基于爬虫技术的网购信息获取与营销策略分析
2018-09-07胡晓青曹宇
文/胡晓青 曹宇
1.引言
孤立的数据,尽管是海量数据量也是没有任何意义的。利用Python进行网络爬虫,是通过既定规则,自动地抓取网页信息的计算机程序。爬虫的目地在于将目标网页数据下载至本地计算机,以便进行后续的数据分析。爬虫技术的兴起源于海量网络数据的可用性,通过爬虫技术,我们能够较为容易的获取网络数据,并通过对数据的分析,得出有价值的结论[1]。
2.Python开发环境及技术支持
2.1 Anaconda 下载以及Scrapy安装
在本项目的实现过程中,选择 Anaconda集成环境,Anaconda可以认为是Python的一个集成安装,平台安装完成后就默认搭建好了python、IPython、集成开发环境Spyder和众多的包和模块,非常智能化。由于开发工作将在Win7平台中进行,因此选用Anaconda进行各种Python扩展包的维护也是非常方便和高效的。
Anaconda安装完毕之后,以管理员身份进入Anaconda Prompt对平台进行扩展包的安装。此次开发过程中使用Scrapy爬虫框架进行数据爬取工作,因此在Anaconda Prompt中进行Scrapy的安装。
2.4 相关Python包简介
(1)requests介绍
Request是使用属性名来得到对应的属性值,并可以自动地把返回信息Unicode解码,Request可以自行保存返回内容,所以我们可以读取多次[2]。
发送请求
导入Requests模块
>>>import requests
获取网页
>>>content = requests.get(url).text
(2)JSON介绍
JSON(JavaScript Object Notation) 是一类轻量级的数据交换方法。采用完全独立于语言的文本格式,运用了和c语言家族相类似的习惯(包含C,C++,C#,JAVA,JavaScript,Python等)。JSON具有的这些特点成为很好的数据交换语言。
引用模块
>>>import json
编码
>>>json.dumps()把Python对象编码转换成json字符串
解码
>>>json.loads()把json格式的字符串解码转换成Python对象
(3)Scrapy介绍
Scrapy是一种基于Twisted,仅仅使用Python语言实现的爬虫框架,开发几个模块就能够比较方便快捷的实现一次爬虫,抓取网页中的有效信息用来分析。
Scrapy作为一个包,功能强大,是一个网络爬虫的架构,是Python开发的快速高层次的屏幕抓取框架,也可以用于自动化运维。在本次项目实施中,是一种最优的设计方案。
3.项目实施过程
本次项目中,我们使用Scrapy创建一个爬虫对象Item的相关类,对该类中各个静态变量进行定义。在通过requests模块对相应网页进行请求,获得网页对应的源码,对得到的源码格式进行整合,再通过json模块对整合好的源码进行分析,将分析结果逐个赋值给Item类中的静态变量。
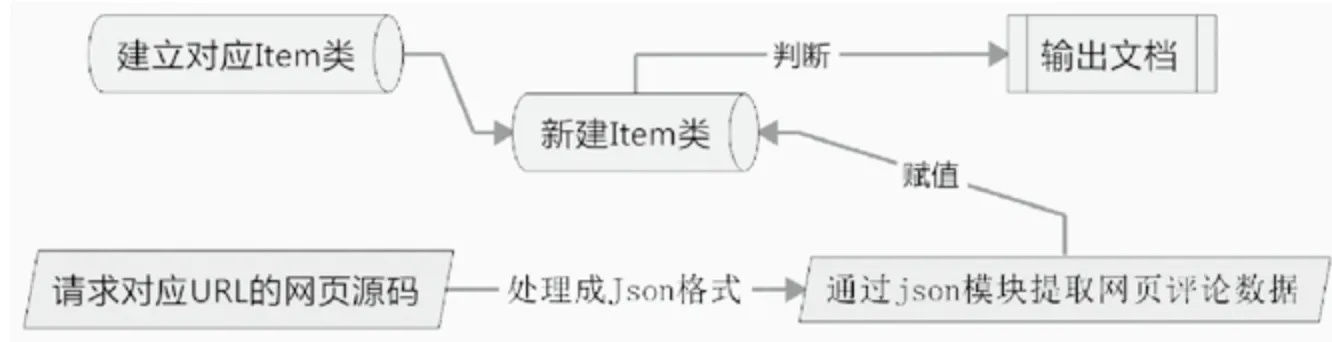
图1 项目整体实现流程图
以京东商城为例,需要先构建一个商品评论的Item类,Item类中包含了评论中所出现的必要信息,比如:买家ID、买家所在省份、评论具体内容、评论时间、打分等。建立好Item类之后,我们通过对该商品评论url的请求获取相应的网页源码,进行简单处理转换为json数据格式,通过json.loads模块进行解析,得到每条评论的具体相关内容,项目主要流程如图1所示。
3.1 选择合适的电商平台
考虑大型电商平台,在淘宝官网的用户评论区,没有发现很多与客户地理信息有关的数据,而且淘宝网站设计中有反爬虫程序,仅仅获取评论中最近99页的内容,因此在做地理信息相关的物流指导过程中,我们选择京东作为目标网站。
另外,在商品的购买人数方面,京东商品评论数能够达到6万+,数据量足够用来实验分析。本次实验结果可以为京东提供一些销售方案,实验数据真实准确,试验方法科学有效且具有可行性。
3.3 方案规划
3.3.1 项目节点问题分析
(1)找到爬虫的网页地址
确定对京东平台的商品信息进行爬虫,所以通过分析网站,得到URL的格式。
这是京东上vivox9手机的网址https://item.jd.com/10941037480.html对这个网址进一步分析得到评论区真正的网址如下:
http://sclub.jd.com/productpage/p-10941037480-s-0-t-3-p-1.html?callback=fetchJSON_comment98vv341
(2)关键代码分析
将爬虫程序中需要用到的模块导入,requests、json、scrapy。 sys是关于系统的模块,包含很多函数,本次程序中使用到reload(sys),重置系统,将系统编码设置为utf-8,sys.setdefaultencoding(‘utf-8’)。re是关于正则的模块,本次程序中使用re.findall()函数将以迭代方式返回匹配的字符串,使用re的一般步骤是先使用re.compile()函数编译成实例再使用findall()函数。time是关于时间的模块,本次程序中使用time.sleep()函数使程序暂停一段时间。threading是关于多线程的模块,本次程序中使用threading.Lock()函数创建锁。(见图2)


