文本摘要的建构渗透度特征模型
2018-08-17任立园谢振平
任立园,谢振平,刘 渊
(1. 江南大学 数字媒体学院, 江苏 无锡 214122;2. 江苏省媒体设计与软件技术重点实验室, 江苏 无锡 214122)
0 引言
为使浏览者快速、准确地获得有用的信息,使他们从纷繁复杂的信息获取、处理中解放出来,文本摘要技术正成为不可或缺的大数据处理工具之一。文本摘要技术是指从大量数据中自动找到能够表达文本主旨内容的摘要文句[1]的技术,能够提高文本浏览、检索、分类的效率。显然地,摘要句集要求有一定的概况性、客观性、可理解性和可读性[2]。
文本摘要方法一般以原文中的句子作为单位进行评估分析,主要依赖文本外部可见特征,如句子长度、位置、词频等信息。本文借鉴知识网络可对领域知识库进行建模表达的思想,为了表征语料库知识间的关联性,将语料库中的文句关键词构建成知识网络节点,从而可将文句映射至知识网络上的一条节点路径进行表达。相应地,可引入文句路径在知识网络中的渗透性特征作为新的摘要句特征量。具体地,引入文句路径中关键词组的覆盖宽度和内在深度作为文句的建构渗透度特征。进一步,借助最大熵分类方法,通过实验分析了新特征与基础特征的摘要句判别影响权重及性能对比结果。
1 相关工作
1.1 文本摘要技术
文本摘要是自然语言处理技术的重要组成部分,最早应用于图书管理中。自Luhn[3]发表第一篇有关文章摘要技术的论文后,在测评会议DUC[4]与TAC[5]组织的自动摘要国际评测的推动下,文本摘要技术已经取得了较大的进展。Chin-Yew Lin[6]开发的摘要质量自动评估工具ROUGE的广泛使用也推动了文本摘要技术的快速发展。
文本摘要技术主要有句子抽取式和句子压缩式[7-8]两类方法。抽取式方法是对句子的重要性进行排序,选择权重最高的句子组成摘要。因此,可以基于规则利用文本常见外部特征抽取摘要,或利用机器学习方法基于句子的不同特征属性对句子分类、回归来抽取句子。常见的学习方法有条件随机场(CRF)[9]、SVM[10-11]、最大熵原理[12]等。选择句子时还需进行数据清洗,消除句子的冗余度。句子压缩方法则是二次提炼过程,对句子中词语进行删除、更换或者重新排序,常见方法有ILP[13]、词汇链[14]和图排序[15]等。也有研究基于对语言学的深度剖析,从深度语义层面产生生成式摘要,如AMR[16]模型,需要语言理解分析及语言学知识来支撑,实现复杂度相对较大。
中文由于自身语法特点,目前国内较为全面的语料库相对较少,中文文本摘要研究发展相对较慢,不过也已形成有代表性的成果,如哈工大信息检索研究室刘挺教授等人构建了具有一定规模的语料库,并基于篇章多级依存结构构建了HIT2863II型自动文摘系统[17];北京大学计算机科学技术研究所提出了基于图排序的自动摘要方法[18-19]等。
1.2 最大熵分类模型
1957年Jaynes E T[20-21]提出了最大熵原理。其主要思想是从信息论角度出发,为了准确估计随机变量的状态,在所有可能的概率模型中,熵最大的模型是最优的。即在满足所有已知知识的约束下, 对未知信息不再做其他先验假设,并认为未知信息分布最合理的推断就是符合已知知识的最不确定或最随机的推断。
1992年,Della Pietra[22-23]等人将最大熵原理应用到自然语言处理中建立语言模型进行文本处理。由于其灵活性和包容性以及优异的处理结果,最大熵模型随后被广泛地应用于自然语言处理中,包括分词、词性标注、词义排歧、短语识别、机器翻译、文本分类等[24]。
最大熵模型常用作概率估计的计算,其原理是在给定上下文特征x的情况下,输出是否为事件y的概率py|x。对此,可以用大量的训练数据集获得随机变量的行为,样本学习结果表示为一个二值指示函数的期望值,相应的指示函数称作特征函数。对于多个有效特征的情况,可基于样本数据训练学习每一个特征的权重参数λ1,λ2,…,λk,通过某种组合方法计算条件概率py|x,实现目标的分类或识别。
2 建构渗透度特征模型
新模型主要将文本中的句子构建成知识网络[25-26]并进行建模表达,从而可以提取能够一定程度上表征文句语义特性的新颖特征。首先着重考虑两个问题: ①如何表示文句关键词知识之间的语义关系; ②如何从语义关系网络中提取能够表征摘要句的有效特征。为此,新模型构建分为两个主要步骤: ①对语料库预处理获取关键词,通过约束关键词之间语义距离来构建知识网络以表征知识间的语义关系,从而将知识节点转化为语义空间的数值变量。②以知识网络节点间路径表征文本文句。为了研究文句在全文的渗透特征对摘要句判别的影响,设计形成渗透度特征,具体引入文句路径中关键词组的覆盖宽度值和内在深度值。
2.1 知识网络
定义知识网络G=(V,E)由节点和边组成,节点表示知识项,边表示两个知识间的语义关系。文中V={Wi}为文句中所有关键词的集合。E⊂V×V是关键词间的关系集合。进而,语料库中文档的每个文句可由多个关键词顺序串成,则相应的每个文句可由知识网络的一条节点路径表示。
文中知识网络的构建分为四个步骤: 1)基于术语抽取方法提取语料库的关键词作为知识网络的节点; 2)采用word2vec词向量模型[27]为每个关键词训练出一个高维词向量; 3)通过计算关键词词向量间的欧氏距离作为知识网络节点间的边权重,从而量化知识网络节点间的语义强弱关系; 4)针对知识网络中每个节点,保留该节点的前top-k个距离最近的节点作为其关联节点,同时保存对应的节点间边权重。
语料库关键词抽取首先对语料库进行预处理,包括解析语料文本、分词、去除停用词等清洗数据步骤,再基于词频统计和信息熵抽取术语得到关键词集合。
词向量模型[27]最早由Hinton于1986年提出,其核心思想是通过文本语料训练,利用词的共现信息、语义信息和上下文依赖关系,将每个词映射成一个高维的实数向量,通过计算向量之间的距离来表征词汇间的语义关系。
根据每个关键词对应的高维词向量,可通过欧氏距离公式计算知识间的语义关系强度。结合小世界网络理论[28]和实验分析,对每一个网络节点,仅记录与其最近邻相关的最多20个节点间的连接边关系。
结合实验中哈工大信息检索研究室单文档自动文摘语料库[29]的预处理结果,图1给出了一个上述方法构造的知识网络结构示例。其中圆点表示关键词节点,节点间的连线表示知识语义关系,权重越小则节点距离越近,表明两个知识之间关系越紧密。节点的所有近邻关系数称为节点度D,节点度越大表明知识节点在知识网络中重要性越大,相应节点的圆点半径大小指示了该关键词节点在该网络中的重要性程度。

