基于刻面与本体标识的语义Web服务发现方法
2018-08-17杜胜浩
杜胜浩,
(郑州大学 信息工程学院,郑州 450001)
0 概述
随着网络技术的不断发展,人们提出Web服务的概念,通过定义和建立一个Web服务界面就可以访问和共享计算资源或信息资源。Web服务可以使用标准协议来组合、发布和定位,以构建在一系列平台上运行的应用程序[1]。语义Web 服务依据本体概念对Web 服务进行语义标注,使服务信息能够被计算机理解并进行交互,从而实现服务的自动发现和处理。随着语义Web服务的增加,如何从规模不断扩大的服务注册库中发现所需服务是一个亟需解决的问题。文献[1]使用UML建模和术语扩展检索Web服务。文献[2]通过制定一个新的Web服务清晰度量表增强服务发现过程。文献[3]提出一种上下文服务发现方法,根据用户端绑定上下文来找出所需的服务。文献[4]基于本体的概念组之间的相关性度量模型分别评价服务请求与服务描述的语义匹配度,从而进行语义Web服务的发现。文献[5]对发布的空间信息服务进行聚类,计算服务请求与各服务簇中心的相似度,确定最优匹配簇为服务发现结果。文献[6]采用空间向量模型表示语义Web服务,对服务进行聚类,并基于带权二分图思想对服务进行匹配。从本质上讲,Web服务是一种轻量级的、松耦合的、与平台和语言无关的构件[7]。因此,对于服务注册库的管理与维护可以利用构件库技术来实现。大部分构件检索方法都使用刻面分类方法对构件进行描述和分类,如文献[8]采用刻面分类法对Web应用构件进行描述和检索。一方面,现在的Web服务发现方法大都通过服务质量 (Quality of Service,QoS)和功能来选择服务。即使具有相同输入和输出参数的Web服务的内部执行过程也会有很大不同,因此导致Web服务发现的准确率较低。另一方面,现有服务发现方法未将本体语言描述和服务聚类思想同时引入其设计思想中。本体语言使语义Web服务的描述更清晰,而且降低了计算复杂性、技术复杂性和概念复杂性。通过聚类形成服务簇,可以减少服务比较次数,优化服务发现过程。服务注册库中的很多服务能够完成相似的功能,具有比较近似的概念和语义信息,因此,可以对服务进行聚类。
本文使用Web服务本体语言(Ontology Web Language for Service,OWL-S)描述的语义Web 服务信息,基于本体库将语义Web服务转化为刻面描述树,用于实现服务聚类的预处理。
1 语义Web服务的描述和发现框架
1.1 语义Web服务描述
