IPI:灵活高效的对象代理数据库索引结构*
2018-08-15李宇珺彭智勇彭煜玮
李宇珺,彭智勇,吴 瑕,兰 海,彭煜玮
武汉大学 计算机学院,武汉 430072
1 引言
面向对象模型解决了传统关系模型难以建模复杂数据的问题,但对象的封装性使得其对象难以分割和重组,从而不具有关系模型的柔软性。针对上述问题,对象代理模型(object deputy model,ODM)应运而生[1],它兼具关系模型的柔软性和面向对象模型的建模能力。近年来,ODM被广泛应用于数据仓库[2]、生物数据管理[3]、地理信息系统[4]、科学工作流[5]和不确定数据管理[6]等领域。对象代理数据库(object deputy database,ODDB)管理系统图腾[7](Totem)已基于ODM开发完成。它在继承了面向对象数据库诸多优点(如直接建模复杂对象等)的基础上,使用代理对象增强了对象的柔软性,允许对已有对象进行分解、组合和扩充,比面向对象数据库具有更柔软的建模能力。
ODDB中的每个对象和其每一个源对象或代理对象都被一个双向指针链接在一起,这类指针称为双向指针。跨类查询作为ODDB的主要查询功能之一,是指基于对象间的双向指针链接,从某个类的对象出发,沿着类路径到达另一个与其存在直接或间接代理关系的类,并对该类中关联对象进行的查询。跨类查询是由路径表达式(path expression,PE)实现的[8],因此优化PE的计算效率对提升ODDB的性能有重大影响。
本文针对ODDB的PE计算提出了一种索引结构——倒排路径索引(inverted path index,IPI),并基于IPI设计实现了计算PE的方法。IPI的核心思想是物化对象间的代理关系,并允许在谓词条件上建立索引以过滤不满足条件的对象。基于IPI的PE计算方法,能灵活用于任意PE,同时避免计算中冗余的对象遍历,有效地减少PE的计算开销。总体来说,本文的主要贡献如下:(1)提出一种新的针对ODDB的索引结构(IPI),支持任意路径/带谓词条件的PE计算,以极小的效率代价为跨类查询提供更多的灵活性。(2)提出使用IPI计算PE的IPI索引方法以及维护IPI的方法。(3)通过实验证明了所提出的IPI索引方法的有效性。
本文组织结构如下:第2章介绍相关工作;第3章给出ODDB中PE的基础知识;第4章介绍倒排路径索引IPI,并提出使用IPI计算PE的IPI索引方法以及维护IPI的方法;第5章讨论IPI的灵活性;第6章通过实验证明提出的IPI索引方法的有效性;第7章进行总结和展望。
2 相关工作
ODDB中由对象间的代理关系构成的网状结构可以比作一个图。图数据库具有管理超大规模图的能力[9],故其可达性问题为PE计算提供了一种解决方案。文献[10]提出Tree-Based索引来解决带标签图的可达性问题。文献[11]提出Top-Chain来解决时序图的可达性问题。然而,PE计算和图数据库的可达性问题之间存在一个本质的区别:前者是在一个非常大的图中确定两个结点之间是否存在由边组成的路径;后者则意味着在许多由对象构成的小图中迭代解决可达性问题。因此,解决图数据库可达性问题的方法并不适用于ODDB的PE计算。
