数据挖掘技术在卒中相关研究中的应用
2018-08-29娜迪热艾孜热提艾力刘煜敏
娜迪热·艾孜热提艾力,刘煜敏
目前全球卒中疾病负担呈显著增长趋势,中国卒中死亡率和疾病负担居全球之首[1]。卒中相关临床数据分析可以更加明确卒中流行病学特点,提出诊断及分型依据,评估疗效和预后,为卒中防治提供更为准确的证据和方向[2]。随着信息技术的发展和医院信息系统的改善,各大医院积累了大量卒中住院患者临床数据,如何有效地利用这些珍贵的数据已成为国内外的研究热点。数据挖掘方法作为智能时代的产物,可以高效处理大规模、高维度的数据,不仅有利于发现更多新的潜在危险因素,还能建立疾病预测模型,指导卒中防治。本文将介绍利用数据挖掘技术分析临床数据的基本步骤,以及数据挖掘技术在卒中相关研究中的应用。
1 数据挖掘技术基本步骤
数据挖掘是指利用机器学习的方法发现数据中隐藏的规律,以及从数据中抽取知识。为了发挥数据挖掘方法的优势,需要有大量高质量的数据。为了利用数据挖掘技术深入研究卒中,国内外创建了专业数据库,比如国内有中国国家卒中数据库,国外以美国国家卒中研究所数据库为代表。研究人员利用这些数据库研究并发表了有关卒中疗效、并发症以及危险因素的论文[3-4]。这些数据库和医院信息系统为卒中数据分析提供了数据来源。利用数据挖掘技术分析卒中数据的基本步骤如图1所示。
1.1 卒中临床数据收集和预处理 根据研究主题从数据库或者医院信息系统中选出需要分析的卒中相关临床数据,构建实验数据集。
临床数据中含有大量的缺失值、不规范值以及噪音。如果数据来源不同,则需要进行格式转换,统一数据的格式。其中最严重的问题在于存在缺失值,临床数据涉及到个人隐私,无法收集所有数据,或者在录入数据时漏记或者录入错误等都有可能产生缺失值。文献[5]在处理缺失值时,针对不同类型的特征采用不同的统计量对缺失值进行填充。对于数值型特征,利用特征的平均值填充;对于有序名义值,利用特征的中位数填充;对于无序名义值,利用特征的众数填充。该文献还提出利用线性回归的方法来填充缺失值,该方法将缺失值作为目标,其余的因素作为特征,构建一个线性回归模型,将模型的预测值作为缺失值的替代值。缺失值处理方法的合理性可通过最终模型的预测性能来评价,也可以通过均方根误差(root mean square deviation)、平均绝对离差(mean absolute deviation)、偏差(bias)等统计量来评价。Xiang Li等[6]用数据挖掘技术分析中国心房颤动登记数据库中数据,建立了心房颤动患者2年内卒中风险预测模型。该文献处理缺失值时,首先删除缺失值过多的特征,如二元特征的缺失值超过80%,多元特征的缺失值超过60%时,将这些特征全部删除。

图1 数据挖掘的基本步骤图
数据预处理另一个重要步骤是将非数值数据转化为数值数据,文献[7]制订了统一的转换规则,将同一种疾病或者相同治疗方法的不同名称转化成统一的名称,进而转化为方便分析的数值代码。