图2
爬取相关信息并对所获取的信息进行json文本处理,实例化一个commentItem,则可以得到每一个字段的值。本次实验中,由于需要分析商品在不同地区的购买情况所以过滤掉了userProvince为空的数据信息。
user_name和user_ID分别记录用户名和用户ID,只是为了记录一条数据。
userProvince记录用户所在省份,将来可以统计该商品在不同地区的销售情况,也可以对比不同商品在同一地区的销售情况,甚至可以指导京东仓储在各个地区的物流压力。
Content记录用户评价,对一种商品的全部评价将来可以进行分词,计算词频,就可以得到对本商品的词云。
Date记录用户创建评论的时间,将来可以分析某段时间内商品在不同地区的销售情况,也可以分析在某地区不同季度该商品的销售情况。(见图3)
Score记录用户评分,userlevelname记录用户等级,将来二者可以结合起来对该商品进行一个加权的评分,用户等级比较高的评分占比较重,这样对该商品的评分更客观。
Ismobile记录用户使用工具是手机还是电脑,如果是手机则为true,否则为false,将来可以分析不同地区网购时使用手机和电脑的占比情况。
write_comm()是一个自定义函数,作用是请求指定的URL,在这个URL中固定好商品ID,页码数,完成后写入指定文本中。URL是通过分析原网站得到的一个固定格式,格式中只有商品ID和页码可以改变,其余部分的格式不能改变。在这个函数中调用get_items()函数。将得到的所有内容存储在指定的文本文档中。(见图4)
这是程序的主函数,逻辑大致如下:首先固定好商品ID、开始页码、得到整个URL的格式,调用max_page()函
数分析评论页第一页得到最大页码数并赋值给page_max,设置开始页page_begin=0,京东评论页码起始页码从0开始。打开写入文件f_open,将来存储爬取的所有数据。在这个程序中,设置了多线程,爬取速度与带宽有关,为了加快速度,我们可以使用多线程来参与爬取。在开始页到最大页之中循环,调用write_comm()函数,使用多线程就可以快速获得所有的数据。
(3)数据处理
通过爬虫程序获得对应商品的文本数据,经过格式转换,提取各条评论对应的信息,再通过 Office Excel进行数据格式调整、处理分类、数据交集数量统计、绘制相应的图表。

图3

图4
4.数据挖掘和数据分析
Python基础教程、花式营养早餐、协和妈妈圈备孕书籍,这是三本看似没有联系的书籍。
《花式营养早餐》的数据,有效数据大概30000条。信息有效。
《Python基础教程》的数据,有效数据大约15000条。信息准确。
《育儿教程》的数据,有效数据大约12000条。信息准确。
做出折线图:(见图5)
本次项目中将三种数据的对比做成折线图,对数据进行对比分析:
(1)观察三种不同类别书籍的销售情况,可以看出,购买力前几名的城市都是北京、广东、江苏、上海等地,原因可能有几种。这些城市发展比较好,思想更加解放,对知识更加渴求。这些城市不管销售什么都不会太差。
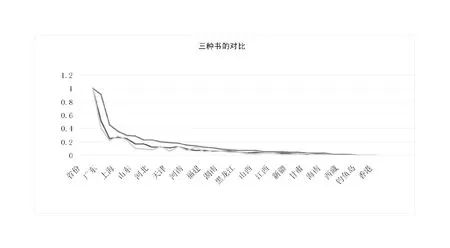
图5 三种不同类型书籍在全国各地区的销售量对比图
(2)对于菜谱类的书籍,可以看出,折线图的变化相对比较平缓,这类工具书很多省份的人都有需求,没有专业限制。但是对于Python这类的专业性书籍,在特定的地区需求量比较大,比如北京、上海、广东,这些城市计算机技术发展相对迅速,对新技术的学习人数多。但是通过折线图可以看出,折线图的走势直上直下,在山东、辽宁、河北等地销量一般,说明Python这一技术在这些地区并没有达到很高的发展,使用这门开发语言的人比较少。
(3)备孕类的书籍和Python类的书籍折线图走势基本相近,我们可以大胆推测,学习Python的人一般都是二三十岁的年轻人,这些人同样也需要备孕类和妈妈帮这类的书籍,所以这两类书籍在各个省份的销量基本一致。如果书店中销售Python等技术类书籍,那么店主不妨可以销售备孕类书籍。
5.总结
本次项目的结果,成功验证了不同种类书籍之间的关系,为以后的研究提供了思路。
不管是电子商务平台还是搜索引擎在相关方面的合理布局和优化规则,都需要研究人员利用海量数据找出不同事物之间千丝万缕的联系,本文使用Python开发程序,以京东商品为例,得出消费者的一些购物习惯,为商家提供了一种销售策略,为以后的研究作了铺垫。
