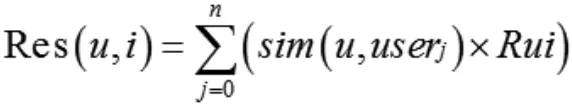
根据目标用户近邻集,分别计算所有课程关于目标用户的预测推荐评分,并存入predictScoreMap中。根据Top-N方法,按照预测评分对所有课程重新进行由大到小排序,按顺序对目标用户进行推荐。
3.3 协同过滤推荐系统面临的问题
(1)数据稀疏性问题(Sparsity)
数据的稀疏性问题是协同过滤推荐算法所面临的最主要问题之一。通常用户自愿给出的评价很少,严重会导致系统有效数据缺乏,使用项目-评分矩阵获取相关系数时,算法很难精准的计算出用户或项目之间的相似度,易致使用户邻居计算不准确,严重影响推荐质量。
(2)冷启动问题(Cold-start)
当一个新用户或新项目启动系统推荐任务时,或是一个全新的系统初次启动时,推荐系统无法从数据库中采集到用户的历史数据,从而无法预测用户未来的兴趣。
(3)扩展性问题
商业网站通常会从在数以万计的用户和项目,推荐算法在计算最近邻居时的搜索时间和空间将会非常庞大。面对巨大的数据量,很难保证算法的实时性。
3.4 混合推荐技术
每种推荐算法都有其各自的优缺点,在面对复杂且数据繁琐的项目时,协同过滤算法具有更加高的效率,却无法如而基于内容推荐,能够为特殊兴趣用户服务,但基于内容推荐较难发现用户的潜在兴趣。因此,使用组合推荐(Hybrid Recommendation),将多个推荐算法混合在一起,能够达到更好地推荐效果。目前领域内关于混合推荐技术研究和应用的方向最主要集中于基于内容推荐和协同过滤推荐的组合。
4 总结与展望
推荐技术在如今的各个领域中广泛应用,与搜索引擎不同,推荐系统不需要用户手动检索所需信息,而是根据用户的历史行为记录、兴趣偏好等数据,得出用户的潜在偏好,再通过预测分析向目标用户推荐其最可能感兴趣的信息或商品。
目前,关于UBCF算法的研究已经成熟,可以有效利用已有学生用户信息和课程信息为目标学生推荐自身符合条件的课程。但为了提高推荐质量,可以尝试将U-CF-I即基于用户和基于项目的混合推荐算法应用于高校课程推荐系统中,能够进一步提高课程推荐的准确度。
个性化推荐系统目前已广泛应用于各个领域,在高校课程推荐中应用协同过滤推荐算法,可以有效地帮助学生用户了解课程相关信息,从而协助学生进行选课工作。推荐算法有关于高等教育还可以作用于高校的教学资源分配、教学质量评估等方面,对于高校教育和远程教育有重要意义。
