基于模糊聚类的云计算集群资源调度算法
2018-08-17周丽娟
周丽娟
山西财经大学实验教学中心,山西 太原 030006
云计算(cloud computing)作为一种将计算资源作为服务并通过网络并提供给用户的计算模式,使得用户可以通过按需使用计算资源,这些资源主要包括数据、软件、硬件和带宽。云计算通过提供软件即服务、平台即服务和基础设施即服务这三类服务来为用户作业提供解决方案。云计算中的资源具有地理分散、资源异构和动态变化等特征。
云计算是在网格计算的基础上发展而来,其主要特征是通过引入虚拟化计算,使得云计算环境下的资源调度不同于网格计算,但其目标往往是最小化最大完工时间,并通过启发式算法来寻求实现资源最优分配。
美国国家标准技术院将云计算定义为:云计算是一种通过网络并使得用户可以按需来共享的一个可配置的资源池,该资源池能在仅需较少管理开销和交互的情况下,对资源进行快速配置和释放,云计算模式的5个基本特征为:按需自助服务、网络的广泛访问和共享资源池以及快速的弹性能力。
资源调度是云计算的一个核心问题,直接关系到云计算服务的稳定性、资源的使用效率和用户满意程度。云计算的资源调度问题的研究从理论技术本身上来说具有非常重要的意义[1-3]。
文献[4]针对云计算领域的任务调度问题,提出了一种基于人工免疫的云计算平台动态任务调度算法,通过排队论粗略确定保持云平台稳定的条件,为后面的计算提供基础数据,然后利用免疫理论中的免疫克隆算法来为不同节点分配资源实现最优配置,实现负载平衡处理。为了提高传统资源调度算法的资源利用率,文献[5]提出了一种云计算环境下的资源调度模型,该资源调度模型基于人工蜂群算法进行调度方案优化。文献[6]分析讨论了1组Directed acyclic graph(DAG)共享云计算资源调度[7-8]中的多DAG数量、属性结构分布特点和资源需求量关系,提出了一种基于资源需求强度预测变异方法的进化算法(evolutional algorithm based on the forecasting of resource demand,EFRD)。文献[9]研究了云端资源的管理和调度,从服务商需求角度出发来构建云资源调度方法,能在不损害用户和生产商利益的前提下实现收益平衡。
上述工作研究了云计算任务调度,具有重要的意义,本文提出了一种基于模糊聚类的云资源调度方法,在对云计算异构资源进行模糊聚类的基础上,实现资源的动态调度,并通过实验证明了文中方法的有效性。
1 资源调度目标函数
本文的云计算资源调度模型采用Map-Reduce编程/资源调度模型[10-14],如图1所示。