OWL-S是构建于Web本体语言(Web Ontology Language,OWL)之上用于描述Web服务的标记语言。OWL-S的Web服务描述模型可以描述语义Web服务,它对服务的基本描述包括服务的基本信息、功能信息和属性等。Web服务的管理与维护可以使用构件库技术实现,而对构件的描述和分类通常由刻面来完成。每个刻面都由一组基本的术语构成,这组术语称为术语空间[9]。因此,语义Web服务中也可由一个刻面集合对其进行描述。
定义1用一个三元组WS={WS_Name,WS_Description,WS_Facets}表示语义Web服务,其中,WS_Name是语义Web服务的标识名,即服务的名称,WS_Description是语义Web服务使用文本描述的基本信息,WS_Facets表示语义Web服务的刻面集。
定义2语义Web服务的刻面集由一组刻面术语的集合组成,每个刻面术语都用于进行本体标注。该服务集合中定义了具体的语义Web服务刻面,包括QoS刻面、功能刻面、参数刻面、应用刻面等。
使用本体标注的各个语义Web服务刻面包含不同的属性信息:
1)QoS刻面,即服务质量刻面,是用户在使用语义Web服务时涉及的体验信息,即用户对语义Web服务的可靠性、安全性、可用性等非功能性属性的期望信息。自QoS被引入到Web服务发现领域后,为Web服务发现研究人员提供了新的研究方向[10-11]。
2)功能刻面,包括语义Web服务的接口信息和调用方式等。
3)参数刻面,包括语义Web服务的输入参数集和输出参数集,分别由一组参数组成,每个参数都用于进行本体标注。
4)应用刻面,是在应用语义Web服务时,服务运行前置条件描述的环境状况和服务运行对相关资源对象产生的效果等。
提取语义Web服务的语义信息并进行本体标注,形成的语义Web服务刻面集包括4个主刻面和若干子刻面,可用图1所示的刻面树表示,根节点用一个虚拟节点表示。

图1 语义Web服务刻面集形成的刻面树
传统描述服务的方式通过一个四元组{Name,Description,Input,Output}来表示,其中,Name是服务的名称,Description表示Web服务的基本描述,Input和Output分别表示服务的输入参数和输出参数的集合。但是,这种表示方式对于具有相同输入和输出的服务不能很好地进行区分。本文采用多刻面和本体对Web服务进行语义描述,增加了QoS刻面和应用刻面的描述,加强了Web服务的语义约束,从而提高了Web服务发现的准确率。
1.2 语义Web服务发现框架
本文提出的语义Web服务发现框架如图2所示,其中,本体库为共享本体库,本文中所有语义Web服务刻面描述都是基于此本体库。在服务提供者提供的语义Web服务经过服务分析器处理并注册到服务注册库后,通过服务注册库中的服务聚类器对语义Web服务进行聚类,能够得到多个服务聚类簇,减少服务匹配器在进行服务匹配时的比较次数,从而提高服务发现的效率。