1.2 特征选择及相关因素分析 数据库或者医院信息系统中往往包含患者的基本信息、病史、治疗方案等众多信息,若在分析时将全部数据纳入实验中,不仅会造成信息冗余,还会减慢模型的训练速度,降低模型的性能,提高对硬件的要求。因此,需要从所有的数据中选出对目标影响最大的数据,即需要进行特征选择。
特征选择一般有两种方法,即利用专家经验的人工选择方法和机器自动选择方法。人工选择方法会提高预测模型的敏感度,而机器自动选择方法会提高模型的准确率[8]。人工选择方法的缺点是严重依赖专家的经验和能力,而机器自动选择方法的缺点是依赖训练数据和测试数据的划分,不同的划分方法可以得到不同的结果。不过,该问题可以通过加大数据的规模来解决。机器自动选择方法的最大优点是不依赖专家知识,不仅可以自动识别重要的特征,还能发现专家仍未发现的潜在的因素。因此,数据挖掘方法中往往使用机器自动选择方法,专家知识可以用于验证机器自动选择方法选出的特征。
特征选择算法分3种[9],分别为过滤式、包裹式、嵌入式。过滤式特征选择方法通过一个特征重要性的函数对每一个特征进行打分,按照分数将特征进行排序,选择重要的特征,常见的评价特征重要性的函数有CHI、信息增益(information gain)、t-test、基于相关性的特征选择方法等。过滤式特征选择方法的优点是跟模型无关,计算复杂度比较低,能够处理大规模的数据,适用范围最广,缺点是忽略特征之间的关系,也忽略特征与预测模型之间的关系。包裹式特征选择方法将模型的预测性能当作评价特征重要性的函数,从而选出最重要的特征子集。嵌入式特征选择方法将特征选择与模型的训练结合在一起。
特征选择方法选出的特征均为对目标结果相关性最大的特征,因此选出的特征子集就是跟目标结果相关性最大的因素。特征选择不仅是模型预测的子过程,还能用于相关因素分析中。相关因素分析是模型预测的附带结果。
1.3 预测模型的构建及评价1.3.1 预测模型的构建 将纳入研究的全部数据集的80%作为训练数据,剩余数据作为测试数据,利用特征选择算法从训练数据集中选出重要特征(相关因素),然后在此特征集中利用数据挖掘的分类算法训练出模型,常见的预测模型有决策树(decision tree)模型、随机森林(random forest)模型、朴素贝叶斯(naïve bayes)模型、k最近邻(k-nearest neighbor)模型、逻辑回归(logistic regression)模型、支持向量机(support vector machine)模型、人工神经网络(artificial neural network)模型等。各模型需要调节的参数、优缺点以及在卒中数据分析中的应用见表1。
