基于统计分析的卷积神经网络模型压缩方法①
2018-08-17蓝章礼
杨 扬,蓝章礼,陈 巍
(重庆交通大学 信息科学与工程学院,重庆 400074)
2012年Hiton[1]构建的深度卷积神经网络AlexNet才在图像分类领域取得了惊人的成绩,卷积神经网络(CNN)在计算机视觉领域包括图像分类[1],目标检测[2]、图像语义分割[3]、视频分类[4]得到了广泛的应用[5].之后,层数更多、更加精细设计的深度卷积神经网络结构相继被提出,比如VggNet[6]、GoogLenet[7]、ResNet[8]在ImageNet[9]上取得了更好的成绩.除此之外,卷积神经网络在人工智能[10],自然语言处理[11],故障诊断[12]有着广阔的应用前景.这些深度卷积神经网络模型参数越来越多,运算量越来越大,对运算设备的内存、CPU、GPU的配置要求越来越高.当需要在运算和存储资源有限的微型设备上[13],比如手机、嵌入式设备上使用卷积神经网络时,除了准确率,计算效率和模型的大小也是至关重要的.
模型压缩最早的研究为OBD[14](Optimal Brain Surgeon)和OBS[15](Optimal Brain Surgeon),通过泰勒展开,分析参数的扰动对损失函数的影响,以此确定参数的重要性,决定参数保留或者裁剪.Han等人[16]通过裁剪、量化、压缩卷积神经网络模型参数,大幅度减少模型的大小,并且没有降低模型的准确率.文献[17]指出非结构的稀疏无法利用现有的硬件进行加速,提出了一种在目标函数上增加group lasso进行结构化稀疏的学习方式.文献[18]通过一个训练好的较大的模型来训练一个较小的模型,将较大的模型学到的知识迁移到较小的模型中.Network in Network[19]除了对卷积层进行了改进,还提出了全局平均化的方法,解决了全连接层参数数量多的问题,并被GoogleNet和ResNet等采用.目前卷积层的卷积核大小、卷积核数量对于不同的数据集参数设置不同,需要大量实验,有一定经验成分,卷积层用一般包含了足够多数目的卷积核,存在冗余,已有相关文献通过实验证明在裁剪部分不重要的卷积核后,再训练整个卷积神经网络(或者逐层裁剪、逐层训练)可以在尽量不损失准的条件下对卷积神经网络进行压缩[20–22].Wen[20]等人通过定义APoZ(Average Percentage of Zeros)来统计每一个卷积核中激活为0的比例,以为评估一个卷积核是否重要,主要是用在最后一层卷积层,以此减少全连接层的参数数量.文献[21]通过将一定样本输入卷积神经网络,计算特征图的各类参数,对活性低的特征图通道裁剪.文献[22]通过将卷积核参数的L1范数作为评价一个卷积核重要性的依据,将不重要的卷积核裁剪.
由于文献[19]提出的全局平均池化在一定会程度上解决了传统卷积神经网络参数多的问题.本文的主要解决的是卷积层的压缩,在调研了卷积神经网络训练过程中的规律的基础上,提出了基于卷积核的标准差作为卷积核重要性指标进行卷积核裁剪的方法,并和文献[22]相结合的方法,通过实验,本文提出的方法能和文献[22]互补,综合两种评价指标综合进行卷积核裁剪能保留对分类更有作用的卷积核.
1 卷积神经网络的原理
1958年,Hubel和Wiesel等人[23]发现了生物视觉系统的信息处理方式,视觉信息从视网膜传递到大脑是通过多层的感受野激活完成的.1998年,Lecun等人[24]提出的LeNet-5,如图1所示,LeNet-5由两层卷积层和两层池化层交替将输入图像转换成一系列特征图,再连接三层全连接层对提取的特征分类.卷积层的卷积核实现了局部感受野和特征提取的功能,将局部区域信息通过卷积核的卷积运算,再经过激活函数、池化,将低层的激活信息传递到高层.以往的人工设计的特征有良好的特征表达能力,例如HOG[25],SIFT[26],但这些人工设计的特征缺乏良好的泛化能力.池化层也称下采样层,能在一定程度上保持特征的尺度不变性并对特征图降维.Lenet提出后,在图像分类领域没有取得实质的进展和突破,直到2012年Hiton及其学生Alex构建的深度卷积神经网络AlexNet在ImageNet上取得了显著的成绩,主要原因是训练的改进,在网络的训练中加入了权重衰减、Droupout[27]、Batch Normalization[28]等技术,更关键的是计算机计算能力的提升,GPU加速技术的发展,使得在计算机可以高效地实现卷积的运算.之后,更复杂,准确率更高的深度卷积神经网络被提出.