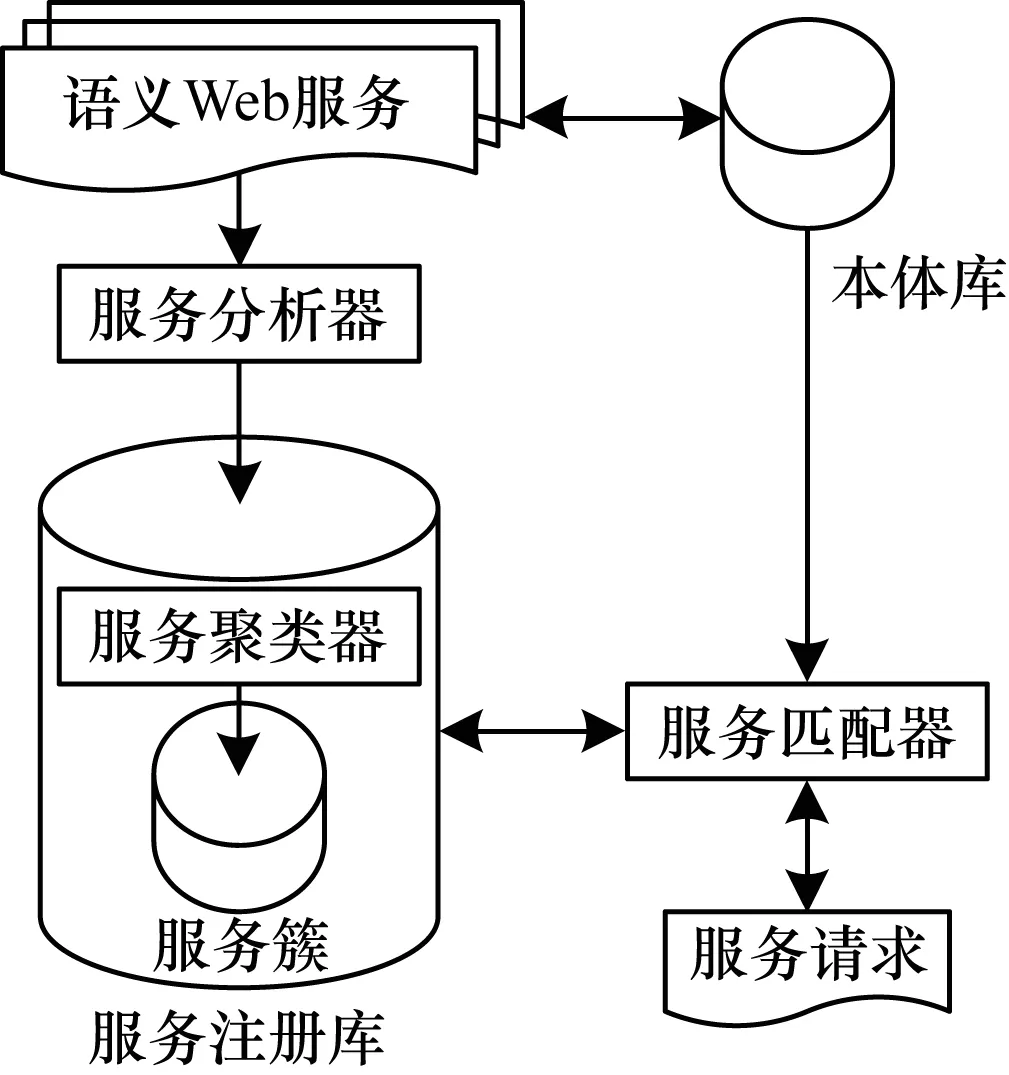
图2 语义Web服务发现框架
该语义Web服务发现框架主要包含3个组件:
1)服务分析器。根据服务提供者提供的语义Web服务的描述,提取语义信息并进行本体标注,进而将语义Web服务刻面集用一棵刻面树表示,为语义Web服务在服务注册库中的聚类提供数据。
2)服务聚类器。语义Web服务经过服务分析器处理后,基于刻面对语义Web服务进行本体语义相似度的聚类,属于同一类别的语义Web服务聚集到一个服务簇中,在每一个服务簇中都选取一个语义Web服务作为服务簇中心,这些服务簇存放在服务注册库中。
3)服务匹配器。对服务请求者的服务请求信息进行分析并依据本体库进行本体标注,依次计算请求服务与服务注册库中每个服务簇中心的相似度,取相似度最大的服务簇作为服务发现集合,然后计算请求服务与集合中的语义Web服务的相似度,将满足阈值要求的服务集合输出给服务请求者。
1.3 刻面的动态更新
随着Web服务的更新和扩展,语义Web服务的功能性和非功能性属性可能发生改变,对应的刻面值也要动态地更新。在服务提供者提供Web服务时,如果发现Web服务刻面集中没有对某一刻面的刻画,则服务提供者可以在已有Web服务刻面集的基础上定义新的刻面和对应的属性值,并添加到语义Web服务刻面集中。如果语义Web服务刻面集中某一刻面的描述错误或冗余,服务提供者可以将其修改或删除。以上语义Web服务刻面更新必须满足刻面的描述规约,否则更新无效。
以QoS主刻面下子刻面的更新为例,在刻面描述中已有服务的可靠性、安全性和可用性,服务提供者发现没有对服务响应时间的刻画,于是服务提供者可根据刻面描述规约添加服务响应时间刻面到QoS主刻面下,扩展语义Web服务刻面集,同时更新刻面树,实现刻面的动态更新。
2 语义Web服务聚类
2.1 本体概念语义相似度
本体作为Web核心支撑技术之一[12],它是一个概念框架,用来对领域知识概念进行抽象和描述,形成领域术语,然后对概念进行标识,通过定义概念以及概念与概念之间的关系来描述语义信息[13-14]。本体可表示成一棵有向树,例如Food本体有向树的部分信息如图3所示,树中每个节点表示一个概念。
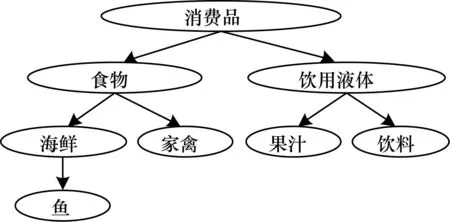
图3 Food本体有向树部分信息示例
本文使用文献[15]中的定义来计算本体距离,设有2个概念C1和C2,则这2个概念的本体距离Dis(C1,C2)为本体有向树中连接它们的最短路径的边数。例如在图3中,概念海鲜(Seafood)和概念果汁(Juice)之间的本体距离Dis(Seafood,Juice)=4。于是,2个本体概念的语义相似度可基于这种本体距离来计算,计算公式为:
