基于GRU型循环神经网络的随机域名检测①
2018-08-17陈立国张跃冬耿光刚延志伟
陈立国,张跃冬,耿光刚,延志伟
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院大学,北京 100049)
3(中国互联网络信息中心,北京 100190)
随机域名是指由随机域名算法生成的域名,在针对域名系统[1]发起的分布式拒绝服务攻击中被普遍使用,随机域名检测是过滤拒绝服务攻击流量的前提.随机域名的检测工作主要基于随机域名的随机性特点来进行.随机域名由随机域名算法生成,各字符出现的概率相同且字符之间没有依赖关系.基于随机域名的随机性特点,现有的随机域名检测方法主要包括基于域名分布相似度的检测方法与基于机器学习的检测方法两类,这两类方法将在第1章中详细介绍.
随机域名检测是域名系统DDoS流量过滤、僵尸网络通信检测等域名安全任务的基础工作,在检测实时性、检测准确率等方面都有较高的要求.传统的随机域名检测方法检测准确率较低,误报率较高,且多数方法在流量过滤等任务中不能满足实时性的需求.
近年来,深度学习在图像、语音、自然语言处理等领域都取得了重大突破[2,3],基于深度学习的应用越来越多[4–6],应用深度学习的模型解决传统研究领域的问题也成为了研究的热点.本文将GRU(Gated Recurrent Unit)型循环神经网络模型[7]应用于随机域名的检测工作中,经过算法生成数据与真实场景数据的实验验证,该模型相比传统检测模型拥有更好的检测性能,且检测过程中不需要对域名提取特征.
1 传统的随机域名检测方法
目前,已有的随机域名检测方法主要分为两类,一类是基于域名分布相似度的检测方法,另一类是基于机器学习的检测方法.
1.1 基于域名分布相似度的检测方法
Sandeep等[8]提出了一种基于分布相似度判定域名是否遭受随机域名攻击的方法.
首先,对于给定的单一域名d,该方法生成其对应的n-gram,如式(1),其中i∈{0,1,···,len(d)−n},n≥1.len(d)为域名d包含的字符数,n在该文章中取值为1,2.
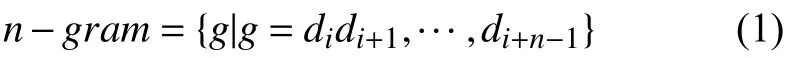
然后,该方法分别统计正常域名与随机域名的ngram分布.得到上述两种分布后,文章选取了三种分布相似度的评价指标:相对熵、杰卡德距离与编辑距离.最后对每一个IP地址或权威域名计算其所对应域名的n-gram分布分别与正常域名n-gram分布和随机域名n-gram分布的相似度,根据相似度的大小判断当前IP地址或权威域名是否遭受了随机域名攻击.
文章中验证了n的不同取值以及不同分布相似度时实验的效果.实验结果显示,当n取1,相似度选用相对熵时,达到100%检出率,2.5%假阳率,实验结果最优.
该方法优势是实现简单,仅需要对比待检测的权威域名或IP地址对应的域名n-gram分布与正常域名、随机域名的分布计算相似度即可.但是单一域名由于字符数有限,字符分布不具有统计特性,基于分布相似度的方法难以做出类别判断.
1.2 基于机器学习的检测方法
基于机器学习的检测方法将随机域名检测作为二分类任务处理,通过最小化代价函数的方式提升检测准确率.这类检测方法由于具有检出率高、误报率小、可实时检测等优势,是近年来的研究热点.
Davuth等[9]提出了一种基于支持向量机的随机域名检测方法.该方法将域名的bi-gram作为特征,通过人工阈值的方式过滤出现频率较低的bi-gram,实现特征选择.文章中采用支持向量机分类器.在第3章中,本文将该方法与基于GRU型循环神经网络的方法进行了对比实验.
王红凯等[10]提出了一种基于随机森林的随机域名检测方法.该方法通过人工提取域名特征来构建随机森林模型训练分类,实现对随机域名的检测.但人工特征的构造过程较为繁琐,而且由于所使用的统计特征过多,特征抽取过程也较为耗时.
章思宇[11]提出了一种基于DNS图挖掘的随机域名检测算法,该方法根据DNS查询日志将域名与主机的集合构建成图模型,然后应用置信传播算法进行声望推断,据此进行随机域名的检测.该方法不仅可以检测出随机域名,也可以分析出网络中的控制服务器和受害主机,但检测准确率较低,且检测实时性较差.
2 基于GRU型循环神经网络的随机域名检测方法
近年来,深度循环神经网络模型在众多自然语言处理的任务中表现出色[7,12,13],由于常规域名通常也保留一定的语言特性[14],注册域名中也通常包含汉语拼音、单词等子串.因此,本文尝试将神经网络模型应用在随机域名的检测工作中,通过挖掘域名语言特性区分常规域名与随机域名.