PE的概念并不是ODDB所特有,早在XML(extensible markup language)中它就已经存在,用于访问XML的嵌套文档结构。目前XML针对PE计算的基本索引方法有:路径分解法[12]和树遍历法[13]。路径分解法将复杂PE分解为简单PE依次进行计算,再把计算结果连接起来,核心思想是分解再连接。由于ODDB中PE各层的连接关系包含了双方对象实例间的所有代理关系,连接的代价过大,路径分解法的思想并不适用于ODDB的PE计算。树遍历法则采用自顶向下或自底向上的方式遍历文档树,该方法需要遍历某元素通往叶子节点的所有路径,其思想类似于ODDB的指针跟踪算法(pointer tracker,PT)[14-15]。
PT是计算ODDB中PE的基本方法:首先沿着PE的导航路径进行对象遍历,检索满足PE各层所定义谓词条件的路径实例,然后获取这些实例上的终点对象,最后由PE的目标表达式投影运算得出结果。显然,对象遍历是计算中最耗时的部分,它需要遍历起点类通往终点类的所有路径实例,频繁的I/O操作降低了计算效率。目前针对ODDB中PE计算的优化方法还比较少。文献[14]提出的对象代理路径索引(object deputy path index,ODPI)针对特定的路径建立索引,存储满足该路径的所有路径实例,减少了对象遍历的时间,但它不适用于中间类带谓词条件的PE。路径导航索引(path navigation index,PNI)[15]解决了该问题,它基于物化的路径实例提供了关联检索,以支持带谓词条件的PE计算。然而,由于每个ODPI/PNI索引都仅服务于其对应的固定路径,计算时缺乏灵活性。若待查询PE所依赖的路径上没有建立索引,那ODPI/PNI索引对计算是无效的,此时只能用PT方法(即不使用索引)来计算该PE。
针对上述问题,本文提出的倒排路径索引,物化了对象间的代理关系,不仅可以灵活用于任意PE,还能有效减少计算开销。
3 基本概念
ODM的基本概念包括源类、代理类、源对象和代理对象等,首先简单描述这些概念,其详细定义参见文献[1],并在此基础上给出ODDB中PE的相关定义和符号表。
在面向对象模型中,所有真实世界的实体都被抽象为一个对象(Object),具有相同属性的对象构成一个类(Class)。在逻辑层面,对象和类类似于关系数据模型中的元组和表,ODM同样具有对象和类的概念。在ODM中,不存在父类的类称为源类,其包含的对象称为源对象;而存在父类的类则称为代理类,它的对象实例称为代理对象。
定义1(直接/间接代理关系)对任意两个类Ci和Cj(i<j),若Ci是Cj的源类或代理类,则Ci和Cj之间存在直接代理关系。给定一系列类{Ci,Ci+1,…,Cj-1,Cj},若对任意k∈[i,j)都满足Ck和Ck+1之间存在直接代理关系,则Ci和Cj之间存在间接代理关系。同理可得对象间的直接/间接代理关系。
定义2(类网/对象网)由类之间的代理关系构成的网状结构称为类网。其中节点表示类,边表示两个节点间的直接代理关系。同理,由对象之间的代理关系构成的网状结构称为对象网。
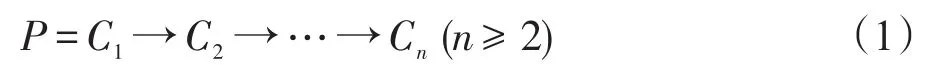
定义3(路径)给定类网CN,式(1)中的路径P是类网CN的一条路径,当且仅当:(1)Ci∈CN(1≤i≤n);(2)对任意i∈[1,n)都满足Ci和Ci+1之间存在直接代理关系。其中C1和Cn分别指起点类和终点类,路径P中的其他类则指中间类。
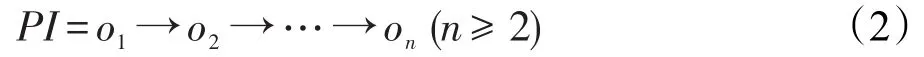
定义4(路径实例)给定式(1)的路径P,式(2)中的由n个对象组成的对象序列PI称为P的一个实例,当且仅当:(1)oi是Ci的一个实例 (1≤i≤n);(2)oi与oi+1之间存在直接代理关系 (1≤i<n)。其中o1为起点对象,on为终点对象。
