基于标记相关性的多示例多标记算法①
2018-08-17李村合田程程
李村合,田程程,姜 宇
(中国石油大学(华东)计算机与通信工程学院,青岛 266580)
在我们的现实生活中,对象往往具有丰富的含义.例如,一篇报道可由多个段落或章节组成,在对其按内容进行分类时,可将其归为“体育”、“科技”等多个类别.如果把报道的每个段落或章节看成一个示例,把其所属的类别看成一个标记,那么,只用一个示例和一个标记来表示这篇报道则太过笼统,表示出的对象也具有概念歧义性和语义歧义性[1].为了同时考察这两方面的歧义性,多示例多标记(Multi-Instance Multi-Label,MIML)[2]学习框架应运而生.多示例多标记学习框架已经成功应用于图像分类、文本分类、网页分类、基因序列编码[2]等问题.解决MIML问题的基本方法是采用退化策略,将MIML问题转化为单示例多标记或者多示例单标记,最终将原问题变成经典的单示例单标记问题.但是,使用退化策略会造成标记之间联系信息的缺失,从而影响分类的质量和效率.
针对这一问题,文章提出了加入了标记相关性影响因子的MIMLSVM- LOC算法来对MIML问题进行求解.改进后的算法采用混合Hausdorff距离进行聚类并将标记的局部相关性运用到MIMLSVM算法中之中,提高了算法的分类准确率,对原算法在退化策略实现过程中,丢失标记之间关联信息的问题实现了优化.具体来说,ML-LOC算法[3]是Huang和周志华在研究多标记学习问题时首先提出来的,考察的是标记的局部相关性.其基本思想是:若示例集合可以被分成若干组,则同组中的示例都有一个相同的标记相关性子集.这种方法,可以充分的利用标记之间的联系信息来提高分类准确率,同时减少过大的输出空间,达到较好的分类效果.
本文的组织结构如下:第1节介绍相关工作,第2节具体说明算法及原理,第3节给出实验数据进行论证,第4节内容是总结全文,并综合评价提出的算法.
1 相关工作
相较于以前的单示例单标记学习算法、多示例学习[4]算法和多标记学习[5]算法,多示例多标记学习算法可以说是一种优化与改进.
目前,在MIML框架下解决问题的方式主要有两种:一种是以退化策略为理论依据,通过进行多示例学习或多标记学习的转换,使原MIML问题简化为一系列二类分类问题,这些二类分类问题与标记空间每个类别一一对应.MIMLBOOST、MIMLSVM和MIMLSVM+等算法都是基于退化策略解决MIML问题的算法.另一种是直接在MIML样本的环境下进行求解,如D-MIMLSVM算法和M3MIML算法等.
周志华和Zhang提出了MIMLBOOST和MIMLSVM算法来解决MIML问题,两者都是在退化策略的基础上进行的[6].MIMLBOOST算法先将MIML问题转化为多示例单标记问题,然后利用多示例学习算法MIBOOSTING[7]进行后面的计算.MIMLSVM算法则是应用K-medoids[8]聚类算法将MIML问题转化为单示例多标记问题.由于两者都没有考虑到实际分类中标记之间的联系信息,使得分类的准确率下降.
Li在进行对果蝇基因进行标注的实验时,使MIMLSVM+和E-MIMLSVM+算法[9]的基本概念出现了雏形.MIMLSVM+算法将MIML问题简化成单示例多标记问题进行求解,并通过SVM分类器将标记独立出来.E-MIMLSVM+算法是在MIMLSVM+算法的基础上优化改进的算法,应用多任务技术[10–12]使SVM分类器中考虑了标记之间的联系信息.E-MIMLSVM+算法的分类质量明显较高,随之付出的代价是训练时间增多,并且存储空间加大.
D-MIMLSVM[2]算法和M3MIML[13]算法是由周志华和Zhang提出的基于正则化机制及最大化间隔策略的算法,皆为直接对MIML问题进行求解的典型算法.D-MIMLSVM算法假设相同样本的标记之间有一定的信息关系,基于正则化机制对MIML问题进行求解.M3MIML算法是基于最大化间隔策略得到一个二次规划问题,若分类系统包含T个线性模型,它们与多个可能的概念类一一对应.每个示例在其相应的线性模型上的最大输出值,决定测试示例样本的分类.DMIMLSVM算法和M3MIML算法都适应于小型数据集[14].
ML-LOC算法[3]是Huang和周志华在研究多标记学习问题时首先提出来的,考察的是标记的局部相关性.ML-LOC算法在每一个示例中添加了一个蕴含标记相关性的向量作为LOC编码,拓展了原始的特征向量.其原理是因为相似的示例具有相似的标记相关性子集,因此相似示例的LOC编码也就越相似.因此本文首先对MIMLSVM算法中的聚类算法进行了改进,之后结合ML-LOC算法对改进聚类方式后的MIMLSVM算法进行训练求解.