其中,Sim(C1,C2)表示概念C1和概念C2的语义相似度,Dismax表示本体有向树中所有概念的本体距离最大值,Dismin表示本体有向树中所有概念的本体距离最小值,Dis(C1,C2)表示概念C1和概念C2的本体距离。
2.2 服务聚类
从使用OWL-S描述的语义Web服务中提取语义信息并进行本体标注,将其表示为一棵语义Web服务刻面树,完成语义Web服务聚类的预处理。将语义Web服务按照子刻面的描述聚集到所属刻面分类下,形成子刻面服务集合,然后聚类得到服务簇,同一个子刻面下的语义Web服务的相似度较大,不同子刻面下的语义Web服务相似度较小。因此,当服务请求者在查找所需服务时,在某种程度上缩小了服务请求者的查找范围,提高了服务发现的效率。本文采用类似于K近邻算法的聚类方法,使用本体概念语义相似度作为聚类标准,依据式(2)计算2个语义Web服务的语义相似度,相似度较大的服务聚成一类。式(2)的形式如下:
子刻面具体聚类步骤如下:
步骤1初始化聚类中心。对服务注册库中已表示成服务刻面树的语义Web服务按照刻面描述进行分类,从所要聚类的子刻面下的语义Web服务中选取k个类作为初始聚类中心,在选择聚类中心时尽量使得k个作为中心的语义Web服务的相似度很小,得到初始聚类中心c={c1,c2,…,ck}。
步骤2根据式(1)和式(2),分别计算当前子刻面下其他语义Web服务与这k个作为类中心的语义Web服务的相似度,并归类于与其相似度最大的那个类。
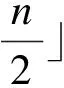
步骤4判断新得到的聚类中心c′与原聚类中心c是否完全相同,若完全相同则结束聚类,跳到步骤7;否则判断count的值,若count的值大于1 000,则跳到步骤7,否则继续向下执行。
步骤5将所有语义Web服务与其所在类的聚类中心的相似度累加到一起,记为SumSim。多次实验结果表明,相似度总和SumSim越大,对语义Web服务的聚类效果越好。
步骤6根据新得到的聚类中心按照步骤2中的聚类方式进行聚类,得到k个新的类。按照步骤5的方式计算相似度总和,得到sumSim′。若sumSim小于sumSim′,则表示新得到的k个类的聚类效果优于之前的类,将聚类中心c′赋予c,让c保存拥有最好聚类效果的聚类中心,然后跳转到步骤3;否则,直接按照步骤3的方式得到新的聚类中心c′={c1′,c2′,…,ck′},并令count=count+1,跳转到步骤4。
步骤7聚类完成,结束聚类算法。
在服务注册库中对每个子刻面下的语义Web服务都按照上述聚类算法进行聚类,从而将相似度较高的语义Web服务聚集到一个类中,形成相应的服务簇。最终聚类的个数,即服务簇的个数取决于子刻面的个数和聚类时选取的k值的大小。本文的服务发现方法在对语义Web 服务进行聚类时,需要提前给出聚类的个数(即k的值),而且聚类的个数直接影响聚类结果,因此,要经过多次不同聚类个数的实验才能确定较好的聚类个数。