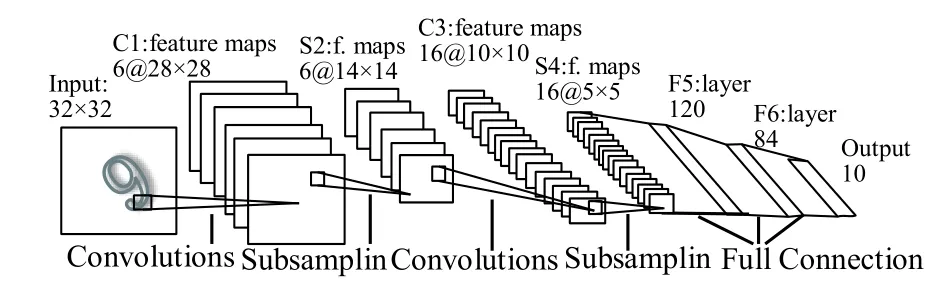
图1 LeNet-5结构图
如图2所示,为一个5×5×3的卷积核作用在一个32×32×3的图像(也可能为32×32×3的特征图)上,5×5×3的卷积核与图像的5×5×3区域点乘再加上偏置(bias)经过激活函数,产生一个运算结果,即图中的小圆球.卷积核在图像的所有局部区域以步长为1滑动并卷积,得到一个28×28×1的特征图(feature map).
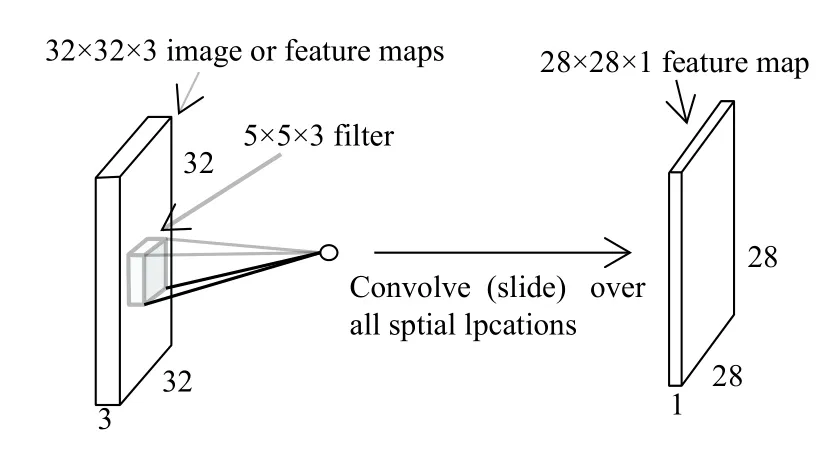
图2 一个卷积核作用在图像或者特征图上
同理,如图3所示,32×32×3的图像经过一个有6个5×5×3的卷积核的卷积层,产生了28×28×6的特征图.在实际中,滑动的步长不一定为1,有时为了保持卷积后特征图大小不变或者取整,会对特征图的边界进行填充(padding),特征图通过卷积层后,会接着通过池化层(pooling layer),将得到的特征图输入到下一层卷积层.

图3 6个卷积核作用在图像或者特征图上
2 卷积核的裁剪
近年来,为了让卷积神经网络达到更好的效果,卷积神经网络朝着更深更复杂的方向发展.而另一方面,增强深度神经网络的运算效率,在不损失精度的情况下,对深度学习训练得到的模型进行优化压缩也有着大量的研究.本文参照文献[21,22]提出的卷积核裁剪方式,针对已经训练好的卷积神经网络模型,对卷积层中数个不重要的卷积核裁剪,同时裁剪对应的特征图,最后对裁剪后的模型进行再训练,恢复模型的性能.
2.1 裁剪方式
为了便于说明裁剪卷积核的方式,如图4所示,Xk∈RHK×WK×NK代表第k层的特征图,Hk、Wk、Nk分别是其高、宽、维度,Convk∈Rs×s×NK×NK+1为第k层卷积层,Fi,j∈Rsk×sk为其中一个2D的单层卷积核,i=1,2,…,Nk,j=1,2,…,Nk+1,sk为第k层卷积层卷积核的高和宽,Nk、Nk+1分别为上一层的特征图的维度和下一层特征图的维度.Xk层特征图通过第k层卷积层Conv k得到了k+1层特征图Xk+1,假设在卷积层中删除第j个卷积核,即图中Convk的j列(灰色),同时也裁剪了Xk+1层特征图的第j个特征图.减少的参数,减少的计算量为,在k+2层特征图Xk+2的计算过程中额外将少的乘法运算量为Nk+2×s2k+1×Hk+2×Wk+2.当在第k层卷积层中裁剪m(0≦m<nk+1)个卷积核时,减少的参数为,减少的乘法运算量为Hk+1.