2 改进的算法
2.1 改进的MIMLSVM算法
MIMLSVM算法[1]是一种退化算法,该算法将MIML问题退化为单示例多标记问题进行求解.给定MIML训练样本集D={(x1,y1),(x2,y2),···,(xn,yn)},其中,n为训练样本集样本的个数,xi是训练集{中的第i个示例包,Yi∈Y是与Xi相关的类别标记的集合
.示例包的集合可以表示为Γ={Xi|i=1,2,···,m}.MIMLSVM算法使用构造性聚类的方法将多示例多标记样本转化为单示例多标记样本.在原始MIMLSVM算法中,每个示例包看作是原子对象,使用k-medoids聚类将示例空间划分为份,聚类个数是事先确定好的[10].k-medoids聚类中使用了Hausdorff距离来度量包之间的距离,Hausdorff距离的定义如下:
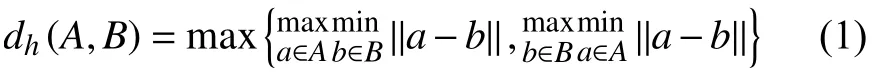
其中,a和b分 别是包中的示例,|a−b|是这两个示例之间的欧式距离.考虑到在基于包间距离测量方法中,由于最大Hausdorff 距离对孤立点敏感,而最小Hausdorff 距离只考虑到包间距离最近的2个示例.因此,从均衡性角度考虑,本文采用文献[6]中提出的混合Hausdorff 距离mixH(A,B)对MIMLSVM算法进行改进.公式如下:
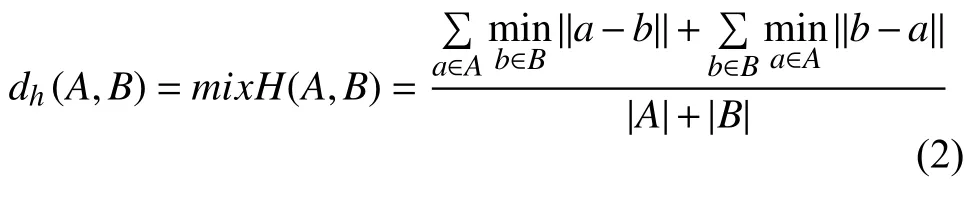
其中,|·|为测量集合的势.mixH(A,B)考虑到了包间示例的几何关系.
上述聚类过程完成后,示例空间Γ已经被划分为k份,每一份的聚类中心可以用Mt(t=1,2,···,k)来表示.接下来计算每个包Xi到聚类中心Mt的Hausdorff距离dh(Xi,Mt)(t=1,2,···,k),使用这k个距离可以构成一个向量zi,即zi的第t维是包Xi和第t(t=1,2,···,k)个聚类中心的距离.可以看出来,向量zi编码了示例包Xi的一些空间结构分布信息,因此包Xi可以用zi来表示,即包Xi转化为了示例zi,这个转化过程称之为构造性聚类转化.这样多示例多标记样本集(Xi,Yi)(i=1,2,···,m)就变成了单示例多标记样本集(zi,Yi)(i=1,2,···,m),其中Φ(Xi)=zi,Φ(x)表示的是使用构造性聚类将包Xi变为示例zi.注意到在转换时,会丢失示例和标记之间的联系信息.
在多示例多标记样本集向单示例多标记样本集转化完成后,MIMLSVM算法使用多标记学习中的MLSVM算法[13]对样本集进行训练.MLSVM算法将多标记问题分解为|y|个二类分类问题,从而为每一个类别标记建立一个SVM分类器.事实上,示例zi参与了每一个分类器的构建,φ(zi,y)=+1仅当y∈Yi即示例zi对应的类别标记集合Yi包含y时,否则φ(zi,y)=−1.至此,多标记学习转化为传统的监督学习问题,可以使用标准的SVM来进行训练分类了[14].
在为每个标记建立完分类器后,对于一个未知标记的样本,根据T-criterion[15]方法,由该样本在标记的分类器上的所得值决定该样本的标记所属类别.
2.2 ML-LOC算法
ML-LOC算法是由Huang S.J.和Zhou Z.H.提出并命名的,是对多标记学习算法的改进,旨在对标记局部相关性进行考察.其主要思想是将示例样本集划分成若干组,并且同一组内的示例具有一致的标记相关性子集.同时减少过大的输出空间,将ML-LOC算法与改进的MIMLSVM算法结合后,不仅可以使标记的作用信息更加完全的发挥作用,使分类更加精准高效,同时能够精简输出量,优化空间存储[6].
首先给定一个训练样本集D,令D表示为D={(x1,y1),(x2,y2),···,(xn,yn)},且xi∈X=Rd是特征向量,d是[特征空间维]度数.yi是xi对应的标记向量且yi=yil,yi2,···,yin,若示例xi具有第l个标记那么yil=1,否则yil=−1.ML-LOC算法使示例多了一个LOC编码信息ci,其在每个示例xi各不相同,其内容是标记的相关性,且作为一个向量存在,使初始的特征向量得到了拓展.由于同组的示例具有一致的标记相[关性,故其]LOC编码也基本一致.我们假设,分类函数f=f1,f2,···fL内有L个函数,意味着每个类别标记对应一个分类函数,并且其中每一个函数fi都是一个线性模型:

在这里,Φ(x)是核函数,示例x被从低维特征空间映射到高维特征空间,wl=[wl,wl]是权重向量,wl和wl与特征空间中的示例x和向量c一一对应.ML-LOC算法的优化目标是:
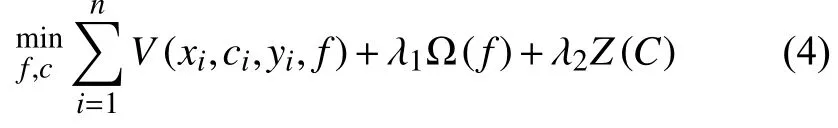
其中,V是损失函数,是基于训练集的数据,具体使用的为hamming loss,其研究的是基于单个标记上的误分次数,其定义如式(5):
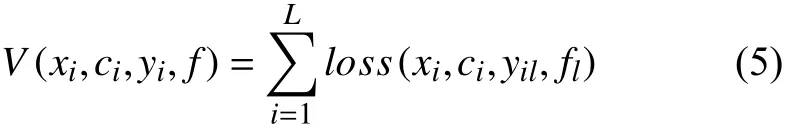
其中,loss(x,c,y,f)=max{0,1−yf([Φ(x),c])}就是SVM中的hamming loss.式(4)中的第二项Ω函数是一个与模型复杂度相关的正则化因子,具体表示如式(6):

