基于数据并行的神经语言模型多卡训练分析
2018-08-17李垠桥阿敏巴雅尔朱靖波
李垠桥,阿敏巴雅尔,肖 桐,薄 乐,朱靖波,张 俐
(东北大学 自然语言处理实验室,辽宁 沈阳 110819)
0 引言
使用神经网络进行语言建模依赖于大规模的语料数据,同时更大规模的参数设置一般来说也会对神经语言模型的训练有着正向的作用[1-3]。但当面对海量的数据和大规模的网络参数时,如何更加快速地进行模型训练便成了一个亟待解决的问题。
针对此问题,研究人员引入了GPU加快矩阵运算,为了进一步获得速度提升,训练也开始从单一设备转变到多设备并行。其主要方法有两种,数据并行和模型并行[4]。本文主要针对数据并行进行研究,该方法将数据分成若干部分,在多个设备上进行训练,以达到加速的效果。但该方法的简单实现并未达到令人满意的速度提升[5],问题在于训练过程中,设备间的数据传输占用大量时间。实验中,我们使用四张NVIDIA TITAN X (Pascal)GPU卡对循环神经网络进行训练,数据传输的时间占比高达70%。可以看出减小这部分耗时成为解决多设备训练中的重要问题。
科研人员针对如何在单位时间内传输大量的数据进行了研究,提出了许多可行的方法,如异步参数更新[6]、基于采样的更新[7]等。本文主要针对使用All-Reduce算法以及采样策略的神经网络梯度更新进行实验,在不同设备数量下训练前馈神经网络和循环神经网络语言模型[8],对比分析时间消耗随设备数量的变化趋势。实验中,使用上述两种方法训练的循环神经语言模型相对点对点结构在四张NVIDIA TITAN X (Pascal)GPU设备环境下分别可节约25%和41%左右的时间。
1 面向神经语言模型的数据传输
1.1 数据并行训练
数据并行的方法最早由Jeffrey Dean等人提出[4],将数据分散到不同的设备中训练,过程如图1所示,参数按照式(1)进行更新。

(1)