2.2 卷积核的评价指标
为了决定一个卷积层中某个卷积核的重要程度,文献[20]通过定义APoZ(Average Percentage of Zeros),即一个卷积核中来统计每一个卷积核中激活为0的比例,以为评估一个卷积核是否重要,主要是用在最后一层卷积层,以此减少全连接层的参数数量.文献[21]通过输入样本,通过计算特征图的相关参数确定卷积核的重要程度,认为对不同样本得到类似特征图的卷积核为冗余的卷积核.通过文献[22]在提出以卷积核的L1作为卷积核重要程度的评价指标,认为裁剪L1范数较小的卷积核对整个模型影响较小.
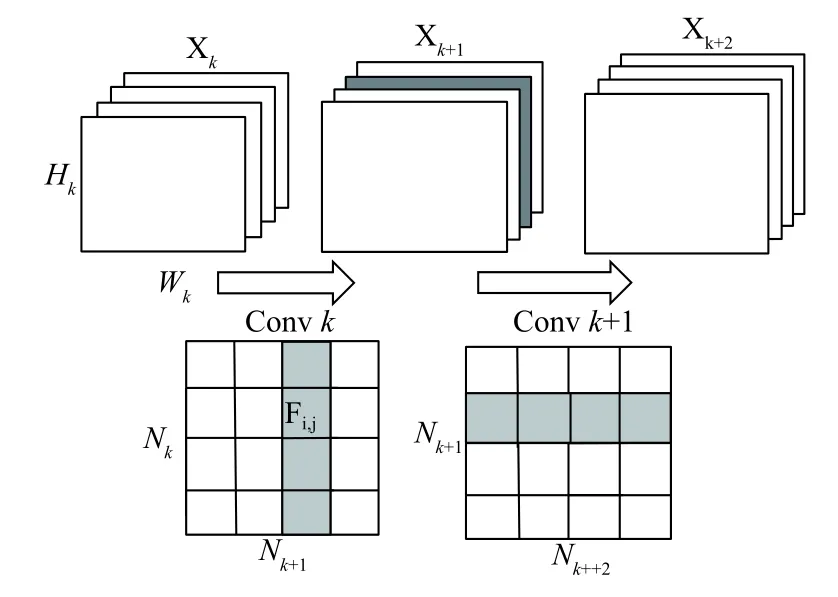
图4 卷积核的裁剪方式
卷积神经网络训练过程中,卷积层中参数的标准差(或方差)逐渐增大,分布范围逐渐扩大,参数之间的差异性逐渐明显,如图5、图6所示.
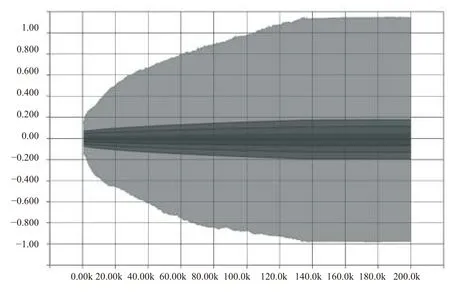
图5 Conv 2参数在训练过程中的分布
本文认为,卷积神经网络通过训练,标准差或者方差更大的卷积核学习到了更明显的局部特征,因此提出了基于标准差的卷积核裁剪方法,克服了文献[20,21]需要输入样本,统计特征图各类参数需要额外大量计算量的缺点,同时也避免了文献[22]只保留L1范数较大的卷积核,而没有考虑到卷积核提取特征的能力与参数的分布有关.本文了还将以卷积核标准差作为卷积核重要性指标与文献[22]提出的以卷积核L1范数作为卷积核重要性指标相结合,即将卷积核的L1范数和标准差结合作为卷积核重要性的评价指标,对卷积核进行裁剪.