从图1可以看出,云计算每个单元包含2个节点:主控节点Jobtracker和从节点Task Tracker,主控节点负责任务的资源分配、调度以及失败任务的跟踪,从节点主要负责任务的执行。
TaskTracker从节点可以形式化的表示为G(V,E),其中V表示其所属主控节点所能管理的所有节点构成的集合,而E是对应的边集。因此,这些节点可以执行一系列任务。
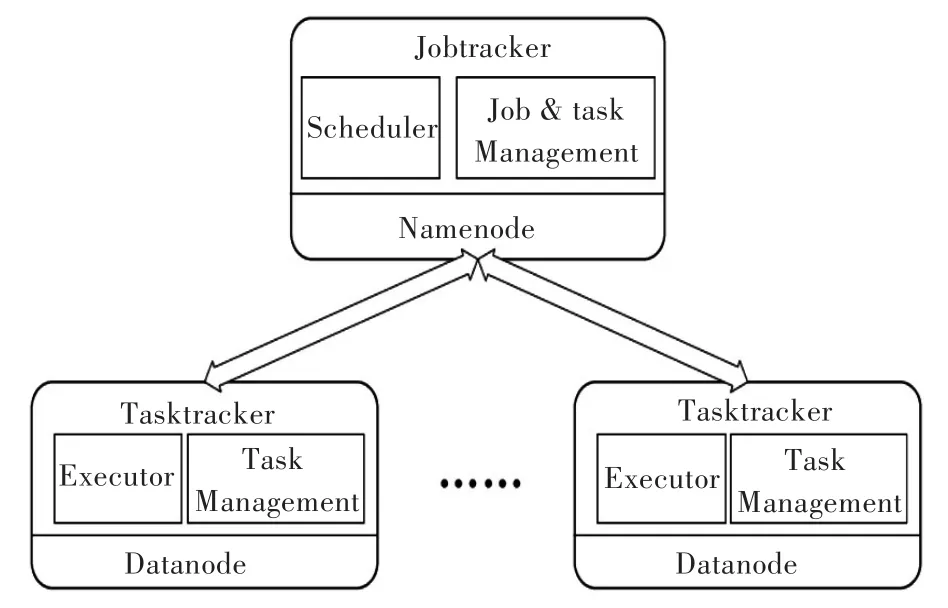
图1 Map-Reduce编程/任务调度模型Fig.1 Program/task scheduling model of map-reduce
本文的主要工作就是采用模糊聚类算法选择最合适分配给节点的资源进行分配。
资源分配过程中考虑的性能指标主要包括:预计执行时间T(r)、网络带宽B(r)和网络延迟D(r)。
1)T(r):任务ti在处理节点tnj执行的最早完成时间,可以表示为:
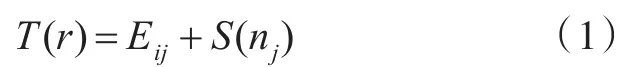
式(1)中,S(nj)为某任务在节点nj上可以执行的最早时间,Eij为在节点nj上执行某任务ti所需的执行时间。
2)B(r):表示路径r对应的网络带宽最大值。
3)D(r):路径r对应的网络延迟最大值。
因此,资源调度的目标函数为:
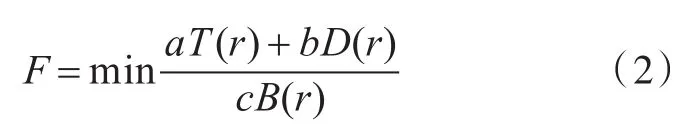
满足:

其中,a、b和c分别为预计执行时间T(r)、网络带宽B(r)和网络延迟D(r)的各自权重,TLT、ELT和DLT为对应的界限。
2 基于模糊聚类的资源调度算法
2.1 模糊聚类
模糊K-MEANS算法具有计算简单和聚类速度快的特点,是一种动态聚类算法,能通过不断最小化误差平方和来求取聚类,并求出每个数据样本点到聚类中心的隶属度,隶属度最高的聚类被定位样本点所属的分类,模糊K-MEANS算法需要确定最优聚类个数和初始聚类中心:聚类个数对于聚类精度具有较大的影响,由于初始阶段无法准确确定聚类个数,因此,通过随机确定聚类个数。
不同的初始聚类中心对聚类结果影响巨大,传统的K均值算法随机选取K个点作为初始聚类种子,并不断通过迭代直到聚类中心确定和算法收敛。
2.2 基于模糊K-MEANS资源分配算法
采用模糊聚类算法来对节点资源进行分配的原理可以表示为:
首先设定一个初始的聚类数K,最大聚类数Kmax,距离阀值为θd,当新节点被释放时,需对所有资源进行重新聚类,而当新任务到来时,首先需计算与其具有最小距离的聚类,将最小聚类对应的中心作为资源分配的节点。