图1 数据并行训练与单设备训练过程对比
1.2 数据传输方法
1.2.1 点对点的数据传输
点对点数据传输是一种常见的参数同步策略,采用中心化结构,如图2(a)所示。网络中设置一个参数服务器,保存全局的网络参数,其余每台设备在计算好自己的权重梯度后将其发送给参数服务器,然后进入等待状态。参数服务器端收集到全部设备的梯度后,将它们累加到自身的网络参数上,之后再将这个更新后的参数值返回给每个计算设备,完成一个minibatch的更新。整个过程如图3所示,主要分为梯度计算、梯度收集、更新模型和回传参数四个部分。
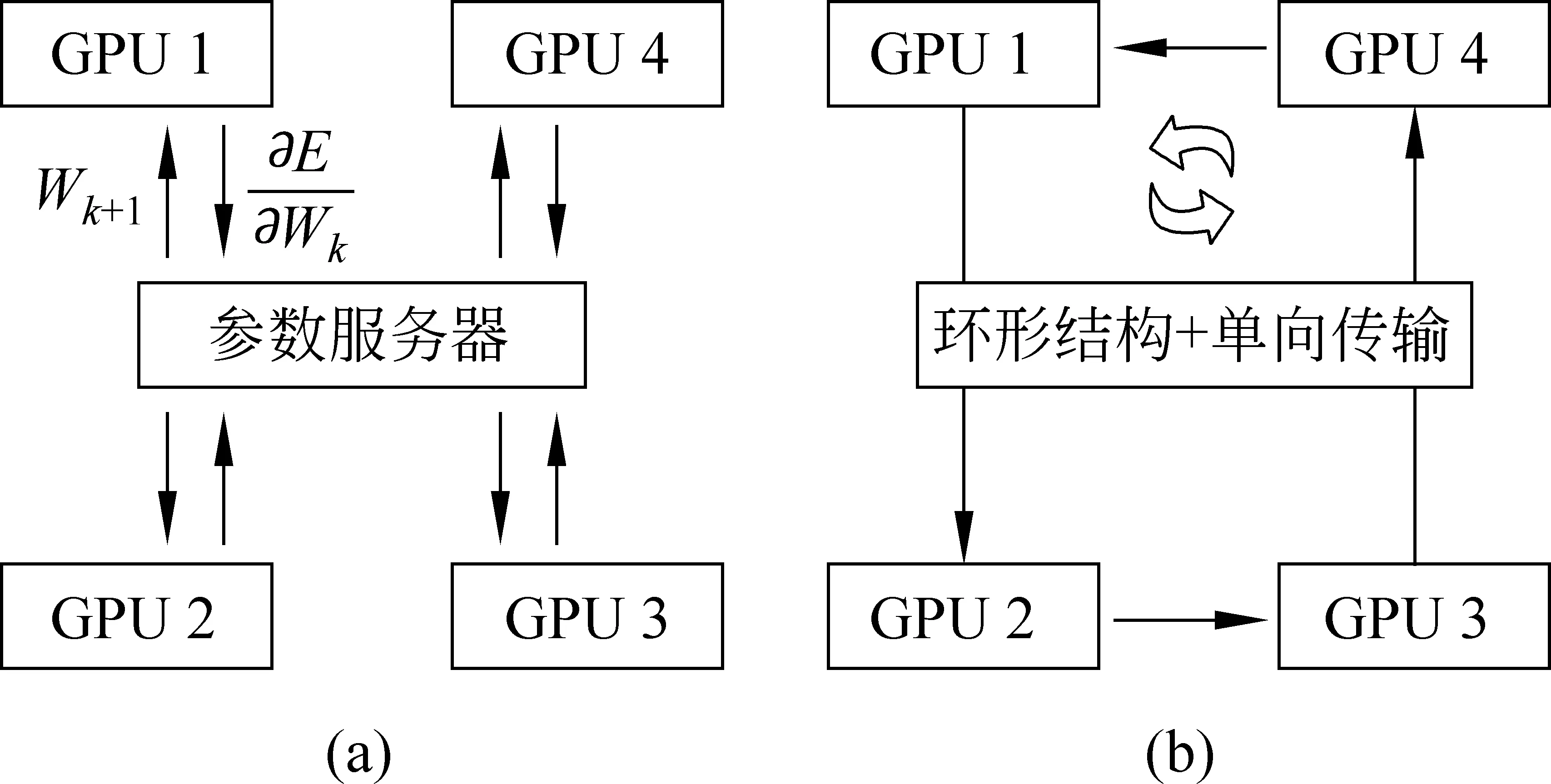
图2 基于点对点、All-Reduce的梯度更新结构

图3 基于点对点的梯度更新计算时序
由于计算机总线带宽有限,因此和数据传输相关的操作会花费较多时间。假设网络中计算梯度的设备数量为n,每个设备上所需传输的数据量大小是K,网络中数据传输的总线带宽是B,那么在梯度收集和回传参数过程中产生的时间消耗如式(2)所示。
(2)
我们可以看出,随着设备数量n的增加,传输的时间消耗也随之线性增长,这导致很难通过简单地增加设备数量获得线性增长的运算速度,难以在更多设备上对网络进行训练。
1.2.2 基于All-Reduce的数据传输
为减轻参数服务器在数据传输过程中的压力,Linnan Wang等人提出使用All-Reduce算法进行梯度的传递[9],结构如图2(b)所示。
整个网络以环状结构进行传输,起初每个设备节点将自身的梯度数组分成n份,n为环形结构中设备节点的数量。在第一阶段,设备节点将依次发送每一块数据到其下一顺位的设备,并从上一个节点接收一个块,累积进本设备的对应位置。执行n-1次后,每个设备中将拥有一个累加了全部设备上对应位次数据的块,之后进入第二阶段。每个设备依次发送自身拥有最终结果的数据块到下一位序的设备,同时根据接收到的数据块进行覆盖更新,同样该步骤按序执行n-1次后,网络中每个设备均将获得最终的累加结果。算法流程如算法1所示。