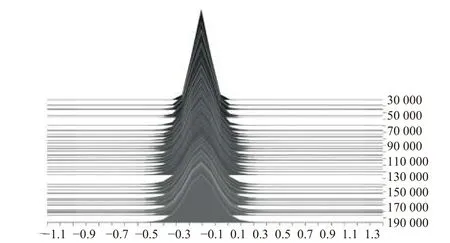
图6 Conv 2参数在训练过程中的统计直方图
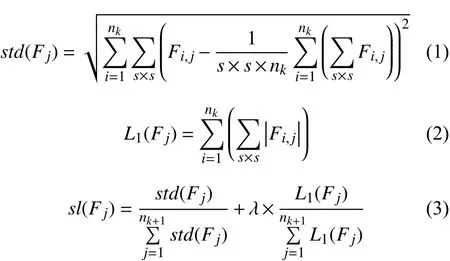
式(1)为一个卷积层中第j个卷积核的标准差计算公式,代表对Fi,j中s×s个元素进行求和.式(2)为卷积层第j个卷积核的L1范数计算公式,代表对Fi,j中s×s个元素的绝对值进行求和,即Fi,j的L1范数,nk个单层卷积核Fi,j的L1范数和即为卷积核Fj的L1范数.式(3)同时考虑了卷积核的L1范数和标准差,为了防止L1范数和标准差计算结果相差过大,对卷积核L1范数和标准差进行了归一化处理,参数λ调节卷积核L1范数和标准差的相对重要程度.当λ=1时,表示卷积核L1范数和标准差同等重要,当λ<1时,表示卷积核标准差比L1范数更重要,当λ>1时,表示卷积核L1范数比标准差更重要.
3 实验分析
为了验证本文所提出的卷积核裁剪方法的正确性和有效性,本文在MNIST和Cifar-10数据集上分别设计了有两层卷积层和三层卷积层的卷积神经网络进行了实验.实验环境:Ubuntu 16.04,Python3.6,Tensorflow 1.2,计算机CPU为6700 hq,GPU为GTX 960 m(4 G显存),内存为8 G.
对MNIST数据集和Cifar-10数据集分别设计了两层卷积层和三层全连接、三层卷积层和三层全连接层结构的卷积神经网络,如表1所示,Conv k代表第k层卷积层,(3,3,1,32)代表该层有32个3×3×1的卷积核.FC k代表第k层全连接层,(3136,200)代表输入一个3136维的数组,输出一个200维的数组.由于cifar-10数据集更复杂,所以在训练过程中采用了数据增强和权重衰减.两个卷积神经网络都采用了交叉熵损失函数计算代价函数.在训练完成后,在MNIST数据集上的正确率达到了99.02%,在Cifar-10上的正确率达到了86.56%.
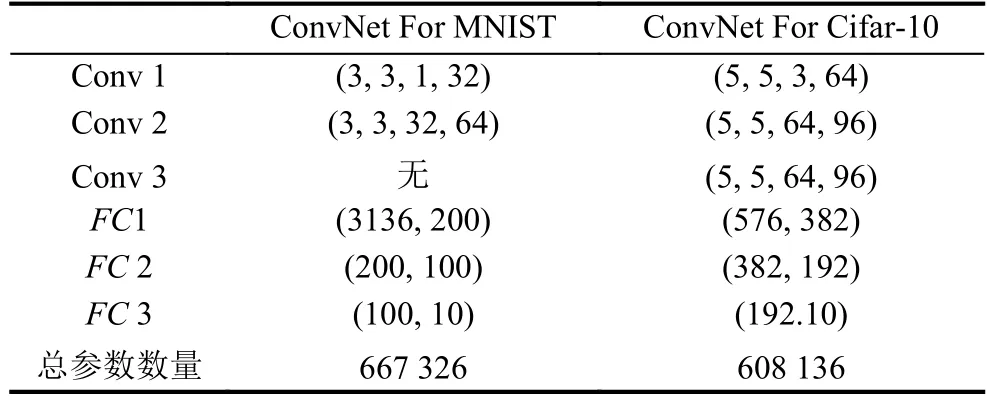
表1 所设计的卷积神经网络的结构
3.1 据方差裁剪卷积核对比
从图7和图8可以看出,在用MNIST数据集训练得到的带有两层卷积层的神经网络中,裁剪标准差较小的卷积核能比裁剪标准较大的卷积核保留的准确率更高,即标准差较大的卷积核比方差较小的卷积核更重要,证实了本文的设想,即标准差较大的卷积核在训练的过程中学到了更为重要的局部特征.
