一种基于可信用户的服务QoS预测方法
2018-09-04武彩红王三虎徐乾
武彩红,王三虎,徐乾
(1.吕梁学院 计算机科学与技术系,山西 吕梁 033000;2.山西大学 计算机与信息技术学院,山西 太原 030006)
0 引言
面对日益增多的Web服务,在服务选择和组合时除了要满足功能方面的需求,还要满足服务QoS这些非功能方面的需求,如响应时间、吞吐量等,QoS驱动的Web服务选择和组合正受到越来越多的关注[1-4]。用户往往事先不知道候选Web服务的QoS值,因此对服务的QoS预测是很有必要的,准确的QoS预测可以为服务推荐、服务选择及服务组合提供可靠的数据支撑。协同过滤(Collaborative Filtering,CF)是服务选择和服务推荐[2]的有效方法之一,已经被广泛用于QoS预测中[3-4]。基于推荐的QoS预测,是通过用户调用服务所形成的历史记录,预测推荐未知的优质服务给用户。常用的协同过滤(Collaborative Filtering,CF)[5],包括基于用户的协同过滤(User-based CF)和基于项目的协同过滤(Item-based CF)[6],采用PCC(Pearson Correlation Coefficient,皮尔逊相关系数)、余弦相似性、调整余弦相似性计算相似度,然后基于相似邻居计算预测缺失的QoS值[7]。
Zheng等人提出WSRec[2]方法,首先通过计算用户之间或服务之间的相似度,然后选择出相似用户和相似服务,最后综合得出缺失QoS值的预测算法,是目前典型的使用协同过滤方法进行服务推荐的算法。Ma等人[8]分析了QoS数据的客观性,得出相似度越高的用户/服务,相似度越稳定的结论,基于高相似度的用户/服务提出了一种未知QoS值的高准确率的预测算法,提高了QoS预测的精确度,但未考虑不可信用户所提交的不真实数据带来的影响。Fan等人[9]提出了两个定义:异常数据和真正异常数据,通过识别并删除真正异常数据,再计算缺失QoS值,但没有从用户或服务的整体角度来考虑异常数据。Wu等人[10]采用两阶段K均值聚类方法预测QoS值,对每个服务的QoS值先进行第一阶段基于服务的聚类,得到用户不可信的索引集合,基于此再进行第二阶段基于用户的聚类,识别出不可信用户。王海艳等人[11]引入了服务推荐的个性属性特征,建立用户之间的信任关系,构建了信任模型,基于可信邻居形成联盟进行服务推荐。Wang等人[12]采用两阶段神经网络识别不可信的Web服务,设计了一个前馈神经网络模型构建QoS分类器,然后采用概率神经网络模型从每个分类识别不可靠的Web服务,但由于神经网络的复杂性,耗时较长。张鹏程等人[13]提出了一种基于多元时间序列的QoS预测方法,考虑多个 QoS 属性之间的关联,将QoS属性历史数据映射到一个动力系统中,再利用服务广告数据近似表示属性值的未来趋势,将历史数据和广告数据共同组成,实现多步长周期预测。