算法1: 使用All-Reduce进行梯度累加输入: 设备数量n(>1),梯度向量grad1blocks = split(grad, n)2for i = n → 2 do3 send(next, block[(i+devID]%n])4 recv_block = recv()5 block[(i+devID-1)%n]+=recv_block6end for7for i = n → 2 do8 send(next, block[(i+devID+1)%n])9 recv_block = recv()10 block[(i+devID)%n]=recv_block11end for
使用All-Reduce算法进行梯度累加,取代了原有方法中梯度收集和回传参数的过程,其梯度更新计算时序如图4所示。最终完成整个过程的时间如式(3)所示。
(3)

图4 基于All-Reduce的梯度更新计算时序
从式(3)中我们可以看出,虽然传输时间仍随设备数量n的增大而增大,但不同于点对点的数据传递,传输时间和设备数量之间不存在线性相关的问题,这一点为引入更多设备参与训练提供了良好的基础。此外,由于该方法并未对模型训练方式及内容进行修改,因此不会对模型本身的性能产生影响。
1.2.3 基于采样的数据传输
不同于All-Reduce算法从增大传输速度的角度减小训练耗时,采样的方法希望通过减小数据传输量达到加速的目的[7]。该方法在收集梯度的过程中,从完整的梯度矩阵中抽取出对提高神经语言模型性能更有帮助的部分进行传输,减少了传输的数据量,从而节约了在该过程中的时间消耗。
该方法针对不同层提出了不同的采样方法。如对于输出层权重(大小为v×h,v为词表大小,h为隐藏层节点数目),其中每一行对应着词表中的一个词。为使网络能够更快收敛,在采样过程中希望能够尽可能频繁地更新那些经常出现的词,具体的选取策略如式(4)所示。
Vall=Vbase∪Vα∪Vβ
(4)
其中,Vbase为在当前minibatch中出现的词,Vα为从词汇表中选择频繁出现的若干词,Vβ为从词汇表中随机抽取的词以保证系统具有良好的鲁棒性,在测试集上更稳定。同样,在输入层和隐藏层也有不同的采样策略。另外,由于本方法更加频繁地对能够加快收敛的梯度部分进行更新,使得模型收敛速度加快,与此同时模型本身性能变化不大。
2 对比
2.1 实验系统
本文相关实验使用东北大学自然语言处理实验室NiuLearning深度学习平台,结合NCCL开源框架,在四张NVIDIA TITAN X (Pascal)GPU设备上进行。主要对比不同设备数量下,基于All-Reduce算法和采样的更新策略对循环神经语言模型训练速度的影响。此外本文也在前馈神经语言模型[16]中使用All-Reduce算法进行实验,分析数据并行在不同网络结构下的适用性问题。
本文实验数据使用Brown英文语料库(1 161 169词,57 341句),从中抽取40 000句子作为训练集,统计49 036词作为语言模型词汇表。在模型参数方面,循环神经网络和前馈神经语言模型输入层和隐藏层节点个数均为1 024,minibatch为64。前馈神经网络训练5-gram语言模型。
2.2 实验结果及分析
2.2.1 加速效果及变化趋势
实验中将基于点对点进行数据传输的系统作为基线,在四张GPU设备上获得约25%的加速效果,具体实验结果见表1。使用基于采样的梯度更新策略,在同样参数设置下,四张GPU设备加速比达41%左右,具体实验结果如表2所示,整体趋势如图5所示。
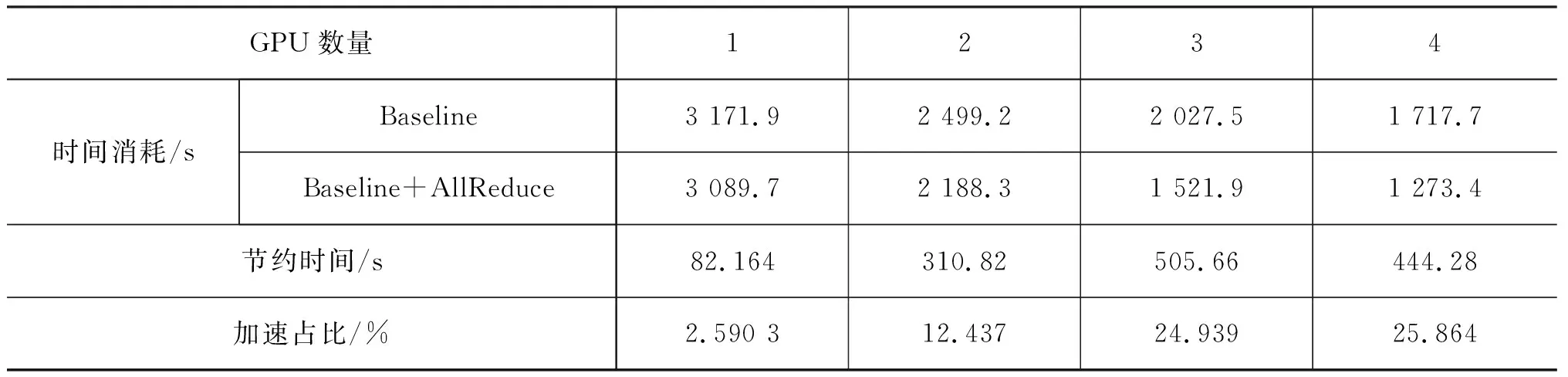
表1 基于All-Reduce梯度更新策略在循环神经语言模型中每个Epoch的时间消耗情况