选择具有最小距离的聚类中心作为任务被分配的资源节点。
当新节点被释放时,需要计算其与所有聚类中心的距离,如果其与所有聚类中心的距离均大于阀值θd,且聚类中心的数量尚未超过允许的最大数量时K≤Kmax时,增加一个新的聚类SK+1,并计算新的聚类中心。
当新任务到来时,则计算其与所有聚类中心的距离,选择具有最小距离的聚类作为其所属的聚类。
算法1基于改进模糊K-MEANS算法的资源分配算法可以描述为:
输入:所有节点集合和任务集合;
初始化:距离阀值为θd、聚类数K,聚类最大数量Kmax,初始化聚类集合S1,S2,...SK空集,初始化数据中心c1,c2,...,cK,当前迭代次数t=1。
步骤1:对聚类于新来的任务xi,计算其到每个节点聚类Sj的隶属度wij:
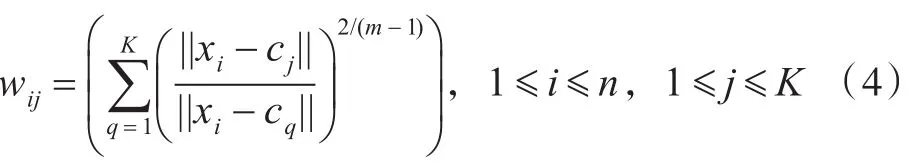
其中,||xik-cjk||表示节点资源xi到数据中心cj之间的欧几里得距离,当中心点的坐标与节点资源xi相同时,即 ||xi-cq|| =0 ,wij==1,否则wij0,且wij满足
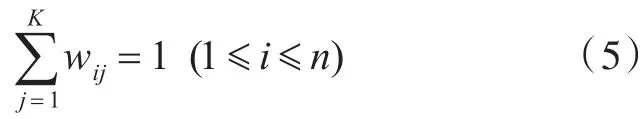
步骤2:对各个节点资源聚类Sj的中心c1,c2,...,cK进行更新:
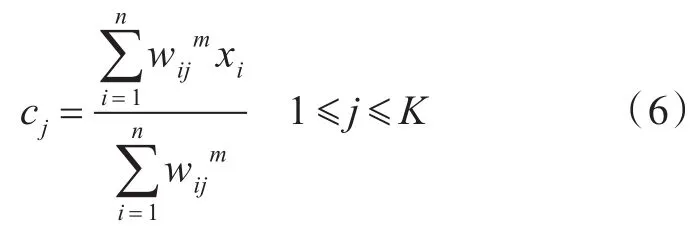
步骤3:计算各资源节点xi到所有聚类中心的距离的最小值J(W,C):
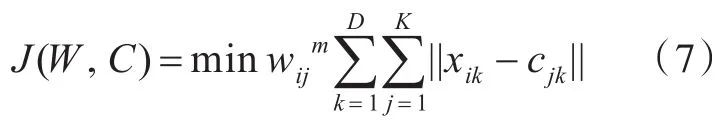
步骤4:对距离最小值J(W,C)进行判断。
如果其大于距离阀值θd,判断K≤Kmax是否成立:如果成立,则转入步骤5;否则,转入步骤6;
步骤5:将节点xi作为聚类中心,并重建新聚类,cK+1=xi,聚类SK={xi},并将聚类数K=K+1。
步骤6:查找任务应分配的节点,即计算J(W,C)对应的聚类,其使:

步骤7:对于具有最小J(W,C)的聚类Sj,对其聚类中心cj进行调整,得到新的聚类中心为:
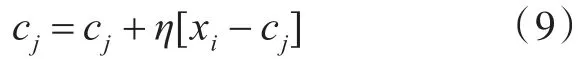
其中,η为学习率。
步骤8:判断算法已达到最大迭代次数。
如果达到,则算法结束;否则,判断任务与所有节点聚类中心的距离是否小于距离阈值:
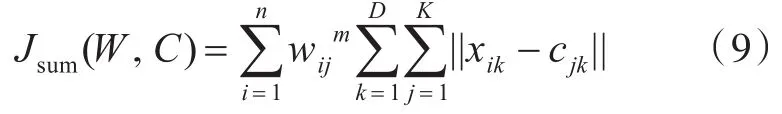
其中,n为样本总数。
当大于距离阈值时,需对节点进行重新聚类,增加聚类总数。
3 结果分析