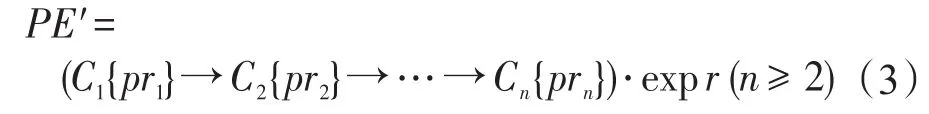
定义5(PE)给定式(1)的路径P,式(3)中的PE′是在P上定义的PE当且仅当:(1)pri是定义在Ci上的谓词条件(pri可为空,1≤i≤n);(2)expr是由Cn的属性和常量通过算术或逻辑运算符组成的表达式。其中C1{pr1}→C2{pr2}→…→Cn{prn}称为PE′的导航路径,expr则称为PE的目标表达式。
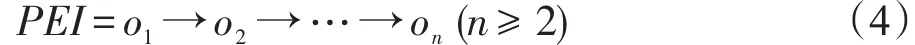
定义6(PE实例)给定式(3)的PE′,式(4)中的由n个对象组成的对象序列PEI称为PE′的一个实例当且仅当:(1)oi是Ci的一个实例 (1≤i≤n);(2)oi与oi+1之间存在直接代理关系 (1≤i<n);(3)oi满足定义于Ci上的pri(1≤i≤n)。
定义7(跨类查询)给定式(3)的PE′,针对PE′的跨类查询表示从起点类C1的对象出发,沿着PE′的导航路径到达终点类Cn,对PE′所有PE实例的终点对象进行查询。
图1给出了一个教学管理数据库的模式,由上述定义可知该数据库模式是一个类网,而Course→Cou_Stu→Student是该类网上的一条路径,(Course{cid=“1”}→Cou_Stu→Student).sid是定义在该路径上的一个PE,其中Course是起点类,Student是终点类,{cid=“1”}是定义在Student类上的谓词条件。
表1总结了几个本文经常出现的符号和术语。
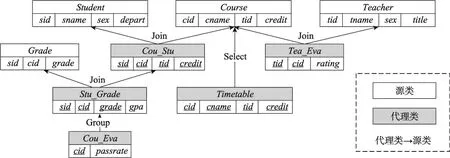
Fig.1 Schema of teaching management database图1 教学管理数据库模式
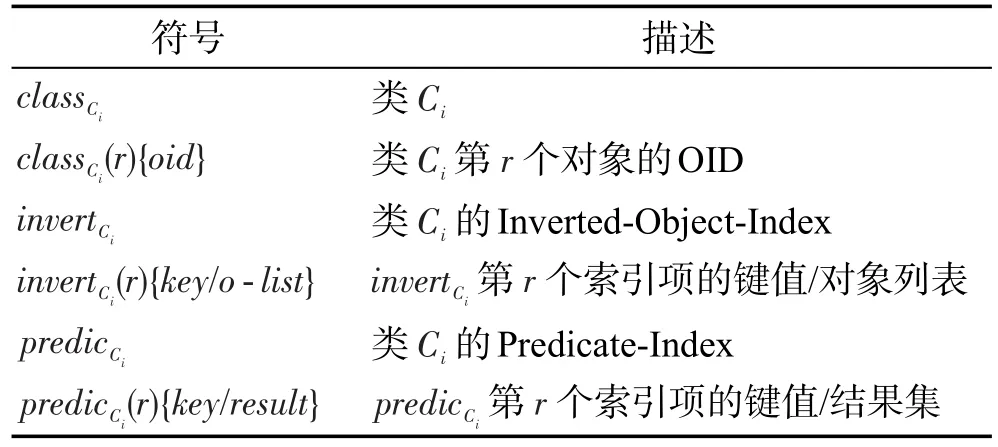
Table 1 Symbol table表1 符号表
4 倒排路径索引IPI
本章介绍一种灵活高效的索引结构——倒排路径索引(IPI)。IPI建立在类之上,由Inverted-Object-Index和Predicate-Index组成。前者存储对象间的代理关系;后者则辅助它计算定义于该类的谓词条件。IPI支持任意路径和带谓词条件的PE计算,并能有效减少计算开销。
4.1 索引的结构
对于一个类网中的每个类,Inverted-Object-Index基于对象间的双向指针使用倒排索引来存储与该类关联的所有代理关系,其每个索引项对应该类的一个对象,映射所有与之存在直接或间接代理关系的对象。每个代理关系对应一个路径实例,因为ODM中对象间的代理关系不能出现环[16],同一对象网中的任意两个对象间有且仅有一条路径连通。因此,Inverted-Object-Index存储的每条路径实例的终点对象可以唯一地标识该路径实例。
Inverted-Object-Index是一个存储(key,object list)对集合的索引结构,其中“key”是键值,由对象的唯一标识符(OID)表示,而“object list”(对象列表)是一组与“key”存在直接或间接代理关系的对象,每个对象由“所属类的OID:对象OID”表示。如图2所示,Inverted-Object-Index包含一个构建在“key”上的BTree索引(Key Tree),其内部节点与普通B-Tree索引一样,而叶子节点中索引项的指针则指向“ObjectList”或“Object Tree”的根页面。若某个“key”的与之存在代理关系的对象数目较多,则在其对象列表(即“object list”)上创建一个B-Tree结构(Object Tree)以加快查找速度。