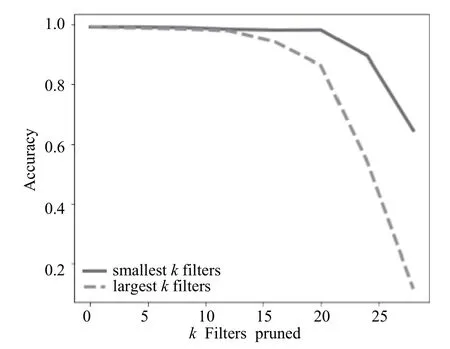
图7 裁剪针对MNIST训练的卷积神经网络第一层卷积层中的卷积核

图8 裁剪针对MNIST训练的卷积神经网络第二层卷积层中的卷积核
如图9-图11可以得出,在Cifar-10上也有着类似的结果,在针对MNIST数据集设计的卷积神经网络中,在裁剪甚至50%的卷积核时,准确率没有明显降低.而针对Cifar-10数据集设计的卷积神经网络,裁剪少数卷积核准确率也会明显降低.一方面是因为MNIST数据集较为简单,Cifar-10数据集较为复杂,其次是因为针对MNIST数据集设计的卷积神经网络卷积核设置得较多,这也说明了,在训练好的卷积神经网络模型中,如果在一个卷积层中裁剪一定的卷积核而准确率没有明显降低,说明这一层的卷积核设置的过多,可以对卷积核进行裁剪.

图9 裁剪针对Cifar-10训练的卷积神经网络第一层卷积层中的卷积核
3.2 对比实验
为了验证本文提出的方法的有效性,本文在分别针对MNIST和Cifar-10训练好的卷积神经网络模型与其他的裁剪方式进行了对比,式(3)中λ取值为1.卷积神经网络在裁剪后,性能会有一定的下降,为了恢复性能,一般会在对裁剪后的模型进行再训练,再训练的迭代次数一般没有从初始状态训练多.24-48代表经过裁剪,第一层卷积层的卷积核保留的个数为24,第二层保留的个数为48,其余情况以类似的方式表示.
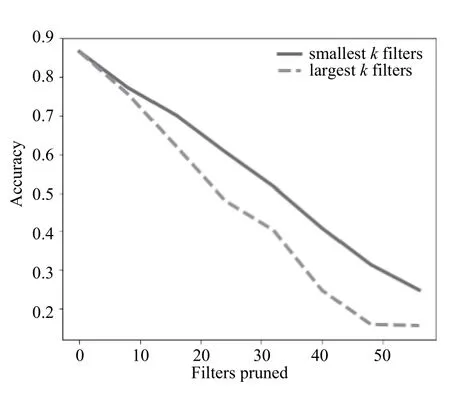
图10 裁剪针对Cifar-10训练的卷积神经网络第二层卷积层中的卷积核
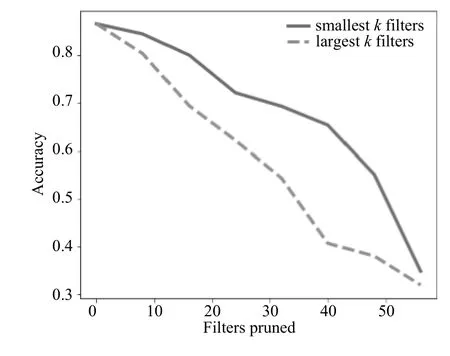
图11 裁剪针对Cifar-10训练的卷积神经网络第三层卷积层中的卷积核
通过表2可以看出,对MNIST数据集设计的两层卷积神经网络分别裁剪后,通过方差作为评价卷积核的裁剪能保留更多的准确率,同时通过再训练后得到的准确率也比文献[22]的方式高.通过表3可以看出,针对Cifar-10设计的三层卷积神经网络中,在48-64-64这种方式裁剪时,文献[22]提出的L1范数作为卷积核的评价指标保留了较大的准确率,而在32-48-48这种裁剪方式时,本文提出的方法保留了较高的准确率,而通过再训练准确率会有所损失.选取L1+std作为卷积核的评价指标进行裁剪时,裁剪后的准确率在L1和std之间.因此,式(3)中的参数λ可以通过卷积核裁剪的比例动态动态调整,在裁剪卷积核数量过多时,适当增大λ,可以保留更高的准确率.

表2 裁剪针对MNIST数据集训练的两层卷积层神经网络

表3 裁剪针对Cifar-10数据集训练的三层卷积层神经网络
4 结论与展望
本文从卷积神经网络训练过程中参数的统计特征出发,提出了一种基统计分析裁剪卷积核的卷积神经网络模型压缩方法.通过在针对MNIST和Cifar-10所设计的两个卷积神经网络中进行裁剪实验,本文提出的标准差较大的卷积学习到了更显著的局部特征的设想是正确的,在与类似的裁剪方式的对比中,本文提出的方法在裁剪较多的卷积核时保留更高的准确率,根据裁剪的比例动态调整卷积核L1范数和标准差的相对重要程度,可以使得裁剪的结果更稳定.在后续的研究中,将进一步研究卷积核通道间的裁剪和利用特征图使得裁剪结果最优.