图1 知识网络结构示例
图1是截取了整体知识网络的部分子图。以语料库中“冰淇淋”一词为例分析,其节点度D为13。指向该词的近邻关系词有“可乐”“奶粉”“饮料”“牛奶”“巧克力”“雪糕”“饼干”“零食”等13个关键词节点,两者语义关系值越小,则在图上越近。图1给出了示例“冰淇淋-巧克力”和“冰淇淋-啤酒”的语义距离分别为1.905 650和2.561 474。此外,可以看出“冰淇淋”节点半径大于指向它的其他关键词的节点半径,而小于它指向的“奶茶”一词的节点半径,说明了在该子图中“奶茶”一词的重要性较高。
进而,可将语料库中的文档及句子映射至知识网络进行表达。具体地,由于文句中每个关键词对应知识网络中的一个节点,则含有多个顺序关键词的一个文句可对应知识网络上的一条节点间路径,而每个文档则可表示为由其文句路径组合成的知识网络社区。在节点路径表示过程中,两个关键词节点间可能是直接或非间接相连。如图2所示,有两条加粗路径分别表示两个不同的文句路径,其中一条节点间连接为全部实线,另一条节点间连接存在虚线,实线表示相邻关键词节点间有直接相连边,虚线表示相邻关键词节点间没有直接相连的边,需要经过二者中间的其他节点。
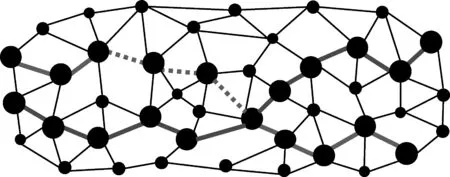
图2 文句路径实例图
2.2 渗透度特征提取
文档中的某个句子如果是摘要句,通常可以认为该句中含有较多的原文信息,即其中的关键词本身在文档中具有较高的影响度。往往这些关键词在文档社区中分布较广,且具有延展性。它们可以从摘要句中渗透到全文中,对文档的行文布局起到提纲挈领的作用,与上下文有着一定联系,这就是关键词的渗透度特性。为了更好地量化渗透度,可引入文句的渗透度特征作为摘要句提取的重要特征量。
结合分析关键词节点的词频、节点度等指标可知,一个关键词节点的渗透延展性越强,它与上下文的知识相关性也越强,对摘要句产生的驱动强度也应越大。为此,定义文句在知识网络中渗透度的渗透覆盖宽度特征和渗透内在深度特征,以反映文句成为摘要句的可能强度。
渗透覆盖宽度特征反映了文句关键词在整个文档中出现的广泛性。故关键词节点渗透覆盖宽度定义为其在文档社区网络中,所覆盖相关的文句路径次数。即经过该关键词节点的文句路径数。而整个文句的渗透覆盖宽度值定义为其所包含的关键词节点的渗透覆盖宽度值的加和,如式(1)所示。
(1)
其中,widi表示文句Si的渗透覆盖宽度值,wij为文句Si中的第j个关键词,dgr(wij)表示社区网络中经过关键词节点wij的文句路径数,即单个关键词节点的渗透覆盖宽度值。式(1)中,ni表示文句Si中关键词的个数。
若网络社区中某条路径仅包含“奥运会”和“中国”两个关键词节点,且上述两个关键词节点的经过路径情况如下所示:
奥运会 4 6 7 31 50 58 60 62 63 70 81
中国 1 2 5 12 13 23 24 31 32 34 37 47 54 55 60 61 70 73 76 78 80
则该条路径的渗透覆盖宽度值wid=11+18=29。这里需要考虑文句中所有关键词节点经过的路径的去重问题。
进一步,如下考虑文句路径的内在渗透深度特征。考虑到文句路径中两个相邻关键词节点的连接性,定义文句路径的内在渗透深度特征为文句路径中所有相邻节点的语义距离之和,其值为:
(2)
其中,depi表示文句Si的内在渗透深度值,wi,j为文句Si中的第j个关键词;dis(wi,j,wi,j+1)为相邻关键词节点间的关键词知识网络上的距离,若两个节点非直接相连,则取两者间所有连通路径中的最短路径距离。
3 实验方法
3.1 文句特征集
结合传统的摘要句特征提取方法,文本实验中合计考虑如下的特征集,