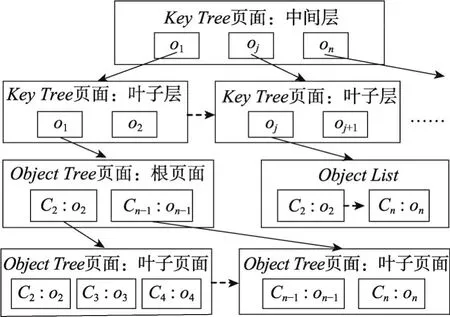
Fig.2 Index structure of Inverted-Object-Index图2 Inverted-Object-Index的索引结构
第2章提到PT方法在对象遍历时,对每个对象都要进行两步操作:(1)判断是否匹配路径;(2)判断是否满足定义于该类的谓词条件。通过Inverted-Object-Index,能快速找到该类中匹配路径的对象实例,并获取其所在的路径实例上的终点对象,但无法判断这些路径实例是否满足可能定义于PE的谓词条件。Predicate-Index是针对谓词条件计算设计的索引,它通过OID将满足谓词条件的对象映射到Inverted-Object-Index的“key”上,辅助Inverted-Object-Index过滤不满足条件的对象。Predicate-Index是一个存储(predicate,result)对集合的索引结构,其中键值“predi⁃cate”表示谓词条件,而“result”(结果集)是一组满足“predicate”的对象。Predicate-Index包含一个构建在“predicate”上的B-Tree索引,叶子节点的索引项指针指向对应结果集(即“result”)。
4.2 索引的创建
算法1和算法2描述了IPI创建的过程,包括Inverted-Object-Index和Predicate-Index。
算法1Inverted-Object-Index的创建

算法1描述了Inverted-Object-Index的创建过程,目标类的每个对象对应其一个索引项,包括键值和对象列表。需要顺序扫描目标类的对象,对每个对象进行如下操作(第2到3行代码):根据OID填充键值,再把所有与键值存在代理关系的对象以“类OID:对象OID”的形式存入对象列表。目标类扫描完毕后,其Inverted-Object-Index也创建完成。
算法2Predicate-Index的创建

算法2描述了Predicate-Index中一个索引项的创建过程,每个谓词条件对应一个索引项,包括键值和结果集。第2行代码根据谓词条件填充键值。结果集包含所有满足键值的对象,需要顺序扫描目标类的对象把满足条件的OID存入结果集(第3到7行代码)。Predicate-Index没有规定行数,可为空,按查询需求把频繁查询的谓词条件创建完毕即可。
4.3 索引的使用
创建完IPI索引,接下来介绍使用该索引计算PE的IPI索引方法。对于一个给定PE,使用IPI计算的流程按如下步骤进行:
(1)进行谓词条件检查和PE划分。首先需要判断PE是否带谓词条件。如果PE带谓词条件,就把PE按谓词条件所在类进行划分;否则就直接在起点类的Inverted-Object-Index中进行路径匹配。
(2)谓词条件计算。为了计算定义于某特定类Ci的谓词条件pred,首先需要在predicCi中扫描pred,若找到了,就把对应的结果集保存在该类的一个临时的谓词条件结果集prCi();否则,需要重新扫描classCi,把满足pred的对象OID加入prCi()。