决策树模型指的是根据训练数据集利用决策树算法构建出的树状结构的决策模型[10]。决策树根据生成方式的不同有以下的几种算法:ID3、C4.5以及CART,其中CART既可以用于分类,又可以用于回归。而随机森林算法通过训练多个决策树并且在数据采样中加入一定的随机性有效地避免了过拟合现象,因此在随机森林模型的误差率往往比决策树低[11]。
朴素贝叶斯模型指的是根据贝叶斯公式和独立性假设将后验概率转化为前验概率的模型。该模型计算目标特征每一个值的概率,并将概率最大的值作为该目标特征的最终结果[12]。K最近邻模型通过一个数据点周围最近的K个邻居来确定数据点的类型,因此K值的确定很重要。逻辑回归模型在线性回归的基础上使用Sigmoid函数将数据分成两个部分。支持向量机模型改善了逻辑回归模型,因此准确率比大部分数据挖掘模型都高,而且适用范围最广。人工神经网络模型是根据人脑的特点设计的,是目前最流行的深度学习方法。人脑中成千上万个神经元相互连接生成一个很复杂的网络结构实现认知。神经网络模型中激活函数类似于神经元,激活函数之间的输入输出关系类似于神经元之间的连接关系,数据类似于神经元之间的电信号。
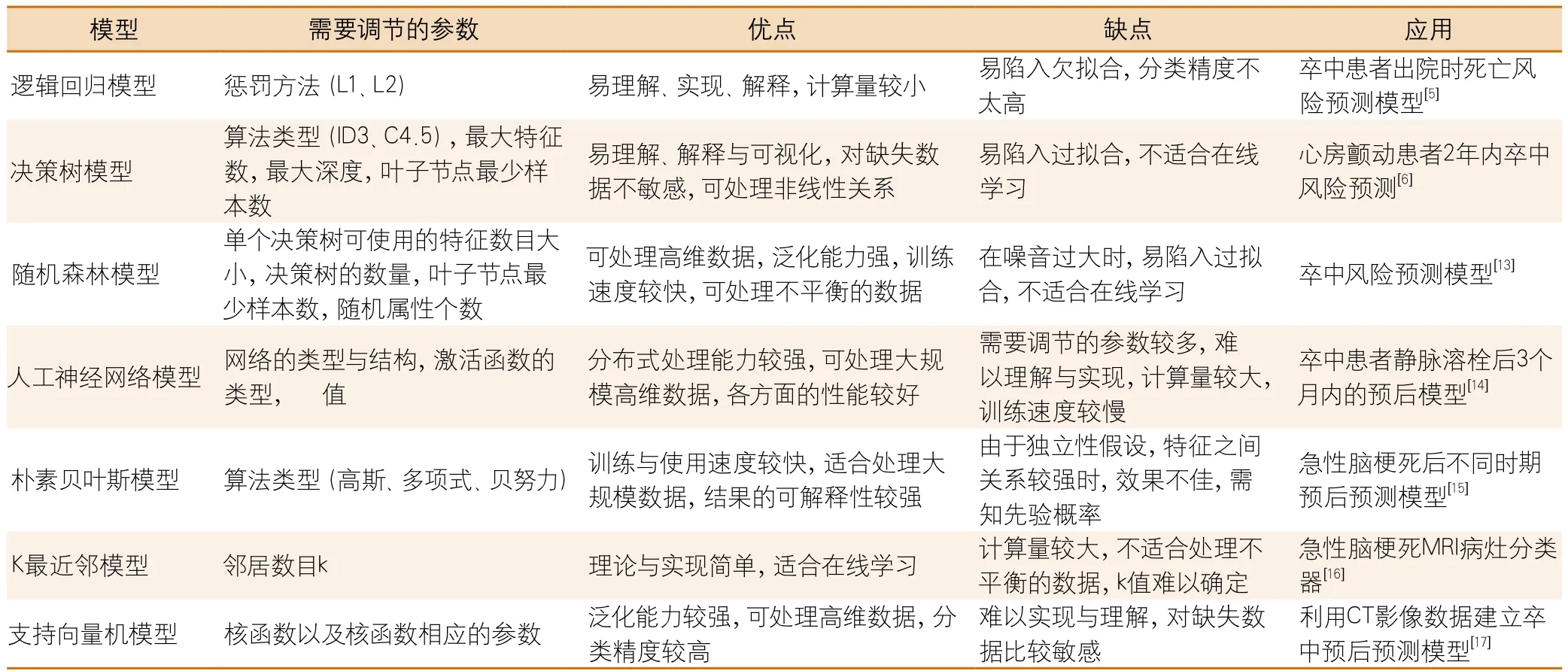
表1 常用预测模型
1.3.2 模型性能的评价 一般的数据挖掘任务中直接使用准确率或者错误率作为模型预测性能的评价,但卒中临床数据分析中,数据的分布往往是不平衡的,准确率无法全面地评价模型的性能,因此需要使用敏感度、特异度、受试者工作特征(receiver operating characteristic,ROC)曲线下面积(area under curve,AUC)值等评价指标。实验结果的分布见表2。
敏感度(真阳性率)=真阳性(TP)/真阳性(TP)+假阴性(FN)
特异度=真阴性(TN)/真阴性(TN)+假阳性(FP)
假阳性率=假阳性(FP)/假阳性(FP)+真阴性(TN)
AUC指的是ROC曲线(横坐标为假阳性率,纵坐标为真阳性率的曲线)下的面积,一般情况下0.5<AUC<1。AUC值越大表示模型的预测性能越好。
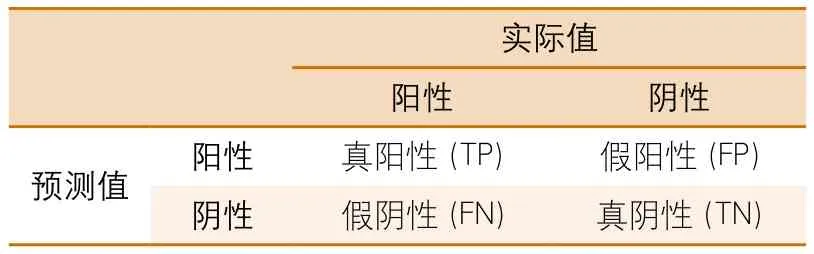
表2 结果分布表
2 数据挖掘在卒中相关研究中的应用举例
目前大多数卒中相关临床性研究中,对医院信息系统的利用仅仅在于最基本的数据储存、录用等层面。本文将介绍如何高效地利用医院信息系统或卒中数据库中的海量信息资源为卒中预防、诊断、评估疗效及判断预后提供更科学的依据。
2.1 卒中危险因素研究中的应用 卒中危险因素分析是卒中预防很重要的一部分。探索卒中危险因素、建立卒中发病风险预测模型可以及时筛选高危患者,进行卒中预防。前文介绍数据挖掘基本步骤时提到,数据挖掘技术中特征选择方法可以用于相关因素分析,因此这种方法也可用于卒中危险因素研究。有研究者利用特征选择选出了16种卒中相关因素,同时使用支持向量机、逻辑回归等方法建立了卒中风险预测模型,并且通过准确度、敏感度、特意度、AUC等指标评价了各种模型的性能,认为此类问题中支持向量机模型的预测性能最佳[17]。