3 语义Web服务发现过程
基于领域本体知识对语义Web服务进行多刻面表示,多角度描述语义Web服务。在服务注册库中对语义Web服务进行基于语义相似度的聚类,使得服务发现方法具备一定的模糊匹配功能。另外,服务请求者对要请求的语义Web服务的描述信息可能不完整,没有包含所有语义Web服务刻面集中的刻面描述信息(即本体概念),服务匹配器为服务请求者没有输入的信息设置默认值,保证服务发现方法具备一定的张弛能力,使Web服务发现结果具有良好的查准率与查全率。
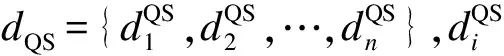

从服务注册库中的多个服务簇的簇中心中选取与请求服务相似度最大的簇中心,记录该服务簇中的所有语义Web服务。根据刻面划分原理,一个主刻面下不同子刻面包含的语义Web服务不同,与服务请求拥有较高相似度的簇中心所在的服务簇中的所有语义Web服务都可作为候选服务发现结果,于是对同一主刻面不同子刻面下被记录的语义Web服务集合求并集。由于一个语义Web服务含有多个刻面描述,同一个语义Web服务会出现在不同主刻面下,因此再对不同主刻面下满足条件的所有语义Web服务求交集,使得到的服务发现结果中的语义Web服务不重复。计算所得语义Web服务集合中的每一个服务与服务请求的相似度,满足要求的语义Web服务与服务请求的相似度记为S1(0≤S1≤1)。上述语义Web服务集合中的服务在不同主刻面下都有其与所属服务簇的簇中心的相似度。为了体现聚类和簇中心在计算服务请求与服务发现结果中的语义Web服务的最终相似度所起到的作用,将语义Web服务在不同主刻面下的相似度求和取平均数,记为S2(0≤S2≤1),于是可以得到服务请求与上述语义Web服务集中服务的最终相似度,记为S(0≤S≤1),令S=(S1+S2)/2。最后,对相似度大于阈值的语义Web服务按照相似度进行排序,得到最终服务发现结果。
服务发现算法流程描述如下:
输入服务请求描述dQS,服务簇sSC,服务本体库lSOL,服务刻面树T
输出相似度从大到小的N个构件
1.对dQS进行基于lSOL的刻面描述
2.for sSC中的所有簇中心
3.Sim_QW=sim(dQS,wWS);
4.end for;
5.for T的子刻面层的所有节点
6.maxsim=max(Sim_QW,k);
7.相似度最大的服务簇中的所有语义Web服务保存到maxSim_WS中;
8.end for;
9.for T的主刻面层的所有节点
10.unionQW=Union(maxSim_WS,n);