基于协同过滤[1,3]方法的关键问题是利用历史数据计算相似度,因此确保历史数据的可信性至关重要。这类方法在相似度计算时假定用户提供的QoS值是真实可信的,不存在异常用户的恶意欺骗。然而,实际应用中QoS数据可能有不真实的,如果不过滤这些异常数据,将会降低预测精度。因此,需要对用户整体角度进行评价,既识别出异常数据又避免了偶然性,过滤不可信用户,在此基础上基于可信用户的信息预测缺失QoS值。
1 问题描述
服务QoS值的预测对于Web服务的推荐,选择,组合[14]等有重要意义,若不考虑用户的数据是否真实可信,在选择邻居用户时误将不可信用户当作相似用户,影响了预测推荐的准确度,因此有效地识别并过滤不可信用户,才能确保预测推荐结果的准确度。
定义1:异常数据——在数据集合中,那些与QoS值的平均值有显著偏差的数据[9]。异常数据的出现可能是偶然的网络异常或者其他原因导致,有异常数据并不能说明某个用户是不可信的。对于一个用户,根据用户服务评价矩阵考量每一行数据,异常数据所占的比重越大,说明该用户评价的异常可能性越高,则该用户数据的不可信程度越高。
分析造成异常QoS值的原因可能有:1)由于客观原因,如突然的网络延时,服务自身的特征,用户客户端的性能等造成的过大或过小QoS值。2)用户主观上存在欺诈行为,由于经济利益,提交QoS值时可能故意抬高或诋毁某个服务[12]。
定义2:不可信用户(异常用户)——一个用户对于所有服务的QoS值中,异常数据所占的比重超过了一定的比值(阈值),则该用户视为异常用户,即不可信用户。
不可信用户对于服务的评价是不客观,不可信的,会极大地影响到相似度计算及QoS预测的,比如有些服务提供商伪装成用户,提供一系列正面评价以抬高自身的QoS评价,也有些竞争服务商伪装成用户,提供一系列负面评价以贬低其他服务的QoS评价。因此需要识别并过滤这些不可信用户,在剩余的可信用户集进行服务预测,这样排除了偶然性,同时提高了推荐精度。
2 TUSQP算法
TUSQP是通过识别并过滤不可信用户,然后基于可信用户进行协同过滤计算的方法。首先定义异常数据[9]如下:
|ri,j-mean(sj)|≥n*Std(sj)
(1)
式中:ri,j是用户ui调用服务sj的QoS属性值,mean(sj)是服务sj的期望,n是常系数,Std(sj)是服务sj的标准差,满足式(1)的QoS值即为异常数据。对于一个目标用户ui,若满足
(2)
则定义为不可信用户,其中N表示服务总数,α是阈值。