式(4)中的Z部分也是一个正则化因子,可以实现对局部标记性编码C的加强,即认为相似的示例具有相似的编码.而λ1、λ2作为平衡因子,作用是使函数的三部分趋于平衡.
使用k-means聚类函数把训练样本集划分成m组{G1,G2,···,Gm},同组的示例拥有同样的标记相关性子集,即Gi中的示例具有相同的标记相关性子集Si.要得到标记相关性过程十分繁琐,Si要通过求Gi中全部示例的标记平均值pj来求得,pj可表示为:
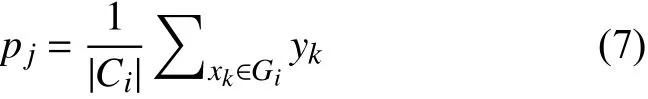
任意一个示例xi,ci指的是相关性子集Si对示例xi的影响系数,则每一个示例xi的LOC编码为ci={ci1,ci2,···,cim}.那么显然,yi与pi的相似度,与Si对示例xi的影响程度成正比,即与cij的值成正比.基于对标记局部相关性研究,我们定义编码上的正则化因子为:
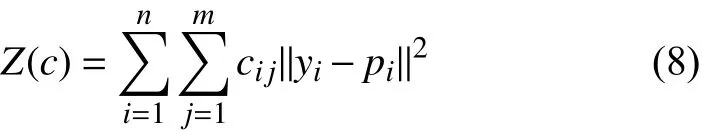
那么最终可以得出ML-LOC算法模型为:
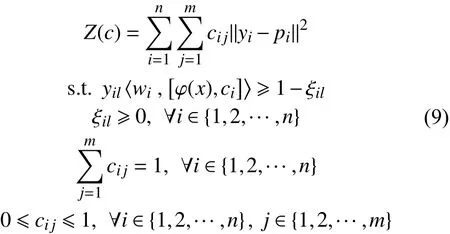
可以看到,cij的取值范围是在[0,1]之间,且LOC编码ci={ci1,ci2,···,cim}中所有值加和值为1.改进的MIMLSVM算法是基于多示例多标记框架提出的模型,通过聚类将每一个包转化为一个示例,将MIML问题简化为了单示例多标记问题.而由于ML-LOC算法就是基于单示例多标记的算法,因此在使用改进的MIMLSVM将问题转化之后,再用ML-LOC算法继续以后的工作.MIMLSVM-LOC算法既是对MIMLSVM算法的改进优化,又考虑到标记局部相关性的特性,使得分类结果更加完善精准[16–18].
2.3 改进算法的流程
MIMLSVM-LOC算法是基于退化策略的多示例多标记SVM算法.该算法首先使用改进的k-medoids聚类算法得到聚类中心Mt(t=1,2,···,k),使用Mt将多示例多标记样本集(Xu,Yu)转化为单示例多标记样本集(Zu,Zu),然后使用ML-LOC算法分类模型继续求解.MIMLSVM-LOC算法的流程如下:
将每一个包看作是原子对象,则示例空间可划分为Γ={Xi|i=1,2,···,m}.
(1)在Γ上使用k-medoids聚类将Γ分为k份,每一份的聚类中心用Mt(t=1,2,···,k)来表示.
1)随机选取k个点Mt(t=1,2,···,k),给聚类中心赋初值.
2)采用公式(2)中的混合Hausdorff 距离mixH(A,B),将剩余示例包Xu∈(Γ−Mt(t=1,2,···,k))分配到各个聚类中去:.
3)重新计算聚类中心.