其中,loc,len,tf-idf为基本特征集,loc表示文句在整个文章中的相对位置值,len表示文句中所含关键词的个数,tf-idf表示词频和逆向文档频率[30],if表示词语在文档中出现的次数,idf表示词语被包含在语料库文档中的篇数的倒数。tf-idf值通常取tf与idf值的乘积。wordvec表示文句中所含关键词的词向量,文中词向量维度取200,向量中每一维表示某种隐含的语义信息。一般词向量空间簇聚紧密的词之间内在关系也较为密切。
对于特征true/false/?,若是训练文句数据,则取明确的标记值true或false;若为测试文句,则取为不定值“?”。
3.2 最大熵摘要句判别模型
最大熵模型中简单的特征集可以表达复杂的语言现象,使用最大熵模型进行中文文本分类方法仍存在有效特征缺失的问题[31],特征的选择是模型性能的关键因素。基于上述特征集,借助最大熵分类模型,本文实验的摘要句判别过程如下。对于任意文句Si的某个特征xik,定义p(yi|xik)表示某个特征条件下,文句Si为摘要句yi=1或非摘要句yi=0的概率。如此,原文文句可视为摘要句和非摘要句的合集,进而对文句集合进行二分处理。在基于最大熵模型的摘要提取模型中,进一步引入特征函数f(y,x)→{1,0},表示特征量x与判别结果量y之间的相关性,取值为1或0,分别表示两者存在或不存在因果特征,如式(3)所示。