在Cloudsim云计算仿真环境[15-17]下对文中所提的资源调度算法进行仿真和实验,并与文献[5]方法和文献[6]方法进行比较,文中方法的参数设置为:物理节点数量为100,CPU计算能力2000(MI·s-1),内存为8 GB,网络带宽为 150(MI·s-1),任务总数为1000个,任务个数与任务分配均为随机的。
3.1 负载均衡程度
采用负载均衡因子来作为性能比较指标,负载均衡因子可以定义为:
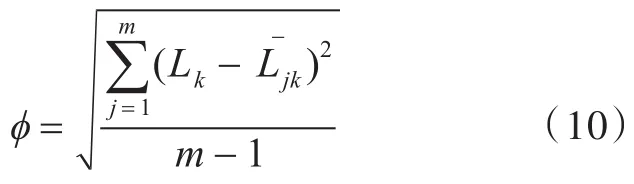
式(10)中,m为实验总次数,L为虚拟机r在某时
jj刻k的负载均衡值,为云计算数据中心在某时刻k的平均负载。
当实验次数为50时,运行文中方法与文献[5]和文献[6]方法进行比较,3种方法得到的负载均衡因子的比较如图2所示,在图2中可以发现,文中方法的负载均衡能力最强,文献[6]方法次之,而文献[5]方法的负载均衡能力较差,因为其负载均衡因子远远大于另外两种方法,且在仿真时间为400 s时,即仿真结束时仍没有收敛的趋势。而文中方法通过模糊聚类对所有节点进行动态重分配,并将任务分配给需求最匹配的节点,因此具有最好的负载均衡能力。
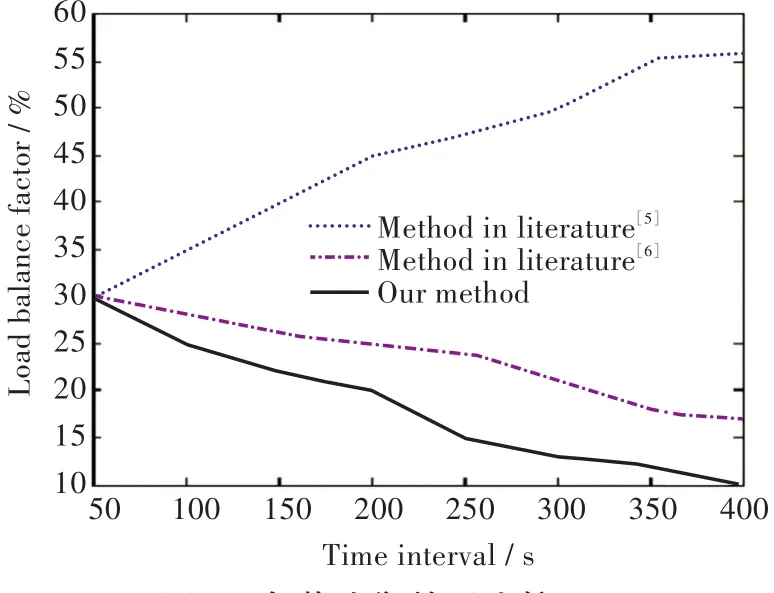
图2 负载均衡效果比较Fig.2 Comparisons of load balance effect
3.2 负载均衡效率
为了进一步对3种算法的负载均衡效率进行比较,在计算出所有的负载均衡因子后,可以计算得到负载均衡效率:
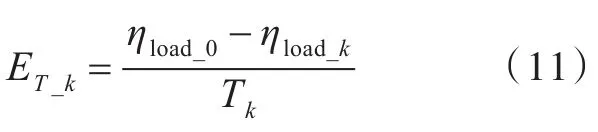
其中,ηload_0表示聚类中心的负载均衡值,从公式(11)可以看出,当ET_k的值越小时,对应算法的负载均衡效率越高。
3种算法的负载均衡效率的比较如图3所示。从图3可以看出,文中方法的负载均衡效率较高,文中方法得到的负载均衡效率的平均值分别为 0.0127,而文献[5]和文献[6]方法的值则分别为0.0416和0.0275,文中方法的负载均衡效率最高。
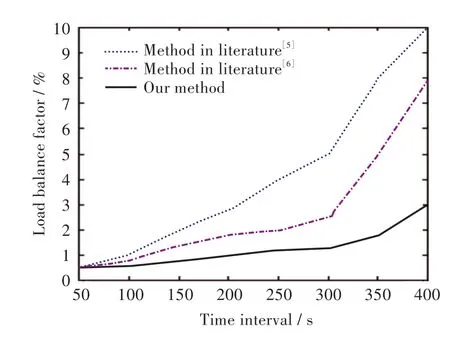
图3 负载均衡效率Fig.3 Comparisons of load balance effect
4 结 语
为了实现云环境下资源的高效调度,设计了一种基于模糊聚类的云计算集群资源调度方法。通过模糊聚类方法对所有资源节点进行聚类,当新任务到来时,自动计算其到各个聚类中心的距离,将具有最小聚类距离的聚类中心分配给该任务。在Cloudsim仿真工具下进行实验,结果表明了文中方法能有效实现节点负载均衡,与其他方法相比,具有较好的负载均衡程度和负载均衡效率,具有较强的应用前景。