表2 基于采样的梯度更新策略在循环神经语言模型中每个Epoch的时间消耗情况

图5 基于All-Reduce和采样策略的时间消耗对比
在基线系统的时间消耗中,由于梯度的计算和更新模型不存在内存和显存的交互,因此速度较快。而对于梯度的收集和参数回传,其占用的时间随设备数量的增多而线性变大,因此每个minibatch所消耗的时间如式(5)所示。
(5)
其中tcal&update为梯度计算和模型更新所消耗的总时间。同理,根据图4我们可以看出,使用了All-Reduce算法的梯度累加替代了原本方案中的梯度收集和参数回传的过程,同时这部分的时间消耗并不随设备数量线性增长。在使用了该算法进行梯度更新的情况下,每个minibatch所花费的时间如式(6)所示。
(6)
在整个训练过程中,由于样本数量是固定的,因此minibatch数量也是不变的。而多设备训练将样本分散到不同设备上并行计算,使得在同一时刻整个系统见到的minibatch个数随设备数量线性增加,换句话说总时间消耗将降为原本的1/n,因此在每一轮训练过程中,基线和基于All-Reduce的方法在时间消耗上分别如式(7)、式(8)所示。
(7)
(8)
其中bn为整个训练集中minibatch的数量。根据上述公式,我们可以得到理论上在1~4块设备的状态下每轮执行所需要的时间,如表3所示。其中当设备数量是1,不使用All-Reduce的情况下,由于无需通过总线进行数据传递,将这部分耗时用tgather&back表示。从表3中我们可以看出,随着设备数量的增长,节约的时间越来越多,这一点从图5的实验结果中也能观察到。