2.2 卒中患者病情严重程度评估研究中的应用 数据挖掘技术可用于卒中患者病情严重程度预测,对卒中重症治疗给予一定的提示,也能用于根据病情严重程度自动计算报销额度,对医保费用管理也有积极作用。有研究使用数据挖掘技术分析社会医疗保险数据库中急性缺血性卒中患者信息,发现了影响卒中患者病情严重程度的7种影响因素,并以这7种因素作为特征,建立病情严重程度预测模型[18]。
2.3 卒中疗效评估方面应用 通过分析“是否接受某项治疗”这一特征与结果事件的关联,巧妙利用数据挖掘技术进行疗效评估,还可以建立接受某项治疗的患者预后预测模型。Yuling Yang等[19]将牛津郡社区卒中数据库分类系统用于评价卒中患者静脉溶栓治疗安全性和有效性。Matthew McNabb等[20]利用数据挖掘技术预测接受介入取栓术的急性脑梗死患者90 d内预后,介绍了这种新的方法在卒中疗效评估中的应用。
2.4 卒中预后影响因素研究中的应用 探讨卒中患者预后影响因素是卒中诊治的重要部分,尤其在大面积脑梗死等重症患者中提前预测卒中预后获益颇大。Jonathan F. Easton等[15]用数据挖掘技术分析急性脑梗死后不同时期预后影响因素,分别从用药种类、既往病史、卒中亚分型、卒中量表得分及住院期间化验结果等方面选出了与结果相关性最高的因素,并分别建立了卒中后短期(7 d内)、中期(8~93 d)的预后预测模型。文献[21]中研究者从国家级疾病数据库中获取卒中患者(19 603例)信息,用决策树C4.5算法建立了卒中后运动障碍预测模型,并用特征选择方法从397种潜在影响因素中选出了70种与卒中后运动障碍关系最明显的因素,显然这种从大量患者信息中寻找潜在关联因素的方法可以为后期研究提供新方向。
2.5 研究卒中疾病负担方面的应用 卒中不仅损害患者身体健康,降低生存质量,也为患者家庭带来巨额的治疗费用和长期护理方面的负担。我国研究者利用神经网络技术建立脑梗死患者住院费用拟合模型,在此基础上进行影响因素敏感度分析发现住院天数对费用影响最大,其次为“治疗结果”“是否抢救”“年龄”等因素[22]。
2.6 卒中病因分型研究中的应用 卒中病因分型涉及到患者治疗及二级预防方案的制定,因此准确地进行卒中病因诊断、确定分型很重要,但临床上卒中老年患者多种疾病共存的情况对确定卒中病因分型造成困扰。数据挖掘中分类算法可以用于卒中病因分型,国外已有此类尝试。文献[23]介绍了韩国学者分析多中心卒中数据库中急性脑梗死患者(6624例)信息后,建立基于磁共振成像的卒中病因分型系统,作者认为此分型系统有望用于卒中临床诊断。作为最新的疾病诊断形式,这类研究成果用于临床仍需更多研究人员进行探索。
【点睛】本文阐述数据挖掘在卒中相关研究中的应用,为卒中临床研究提供一种全新的数据分析技术。