4)重复2)和3)的过程,直至Mt不变.
(2)得到每个包Xi到聚类中心Mt的Hausdorff值,使用这k个距离作为一个示例,从而将多示例多标记样本集(Xu,Yu)转化为单示例多标记样本集(Zu,Zu),其中,zu=(zu1,zu2,···,zuk).=(dh(Xu,M1),dh(Xu,M2),···,dh(Xu,Mk))
(3)对于标记y∈Y,得到训练集Dy={(zu,φ(zu,y))},使用ML-LOC算法对该多(标记问题进)行求解得到分类函数fy=ML−LOCTrainDy,λ1,λ2,m.
1)通过k-means聚类[8]将Dy分成m组并为求解式(8)完成初始化.
2)使用交替优化方法求解式(9),即固定其中的两个变量不变,优化剩余的一个变量.由于式(9)是下界有界的,它将收敛达到最低限度.
3)建立m个回归模型,用于对未知标记示例求解LOC编码.

(5)使用训练出来的分类函数进行预测:
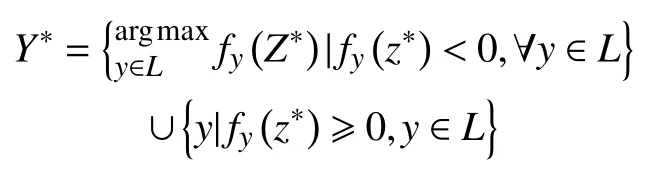
3 实验
本文实验所用电脑配置Windows 7操作系统,Intel酷睿i7处理器,4 G运行内存和128 G固态硬盘,运行环境为Matlab R2014b.
3.1 数据集
本文实验数据来自南京大学周志华等人提供的图像数据集与文本数据集[19].这两个数据集中的样本都是MIML样本,即数据集中的每个样本由多个示例表示其概念,并且由多个标记来标识其所属语义范畴.
图像数据集包含2000个场景图像,每个图像都被分配一组标记.共预定义5个类别,分别是日落、沙漠、树、山以及海洋,其中,单标记样本数目约占77%左右,双标记样本约占22%左右,三标记样本数约占0.75%左右.在该数据集中,每幅图片所对应的MIML样本的示例数为9,每一个示例用一个15维的特征向量表示.
文本数据集主要包括常见的七大类别.该数据集从Reuters中移除无类别或无正文的文本和单类别文本,随机选取部分样本,获得2000个文档.利用滑动窗口技术[14]将每篇文档表示为一个示例包,包中的每个示例对应文档中的大小为50的滑动窗口所包围的一段文本片段.包中的示例采取基于词频的词袋模型进行表示,利用降维的方式,将词频为前2%的词汇予以保留,最终包中的所有示例都可以用243维的特征向量进行表示.表1总结了图像样本集(Scene)和文本样本集(Reuters)的特征.

表1 样本集特征
3.2 评价指标
本文采用多示例多标记领域的五个评价指标hamming loss、one-error、coverage、ranking loss和average precision进行评价.设数据集S={(x1,y1),(x2,y2),···,(xn,yn)}.
(1)hamming loss,定义如下:
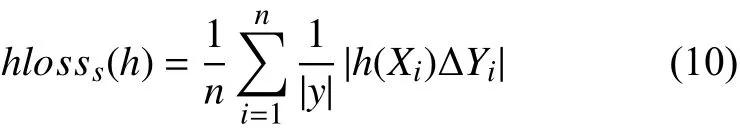
其中,∆表示两个集合之间的对称差,hamming loss评价的是样本在标记相同上的分类误差值,结果值小,则说明算法表现更好.
(2)one-error,定义如下:

其评价的主要内容是,统计所考察样本的标记序列中,最前端的标记不属于样本集合的情况,同样的,结果值小说明算法表现更优.
(3)coverage,定义如下:

coverage用于评价样本的标记集中,覆盖某样本所有标记所用的搜索深度,结果值小,对应的算法效果更优.
(4)ranking loss,定义如下:
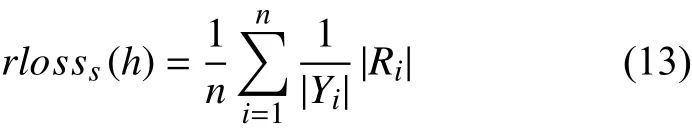
其评价的内容是标记序列发生误排序的情况,同以上四种标准,结果值小则算法效果越好.
(5)average precision,定义如下:

3.3 实验算法
本文将提出的MIMLSVM-LOC算法与MIMLSVM+算法、MIMLBOOST算法和MIMLSVM算法进行对比.这三个算法都是基于退化策略的算法,其中,MIMLSVM算法和MIMLSVM+算法将MIML问题转化为单示例多标记问题,即为每一个标记建立一个SVM分类器进行求解,MIMLBOOST算法将MIML问题多示例简化成单标记问题,最终利用多示例学习算法MIBOOSTING[7]解决问题.
MIMLBOOST和MIMLSVM算法的参数根据文献[10]的实验设置为它们的最佳值,即将MIMLBOOST的boosting rounds的值设为25,MIMLSVM的高斯核为?γ=0.22,聚类个数k为训练个数的20%.MIMLSVM+的核函数的两个参数分别为γ1=10−5和γ2=10−2.根据文献[3]中对ML-LOC算法的实验,设置λ1=1、λ2=2、m=5.实验采用3.1小节所介绍的数据集,采用10折交叉验证的方式,重复10次实验之后求得实验的平均值及方差.
3.4 实验结果
表2和表3分别显示了四种不同的MIML算法在图像数据集、文本数据集上的实验数据值.在表3和表4中,黑体部分是MIMLSVM-LOC算法的实验结果.从表中数据可以分析,MIMLSVM算法的性能总体上优于MIMLBOOST算法,这是由于训练集中具有两个以上类别标记的样本较少,使得MIMLBOOST在从MIML样本简化为多示例单标记样本的过程中出现类别不平衡的问题,影响了分类效果.MIMLSVM+算法的性能总体上优于MIMLSVM算法,MIMLSVM-LOC算法的性能总体上优于MIMLSVM+算法,可见,增加了标记之间的关联关系可以提高分类的效果.因此,MIMLSVM-LOC算法在两种多示例多标记学习任务中的总体表现要优于其它MIML分类算法.

表2 场景样本集上实验结果

表3 文本样本集上实验结果

表4 各算法在两个数据集上的训练时间
表4列举了四种算法在两个数据集上所用时间值观察表4可知,黑体部分MIMLSVM-LOC算法耗时比MIMLSVM+算法略多,与MIMLSVM算法基本持平,远远小于MIMLBOOST算法,因此MIMLSVM+算法耗时最短,MIMLSVM-LOC和MIMLSVM算法总体耗时相差不大,但是分类效果却优于MIMLSVM算法.而MIMLBOOST在文本样本集耗时虽较图像样本集有所减少,但仍远远高于其他算法.综上所述,MIMLSVMLOC算法在图像和文本数据集上,整体表现优异,比较适用于解决多示例多标记问题.
4 总结
针对退化策略中具有的标记关联信息丢失的问题,本文提出了改进的MIMLSVM算法并将改进的算法与ML-LOC算法相结合,提出MIMLSVM-LOC.该算法采用混合Hausdorff距离进行聚类并借鉴ML-LOC算法的思想,将示例样本集划分成若干组,并且同一组内的示例具有一致的标记相关性子集,减少过大的输出空间.改进后的MIMLSVM-LOC算法,不仅考虑到示例的几何关系同时也考虑到了标记的作用信息,使分类更加精准高效,同时能够精简输出量,优化空间存储.
实验数据说明MIMLSVM-LOC算法的表现优于其它MIML分类算法,比较适合应用于多示例多标记问题.但是,提出的方法仍存在待改进的地方:
(1)参数取值问题.本文中,参数选取的值多为经验参数,缺乏理论的指导.参数的取值对于实验结果具有一定的影响,因此,如何使参数取值更加恰当是一个亟待解决的问题.
(2)核函数选取问题.本文实验中选用多示例核函数,在实际应用中,由于样本的不同,核函数的选取也会影响实验的结果.因此,如何动态选取核函数,仍是值得研究的方向.