(3)路径匹配。若PE带谓词条件,就依次从prCi()中获取OID,分别找到它们在invertCi中对应的索引项。对每个索引项,判断其对象列表中是否包括了PE的所有类,若是则说明该索引项能够匹配路径,获取对象列表中终点对象OID,加入该类的一个临时的终点对象集resCi()。若PE不带谓词条件,则顺序扫描起点类的Inverted-Object-Index,对其每个索引项的操作和带谓词条件的情况相同。
(4)合并结果。若PE带谓词条件,取所有非空resCi()(1≤i≤n)的交集为最终终点对象集;否则起点类终点对象集resC1()即最终终点对象集。
(5)根据目标表达式对最终终点对象集进行投影运算得到并返回结果对象。
4.4 索引的维护
IPI和传统索引一样依赖于数据库建立。若数据库被修改,IPI也需要被维护。数据库可能的修改包括:创建对象和类,删除对象和类以及修改对象的属性值。由于创建/删除一个类相当于插入/删除该类包含的多个对象,本节主要介绍针对插入/删除对象操作和修改对象属性值操作的IPI索引维护。为方便讨论维护时间的复杂度,假设invertCi的平均索引项数目为n,predicCi的平均索引项数目为m,m<<n。
(1)插入/删除对象。当一个对象oi被插入/删除需要维护3处:①在invertCi中添加/删除记录oi;②在predicCi中找到oi所满足的谓词条件,分别在对应结果集中添加/删除记录oi;③对所有与oi存在代理关系的对象(假设数目为常数k),在其各自Inverted-Object-Index对应索引项的对象列表中添加/删除记录oi。其中,①相当于在invertCi二叉树中查找目标对象,平均维护时间为lbn+1;②相当于顺序查找不定量的谓词条件,平均维护时间为m+m/2;③同①,相当于在k个二叉树中分别查找目标对象,平均维护时间为k×(lbn+1)。综上该操作的维护时间如式(5)所示,时间复杂度为O(lbn)。
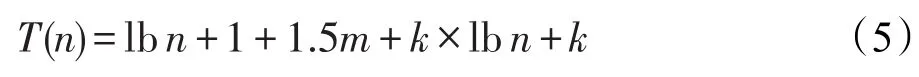
(2)修改对象的属性值。对象属性值的修改不改变对象间的双向指针,因此invertCi不需要被维护。当一个对象oi的属性值被修改可能导致两种情况:①一个对象修改前不满足某谓词条件但修改后满足;②一个对象修改前满足某谓词条件但修改后不满足。它们都会影响predicCi,具体维护操作如下:首先在predicCi中扫描定义于该属性的谓词条件,重新判断oi是否满足这些谓词条件,然后根据判断结果在它们的结果集中添加/删除oi的记录。同(1)操作中的②,该操作的维护时间T(n)=1.5m,时间复杂度为O(1)。
插入/删除对象的操作需维护同一类网中大多类的Inverted-Object-Index和被修改类的Predicate-Index;而修改对象属性值的操作也需要维护被修改类的Predicate-Index。执行多次的单步维护操作可能导致冗余维护,降低了维护效率。因此,设计了op_update(表2)和op_maintain(表3)两个系统表来支持批量维护操作。系统表op_update存储对数据库的修改操作,op_maintain存储由修改操作转换而成的针对各个类的维护指令。批量维护操作并不是当数据库被修改一次就立即维护IPI,而是将修改操作存入系统表op_update中,当操作数超过一定阈值或所有修改操作都已读入时,就根据缓存的修改操作来维护IPI,具体维护步骤如下:
首先,对系统表op_update中所有操作进行抵消和合并,该功能由记录修改操作执行时间的time来支持:(1)若一个插入操作和一个删除操作作用于同一对象,且前者执行时间比后者早,即插入一个对象后再将它删除,那么这两个操作的作用会相互抵消。在该情况下,这两个操作会被清除。(2)若有两个或两个以上的属性值修改操作对同一对象的同一属性先后进行修改,那么执行时间最晚的一个修改操作就会覆盖先前的。在该情况下,这些修改操作会被合并为时间最新的一条属性值修改操作。