11.unionQW中的语义Web服务与服务簇中心的相似度的值保存到unionQW_Sim;
12.end for;
13.array_mixQW=mix(unionQW,n);
14.array_mixQW_Sim记录array_mixQW中的语义Web服务与簇中心的相似度;
15.for array_mixQW中的所有语义Web服务
16.S1=sim(wWS,dQS);
17.S2= n个主刻面下的相似度的平均值;
18.if((S1+S2)/2≥阈值)
19.result=(array_mixQWi,(S1+S2)/2);
20.end for
21.sort(result);
在服务发现算法中,步骤1是将语义Web服务请求进行基于本体库的刻面表示;步骤2~步骤4用式(3)计算服务请求与服务簇的簇中心的相似度;步骤5~步骤8是选取与服务请求相似度最大的簇中心,步骤6中的k为聚类个数;步骤9~步骤12是同一主刻面下不同子刻面中选出的服务簇求并集;步骤13和步骤14是对不同主刻面下得到的服务簇求交集,同时记录语义Web服务与所属服务簇中心的相似度;步骤15~步骤20是计算服务请求与符合要求语义Web服务的总相似度,大于阈值条件的加入服务发现结果集中;步骤21是对得到的服务发现结果集中的服务按照相似度排序,并将结果呈现给用户。该算法中刻面的个数相比于语义Web服务的个数可以忽略不计,故算法的时间复杂度为O(n)。
4 实验结果及分析
为验证本文所提出的语义Web服务发现方法在查准率、查全率以及执行效率方面的性能,使用OWLS-TC4测试集进行实验。OWLS-TC4测试集提供了来自9个不同领域的总共1 083个语义Web服务,包括教育、医疗保健、食品、旅游、通信、经济、武器、地理和仿真。本文选取服务个数和请求个数较多的4个领域的语义Web服务进行实验,实验数据如表1所示。

表1 语义Web服务的实验数据
利用Protégé工具处理OWLS-TC4测试集中服务的本体概念,借助MySQL数据库,使用Java语言在Eclipse中对算法进行编码和实现。实验中服务发现的效果通过评测查准率、查全率和执行时间3个指标来体现,查准率和查全率的计算公式分别为:查准率P=nr/Nq,查全率R=nr/Nr。其中,nr是检索结果中满足服务请求的语义Web服务个数,Nq是检索得到的服务总个数,Nr是服务注册库中满足服务请求的服务个数。另外,通过在不同相似度阈值下进行的实验测试,发现阈值取为0.7,即服务相似度S≥0.7时,检索结果的查准率和查全率较好,故在本文中服务相似度阈值设为0.7。