2.1 域名向量化
由于循环神经网络模型接受的输入x为定长的向量,而域名本身为字符串,因此需要引入域名向量化步骤,将字符串转换成循环神经网络输入.域名向量化过程首先统计在所有域名中出现的字符集合,假设该集合中字符数为n,则将域名中的每个字符编码成长度为n的one-hot向量,最后将该域名中的所有字符对应的one-hot向量按照各个字符在域名中的顺序拼接得到循环神经网络的输入x.
2.2 GRU型循环神经网络结构
GRU型神经网络是一种循环神经网络,隐层节点相互连接,呈现出循环的特性.不同的是该网络隐层节点内部结构并非单一激活函数,而是采用GRU结构.图1为GRU内部结构示意图,其中ht−1为t–1时刻隐藏层输出,Xt为t时刻输入,ht为t时刻隐藏层输出,rt表示重置门,zt表示更新门,h˜t表示t时刻隐层节点的候选值,其他元素操作如右侧图例所示,用公式描述图1如下:


图1 GRU内部结构
实验所采用的循环神经网络由输入层、隐含层、全连接层和输出层组成,其结构如图2所示.其中l为域名的截断长度,当域名长度超出l则对域名进行截断,当域名长度小于l则在域名向量后拼接零向量,直到域名向量长度达到l.xt为当前输入域名中的第t个字符,采用one-hot编码.ht为当前时刻第t个字符对应的隐含状态.drop_out为随机丢弃层,用于防止网络的过拟合[15],经过实验测试,当随机丢弃概率为0.5时,训练得到的模型分类性能最优.full_connected为全连接层,全连接层的节点数设置为32.Y为输出的类别,取值为0或1,分别表示当前输入是否为随机域名.实验中,模型的超参数设置将在3.2节中详细介绍.
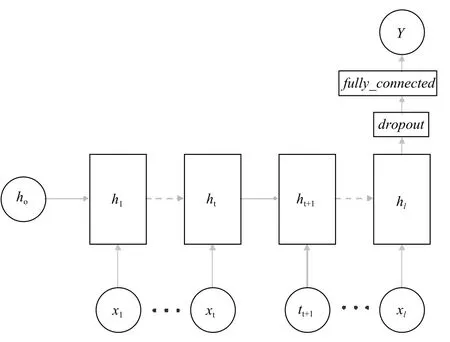
图2 GRU型循环神经网络随机域名检测模型结构
传统方法为了提升随机域名的检测准确率,往往会抽取一定维度的域名特征[10],统计当前一段时间内被请求域名的信息,当DNS系统遭受DDoS攻击后,解析请求量急速上升,特征的提取需要更多的计算资源,为了保证攻击流量过滤的实时性,需要减少特征提取的时间,降低特征提取所需的算力成本.而GRU型循环神经网络随机域名检测模型是一个端到端的模型,输入为域名向量,输出为该域名对应的类别.相比传统方法,该模型不需要对该域名抽取统计特征,节省了特征抽取的算力成本和时间成本,使得模型能够及时对当前域名的类别做出判断并设置防火墙规则,从而能够满足大规模攻击流量过滤任务的实时性需求.
相比于使用n-gram特征的方法[9],GRU型神经网络的随机域名检测方法检测性能更好,准确率更高,在相同的实验环境下,该模型拥有更低的误报率和漏报率.具体实验结果将在3.3节中详细介绍.
3 实验分析
3.1 实验数据
本文中所使用的实验数据包含算法生成数据与真实场景数据两部分.
算法生成数据中,负类样本由5种著名僵尸网络的随机域名算法生成:newGOZ[16]、Ramnit[17]、Shiotob[18]、Symmni[19]、Banjori[20].负类样本共计50万条,每种随机算法产生的随机域名占比20%,且各个算法产生的随机域名在训练集中服从均匀分布.正类样本为.cn在正常服务状态下被查询的域名经过随机采样、反向查询过滤得到的域名集合,共计50万条.

图3 算法生成数据示例
真实场景数据来自.cn域名服务在2015年5月12日遭受的一次随机子域名攻击事件.负类样本为遭受攻击时被攻击域名的子域名去除已注册子域名得到的域名集合,共计50万条.正类样本为.cn在正常服务状态下被查询的域名经过随机采样和过滤反向查询得到的域名集合,共计50万条.正负类样本合计100万条,数据格式与算法生成数据相同.