TUSQP算法采用基于用户和基于项目的CF方法,主要涉及四个方面:数据预处理、相似度计算、最近邻居选择和预测。
(1)数据预处理
对于服务集S中所有服务s,计算出均值和标准差,对于用户集U中每一个用户ui计算式(2),当满足式(2)时,yi=1,识别为不可信用户,不可信用户集合表示为UT={(ui,yi)|ui∈U,yi=1},否则,yi=0,为可信用户,可信用户集合表示为T={(ui,yi)|ui∈U,yi=0},显然UT∪T=U且UT∩T=Ø。
(2)相似度计算
相似度的计算是筛选相似用户的前提,不可信用户的数据对于其他用户不具有参考价值,会降低准确率,因此过滤不可信用户后,使用改进的PCC计算两个用户的相似度。
(3)
其中:
(4)
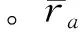
两个服务的改进PCC相似度:
(5)
其中:
(6)
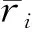
(3)最近邻居选择
根据相似度结果排序,筛选有效的最近邻居,相似度低的邻居可能会降低预测的准确度,因此PCC值小于等于0的都将不予考虑,选择Top-K作为相似邻居。
用户u的相似邻居集定义为:
N(u)={ua|sim′(ua,u)>0,ua≠u,ua∈TopK(u)}
(7)
服务i的相似邻居集定义为:
N(i)={ik|sim′(ik,i)>0,ik≠i,ik∈TopK(i)}
(8)
其中,TopK(u)是用户u的前k个邻居用户集合,由于在计算PCC时已过滤不可信用户,因此TopK(u)中的用户全部都是可信用户,TopK(i)是服务i的前k个邻居服务集合。
(4)预测
综合基于用户和基于服务的相似邻居进行预测:
(9)
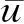
当N(u)∪N(i)=Ø时,意味着对于缺失值ru,i既没有相似用户,也没有相似服务。这时,本文采用均进行值预测:
(10)
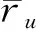
TUSQP算法的主要步骤总结如下:

算法1 TUSQP算法
3 实验结果与分析
3.1 数据集
本文使用公开的WSDream[15]数据集Dataset1进行测试,该数据集描述了真实世界中来自不同国家的339个用户调用5 825个Web服务的QoS数据,包括两个QoS矩阵:响应时间(rtMatrix)和吞吐量(tpMatrix)。两个矩阵皆为339行×5 825列的用户-服务矩阵,其中存在着很多-1值,代表着未调用访问超时等,这些-1值由于不存在真实值,故不会被预测。