(3)
进一步基于最大熵分类模型,可得到如下关于摘要句判别的最优概率公式,如式(4)所示。

(4)

(5)

3.3 实验数据集及评价指标
本文采用的语料库是哈工大信息检索研究室单文档自动文摘语料库[29],这是一个可训练的XML文本集,其中共有1 055篇文档,共计约43 505个文句。文本内容为人工按照原文10%以及20%文摘句标注后的语料。实验中随机从10%和20%标注的摘要句中抽取训练和测试文本的摘要文句。实验中共提取了46 272个关键词作为知识网络构成节点。
模型训练、测试过程中,考虑等量地抽取正负样本。从知识网络中提取出相同数量的摘要路径和非摘要路径构成训练文本。这样提取的特征集样本不会太单一,从而保证训练模型的准确率。预处理后的语料库的80%用来生成训练文本,剩下的20%留作测试文本。
分类模型将测试文本的句子分类为摘要句和非摘要句,摘要的评测方法是把模型生成的摘要与人工标准摘要进行比较,用查准率P和查全率R(召回率)来衡量性能差异,相应的公式表示如式(6)~(7)所示。
其中,M为摘要算法判别生成的摘要句集合,B为人工建立的标准摘要句集。召回率用来衡量文本摘要算法生成摘要的信息覆盖率,而查准率用来衡量算法评估摘要句的精确度。
为了平衡查准率和召回率影响,较为全面评价模型性能以及提取特征的权重,引入F-Score作为综合指标。根据不同需求,可考虑F1-Score、F0.5-Score、F2-Score三个指标。其中,F1-Score是指查准率和召回率同等重要,F0.5-Score是指查准率比召回率重要,F2-Score是指召回率比查准率重要。具体公式定义如式(8)所示。
(8)
4 实验结果分析
4.1 特征影响权重收敛性
图3首先给出了模型参数求解的一个典型收敛曲线情况结果。其中横坐标代表迭代次数,纵坐标表示特征的权重值。从中可以看出,迭代初期时参数变化波动大,而随着迭代次数的增加,各特征权重参数均趋于收敛稳定,这一结果表明了文中所述特征模型及摘要句判别模型的有效性。又由模型特性可知,各权重参数值大小与对应特征影响强度正相关,收敛得到的特征权重因子越大,则该特征对摘要文句的分类驱动强度越大。分析图3结果可知,与基本特征相比,建构渗透度特征wid,dep对应权重参数的收敛值更好,清晰地表明了新模型特征量的有效性。

图3 模型参数λk的典型收敛性曲线
表1进一步给出了各个参数的详细求解实验结果,表中给出了运行20次实验所得结果的均值与均方差。分析可知,权重影响最小的特征为文句关键词个数len,较大的为渗透度覆盖宽度wid,以及渗透度内在深度特征dep。此外tf-idf和wordvec特征权重较为接近,文句位置的重要性比预想要高。