表3 在1~4块设备上执行一轮训练所需理论时间
从表2的实验结果我们可以看出,使用采样的梯度更新策略可以获得更高的加速比。不同于All-Reduce试图找到一种更快速的传输策略,该方法通过减少数据传输量来降低多设备训练中大量的时间消耗。由于二者出发点不同,因此理论上可以同时使用两种方法对训练过程进行加速。
2.2.2 数据并行算法适用性
我们使用不同大小的词汇表,通过All-Reduce算法训练循环神经语言模型,时间消耗如图6所示。可以看到,随着词表的减小,多设备训练的时间优势逐渐降低。
此外我们在前馈神经语言模型上进行实验,参数相关设置与循环神经网络相同,具体实验结果见表4。在多设备情况下,随着设备数量的增多,前馈神经网络在使用All-Reduce算法前后变化趋势如图7左侧部分所示,类似于循环神经网络。但从表4中我们可以看出,当设备数为1时,训练1轮所需时间远小于多设备训练的方法。以上两组实验均出现了单设备训练优于多设备并行的现象。循环神经语言模型实验中,由于词表的减小,梯度计算耗时变低,导致并行优势被数据传输所掩盖。同理,前馈神经网络相较循环神经网络在结构上更加简单,数据传输占据了耗时的主要部分,即使使用All-Reduce算法对传输时间进行稀释,也无法抵消其所带来的耗时问题。从表3的理论推导中我们也可以看出,当使用多设备(n>1)训练神经网络的时候,时间消耗均与K有着很强的线性关联,当所需传输的数据量较大时,多设备训练的实际效果并不会很好。

图6 不同词表大小下基于All-Reduce的时间消耗

GPU数量1234时间消耗/sBaselineBaseline+AllReduce节约时间/s加速占比/%317.221 280.41 242.61 228.8216.071 245.41 095.4903.58101.1535.003147.18325.2331.8862.733711.84526.467

图7 不同设备配置下基于All-Reduce的时间消耗
2.2.3 硬件连接方式对速度的影响
在实验过程中发现,设备之间硬件的连接方式也会对传输速度产生影响。在前馈神经网络语言模型的实验中,当设备数量为2且工作节点使用0号和1号GPU进行训练时,时间消耗曲线如图7中右侧部分所示,左侧部分为使用0号和2号设备所得,我们可以看出,当选择不同设备进行数据传输时,其所消耗的时间也有可能不同。我们实验平台上的硬件拓扑结构如图8所示,0号和1号卡为一组,2号和3号为一组,均使用PCIe Switch进行连接。
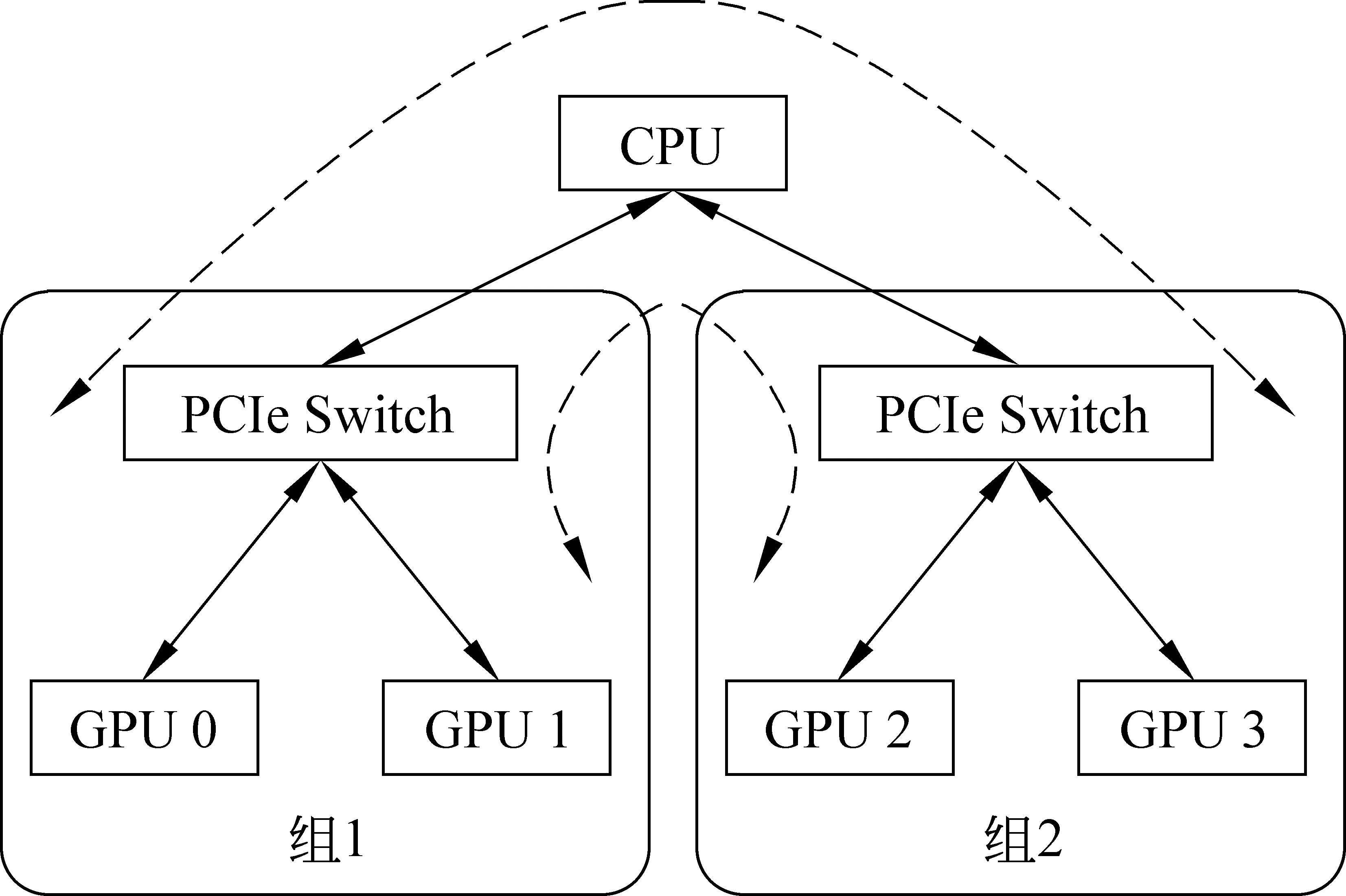
图8 实验平台的硬件拓扑结构
由于组内进行数据传输无需通过CPU,占用总线带宽,因此传输速率较快,组间由于需要经过多个设备对数据进行转发,因此速度相对慢一些。1~3卡之间互相传输数据带宽如图9左侧部分所示,其中颜色越浅带宽越高,传输速率越快,图9右侧给出组内平均带宽为5.96 GB/s,组间4.46 GB/s。