3.2 实验设置与超参数
在随机域名检测任务中,模型的分类性能是评价模型优劣的首要考虑因素,实验的第一部分将考察模型的分类性能.而神经网络模型通常存在容易过拟合[21]、收敛难度大等缺陷,实验的第二部分将会比较逻辑回归模型与基于GRU型神经网络模型的收敛过程,验证.
在分类性能实验中,本文分别实现了基于逻辑回归与基于支持向量机的随机域名检测模型,并分别使用算法生成数据和真实场景数据训练、测试两种模型.在实验中,训练集占80%,验证集占10%,测试集占10%.使用5种评估指标来评估模型效果,评估结果在3.3小节中详细描述.
在收敛过程实验中,本文将对比GRU型循环神经网络检测模型与基于逻辑回归的检测模型在每轮迭代过程中的AUC,比较两种模型的收敛过程,为了更明显的效果对比,两种模型的学习率都调整为分类性能实验的0.2倍.
GRU型循环神经网络检测模型的主要超参数包含:隐层节点个数l,随机丢弃概率p_drop,全连接层节点个数m,学习率a,激活函数f,学习算法la,损失函数loss等.基于逻辑回归的检测模型主要超参数包含:学习率a,正则项penalty,正则化强度C.基于支持向量机的n-gram检测模型主要超参数有:核函数kernel,惩罚因子C.两次实验的超参数如表1所示.
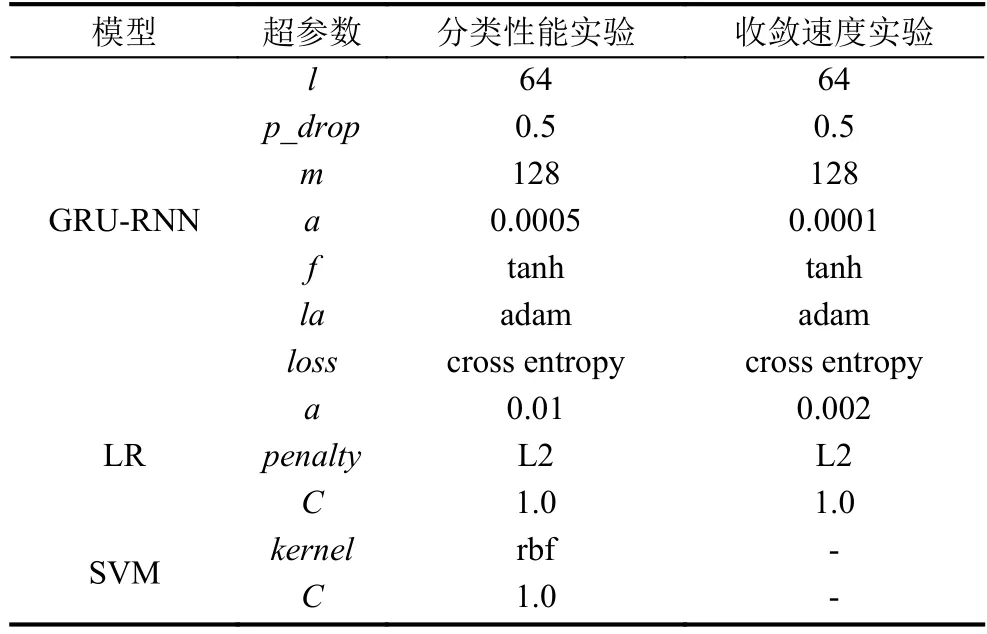
表1 各模型超参数设置
3.3 实验结果分析
本文提出和实现了基于GRU型循环神经网络的随机域名检测模型,为了对比传统模型的检测性能,分别实现了基于n-gram特征的逻辑回归、支持向量机随机域名检测模型,以上模型的分类性能在算法生成数据上的表现如表2所示,在真实数据上的分类性能如表3所示.根据实验可以得出,基于bi-gram特征的模型分类性能普遍优于基于uni-gram特征的模型,支持向量机模型普遍优于逻辑回归,而GRU型循环神经网络模型在各项分类性能中都表现优异,领先前两者.