Table 2 Attributes of op_update表2 系统表op_update的属性
接下来,把系统表op_update中的操作转换成以类为单位的维护指令,填充到系统表op_maintain中。如表3所示,opindex决定具体要对哪部分索引进行维护。若optype为3,则opindex只能取2,因属性值修改时不需要维护Inverted-Object-Index,此时position表示被修改属性的列号,value表示修改后的属性值。属性position的另一作用是当optype为1或2,opindex为1时,表示维护操作作用的对象,分为两种情况:(1)position等于opoid,即维护的是被修改对象本身,相当于插入/删除对象时维护的第i点。(2)position表示所属于classoid并且与opoid存在代理关系的对象,相当于插入/删除对象时维护的第③点。在第(1)种情况中,构建插入对象在Inverted-Object-Index的索引项时需要对象列表的信息,由表3的value属性给出:如果opoid有源对象,value值就是其源对象的OID与源对象的对象列表的并集;否则,value值为空。
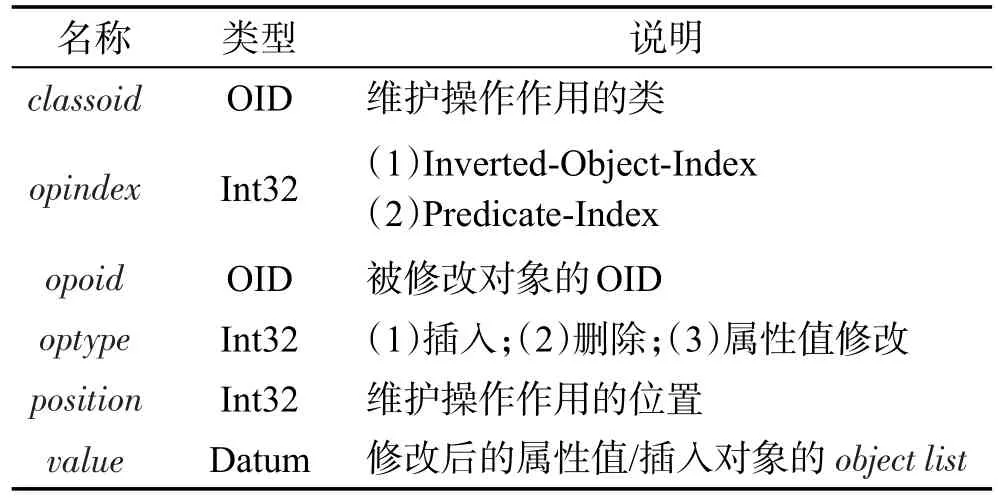
Table 3 Attributes of op_maintain表3 系统表op_maintain的属性
最后,根据属性classoid把系统表op_maintain中的维护指令划分到对应类,逐个类进行索引维护。当op_maintain系统表中的所有维护指令执行完毕,一次批量维护操作也就完成了。
5 IPI的灵活性讨论
第2章提到目前针对ODDB中PE的索引结构(ODPI[14]、PNI[15])都存在一个严重问题,即缺乏灵活性。由于ODPI的核心思想与PNI类似,且谓词条件计算受限制,因此本文没有把ODPI作为对比索引(下同)。本文通过对比IPI和PNI从以下两方面来说明IPI在灵活性方面的优势:
(1)使用IPI能以较少的索引支持更全面的路径覆盖。假设一个类网有n个类,就有n×(n-1)条路径。由于正逆路径共用同一个PNI,覆盖全部路径需要n×(n-1)/2个PNI;而对于IPI,覆盖全部路径只需要对每个类建立索引,即n个IPI。显然,O(n)在复杂度上远小于O(n2)。如果PNI仅建立和IPI同样数目的索引,即只对n条路径建立PNI,那么此时PNI的路径覆盖率如式(6)所示。随着n的增加,其路径覆盖率会越来越小。因此,在大多情况下,需要更多的PNI才能维持和IPI同样的需求,并且类网的数据规模越大,IPI的优势越明显。
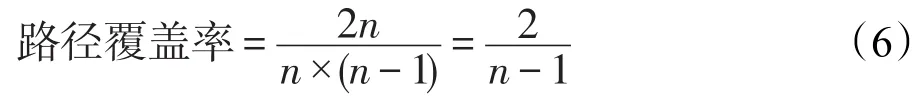
(2)使用IPI能更好地适应需求变化。以图1的教学管理数据库模式为例,假设使用者是学生,可能的查询需求有:查询课程信息,查询自己某门课程的绩点等等,分别对应如下的路径:Student→Cou_Stu→Course,Student→Cou_Stu→Stu_Grade。要维持此时的需求,可以对每个类建立IPI或对每条频繁查询的路径建立PNI。若以后该数据库的使用者变为教师,查询需求则可能有:查询课程信息,查询自己的职称等,分别对应如下的路径:Teacher→Tea_Eva→Course,Teacher→Tea_Eva。此时原先建立的PNI对新的查询无效,而IPI索引方法则可以提供任意路径的查询。当然上述例子也许过于极端,但能说明PNI难以适应需求变化的问题。