图9 不同设备之间数据传输带宽
由于All-Reduce算法采用环形结构让设备之间进行数据传输,因此只要系统中存在任意两台设备间传输速度慢,那么就会拖慢整体系统的传输速率。因此在前述两张卡的实验中,为保证实验公平性,我们使用0号和2号进行实验,保证多设备的每组实验中均存在组间的数据传递。同理,在基于采样的数据传输过程中,其数据传输方式仍为点到点的传输,慢速的连接只会影响节点本身与参数服务器之间的传输过程,对整体的时间消耗影响有限。
3 总结
本文主要针对如何降低多设备训练神经语言模型中的时间消耗进行实验,对比不同梯度更新策略的加速效果。
•加速效果: 使用All-Reduce的梯度收集策略在循环神经语言模型上可获得25%左右的加速效果,同时随着设备数量的增加,加速效果更加显著;使用基于采样的梯度更新方法可达到约41%的加速。
•数据并行适用性: 使用多设备训练神经网络在不同模型下速度变化趋势稍有不同。实验发现对于大量数据传输占主导的网络模型,多设备训练反而会降低整体运行速度。在这种情况下即使使用了All-Reduce等的加速方法也很难获得与单设备可比的运行速度。而对于数据传输量偏小的模型,在实际使用中比较适合在多设备上并行训练。
•硬件连接方式对速度的影响: 实验中发现,设备之间不同的硬件连接方式会对传输速度产生影响。针对该特性,我们在未来工作中考虑将采样算法与All-Reduce进行结合,对于传输较慢的设备在采样中给予相对较低的采样率,实现能者多劳,不让某些设备的传输速度拖慢整体。