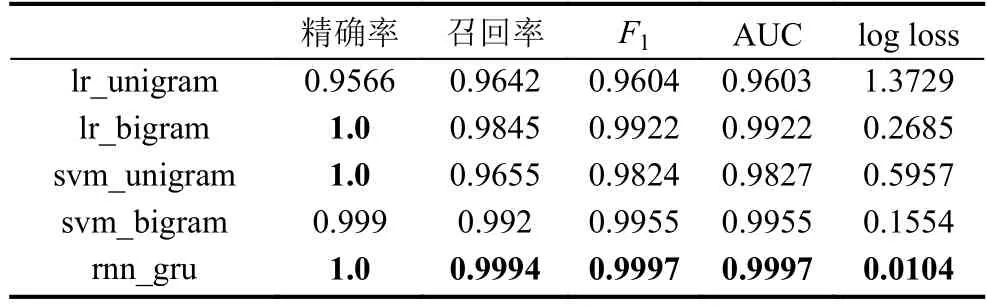
表2 各模型在算法生成数据上的分类性能
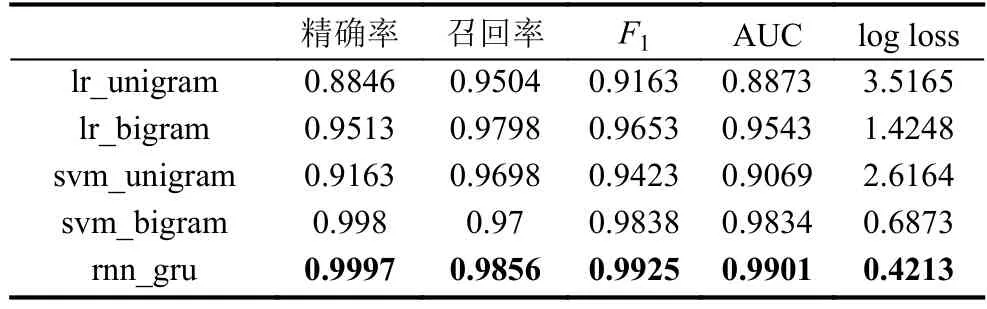
表3 各模型在真实场景数据上的分类性能
收敛过程实验结果如图4所示,横轴为模型迭代次数,纵轴为算法生成数据上的每一轮迭代后各模型的AUC.由图中可以看出,基于GRU型循环神经网络的检测模型收敛速度与逻辑回归模型相当且收敛过程较为平稳.
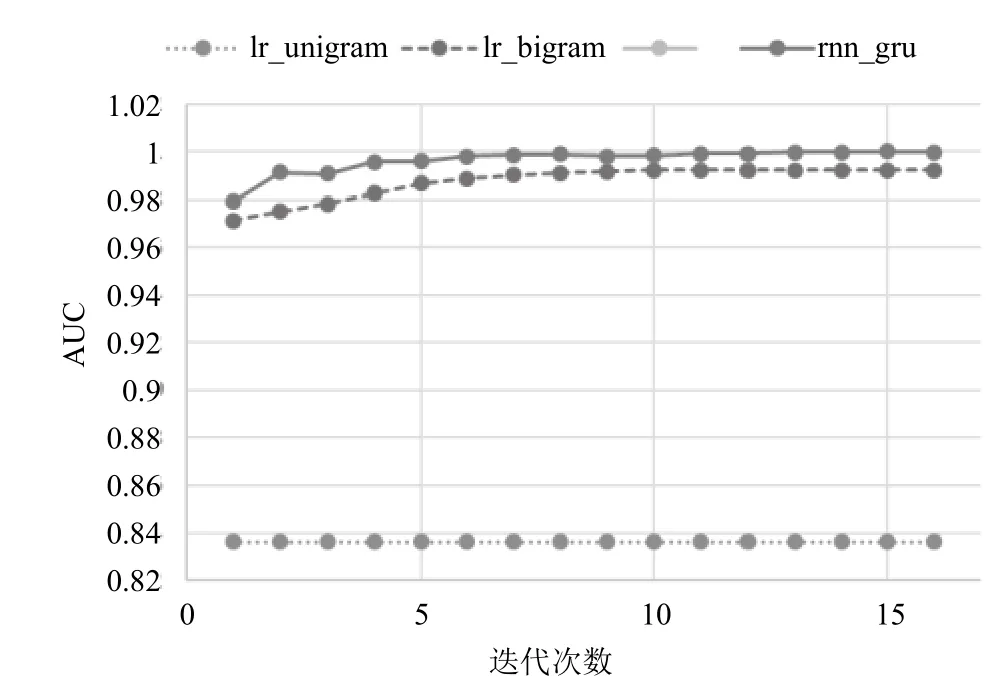
图4 GRU型循环神经网络检测模型与逻辑回归检测模型收敛过程比较
4 结论与展望
本文的主要工作是将GRU型循环神经网络应用到随机域名的检测工作中,提出和实现了基于GRU型循环神经网络的随机域名检测方法,并将该方法与传统检测方法进行对比分析.经过实验验证,该模型在算法生成数据和真实场景数据上都相比传统方法表现出色,模型收敛速度快,收敛过程平稳.但目前该模型的检测对象仅限于随机域名,对于可能包含语言特性的恶意域名检测效果尚未得到验证.在接下来的工作中,将研究如何将现有检测模型融入注册、解析等非语言本身的特征,使得融合后的模型能够应对更加复杂的应用场景.