实验中随机将数据集分为两部分,分别用于训练和测试。由于实际应用中,数据通常是非常稀疏的,而WSDream测试数据集是非常稠密的,因此首先需要随机删除一定数量的值,形成不同的稀疏密度。
3.2 评价指标
本文使用的评价指标是平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE),用于评估推荐算法的准确度。它们分别定义如下:
(11)
(12)
其中P(ru,i)是用户u调用服务i的预测值,ru,i是用户u调用服务i的真实值,N为需要预测的QoS的总个数。一般MAE与RMSE越小,表示预测的准确度越高。
3.3 实验结果
为验证本文提出TUSQP方法的有效性,将其与UPCC(user-based collaborative filtering method using PCC,基于用户的PCC协同过滤),IPCC(item-based collaborative filtering method using PCC,基于项目的PCC协同过滤),WSRec[2]三种方法进行对比。与文献[16]类似,百分之p的用户被随机选为不可信用户,他们的值被替换为随机产生的值,随机值范围在对应QoS的最小值和最大值区间内。分析得知响应时间的替换随机值范围是[0.001,19.999],吞吐量的替换随机值范围是[0.004,1000]。
(1)不可信用户比例p对算法的影响
实验将p从1%增加到5%,步长为1%,矩阵密度为10%,K=10,n=10,α=0.05,λ的取值从0到1,步长为0.1,取误差最小的为每一次运行的结果。实验重复10次,每次生成不同的不可信用户,结果取平均值。
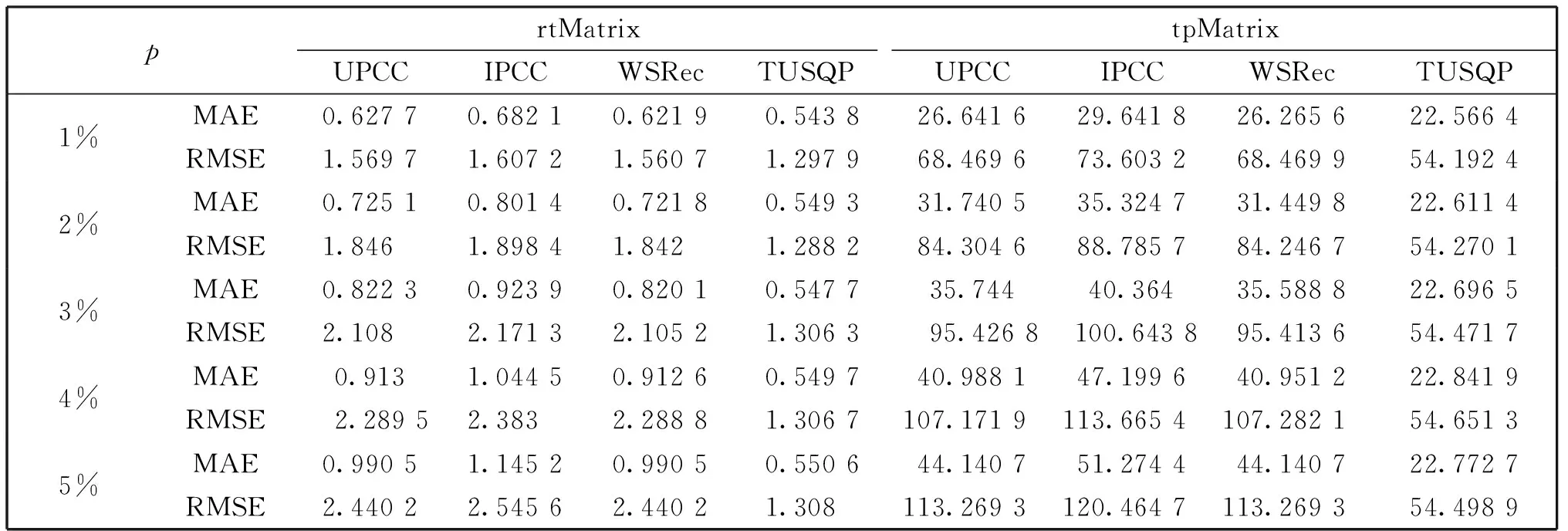
表1 准确度比较
通过表1可以看出,TUSQP方法在两个数据集上相比其他方法,在预测的准确度上都有明显提高。随着不可信用户比例p从1%增加到5%,其他三种方法的MAE和RMSE都有明显增加,预测准确度随之降低。由于其他方法未检测不可信用户,异常数据对相似度计算造成干扰,降低了预测准确度。TUSQP方法检测并过滤了不可信用户,|UT|(不可信用户个数)越多,该方法提升的效果越明显。在p取不同值情况下,矩阵密度不变,TUSQP方法在响应时间数据集上的MAE在0.54-0.55之间,RMSE在1.28-1.31之间,在吞吐量数据集上的MAE在22.5-22.8之间,RMSE在54.1-54.5之间,MAE和RMSE保持相对稳定,对于恶意用户的抵御有较好的鲁棒性。
(2)矩阵密度对算法的影响