综上,由于一个类网中类的数目远小于路径数,IPI对每个类建就能覆盖全部路径,并能适应应用需求的变化。与PNI相比,IPI能以更少的索引数量满足需求,对需求变化的适应性也更好。
6 实验
本文把IPI索引方法分别与PT[14-15](即不使用索引)和PNI[15]索引方法进行对比。通过实验证明IPI索引方法的有效性。所有实验都在ODDB系统Totem[7]中完成。
实验使用的测试环境是一台PC机,其配置如下:Intel®CoreTMi5-2320 3.0 GHz CPU,4 GB内存容量,500 GB硬盘,Ubuntu 16.04操作系统,Totem 2.0数据库系统。实验采用一个教学管理数据库为测试数据库(数据库模式如图1所示),不同规模的数据集(DS1~DS6,表4)为测试数据集。在表4中,每个单元格的数据表示不同数据集中每个类的对象数目。
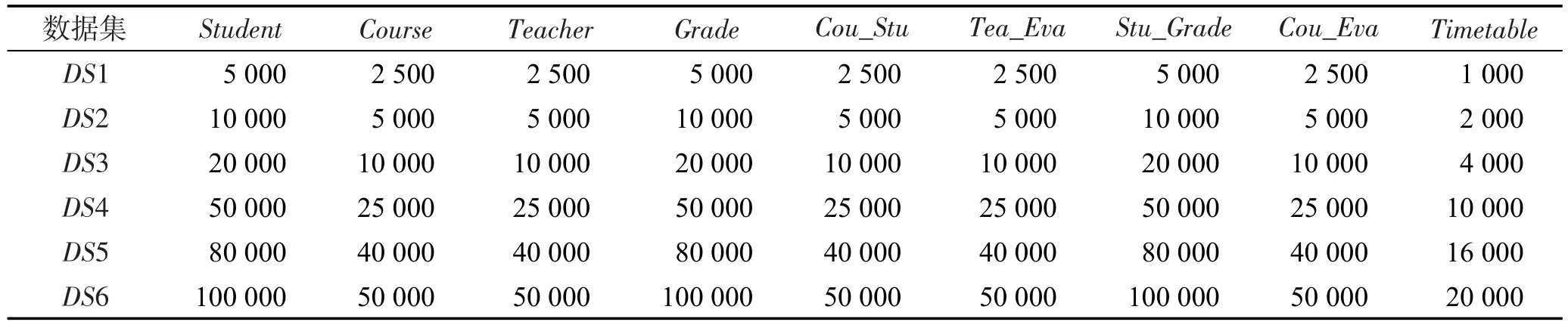
Table 4 Test data sets表4 测试数据集
实验结果表明使用IPI得到的结果和不使用索引的完全相同,即IPI的有效性得到证明。下面实验将分析路径长度和谓词条件对计算效率的影响,以及IPI创建时间和存储空间的影响因素,并讨论索引维护时间、效率以及灵活性之间的权衡。
6.1 路径长度对PE计算的影响
第一组实验在不考虑谓词条件的情况下,分别以路径长度为3和5的PE为测试用例,测试不同数据规模下各个方法的执行时间。由图3可以看出,3种方法的执行时间都是随着路径长度的增加而增长。它们在计算过程中都依赖于路径:IPI需要判断是否匹配路径中的所有类;PT是沿着路径依次获取每个类满足条件的对象实例;PNI则是直接建立于固定的路径上。整体实验结果表明,3种方法中PT效率最差,这是因为它需要不断存取中间路径上的对象实例,频繁的I/O操作导致总的时间开销较大。IPI的效率比PNI略差一些,因为IPI在获取终点对象前比PNI多一步操作,即判断对象是否匹配路径。但该操作消耗的时间占整个计算时间的比重很小,因此二者的效率相差无几。
6.2 谓词条件对PE计算的影响
第二组实验在不考虑路径长度的情况下,分别以带1个和2个谓词条件的PE为测试用例,测试不同数据规模下各方法的执行时间。由图4可以看出,IPI和PNI的执行时间随谓词条件数目的增加而增长,而PT则无明显变化。因为PT是在遍历路径的同时判断谓词条件。一旦发现对象实例不满足谓词条件,就会提前中止该趟计算流程,因此更多的谓词条件对PT的执行时间影响不大,反而可能节省一些不必要的对象遍历时间。与之相反,IPI和PNI索引方法都以谓词条件为单位进行计算,因此谓词条件的数目和它们的执行时间成正比。
6.3 IPI索引的创建时间
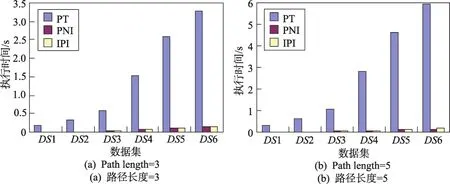
Fig.3 Influence of path length on PE evaluation图3 路径长度对PE计算的影响