考虑到聚类个数对聚类结果存在直接影响,进而影响实验结果的查准率和查全率,于是使用本文提出的服务发现方法进行多次不同聚类个数的实验,选取教育领域的286个语义Web服务,不同聚类个数的查准率、查全率和F-measure值如图4所示。

图4 不同聚类个数查准率、查全率和F-measure值趋势
根据图4中聚类个数对查准率、查全率和F-measure值影响的分析确定合适的聚类个数,然后在不同领域下进行实验,采用OWLS-TC4测试集中提供的请求,同时与文献[6]所提出的基于聚类和二分图匹配的Web服务发现方法作对比,最后对每个领域的多次服务请求所得的查准率和查全率分别计算平均值。不同领域下2种服务发现方法的查准率和查全率分别如图5和图6所示。通过2种服务发现方法的查准率和查全率的对比可以发现,相较于基于聚类与二分图匹配服务的发现方法,本文方法对服务的查准率和查全率较高。实验结果表明,本文方法的平均查准率在85%以上,查全率是90%左右。
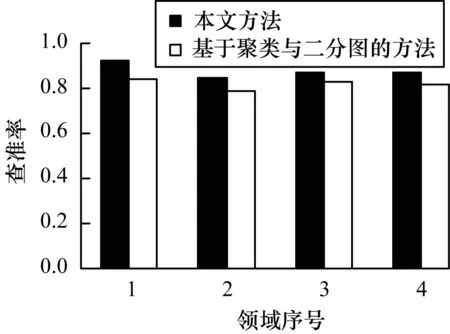
图5 不同领域查准率对比

图6 不同领域查全率对比
实验中算法的执行效率(即服务请求的响应时间)除了和服务发现方法有关,还与进行实验时使用的仿真平台及硬件配置有关,本文进行实验时使用的电脑处理器是AMD Athlon X4。对不同领域中的服务请求分别进行响应时间的测试,选取OWLS-TC4测试集中经济领域的12个服务请求,2种服务发现方法的服务请求响应时间对比如图7所示。
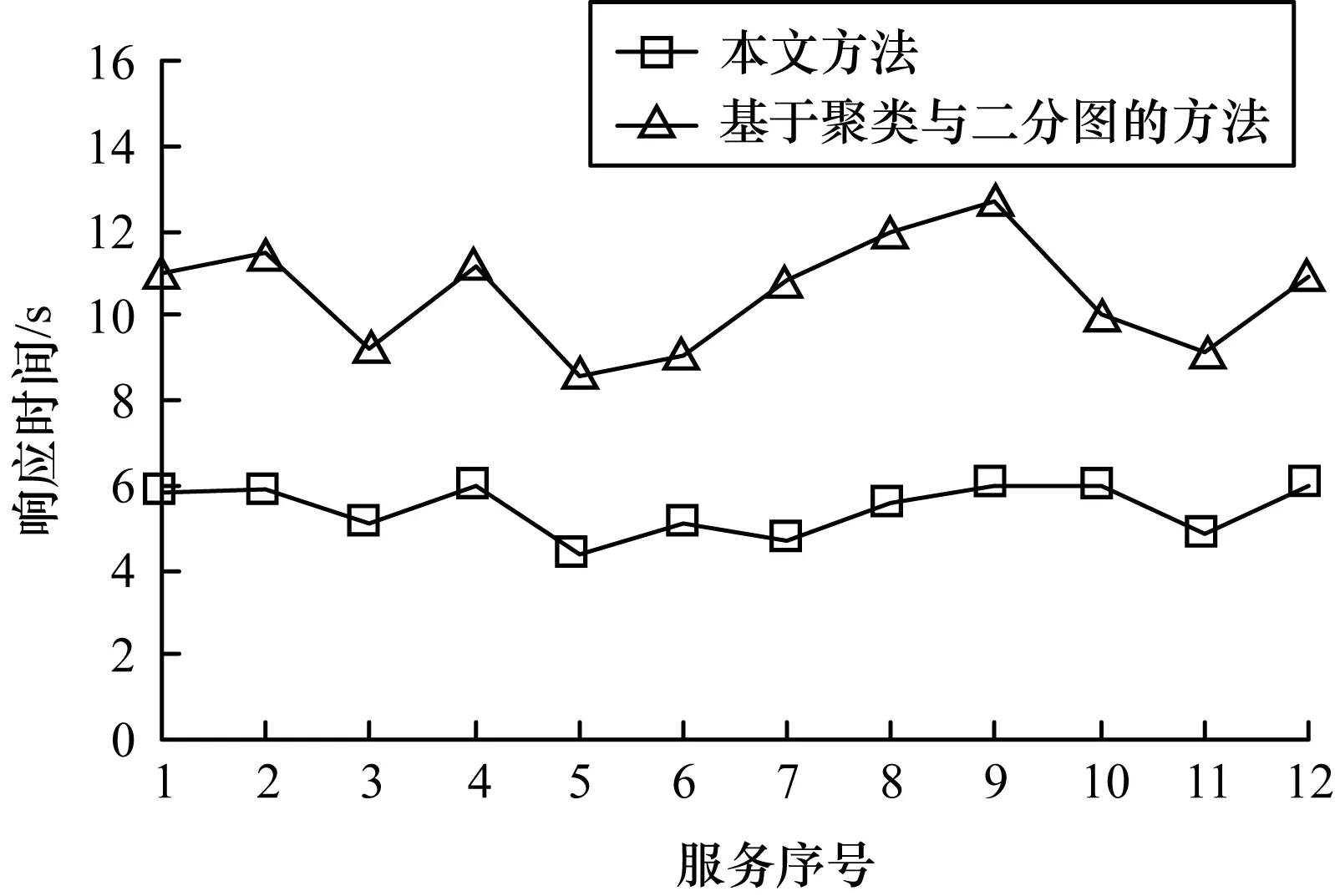
图7 服务请求响应时间对比
实验结果表明,本文方法的服务请求响应时间比基于聚类和二分图匹配语义的Web服务方法要少很多,服务发现效率明显提高。综合服务的查准率、查全率和服务请求响应时间,本文提出的服务发现方法是有效的,而且拥有较好的服务发现效果。
5 结束语
在软件开发过程中对现有软件进行复用,可以在很大程度上节约开发成本和开发时间。随着人们对Web服务的研究与开发,从服务注册库中快速且有效地找到用户所需要的服务对软件检索技术提出了更高的要求。本文提出基于刻面和本体标识的语义Web服务发现方法,通过服务分析器将语义Web服务转化成基于本体概念的刻面树,再使用服务聚类器对服务注册库中的语义Web服务按照刻面进行聚类,得到多个服务簇。实验结果证明本文的服务发现方法具有较好的查准率、查全率和执行效率。
语义Web服务的研究依赖于语义分析技术,对语义Web服务进行刻面描述时,刻面的选取以及相关的本体概念都对本文的服务发现方法有影响。另外,本文都是在同一个领域中进行服务发现实验,而且数据也不够多。因此,后续工作将对语义分析技术、语义Web服务的刻面分类描述以及聚类方法进行研究,完善服务发现方法、增加实验数据,进一步提高检索效果。