表1 实验语料库上的特征权重结果
进一步综合分析实验结果,可有以下结论:
(1) 一个文句的建构渗透度特征wid值越大,文句为摘要句的可能性越大。
(2) 一个文句是否为摘要句和文句中关键词个数即特征len的相关性较弱。可以想象,较短摘要文句是对全文的概括,较长摘要文句则是解释说明相关关键词,所以摘要文句长度值波动范围较大。
(3)loc=2或loc=3的文句多为摘要文句。摘要文句多在段首,实验采用累加计数法统计loc值,不同段首的摘要文句loc值逐渐增大。
(4) 含有较高tf-idf值的关键词的文句为摘要文句的概率较大,而特征wordvec与tf-idf对摘要文句中的驱动强度相接近。
(5) 一个文句的dep值在一个中间区间范围内时,文句为摘要句的可能性最大。可见,dep值太小时,文句的概括性较弱;dep值过大时,文句的内涵紧密性可能也较弱,均不利于成为一个摘要句。
4.2 不同特征的性能影响比较
本小节进一步定量化考察不同特征下的摘要句判别性能影响。表2给出了选取不同特征情况下,基于最大熵分类所得摘要句分类性能的实验结果,表中同样给出了运行20次实验的性能指标的均值和均方差值。其中,基础特征集为loc、len、tf-idf、wordvec,表中性能指标均为百分比值(%)。

表2 不同特征集下的摘要性能结果
表2中结果显示,在加入建构渗透度特征后,摘要生成的查准率和召回率均有了较大幅度的提升,明确地显示了建构渗透度特征模型的强有效性。具体地,基础特征集加入渗透度内在深度特征后,查准率提高了17.94%,召回率提高了20.38%。渗透度内在深度特征计算了文句路径中相邻关键词间的知识网络上的建构语义距离,定性分析摘要句特性可知,摘要句中相邻关键词间不应是简单的语义近邻关系,而更应体现一种知识建构性。建构渗透度内在深度特征一定程度上反映了上述概念思想,并获得了良好的性能提升。
在基础特征集中加入渗透度覆盖宽度特征后,模型的查准率较加入渗透度内在深度的特征方法高了6.92%。显然地,渗透度覆盖宽度特征对摘要分类的驱动强度要大于渗透度内在深度特征,这与图3、表1所示结果相吻合。分析可知,在文档网络社区中,若路径中关键词节点的经过路径较多,不仅仅意味着该关键词知识在上下文中频率较高,更表明该知识节点对其他文句路径有较多的支撑作用,这一特征表现与摘要句的内在特性高度吻合。
结合F值性能结果比较可知,加入了渗透度内在深度和覆盖宽度特征后的模型性能进一步得到了提升,综合地表明了文中所定义的两个建构渗透度特征具有互补性,可有效结合运用。
4.3 新特征模型下常用分类算法性能比较
基于文中提出的建构渗透度特征模型F=loc,len,tf-idf,wordvec,wid,dep,进一步研究分析不同常规分类算法的性能结果,将最大熵分类模型、朴素贝叶斯算法及SVM算法进行对比。基于前述实验相同的数据集及实验方法进行实验分析,所得结果如表3所示。对于SVM,各维度特征量进行了均值为0和方差为1的归一化处理,核函数为高斯函数,模型中核宽度和结构项权重值进行了优化选择。从表3的结果可以看出,本文采用的基于最大熵分类的摘要句判别模型取得了更好的综合性能。

表3 基于新特征模型的算法性能比较
5 总结
本文通过引入关键词知识网络,以节点表示文句关键词,边表征关键词间语义关系,节点间路径表征文句特性。并在知识网络中引入文句的渗透度特征,分别提出了渗透覆盖宽度和内在深度特征量,并进一步结合最大熵分类模型进行摘要句提取建模。实验结果表明了新特征模型的良好有效性,且指出渗透覆盖宽度特征具有最强的特异性。进一步的常规算法对比实验结果也表明,在新特征模型上,使用基于最大熵分类的文本摘要方法具有最佳的性能表现。文中综合研究结果表明,所提出的建构渗透度特征模型具有良好的可计算性及较高的应用性能价值。