第三组实验以教学管理数据库模式(图1)的Student类为例,得到不同数据规模下Student类的IPI创建时间(Inverted-Object-Index和Predicate-Index)。由图5可以看出,Inverted-Object-Index和Predicate-Index的创建时间随着数据规模的增大而增长。二者在创建过程中都需要扫描其所在类的对象,数据规模越大,创建时间也越长。此外,因为Predicate-Index的每个索引项对应一个谓词条件,所以谓词条件的数目是Predicate-Index创建时间的另一影响因素。如图5(b)所示,谓词条件越多,Predicate-Index的创建时间越长。
6.4 IPI索引的存储空间开销
第四组实验以教学管理数据库模式(图1)的Stu⁃dent类为例,得到不同数据规模下Student类的IPI存储开销(Inverted-Object-Index和 Predicate-Index)。由图6可看出,IPI的存储空间随数据规模的增大而增长。因Inverted-Object-Index的每个索引项对应其所在类的一个对象,显然Inverted-Object-Index的存储空间和数据规模成正比。对非空的Predicate-Index,每条记录的结果集规模越大,所占用的存储空间就越大。
6.5 IPI索引的维护时间与效率讨论
由图3和图4可以看出,使用IPI比不使用IPI(即PT)节省的时间随数据集的增大呈抛物线增长,其复杂度约为O(n2)。第4.4节讨论到IPI单次维护时间的复杂度最多是O(lbn),维护时间代价远小于使用IPI节省的时间。因此,IPI以较小的维护时间代价换取较大的效率提升是值得的。
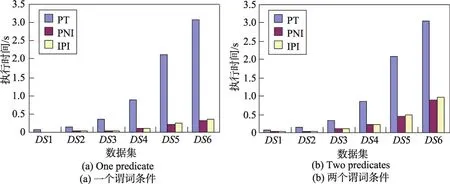
Fig.4 Influence of predicates on PE evaluation图4 谓词条件对PE计算的影响
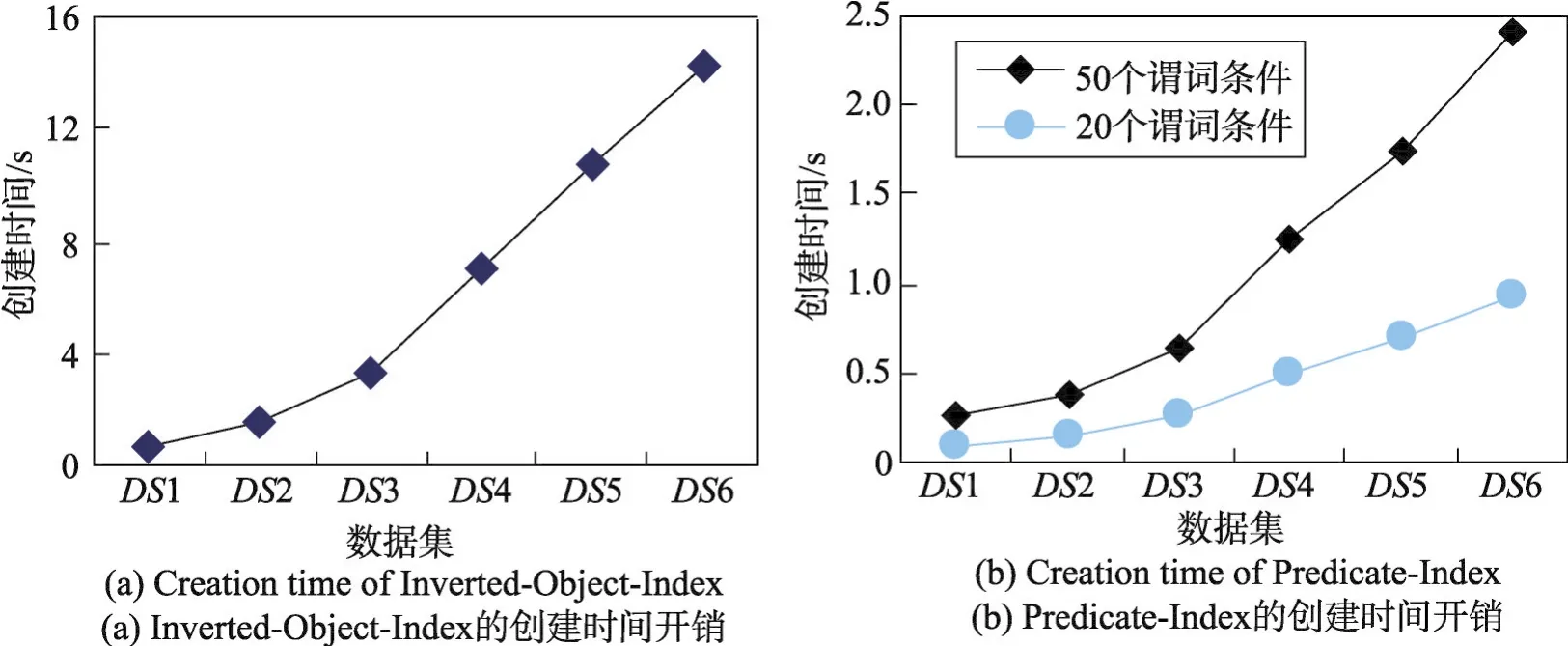
Fig.5 Creation time of IPI图5 IPI的创建时间开销
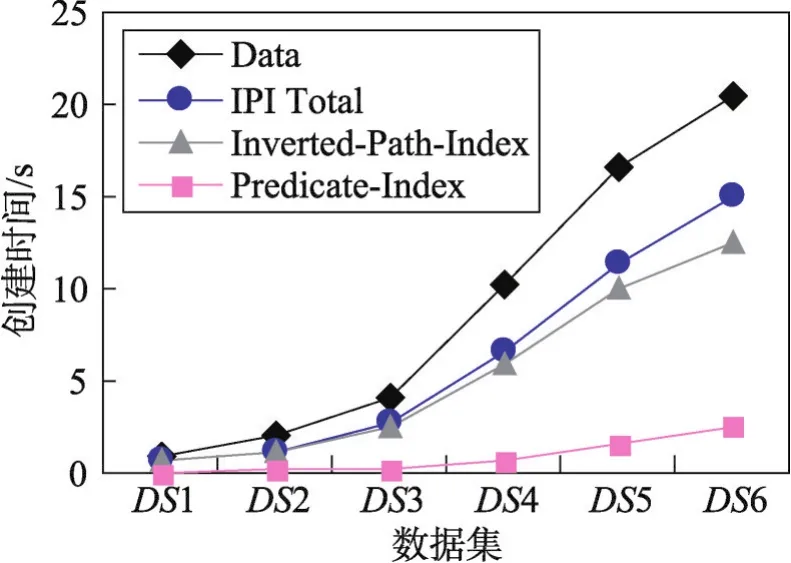
Fig.6 Storage space of IPI图6 IPI的存储空间开销
6.6 IPI索引的效率与灵活性讨论
由图3和图4可以看出,IPI整体效率比PNI略差一些,相差的时间平均约占IPI执行查询时间的5%,数据规模越大,其所占比重越小。第5章讨论到要覆盖某类网的全部路径,IPI需要的索引数目远小于PNI,且数据规模越大,两者数目相差越大。因此,对于比较大的数据规模,IPI以比较小的效率代价换取较大的灵活性是值得的。
7 结论和展望
作为ODDB的主要查询功能之一,跨类查询由PE实现,故PE的计算效率对ODDB的性能有显著影响。现有的一些针对ODDB跨类查询的索引结构(ODPI[14]、PNI[15])都局限于固定的路径,缺乏灵活性。在此背景下,本文提出一种新的索引结构——倒排路径索引(IPI),使ODDB跨类查询具备灵活高效的查询性能。IPI索引物化了对象间的代理关系,并利用对象关联检索技术辅助进行谓词条件计算。物化的对象代理关系可以灵活覆盖所有路径实例,并减少计算中对象遍历的开销;对象关联检索能过滤不满足条件的代理关系,以辅助计算谓词条件。本文通过实验对影响PE计算的各种因素进行研究,分析了路径长度和谓词条件对计算效率的影响。实验结果表明IPI索引方法能以不低于现有方法的效率支持更加灵活的PE计算。
IPI索引方法仍有一些不足。与PT[14-15]相比,建立IPI需要消耗存储空间,并且随数据库的变化需要频繁地维护IPI索引。因此,如何减少IPI的存储占用和维护时间是下一步的工作。