本实验对比不同矩阵密度对算法的影响,矩阵密度从5%到50%,步长为5%,不可信用户比例p=3%,K=10,n=10,α=0.05,λ的取值从0到1,步长为0.1,取误差最小的为每一次运行的结果。实验重复10次,生成10次不同的不可信用户,结果取平均值,实验结果如图1所示。
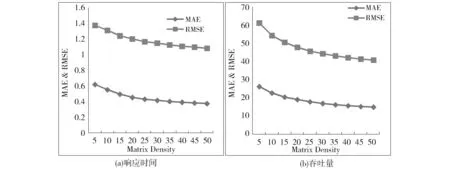
Fig.1 Impact of matrix density图1 矩阵密度对算法的影响
从图1可以看出,矩阵密度越大,MAE和RMSE越小,预测准确度越高。矩阵越稀疏,不可信用户对预测准确度的影响越大。很多实际应用中矩阵都是非常稀疏的,若不检测异常数据识别不可信用户,将会导致预测效果变差,这也说明,识别并过滤不可信用户的必要性。
(3)常系数n对算法的影响
本节对常系数n的取值进行实验,设置两组实验,K=10,α=0.05。第一组实验设置矩阵密度=20%,不可信用户比例p=5%,第二组实验设置矩阵密度=10%,不可信用户比例p=3%。对于响应时间和吞吐量得到MAE和RMSE如下图2所示。
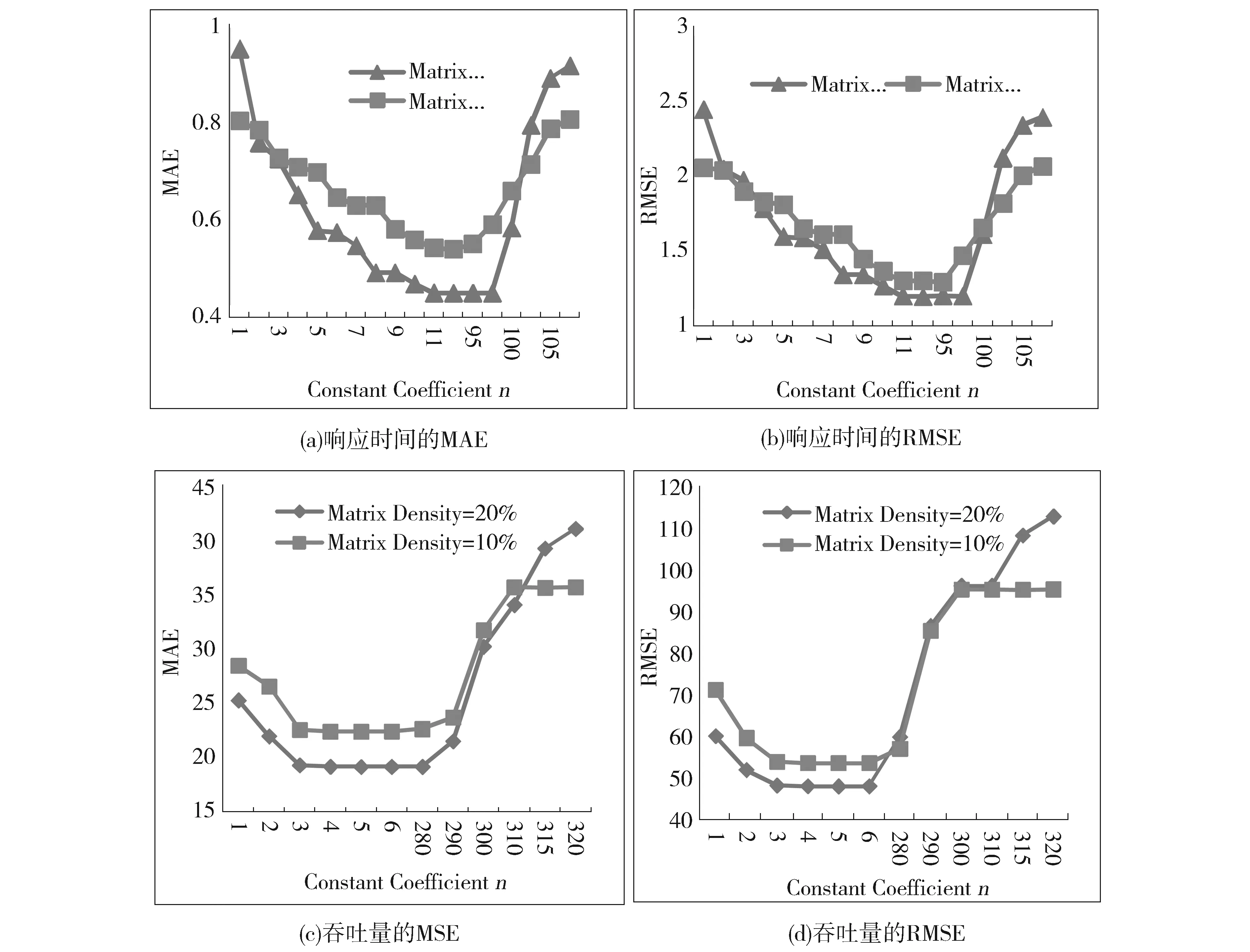
Fig.2 Impact of constant n图2 常系数n对算法的影响
从图2可看出,两个不同的QoS属性,随着n的取值从小到大,MAE和RMSE曲线图可以分为三个阶段:先由大变小,保持平缓,再由小变大。对于响应时间,随着常系数n由1到10,预测误差值在减小;当n在区间[10,90]之间时,误差值趋于稳定,预测准确度达到最优;当n超过100时,预测误差随之增大。对于吞吐量,也有相似的规律曲线,与响应时间不同的是,当n在区间[6,280]之间时,误差值趋于稳定,预测准确度达到最优。不同的QoS属性,n的最优取值不同。
造成误差值变化的原因是不可信用户的识别是否准确,当n取值较小时,符合式(1)的数据增多,会存在很多将正常用户误识别为不可信用户的情况,识别出的|UT|越多,导致矩阵越稀疏,降低了预测准确度。当n取值很大时,符合式(1)的数据减少,识别出的|UT|越少,部分不可信用户未被准确识别出,那些异常数据也被用于相似度计算和预测,造成了误差的增大。这些实验结果表明:当n的取值在合理的范围内时可以达到准确度最高。
4 结论
本文提出了基于可信用户的服务QoS预测方法TUSQP,首先分析异常数据,根据异常数据比例识别出不可信用户,然后基于可信用户的协同过滤方法预测缺失的QoS值。在数据集WSDream上的实验,验证了该方法提高了预测准确度,特别是在不可信用户增多时表现出更好的性能。由于Web服务中的服务和用户都在不断增长,使得服务预测、选择面临更多的挑战,未来将结合人工智能方法以自动识别不可信用户,进行服务选择与组合。
